Documento de información: Papel
contorno
Clasificador Para asignar una etiqueta a cada muestra, en donde la etiqueta más de dos categorías. Por ejemplo, para un micro-blog, si quieres clasificación temática, etiquetas de categoría pueden tener entretenimiento, deportes, militar, educación y así sucesivamente.
método de clasificación de texto utilizando principalmente una red neuronal existente. En la última capa se calcula generalmente utilizando un Softmax texto probabilidad que pertenece a cada categoría. Sin embargo, este método se considera por separado para cada categoría, haciendo caso omiso de la correlación entre las categorías que contribuyeron las características de entrada originales para cada categoría son iguales.
Algunos métodos que utilizan el modo de una sola vs-resto (OVR) para la clasificación multi-etiqueta. Es decir, para cada clase, hay un clasificador binario para determinar si la muestra pertenece a la clase pertenecen a esta clase. De esta manera, inspirado en el aprendizaje multi-tarea, el aprendizaje a través intento conjunto para capturar múltiples clasificadores asociación entre múltiples tareas. Multitarea aprender diferentes aspectos de características, mientras que el potencial del modelo de regularización, por lo que el modelo mejor.
Este documento también se llevó a cabo a través de múltiples clases OVR clasificación, OVR pero cada clasificador binario como una tarea independiente, toda la OVR clasificador binario y el multi-clase formulario de clasificación de aprendizaje multi-tarea original. El autor cree que contiene tanto la clase de entidad de entrada independiente intercambio de información (clase agnóstica) y específicos para cada categoría (clase específica) de. El ex poca utilidad para la clasificación, que contiene información útil para la clasificación, que quieren separar estas dos características de piezas, es decir, para eliminar a los irrelevante que algunos de la categoría de información.
Con el fin de hacer que el modelo de las características que se divide, el documento también propone una estrategia de entrenamiento de combate. Específicamente, el clasificador binario OVR cada categoría tiene un codificador característica particular, además de una característica compartida de un codificador para generar una clase de entidad de entrada clasificadores independientes. discriminador de Objetivo que se determina de la categoría característica, el generador de destino genera una clase es irrelevante y spoofing discriminador función. De esta manera más de otra tarea de clasificación es aplicable.
método
Los siguientes son el modelo estructural principal de la fig.
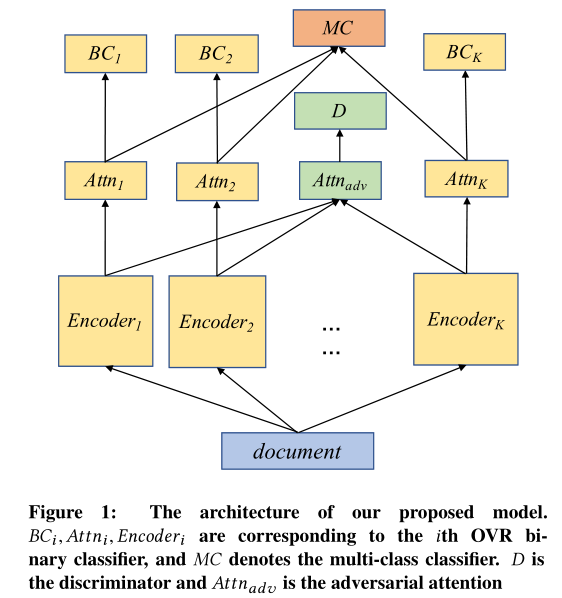
Definición del problema
Cada documento \ (D_I \ in D \) por una serie de frase \ (<s_1, s_2, \ dots> \) , cada uno de los cuales consiste en una serie frase-palabra. Dado un conjunto de documentos \ (D \) , el documento \ (K \) tarea de clasificación es estudiar el documento para asignar la etiqueta \ (f: D \ rightarrow \ {L_1, \ dots, L_K \} \) . La tarea multi-clasificación basado en papel OVR modo de división \ (K \) th tareas binarios, cada uno expresado como un clasificador binario \ (F_k: D \ rightarrow \ {L_K, -l_k \} \) , en la que \ (-l_k \) indica que el documento no pertenece a la primera \ (k \) clase.
