1. Descripción
¿Quiere comenzar su próximo proyecto de visualización de datos? Sea amigable con la limpieza de datos primero. La limpieza de datos es un paso importante en cualquier canalización de datos, ya que transforma las entradas de datos "sucios" sin procesar en datos más confiables, relevantes y concisos. Las herramientas de preparación de datos como Tableau Prep o Alteryx se crearon para este propósito, pero ¿por qué gastar dinero en estos servicios cuando puede hacer el trabajo en un lenguaje de programación de código abierto como Python? Este artículo lo guía a través del proceso de preparación de datos para su visualización mediante scripts de Python, lo que brinda una alternativa más rentable a las herramientas de preparación de datos.

Foto de Robert Katzki en Unsplash
2. Descripción general de la limpieza de datos
Nota: en este artículo, nos centraremos en preparar Tableau para la visualización de datos, pero los conceptos principales también se aplican a otras herramientas de inteligencia empresarial.
Veo. La limpieza de datos puede parecer otro paso en el largo proceso de dar vida a una visualización o tablero . Pero es crucial, y puede ser agradable. Así es como ajusta el conjunto de datos al obtener información sobre qué datos tiene y qué no tiene y las decisiones correspondientes que debe tomar para lograr sus objetivos de análisis finales.
Si bien Tableau es una herramienta de visualización de datos versátil, a veces el camino hacia las respuestas no está claro. Aquí, manipular su conjunto de datos antes de cargarlo en Tableau puede ser su mayor aliado secreto. Exploremos algunas razones clave por las que la limpieza de datos es beneficiosa antes de integrarla con Tableau:
- Elimine la información irrelevante: los datos sin procesar a menudo contienen información innecesaria o repetitiva que puede confundir su análisis. Al limpiar sus datos, puede eliminar el desperdicio y enfocar las visualizaciones en las características más relevantes de sus datos.
- Simplifique las transformaciones de datos : realizar estas transformaciones previas antes de cargar los datos en Tableau puede simplificar el proceso si tiene una idea clara de la visualización que desea generar.
- Transferencia más fácil dentro del equipo : si bien las fuentes de datos se actualizan regularmente, agregar nuevas fuentes de datos puede generar inconsistencias y potencialmente romper Tableau. Con la ayuda de las secuencias de comandos de Python y las descripciones de código (más conocidas formalmente como documentos de rebajas), puede compartir de manera efectiva y capacitar a otros para que entiendan su código y resuelvan cualquier problema de programación que pueda surgir.
- Ahorre tiempo en la actualización de datos: los datos que deben actualizarse regularmente pueden beneficiarse del aprovechamiento de Hyper API, una aplicación que genera el formato de archivo Hyper específico de Tableau, lo que permite la carga automática de extractos y aumenta la eficiencia de la actualización de datos. proceso.
Ahora que hemos cubierto algunas de las ventajas de preparar datos, pongámoslo en práctica creando una canalización de datos simple. Exploraremos cómo la limpieza y el procesamiento de datos se pueden integrar en los flujos de trabajo y ayudar a simplificar la gestión de las visualizaciones.
3. Use secuencias de comandos de Python para crear canalizaciones de datos
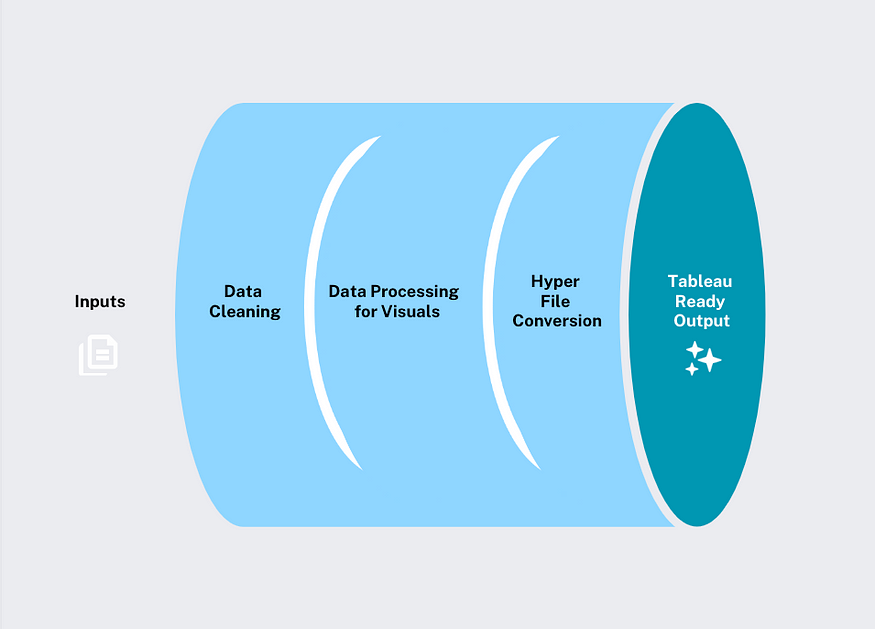
Fuente de la imagen: autor
Nuestro proceso de datos es simple: limpieza de datos, procesamiento de datos visuales y conversión en superarchivos listos para Tableau para una integración perfecta.
Una última nota antes de sumergirse en nuestro ejemplo de trabajo, para la conversión de archivos Hyper, debe descargar la biblioteca. Esta biblioteca simplifica el proceso de convertir marcos de datos de Pandas en extractos .hyper de Tableau. Puede hacerlo fácilmente usando el siguiente código en una terminal en su entorno de elección (para aquellos menos familiarizados con los entornos, aquí hay un excelente artículo introductorio sobre qué son y cómo instalar ciertas bibliotecas ) :pantab
#run the following line of code to install the pantab library in your environment
pip install pantab4. Tutorial: Preparación de datos con Python (Explorando matrículas de vehículos eléctricos en Canadá)
Nos centraremos en la popularidad de las diferentes marcas y modelos de vehículos eléctricos en función de los datos gubernamentales disponibles de Statistics Canada.
Es importante tener en cuenta que esto se basa en el conjunto de datos utilizado en mi publicación anterior: Análisis de vehículos eléctricos con R. Si está interesado en comprender la exploración inicial del conjunto de datos y la lógica detrás de las decisiones tomadas, consulte para obtener más detalles. Este tutorial se centra en cómo crear secuencias de comandos de Python y, en cada paso después de la entrada inicial, guardamos la salida de cada secuencia de comandos de Python en su propia carpeta de la siguiente manera:

Fuente de la imagen: autor
El proceso de la carpeta mantiene la canalización organizada y podemos documentar todos los resultados del proyecto. ¡Comencemos a construir nuestro primer script de Python!
4.1 Limpieza de datos
Los scripts iniciales en la canalización siguen los pasos básicos de limpieza de datos, que para este conjunto de datos incluyen: mantener/renombrar columnas relevantes, eliminar nulos y/o duplicados y hacer que los valores de los datos sean consistentes.
Podemos comenzar especificando la ubicación del archivo de entrada y el destino del archivo de salida. Este paso es importante porque nos permite organizar diferentes versiones del archivo en el mismo lugar, en este caso modificamos la salida del archivo cada mes, por lo que cada salida del archivo está separada por mes, como se muestra al final del nombre del archivo:2023_04
#import necessary packages
import pandas as pd
import os.path as path
inputfile = "Data/prep_tableau/input/izev-april-2023.csv"
outputfile = 'clean_data/clean_data_2023-04.csv'El siguiente código lee la entrada .csv sin procesar y define las columnas que queremos conservar. En este caso, nos interesa mantener la información relacionada con el tipo de modelo de automóvil comprado e ignorar las columnas relacionadas con los concesionarios de automóviles o cualquier otra cosa que no sea relevante.
# read in the data
df = pd.read_csv(inputfile)
# removing certain columns
clean_df = df[df.columns[~df.columns.isin(['Incentive Request Date',
'Government of Canada Fiscal Year (FY)',
'Dealership Province / Territory '
'Dealership Postal Code','BEV/PHEV/FCEV - Battery equal to or greater than 15 kWh or \nElectric range equal to or greater than 50 km',
'BEV, PHEV ? 15 kWh or PHEV < 15 kWh (until April 24, 2022) \nand\nPHEV ? 50 km or PHEV < 50 km and FCEVs ? 50 km or FCEVs < 50 km\n(April 25, 2022 onward)',
'Individual or Organization \n(Recipient)',
'Country'])]]Ahora podemos acortar los nombres de las columnas, eliminar los espacios iniciales o finales y agregar guiones bajos para facilitar la comprensión.
# shortening longer column names
clean_df = clean_df.rename({"Battery-Electric Vehicle (BEV), Plug-in Hybrid Electric Vehicle (PHEV) or Fuel Cell Electric Vehicle (FCEV)" : "EV_Type",
"Recipient Province / Territory":"Province.Recipient"},axis="columns")
# adding and removing white spaces underscores between column names
clean_df.columns = clean_df.columns.str.strip()
clean_df.columns = clean_df.columns.str.replace(' ', '_') A continuación, usaremos la función para eliminar datos vacíos después de comprobar que solo hay unas pocas entradas vacías en el conjunto de datos. En este punto, también desea eliminar los duplicados, pero no lo haremos para este conjunto de datos en particular. Esto se debe a que hay mucha información duplicada y, sin identificadores de fila, la eliminación de duplicados provocaría la pérdida de datos..dropna
# removing nulls
clean_df = clean_df.dropna(how="all") El paso final es guardar los datos como un archivo .csv en la ubicación de carpeta adecuada que se colocará en una carpeta en nuestro directorio compartido.clean_data
# save to csv
clean_path = path.abspath(path.join(__file__ ,'../', outputfile ))
clean_df.to_csv(clean_path,index=False) Observe cómo usamos el archivo de referencia y especifique el directorio del archivo con el comando bash, que indica la carpeta anterior. Esto concluye nuestro script de limpieza de datos. ¡Ahora pasemos a la fase de procesamiento de datos!__file__../
El acceso al código de trabajo completo y los scripts de ensamblaje se puede encontrar en mi repositorio de Github .
4.2 Procesamiento de datos visuales
Revisemos los objetivos de visualización que estábamos tratando de lograr para resaltar los cambios en la penetración de vehículos eléctricos registrados. Para demostrar esto de manera efectiva, queremos que el conjunto de datos final listo para Tableau contenga las siguientes funciones, que codificaremos:
- Número absoluto de vehículos por año
- Participación de vehículos por año
- El mayor aumento o disminución de vehículos matriculados
- Clasificación de vehículos registrados
- Clasificación de vehículos en comparación con registros anteriores
Dependiendo de las imágenes que pretenda generar, crear la columna ideal puede ser un proceso iterativo. En mi caso, incluí la última columna después de crear la visualización porque sabía que quería brindarle al espectador una comparación visual de la diferencia de clasificación, así que ajusté el script de Python en consecuencia.
Para el siguiente código, nos centraremos en el conjunto de datos de agregación del modelo, ya que los otros conjuntos de datos de la marca son muy similares. Primero definamos nuestra suma:inputfileoutputfile
inputfile = "/Data/prep_tableau/clean_data/clean_data_2023-04.csv"
outputfile = "clean_model/ev_vehicle_models_2023-04.csv" #edit date as needed Tenga en cuenta cómo nos referimos a la carpeta from, que es el resultado de nuestro script de limpieza de datos.inputfileclean_data
El siguiente código lee los datos y crea un marco de datos de recuentos agregados:Vehicle_Make_and_ModelCalendar_Year
# Read in the data
auto_df = pd.read_csv(inputfile)
# Defining the Dataframe and renaming columns
processed_auto = pd.DataFrame(auto_df.groupby(["Vehicle_Make_and_Model", "Calendar_Year"])["Calendar_Year"].count())
processed_auto = processed_auto.rename(columns={"Calendar_Year": "count"}).reset_index() La función funciona como una función de tabla dinámica en Excel, donde ingresa cada valor como una columna.pivotCalendar_Year
# Pivoting the data based on Vehicle Make and Year with their respective counts
processed_auto_pivot = processed_auto.pivot(index='Vehicle_Make_and_Model', columns='Calendar_Year', values='count').reset_index()
Luego, el script usa un bucle For para crear la entrada. Esto calculará la escala para cada modelo, de modo que cada modelo se pueda comparar en la misma escala, y creará una columna para cada año:per_1K
# Defining column list required for the For Loop
col_list = range(2019, 2024)
# Looking at magnitude every 1000 cars - For loop
for year in col_list:
column_name = f"per_1K_{year}"
total_column = year
processed_auto_pivot[column_name] = round(processed_auto_pivot[total_column] / processed_auto_pivot[total_column].sum(), 4) * 1000
Al calcular la escala por año, podemos calcular el aumento o disminución máximos en los datos desde el comienzo del conjunto de datos de 2019 hasta el último año completo de datos de 2022.
#Calculating prop_num_change
processed_auto_pivot["prop_num_change"] = processed_auto_pivot["per_1K_2022"] - processed_auto_pivot["per_1K_2019"]
Aquí, la función se usa para volver a girar la columna separada por año en filas, por lo que solo tenemos una columna y su valor asociado.meltper_1Kper_1K
# Pivoting for totals
cars_per1K = pd.melt(
processed_auto_pivot,
id_vars=["Vehicle_Make_and_Model", "prop_num_change"],
value_vars=["per_1K_2019", "per_1K_2020", "per_1K_2021", "per_1K_2022", "per_1K_2023"],
var_name="year",
value_name="per_1K"
).loc[:, ["Vehicle_Make_and_Model", "year", "per_1K", "prop_num_change"]El siguiente código nos permite unir el conteo absoluto con el otro cálculo que acabamos de crear.
