directorio
sistema de medición del riesgo de crédito incluye un cuerpo y modelos de calificación de calificación de la deuda principal de dos partes. Calificaciones y el cuerpo tiene una serie de calificación de la deuda modelo de calificación, donde los modelos de calificación cuerpo disponibles "cuatro cartas" para representar, respectivamente, una tarjeta A, tarjetas B, C F tarjetas y tarjetas; la deuda modelo calificación general de acuerdo con los propósitos de financiación corporal , dividido en modelo de finanzas corporativas, modelo de financiación el flujo de caja y el modelo de financiación del proyecto. Nos centramos en el proceso de desarrollo de los principales modelos de calificación.
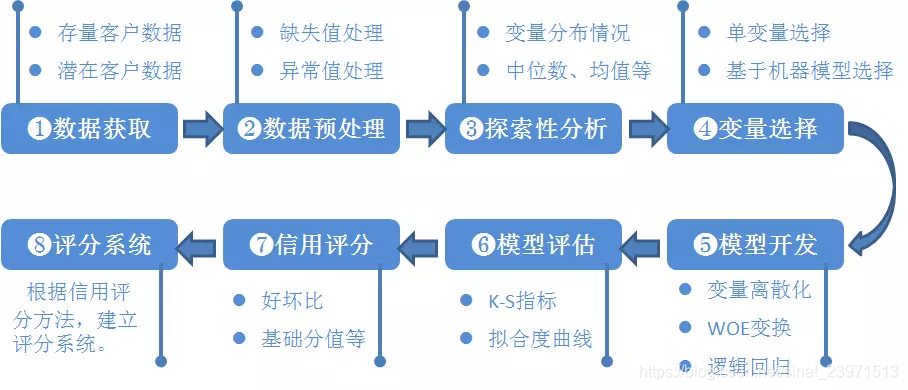
En primer lugar, el proceso del proyecto
modelo de calificación de crédito típica se muestra en la Figura 1-1. El proceso principal riesgo de crédito para el desarrollo modelo de calificación son las siguientes:
(1) la adquisición de datos, incluido el acceso a los clientes existentes y los datos de los clientes potenciales. Los clientes actuales significa que el cliente ha de llevar a cabo las compañías de valores de clase financiación de las empresas relacionadas, incluyendo clientes individuales e institucionales; potencial cliente es un cliente en el futuro se llevarán a cabo las empresas de financiación de valores de clase de negocios relacionados, incluyendo clientes institucionales, que consiste en resolver la industria de valores un menor número de muestras usadas comúnmente métodos, estos potenciales clientes institucionales, incluyendo las sociedades cotizadas, los emisores de bonos emitidos públicamente, tres empresas de nueva junta en la lista, las empresas que figuran centro de operaciones con acciones regionales, las instituciones financieras y otros no estándar.
(2) pre-procesamiento de los datos, los datos principales, incluyendo el trabajo de limpieza, valores, un procesamiento de valor anormal falta, principalmente con el fin de obtener los datos sin procesar en datos con formato se puede utilizar como el desarrollo del modelo.
(3) análisis exploratorio de datos, la etapa de obtener una muestra principalmente sobre la situación general, la situación general del histograma principal índice de descripción de muestra, caja, etc. FIG.
(4) selección de variables, el paso principalmente a través de los métodos estadísticos, seleccione el impacto más significativo en el índice de incumplimiento. Existen métodos de selección de características univariados y modelo de máquina de aprendizaje.
(5) el modelo de desarrollo, las variables que incluyen la etapa de segmentación, las variables de la aflicción (peso de la prueba) en tres partes y la estimación de regresión logística.
(6) modelo de evaluación, este paso es distinguir principalmente modelo de capacidad de evaluación, capacidad de predicción, la estabilidad, y el informe de evaluación del modelo de formación concluyó que si el modelo se puede utilizar.
(7) puntuación de crédito, cuenta de crédito se determina según el método de coeficientes de regresión logística y similares AY. Convertir Modelo logístico en forma de puntuaciones estándar.
(8) establecer un sistema de puntuación basado en métodos de calificación de crédito, establecer un sistema de puntuación de crédito automático.
PD: a veces el nombre de conveniencia, los números de referencia correspondientes variables de sustitución
En segundo lugar, la adquisición de datos
Los datos de la Kaggle Dame de S Algunos de Credit , hay 150.000 de datos de ejemplo, la siguiente figura se puede ver la situación general de estos datos.
Los datos son los préstamos de consumo personales, sólo puede ser considerado cuando se utiliza la puntuación de crédito, la implementación final de algunos aspectos de los datos debe ser de la siguiente manera obtener los datos:
- propiedades básicas incluyen: la edad del prestatario en el momento.
- Solvencia: incluyendo el ingreso mensual del prestatario, ratio de deuda.
- Las operaciones de crédito: el número de 35-59 días de mora dentro de dos años, el número de 60-89 días pasados por un plazo de dos años, dentro de los 90 años
el número de días o mayor de 90 días de mora.
- Condiciones de almacenamiento: incluyendo el número de crédito abierta y préstamos, préstamos de bienes raíces o la cantidad de crédito.
- Préstamo propiedades: No.
- Otros factores incluyen: la cantidad de miembros de la familia del prestatario (no incluido yo mismo).
- Ventana de tiempo: argumentos Ventana Inspección durante los últimos dos años, la variable dependiente es el rendimiento de la ventana de los próximos dos años.

3. pre-procesamiento de datos
Antes de procesar los datos, la necesidad de comprender los valores atípicos de datos y situación de los valores perdidos. No describen el pitón () función, conjunto de datos puede comprender los valores que faltan, media y la mediana y similares.
#载入数据
data = pd.read_csv('cs-training.csv')
#数据集确实和分布情况
data.describe().to_csv('DataDescribe.csv')
Los detalles del conjunto de datos:

Los valores de la figura, la presencia y ausencia de NumberOfDependents MonthlyIncome variables, variable total MonthlyIncome faltan 29731, NumberOfDependents 3924 tiene valores que faltan.
3.1 valores perdidos
Esta situación es muy común en los problemas del mundo real, que puede conducir a una serie de métodos analíticos no puede manejar los valores perdidos no se pueden aplicar, por lo tanto, el primer paso en el desarrollo de modelos de calificación de riesgo de crédito que va a ser los valores que faltan. Un método de tratamiento de los valores que faltan, incluyen los siguientes.
(1) eliminar una muestra que contiene los valores que faltan.
(2) para imputar valores basados en similitudes entre las muestras que faltan.
(3) para llenar los valores que faltan sobre la base de la correlación entre las variables.
falta MonthlyIncome tasa variable es relativamente grande, por lo que rellene los valores que faltan en base a la correlación entre las variables, se utilizó el método aleatorio forestal:
# 用随机森林对缺失值预测填充函数
def set_missing(df):
# 把已有的数值型特征取出来
process_df = df.ix[:,[5,0,1,2,3,4,6,7,8,9]]
# 分成已知该特征和未知该特征两部分
known = process_df[process_df.MonthlyIncome.notnull()].as_matrix()
unknown = process_df[process_df.MonthlyIncome.isnull()].as_matrix()
# X为特征属性值
X = known[:, 1:]
# y为结果标签值
y = known[:, 0]
# fit到RandomForestRegressor之中
rfr = RandomForestRegressor(random_state=0,
n_estimators=200,max_depth=3,n_jobs=-1)
rfr.fit(X,y)
# 用得到的模型进行未知特征值预测
predicted = rfr.predict(unknown[:, 1:]).round(0)
print(predicted)
# 用得到的预测结果填补原缺失数据
df.loc[(df.MonthlyIncome.isnull()), 'MonthlyIncome'] = predicted
return df
NumberOfDependents variable de los valores que faltan es relativamente pequeña, directa de eliminación, el modelo general no causa mucho impacto. Después de los valores que faltan se han procesado, eliminar duplicados .
data=set_missing(data)#用随机森林填补比较多的缺失值
data=data.dropna()#删除比较少的缺失值
data = data.drop_duplicates()#删除重复项
data.to_csv('MissingData.csv',index=False)
3.2 manejo de valores atípicos
Después de la finalización de los valores que faltan, también tenemos que hacer frente a los valores atípicos. Se refiere a los valores atípicos más significativamente de los valores de datos de muestra, tales como la edad del cliente individual es 0, el valor se considera en general valores atípicos. Identificar valores atípicos muestras en la población, por lo general los valores atípicos detectados.
En primer lugar, hemos encontrado 0 variable edad, el valor aparentemente anormal, salvo directamente:
# 年龄等于0的异常值进行剔除
data = data[data['age'] > 0]
Para NumberOfTime30-59DaysPastDueNotWorse variables, NumberOfTimes90DaysLate, NumberOfTime60-89DaysPastDueNotWorse estas tres variables, la siguiente se puede ver en la figura diagrama de caja 3-2, valores atípicos están presentes, y una función única que pueden existir en dos anomalías 96, 98 valor, fueron excluidos. 96, 98, que también eliminará valor de una variable encontrado, el valor de las otras dos variables 96, 98 se eliminará en consecuencia.
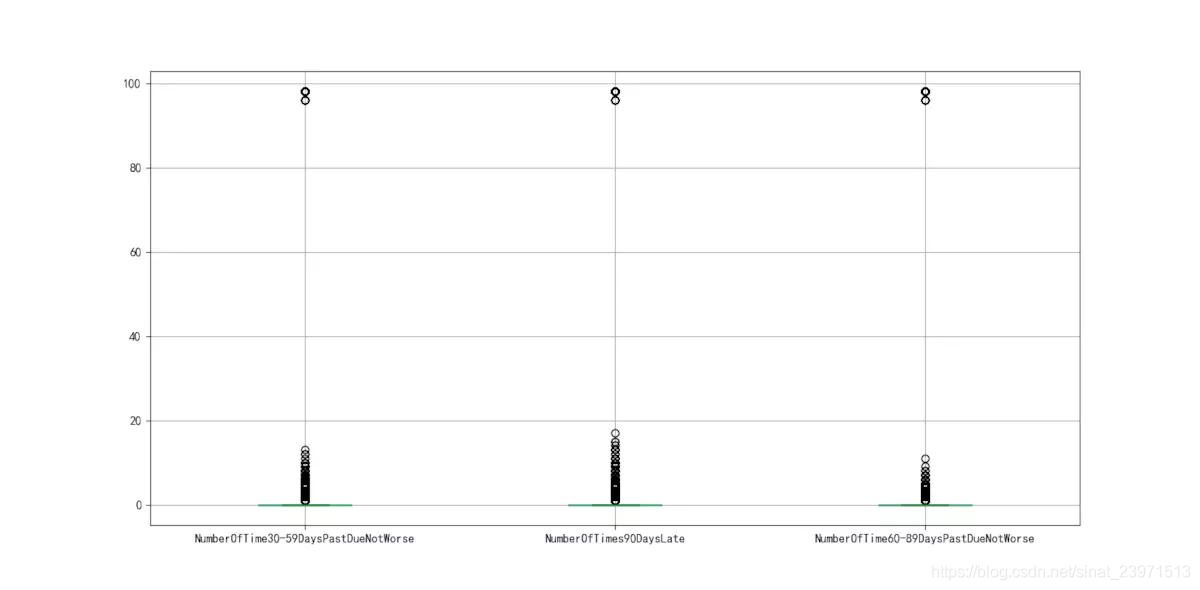
Excluyendo NumberOfTime30-59DaysPastDueNotWorse variables, NumberOfTimes90DaysLate, los valores extremos de NumberOfTime60-89DaysPastDueNotWorse. Además, los buenos datos de los clientes establecen en 0, el valor predeterminado es 1 cliente, teniendo en cuenta la comprensión normal de funcionamiento normal y pagan un interés del 1 al cliente, por lo que vamos a ser negada.
#剔除异常值
data = data[data['NumberOfTime30-59DaysPastDueNotWorse'] < 90]
#变量SeriousDlqin2yrs取反
data['SeriousDlqin2yrs']=1-data['SeriousDlqin2yrs']
segmentación de datos 3.3
Con el fin de verificar los resultados del modelo de ajuste, tenemos que ser conjunto de datos segmentada se divide en entrenamiento y prueba.
from sklearn.cross_validation import train_test_split
Y = data['SeriousDlqin2yrs']
X = data.ix[:, 1:]
#测试集占比30%
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.3, random_state=0)
# print(Y_train)
train = pd.concat([Y_train, X_train], axis=1)
test = pd.concat([Y_test, X_test], axis=1)
clasTest = test.groupby('SeriousDlqin2yrs')['SeriousDlqin2yrs'].count()
train.to_csv('TrainData.csv',index=False)
test.to_csv('TestData.csv',index=False)