modelo
clasificación binaria
Como se muestra anteriormente, se proporciona el papel para cada tarea OVR codificador binario en un codificador, el codificador es la capa atención. Estas dos partes se logran directamente a través de la atención a nivel de red HAN (Yang, Zichao, et al ., 2016). La salida de cada atención capa atención a un re-entrada completa por capa de conexión binaria. Específicamente, para el documento \ (D \) y la categoría \ (K \) , el papel se calculó utilizando rasgo de clase específica HAN \ (a_k \) para la clasificación binaria:
En donde, \ (\ {texto} _K Encoder \) y \ (\ text {} A la atención de _i \) es la primera \ (K \) parámetros del codificador y la capa atención son \ (\ theta_ {e_k} \ ) y \ (\ theta_ a_k} {\) , cuyo documento \ (D \) se convierte en un vector \ (a_k \) . \ (W_k ^ T \) y \ ({w ^ { '} } _ k ^ T \) es el peso de la totalidad de los vectores de peso de la capa de conexión. función de pérdida clasificación binaria se puede expresar como el logaritmo de la verosimilitud negativa:
clasificación con varias categorías Estándar
Además, \ (K \) grupo en donde \ (a_1, a_2, \ cdots , a_k \) también se utiliza para la clasificación multi-clase estándar:
Ese es el uso directo Softmax clasificación múltiple, pérdida de la función en este momento más de catálogo:
entrenamiento de combate
Con el fin de distinguir categorías específicas de características y función independiente de clase, el documento también utiliza la estrategia de entrenamiento de combate. modelo de la figura \ (Attn_ {adv} \) es un generador, \ (D \) es el discriminador. \ (Attn_ {adv} \) un \ (K \) da salida a un codificador como entrada y genera una correspondiente \ (K \) número contra instancias. El objetivo es determinar generador discriminador para generar instancias de confrontación de la que Encoder. Los artículos que los clasificadores de engañar, generador \ (Attn_ {adv} \) pueden aprender a extraer la categoría característica extraña. proceso de entrenamiento de combate se puede expresar de la siguiente manera:
En donde \ (a_ {adv} (k ) \) es el generador de la primera \ (K \) categorías generado contra ejemplo, \ (Z_K ^ J \ in \ {0,1 \} \) indica si la muestra la primera \ (K \) de clase, \ (v_i \) es un discriminador de parámetro, \ (\ lambda \) es un super-referencia. \ (P_D (j | k) \) es un proceso de clasificación discriminador, \ (L_ {ADV} \) está en contra de la pérdida de aprendizaje.
En este caso, el modelo puede aprender a extraer y característica película independiente clase separada categoría específica, es decir, \ (\ text {A la atención} _i \) con capacidad de salida específica \ (K \) información de clase, \ (\ {texto} _ {A la atención adv} \) características de salida de clase independiente, caracterizado porque parte del caso removidos para poner el independiente clase. Mientras tanto, a fin de evitar características de clase específicos incluyen la película independiente de clase, el documento también cuenta con las dos restricciones ortogonales. En el período de pronóstico, sólo ciertas categorías de características serán utilizados para la clasificación.
función de pérdida
características independientes tipo de pérdida de ortogonalidad clase de restricción y funciones específicas pueden expresarse como:
El modelo final es una combinación lineal de la pérdida de función de cuatro pérdida:
Lo cual, \ (\ alfa, \ beta, \ gamma, \ Delta \) son hiper-parámetros.
experimento
Este trabajo utiliza dos gran escala conjunto de datos de clasificación de texto, conjunto de datos caso como sigue:

Los resultados se muestran a continuación:

