Tabla de contenido
1.1 Calcular el rango de clics del usuario y el número de clics
2.1, registro de clics del usuario del conjunto de entrenamiento
2.2, registro de clics de usuario del conjunto de prueba
2.3 Tabla de datos de información de artículos de noticias
2.4 Artículo de noticias incrustando representación vectorial
3.1 Número de veces que los usuarios hacen clic repetidamente en las noticias
3.2 Distribución de usuarios con diferente número de clicks de noticias
3.3 El número de clics de noticias
3.5.1 Horarios de aparición de los distintos tipos de noticias
3.5.2 Número de palabras de noticias
3.5.3 La preferencia de tipos de noticias en las que hacen clic los usuarios
3.5.4 Distribución de la longitud de los artículos vistos por los usuarios
3.6 Análisis del tiempo de los usuarios que hacen clic en noticias
3.6.1 El valor promedio de la diferencia de tiempo de clic
4. Verifique la lista de similitud de artículos antes y después de obtener usuarios
4.1 Vectores de palabras para noticias de formación
4.2 Verifique la similitud de los artículos vistos por los usuarios antes y después
4.3 Verifique la lista de similitud de artículos antes y después de obtener usuarios
4.4 Ver la lista de similitud de artículos antes y después de visualizar usuarios
1. Preprocesamiento de datos
1.1 Calcular el rango de clics del usuario y el número de clics
%matplotlib inline
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
plt.rc('font', family='SimHei', size=13)
import os,gc,re,warnings,sys
warnings.filterwarnings("ignore")
path = '新建文件夹/推荐系统/零基础入门推荐系统 - 新闻推荐/'
# trn_click = pd.read_csv(path + 'train_click_log.csv')
trn_click = pd.read_csv(path+'train_click_log.csv',encoding= 'utf-8-sig',sep = r'\s*,\s*',header = 0)
trn_click.head()
item_df = trn_click = pd.read_csv(path + 'articles.csv',encoding= 'utf-8-sig',sep = r'\s*,\s*',header = 0)
item_df = item_df.rename(columns={'article_id': 'click_article_id'}) #重命名,方便后续match
item_df.head()
item_emb_df = pd.read_csv(path+'articles_emb.csv',encoding= 'utf-8-sig',sep = r'\s*,\s*',header = 0)
item_emb_df.head()
print(trn_click.columns.tolist())
Tutorial de Pandas | Explicación de uso de Groupby súper fácil de usar
# 对每个用户的点击时间戳进行排序
trn_click['rank'] = trn_click.groupby(['user_id'])['click_timestamp'].rank(ascending=False).astype(int)
tst_click['rank'] = tst_click.groupby(['user_id'])['click_timestamp'].rank(ascending=False).astype(int)
#计算用户点击文章的次数,并添加新的一列count
trn_click['click_cnts'] = trn_click.groupby(['user_id'])['click_timestamp'].transform('count')
tst_click['click_cnts'] = tst_click.groupby(['user_id'])['click_timestamp'].transform('count')2. Visualización de datos
2.1, registro de clics del usuario del conjunto de entrenamiento
Combinar trn_click y item_df en el conjunto de entrenamiento de registro de clics del usuario
#用户点击日志-训练集
trn_click = trn_click.merge(item_df, how='left', on=['click_article_id'])
trn_click.head()
trn_click.describe().T
trn_click.info()<clase 'pandas.core.frame.DataFrame'> Int64Index: 1112623 entradas, 0 a 1112622 Columnas de datos (total 14 columnas): # Columna Non-Null Count Dtype --- ------ ------ -------- ----- 0 user_id 1112623 no nulo int64 1 click_article_id 1112623 no nulo int64 2 click_timestamp 1112623 no nulo int64 3 click_environment 1112623 no nulo int64 4 click_deviceGroup 1112623 no nulo int64 5 click_os 1112623 no nulo int64 6 click_country 1112623 no nulo int64 7 click_region 1112623 no nulo int64 8 click_referrer_type 1112623 no nulo int64 9 rango 1112623 no nulo int32 10 click_cnts 1112623 no nulo int64 11 category_id 1112623 no nulo int64 12 created_at_ts 1112623 no nulo int64 13 words_count 1112623 no nulo int64 dtypes: int32(1), int64(13) uso de memoria: 123,1 MB
- 20000 usuarios totales
trn_click.user_id.nunique()#200000- Cada usuario hizo clic en al menos dos artículos en el conjunto de entrenamiento
trn_click.groupby('user_id')['click_article_id'].count().min() # 训练集里面每个用户至少点击了两篇文章- El entorno de clics click_environment cambia de manera muy estable, solo 2102 veces (0,19 %) el entorno de clics es 1; solo 25894 veces (2,3 %) el entorno de clics es 2; el resto (97,6 %) el entorno de clics es 4.
trn_click['click_environment'].value_counts()4 1084627 2 25894 1 2102 Nombre: click_environment, dtype: int64
- Haga clic en el grupo de dispositivos click_deviceGroup, el dispositivo 1 representa la mayoría (61%) y el dispositivo 3 representa el 36%.
trn_click['click_deviceGroup'].value_counts()1 678187 3 395558 4 38731 5 141 2 6 Nombre: click_deviceGroup, dtype: int64
2.2, registro de clics de usuario del conjunto de prueba
#测试集用户点击日志
tst_click = tst_click.merge(item_df, how='left', on=['click_article_id'])
tst_click.head()
tst_click.describe()
tst_click.user_id.nunique()#50000
tst_click.groupby('user_id')['click_article_id'].count().min() # 注意测试集里面有只点击过一次文章的用户Los ID de usuario del conjunto de entrenamiento van de 0 a 199999, mientras que los ID de usuario del conjunto de prueba A van de 200000 a 249999.
Durante el entrenamiento, también se deben incluir los datos del conjunto de prueba, lo que se denomina cantidad total de datos.
2.3 Tabla de datos de información de artículos de noticias
item_df.head().append(item_df.tail())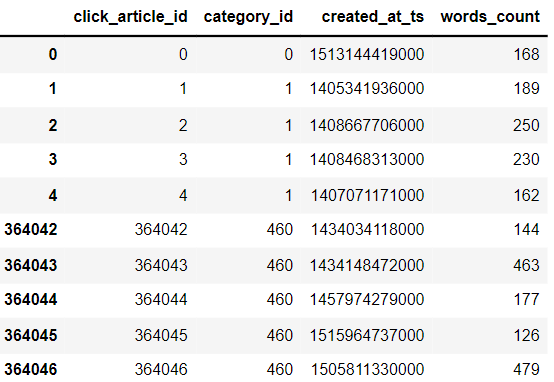
item_df.shape # 364047篇文章- recuento de palabras de noticias
#新闻字数统计
item_df['words_count'].value_counts()- categoría de noticias
#新闻类别
item_df['category_id'].nunique()#461
item_df['category_id'].hist()2.4 Artículo de noticias incrustando representación vectorial
item_emb_df.head()
item_emb_df.shape3. Análisis de datos
Combinar registros de usuario para conjuntos de entrenamiento y prueba
user_click_merge = trn_click.append(tst_click)
3.1 Número de veces que los usuarios hacen clic repetidamente en las noticias
#reset_index()重置索引。
user_click_count = user_click_merge.groupby(['user_id', 'click_article_id'])['click_timestamp'].agg({'count'}).reset_index()
user_click_count[:10]
| id_usuario | click_article_id | contar | |
|---|---|---|---|
| 0 | 0 | 30760 | 1 |
| 1 | 0 | 157507 | 1 |
| 2 | 1 | 63746 | 1 |
| 3 | 1 | 289197 | 1 |
| 4 | 2 | 36162 | 1 |
| 5 | 2 | 168401 | 1 |
| 6 | 3 | 36162 | 1 |
| 7 | 3 | 50644 | 1 |
| 8 | 4 | 39894 | 1 |
| 9 | 4 | 42567 | 1 |
user_click_count[user_click_count['count']>7]
user_click_count['count'].unique()
#array([ 1, 2, 4, 3, 6, 5, 10, 7, 13], dtype=int64)| id_usuario | click_article_id | contar | |
|---|---|---|---|
| 311242 | 86295 | 74254 | 10 |
| 311243 | 86295 | 76268 | 10 |
| 393761 | 103237 | 205948 | 10 |
| 393763 | 103237 | 235689 | 10 |
| 576902 | 134850 | 69463 | 13 |
#用户重复点击新闻次数
user_click_count.loc[:,'count'].value_counts() #取count列所有行,统计不同的count出现的次数
#可以看出:有1605541(约占99.2%)的用户未重复阅读过文章,仅有极少数用户重复点击过某篇文章。 这个也可以单独制作成特征1 1605541 2 11621 3 422 4 77 5 26 6 12 10 4 7 3 13 1 Nombre: recuento, dtipo: int64
3.2 Distribución de usuarios con diferente número de clicks de noticias
3.2.1 Usuarios activos
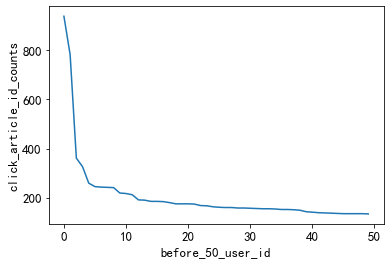
Los 50 usuarios principales con clics tienen más de 100 clics. Es posible definir usuarios cuyos clics son mayores o iguales a 100 veces como usuarios activos.
Esta es una idea de procesamiento simple. Para juzgar la actividad del usuario, es más completo combinar el tiempo de clic.
Más adelante, lo basaremos en el número de clics y tiempo de clic para determinar la actividad del usuario.
#用户点击次数分析
user_click_item_count = sorted(user_click_merge.groupby('user_id')['click_article_id'].count(), reverse=True)
plt.plot(user_click_item_count)
plt.xlabel('user_id')
plt.ylabel('click_article_id_counts')
#点击次数在前50的用户
plt.plot(user_click_item_count[:50])
plt.xlabel('before_50_user_id')
plt.ylabel('click_article_id_counts')
3.2.2 Usuarios inactivos
Hay muchos usuarios con menos o igual a dos clics, y estos usuarios pueden considerarse como usuarios inactivos.
#点击次数排名在[25000:50000]之间
plt.plot(user_click_item_count[25000:50000]) 
3.3 El número de clics de noticias
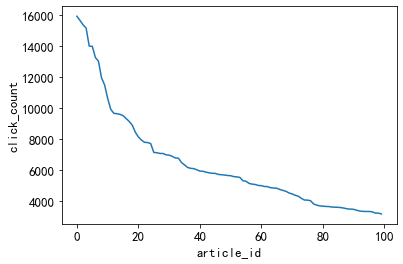
3.3.1 Noticias calientes
'''Los 20 principales artículos de noticias con más clics, el número de clics es superior a 2500.
Idea: Estas noticias se pueden definir como noticias calientes, que también es una forma sencilla de tratarlas.
