contenido
1. ¿Qué es un reptil?
2. ¿Por qué rastreadores web con Python
configuración del entorno de 3.python
4. Necesito saber lo que pre-conocimiento de reptil serpiente pitón
5. Acerca de las expresiones regulares
6. Extraer el contenido web y la expresión tratados con n
7.xPath y BeautifulSoup introducción
En pocas palabras, la sonda reptiles es una máquina, su funcionamiento básico consiste en simular el comportamiento humano a varios sitios de paseo, pequeños botones, buscar datos, información o para ver la parte de atrás de vuelta. Como un incansable insectos que se arrastran alrededor en un edificio.
Se puede imaginar fácilmente: todo reptil es su "avatar". Al igual que el Rey Mono sacó un puñado de pelos, soplar un montón de monos.
Que utiliza cada día Baidu, de hecho, el uso de la tecnología de este reptil: el día de la liberación innumerables reptiles a cada sitio, su información se vuelve otra vez, y luego la fila de buen equipo de maquillaje en espera de ser cargado.
Software para la califican de agarre, lo que equivale a extenderse numerosos compromisos, en cada avatar le ayudará a entrenar constantemente renovado sitio web de más de 12306 entradas. Una vez que un billete, sin contemplaciones, y luego gritas: Ven pago tirano.- desde el usuario a conocer la historia de casi
<- ... ->: Define el comentario
<! DOCTYPE>: Define el tipo de documento
<html>: total del documento etiqueta HTML
<head>: Define el Jefe
<body>: define el contenido web
<script>: Los scripts personalizados
<div>: división, definir particiones, las etiquetas del envase
<p>: párrafo, el párrafo definido
<a>: definir hipervínculos
<span>: define el contenedor de texto
<br>: envoltura
<form>: formulario personalizado
<table>: tabla de definición
<th>: encabezado definido
<tr>: fila de la tabla
<td>: columna de la tabla
<b>: definir negrita
<img>: imagen personalizada
Importación Re importación urllib.request importación del Chardet la Respuesta = el urllib.request.urlopen ( " http://news.hit.edu.cn/ " ) # parámetros de entrada para la página que desea rastrear la dirección URL del HTML = response.read () # html leer variable de chardet1 = chardet.detect (html) # adquiere codificación html = html.decode (chardet1 [ ' codifica ' ]) # procesa de acuerdo con la codificación adquirido
Aquí tenemos el sitio web de noticias oficial de una universidad como un ejemplo para demostrar el funcionamiento de reptiles pitón, sólo unas pocas líneas de código anterior se logrará el rastreo de contenido web para operaciones locales.
El siguiente es el contenido de la arrastró hasta el procesamiento de expresiones regulares, obtenemos lo que queremos llegar a observar el código fuente de la página:

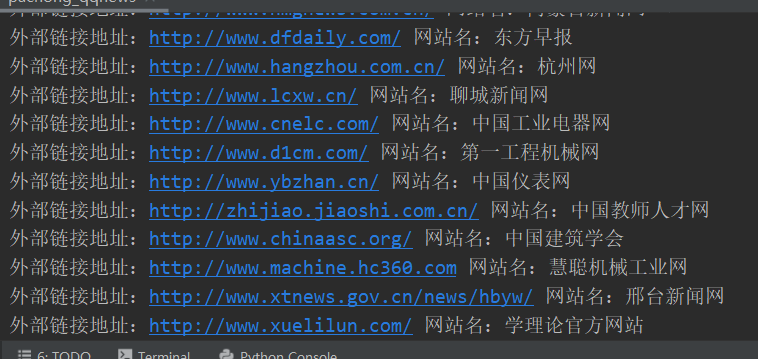
Esperamos que los enlaces externos, que se corresponden con la expresión regular antes de que el conocimiento aprendido a lograr lo siguiente:
mypatten = " <li class = \" link-elemento \ "> <a href=\"(.*)\"> <span> (. *) </ span> </a> </ li> " milista = re.findall (mypatten, html) para i en mylist: impresión ( " 外部链接地址:% s网站名:% s " % (i [0], i [1]))
El efecto resultante es:
7.xPath y BeautifulSoup introducción
Además de los documentos de la tela de procesamiento de expresiones regulares obtenidos por, también podemos considerar su propia arquitectura de la web.
XPath, nombre completo de la Lengua XML Path, a saber XML Path Language, es un hallazgo información en un lenguaje documento XML. XPath fue diseñado originalmente para buscar documentos XML, pero también se aplica a la búsqueda de documentos HTML.
nombredenodo seleccionar todos los nodos del hijo de este nodo
nodo secundario directo / nodos de la corriente seleccionada
// Seleccionar nodo descendiente del nodo actual
. Seleccione el nodo actual
.. seleccionar el nodo padre del nodo actual
@ atributo de selección
Aquí una lista de reglas de concordancia comúnmente XPath, por ejemplo / representantes seleccionados nodo hijo directo que representa el seleccionado // todo descendiente nodos representante de seleccionar el nodo actual, el nodo actual .. se añade nodo padre seleccionado Representante @ atributo definir, seleccionando un nodo de atributos específicos que coinciden.
de lxml importación etree importación urllib.request importación Chardet respuesta = urllib.request.urlopen ( " https://www.dahe.cn " ) html = response.read () chardet1 = chardet.detect (html) html = html.decode (chardet1 [ ' codifica ' ]) etreehtml = etree.HTML (html) mylist = etreehtml.xpath ( " / html / cuerpo / div / div / div / div / div / ul / div / li " )
BeautifulSoup4 reptil aprenderá habilidades. BeautifulSoup función principal es obtener los datos de la web, Beautiful Soup convierte automáticamente a Unicode codifica documento de entrada, el documento se convierte a una salida UTF-8 codificado. BeautifulSoup es compatible con la biblioteca estándar de Python del analizador de HTML también es compatible con analizador de terceros, si no lo instale, el valor por defecto de Python Python utiliza el analizador, el analizador lxml más potente, más rápido, recomendado lxml resolución dispositivo.
de BS4 importación del BeautifulSoup Archivo = Abierto ( ' ./aa.html ' , ' RB ' ) HTML = File.read () BS = la BeautifulSoup (HTML, " html.parser " ) # hendidura de impresión (bs.prettify () ) # estructura de formato html impresión (bs.title) # obtener el nombre de la etiqueta del título de impresión (bs.title.name) # obtener la etiqueta del título del texto Imprimir (bs.title.string) # todo el contenido de etiqueta de la cabeza adquisición de impresión ( bs.head) #Obtener todos los contenidos de la primera etiqueta div de impresión (bs.div) # obtener un primer valor de la etiqueta div id de impresión (bs.div [ " Identificación " ]) # Get todo el contenido de una etiqueta a una impresión (bs.a) # obtener todos los contenidos de todas las etiquetas en una impresión (bs.find_all ( " a " )) # Get = ID "U1" Imprimir (bs.find (ID = " U1 " )) # recuperar todos una etiqueta y un valor de desplazamiento de impresión de etiquetas href para el artículo en bs.find_all ( " un " ): Imprimir (item.get ( " href ")) # Obtener todos una etiqueta, e imprimir un valor de desplazamiento texto de la etiqueta para el artículo en bs.find_all ( " un " ): Imprimir (item.get_text ())
<- ... ->: Define el comentario
<! DOCTYPE>: Define el tipo de documento
<html>: total del documento etiqueta HTML
<head>: Define el Jefe
<body>: define el contenido web
<script>: Los scripts personalizados
<div>: división, definir particiones, las etiquetas del envase
<p>: párrafo, el párrafo definido
<a>: definir hipervínculos
<span>: define el contenedor de texto
<br>: envoltura
<form>: formulario personalizado
<table>: tabla de definición
<th>: encabezado definido
<tr>: fila de la tabla
<td>: columna de la tabla
<b>: definir negrita
<img>: imagen personalizada