# Making year names consistent with processed_auto
cars_per1K["year"]= cars_per1K["year"].str.replace("per_1K_", "")
#joining the total counts with 1K totals
ev_totals = processed_auto.merge(cars_per1K, left_on=["Vehicle_Make_and_Model", "Calendar_Year"], right_on=["Vehicle_Make_and_Model", "year"], how="left")
#dropping irrevelant column
ev_totals = ev_totals.drop("year", axis=1)Ahora podemos crear una columna con el recuento de licencias y ordenar estos valores por y .rankVehicle_Make_and_ModelCalendar_Year
#ranking model by counts
ev_totals['rank'] = ev_totals.groupby('Calendar_Year')['count'].rank(ascending=False, method="min")
ev_totals = ev_totals.sort_values(['Vehicle_Make_and_Model', 'Calendar_Year'])La última columna que se crea es la que se crea con esta función.previous_rankshift
#creating previous rank, lag by rank
ev_totals['previous_rank'] = ev_totals.groupby('Vehicle_Make_and_Model')['rank'].shift()Finalmente, podemos guardar la salida en una ruta de carpeta en la canalización, lo que nos brinda un conjunto de datos listo para la visualización.clean_model
# save to csv
model_path = path.abspath(path.join(__file__ ,'../', outputfile ))
ev_totals.to_csv(model_path,index=False)Como recordatorio amistoso, el código completo de la secuencia de comandos de Python, incluido el código para el conjunto de datos procesado, se puede encontrar en mi repositorio de GitHub .
clean_brand
4.3 Convierta el archivo de datos final al formato de archivo .hyper
El paso final de la tubería es relativamente simple, ya que todo lo que nos queda por hacer es convertir el archivo .csv que creamos para procesar al formato de archivo .hyper. Esto debería ser relativamente fácil siempre que haya descargado las bibliotecas antes mencionadas.pantab
Vale la pena mencionar que en Tableau, los datos conectados pueden conectarse en vivo o extraerse. Las conexiones en vivo garantizan un flujo de datos continuo, con actualizaciones de fuentes reflejadas en Tableau casi al instante. La extracción de datos implica que Tableau cree un archivo local con una extensión de archivo .hyper que contiene una copia de los datos (puede encontrar una descripción detallada de la fuente de datos aquí ). Su principal ventaja son sus capacidades de carga rápida, que permiten a Tableau acceder a la información y presentarla de manera más eficiente, lo que es especialmente útil para grandes conjuntos de datos.
El código para la secuencia de comandos de conversión de hiperarchivo comienza con la carga y el empaquetado, y luego con la lectura de los conjuntos de datos que necesita Tableau.pandaspantabcleaned_model
import pandas as pd
import pantab
#read in files
model_df = pd.read_csv('Data/prep_tableau/clean_model/ev_vehicle_models_2023-04.csv') La última línea de código usa una función que genera un archivo .hyper y lo guarda en una carpeta.frame_to_hyper hyper
#save to hyper file
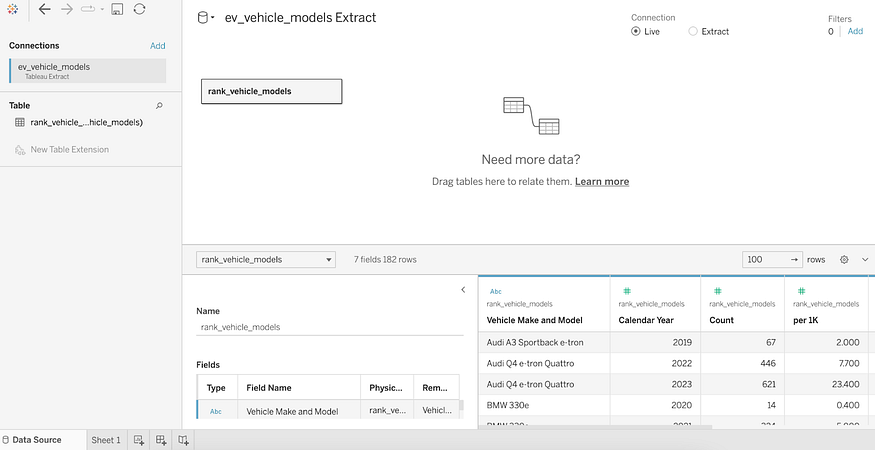
pantab.frame_to_hyper(model_df, "hyper/ev_vehicle_models.hyper", table="rank_vehicle_models") El último paso, podemos cargar fácilmente el formato de archivo .hyper en Tableau abriendo un nuevo libro de trabajo, en esa sección puede hacerlo seleccionando Cuando cargamos el archivo, debería aparecer como un extracto de Tableau como en la pantalla a continuación, como se muestra en la captura de pantalla, ¡sus datos están listos para crear imágenes en ellos!select a filemoreev_vehicle_models.hyper
conclusión V
Al incorporar una planificación cuidadosa en sus visualizaciones, puede simplificar el mantenimiento de sus tableros mediante la creación de canalizaciones de datos simples. No se preocupe si tiene pocos recursos; los programas de codificación de código abierto como Python ofrecen capacidades poderosas. Finalmente, como recordatorio amistoso, para acceder a la secuencia de comandos de Python, consulte mi repositorio de GitHub aquí .