Más adelante, también dividiremos la popularidad de los artículos según la cantidad de clics y el tiempo. '''
item_click_count = sorted(user_click_merge.groupby('click_article_id')['user_id'].count(), reverse=True)
plt.plot(item_click_count)
plt.xlabel('article_id')
plt.ylabel('click_count')
plt.plot(item_click_count[:100])
plt.xlabel('article_id')
plt.ylabel('click_count')
#点击率排名前100的新闻点击量都超过1000次
plt.plot(item_click_count[:20])
plt.xlabel('article_id')
plt.ylabel('click_count')
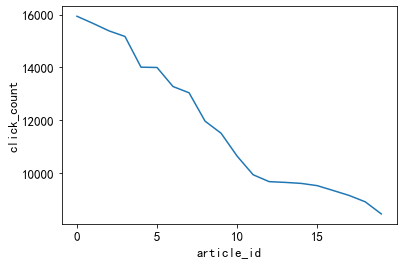
3.3.2 Noticias impopulares
En muchas noticias solo se hace clic una o dos veces. Idea: Se puede definir que estas noticias son noticias impopulares
plt.plot(item_click_count[3500:])3.4 Frecuencia de co-ocurrencia de noticias: el número de veces que dos noticias aparecen consecutivamente
tmp = user_click_merge.sort_values('click_timestamp')
tmp['next_item'] = tmp.groupby(['user_id'])['click_article_id'].transform(lambda x:x.shift(-1))
union_item = tmp.groupby(['click_article_id','next_item'])['click_timestamp'].agg({'count'}).reset_index().sort_values('count', ascending=False)
union_item[['count']].describe()
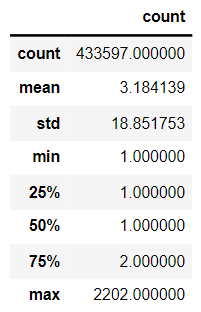
El número promedio de co-ocurrencias es 3.18, y el más alto es 2202. La probabilidad de que dos noticias aparezcan consecutivamente es alta, lo que indica que las noticias que leen los usuarios están altamente correlacionadas.
x = union_item['click_article_id']
y = union_item['count']
plt.scatter(x, y)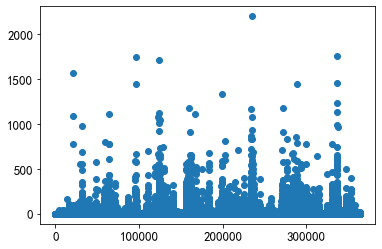
Unas 75.000 parejas coexisten al menos una vez
plt.plot(union_item['count'].values[40000:])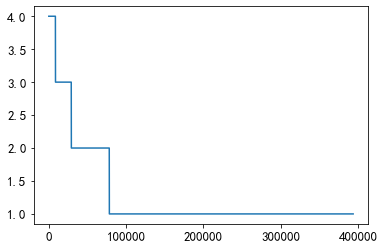
3.5 Información de la noticia
3.5.1 Horarios de aparición de los distintos tipos de noticias
Menos de 50 tipos diferentes de noticias tienen mayor número de ocurrencias
#不同类型的新闻出现的次数
plt.plot(user_click_merge['category_id'].value_counts().values)
plt.xlabel('article_id')
plt.ylabel('appear_counts')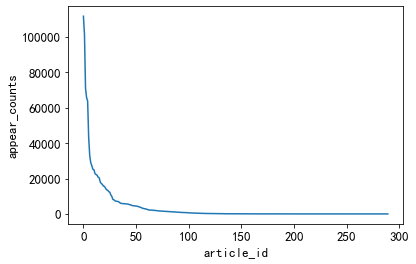
noticias con menos ocurrencias
#出现次数比较少的新闻类型, 有些新闻类型,基本上就出现过几次
plt.plot(user_click_merge['category_id'].value_counts().values[150:])
plt.xlabel('article_id')
plt.ylabel('appear_counts')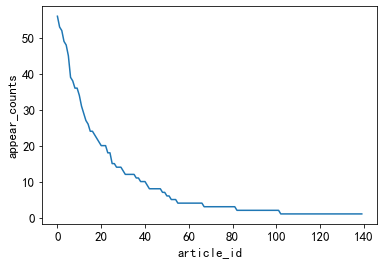
3.5.2 Número de palabras de noticias
#新闻字数的描述性统计
user_click_merge['words_count'].describe()
plt.plot(user_click_merge['words_count'].values)
3.5.3 La preferencia de tipos de noticias en las que hacen clic los usuarios
Esta función se puede utilizar para medir si los intereses del usuario son amplios.
#用户偏好的新闻广泛程度
plt.plot(sorted(user_click_merge.groupby('user_id')['category_id'].nunique(), reverse=True))
plt.xlabel('user_id')
plt.ylabel('category_id')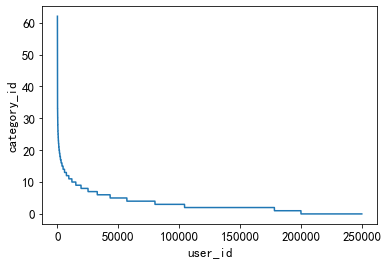
En la figura se puede ver que hay menos usuarios con una amplia gama de tipos de preferencias, y la mayoría de los usuarios tienen menos tipos de preferencias, menos de 20 tipos.
3.5.4 Distribución de la longitud de los artículos vistos por los usuarios
Al contar el recuento promedio de palabras de noticias en las que hacen clic diferentes usuarios, esto puede reflejar si los usuarios están más interesados en artículos largos o artículos cortos.
plt.plot(sorted(user_click_merge.groupby('user_id')['words_count'].mean(),reverse = True))
plt.xlabel('user_id')
plt.ylabel('avg_words_count')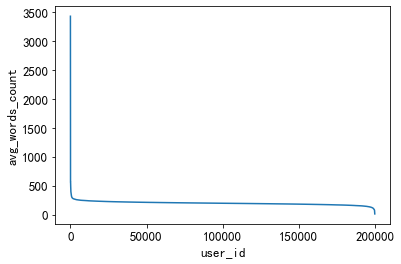
El número medio de palabras de los artículos leídos por un pequeño grupo de personas es muy alto y el número medio de palabras leídas por un pequeño grupo de personas es muy bajo.
La mayoría de la gente prefiere leer noticias de entre 200 y 400 palabras.
plt.plot(sorted(user_click_merge.groupby('user_id')['words_count'].mean(),reverse = True)[1000:45000])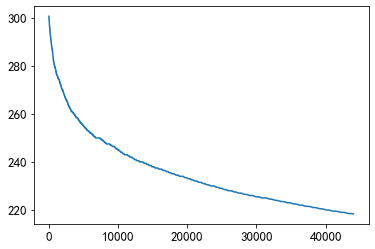
En el rango de la mayoría de las personas, las personas prefieren leer noticias con un recuento de palabras de 220 a 250 palabras.
3.6 Análisis del tiempo de los usuarios que hacen clic en noticias
#为了更好的可视化,这里把时间进行归一化操作
from sklearn.preprocessing import MinMaxScaler
mm = MinMaxScaler()
user_click_merge['click_timestamp'] = mm.fit_transform(user_click_merge[['click_timestamp']])
user_click_merge['created_at_ts'] = mm.fit_transform(user_click_merge[['created_at_ts']])
user_click_merge = user_click_merge.sort_values('click_timestamp')3.6.1 El valor promedio de la diferencia de tiempo de clic
def mean_diff_time_func(df, col):
df = pd.DataFrame(df, columns={col})
df['time_shift1'] = df[col].shift(1).fillna(0)#shift(1)是把数据向下移动1位
df['diff_time'] = abs(df[col] - df['time_shift1'])
return df['diff_time'].mean()
# 点击时间差的平均值
mean_diff_click_time = user_click_merge.groupby('user_id')['click_timestamp',
'created_at_ts'].apply(lambda x: mean_diff_time_func(x, 'click_timestamp'))
plt.plot(sorted(mean_diff_click_time.values, reverse=True))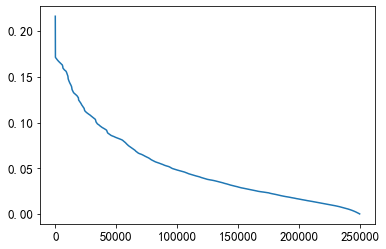
3.6.2 El valor promedio de la diferencia de tiempo de creación de los artículos en los que se hizo clic antes y después
# 前后点击的文章的创建时间差的平均值
mean_diff_created_time = user_click_merge.groupby('user_id')['click_timestamp',
'created_at_ts'].apply(lambda x: mean_diff_time_func(x, 'created_at_ts'))
plt.plot(sorted(mean_diff_created_time.values, reverse=True))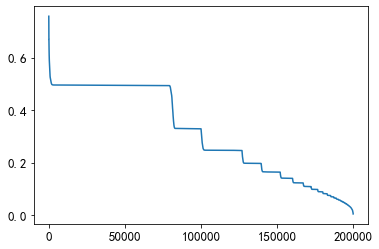
De la figura anterior, se puede encontrar que la diferencia de tiempo entre diferentes usuarios que hacen clic en el artículo es diferente. Los usuarios hacen clic en el artículo sucesivamente, y el tiempo de creación del artículo también es diferente.
4. Verifique la lista de similitud de artículos antes y después de obtener usuarios
4.1 Vectores de palabras para noticias de formación
from gensim.models import Word2Vec
import logging, pickle
# 需要注意这里模型只迭代了一次
def trian_item_word2vec(click_df, embed_size=16, save_name='item_w2v_emb.pkl', split_char=' '):
#按click_timestamp排序
click_df = click_df.sort_values('click_timestamp')
# 将click_article_id转换成字符串才可以进行训练
click_df['click_article_id'] = click_df['click_article_id'].astype(str)
# 将click_article_id转换成句子的形式
docs = click_df.groupby(['user_id'])['click_article_id'].apply(lambda x: list(x)).reset_index()
docs = docs['click_article_id'].values.tolist()
# 为了方便查看训练的进度,这里设定一个log信息
logging.basicConfig(format='%(asctime)s:%(levelname)s:%(message)s', level=logging.INFO)
# 这里的参数对训练得到的向量影响也很大,默认负采样为5
w2v = Word2Vec(docs, vector_size=16, sg=1, window=5, seed=2020, workers=24, min_count=1, epochs=10)
# 保存成字典的形式
item_w2v_emb_dict = {k: w2v.wv[k] for k in click_df['click_article_id']}
return item_w2v_emb_dictitem_w2v_emb_dict = trian_item_word2vec(user_click_merge)4.2 Verifique la similitud de los artículos vistos por los usuarios antes y después
# 随机选择5个用户,查看这些用户前后查看文章的相似性
sub_user_ids = np.random.choice(user_click_merge.user_id.unique(), size=15, replace=False)
sub_user_info = user_click_merge[user_click_merge['user_id'].isin(sub_user_ids)]# .isin()筛选行
sub_user_info.head()4.3 Verifique la lista de similitud de artículos antes y después de obtener usuarios
# 得到用户前,后查看文章的相似度列表
def get_item_sim_list(df):
sim_list = []
item_list = df['click_article_id'].values
for i in range(0, len(item_list)-1):
emb1 = item_w2v_emb_dict[str(item_list[i])] # 需要注意的是word2vec训练时候使用的是str类型的数据
emb2 = item_w2v_emb_dict[str(item_list[i+1])]
sim_list.append(np.dot(emb1,emb2)/(np.linalg.norm(emb1)*(np.linalg.norm(emb2))))
sim_list.append(0)
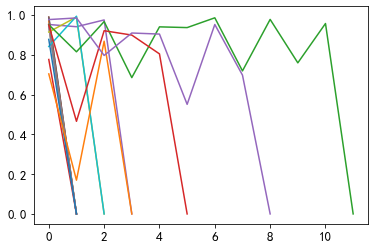
return sim_list4.4 Ver la lista de similitud de artículos antes y después de visualizar usuarios
for _, user_df in sub_user_info.groupby('user_id'):
item_sim_list = get_item_sim_list(user_df)
plt.plot(item_sim_list)