En este artículo se describe el marco Scrapy cupones que se arrastran libro de información, y escribe la base de datos del resultado de MySQL.
Directorio artículo
- marco 1 Scrapy
- 2. Uso básico
- 3. Scrapy de combate: los datos de rastreo de productos Dangdang
- 3.1 Análisis del campo Nombre del libro
- 3.2 Revisión de análisis del segmento digital de Libros
- Análisis del campo de enlace 3,3 del producto
- URL cambia de 3,4 páginas diferentes de análisis
- 4. El código completo
Es necesario instalar el paquete:
- pip instalar la rueda
- pip instalar trenzado
- pip instalar lxml
- pip instalar scrapy
Anaconda instalación recomendada Prompt.
marco 1 Scrapy
1.1 Introducción
Scrapy es un sitio web para el rastreo de datos, extraer datos estructurado escrito marco de aplicación. Las aplicaciones pueden incluir la extracción de datos del programa, procesada o almacenada en una serie de datos históricos.
Fue pensado originalmente para rastrear la página (más precisamente, el rastreador web) diseñado, sino que también puede ser utilizado en la obtención de los datos devueltos por el API (como Amazon Web Services Associates) o de propósito general rastreador web.
Comandos comunes 1.2
scrapy startproject tutorial: Crear un proyecto rastreador;scrapy genspider -l: Ver la plantilla de reptiles;scrapy genspider -t basic example example.com(Ejemplo): plantillabasic, reptiles nombre de archivoexample, el nombre de dominioexample.com;scrapy crawl: Ejecutar reptiles;scrapy list: Lista proyecto actual todos disponibles araña. Cada línea de salida de una araña.
2. Uso básico
1. Abra una línea de comandos, introduzca el siguiente comando para crear el proyecto scrapy
scrapy startproject FirstProject
2. Proyecto de estructura de directorios

3. Ir al proyecto, consulte la plantilla de reptiles:
>cd FirstProject
>scrapy genspider -l
Available templates:
basic
crawl
csvfeed
xmlfeed
4. Crear reptiles, nota que el nombre de dominio no incluye el nombre de host ; (. Como www)
Por ejemplo, supongamos que se arrastra sitio CCTV5 vídeo del fútbol mundial en: http://tv.cctv.com/lm/txzq/videoset/ , generar también puede modificar posteriormente en el programa, mal no importa, basta con modificar el programa cuando hay un campo de la nota es el nombre de dominio.
>scrapy genspider -t basic first cctv.com/lm/txzq/videoset/
Created spider 'first' using template 'basic' in module:
FirstProject.spiders.first
Crear un documento bueno:

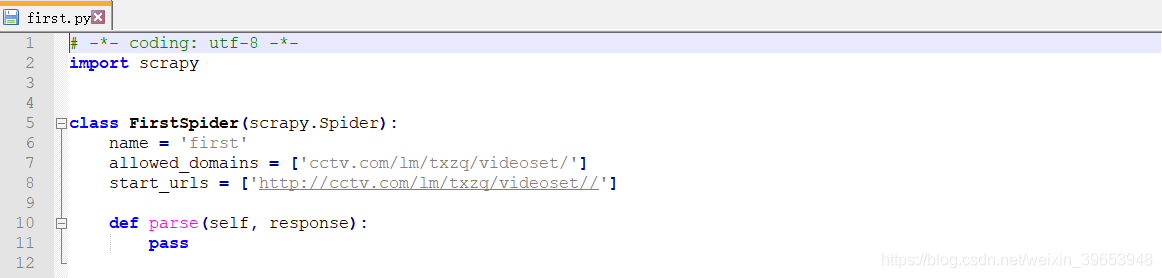
5. reptiles Run
>scrapy crawl first
6. Revisar el reptil disponibles en la actualidad
>scrapy list
7. Ver la instrucción scrapy
>scrapy
3. Scrapy de combate: los datos de rastreo de productos Dangdang
Escribir un proceso de proyecto reptiles Scrapy:
- Crear un proyecto rastreador;
- artículos de escritura;
- Crear un archivos de oruga;
- Para escribir un archivo de reptiles;
- tuberías de escritura;
- Los valores de configuración;
Dangdang libros de informática como Home: http://category.dangdang.com/cp01.54.26.00.00.00.html
3.1 Análisis del campo Nombre del libro
Al abrir la página, haga clic en el espacio en blanco, ver el código fuente de la página, encontrará los siguientes campos, a través de análisis y los resultados de búsqueda, puede determinar que el campo contiene la información del título del libro. Los comentarios pueden ser posicionados por el número de interfaz de los productos básicos, y luego determinar el campo contiene el nombre del producto.
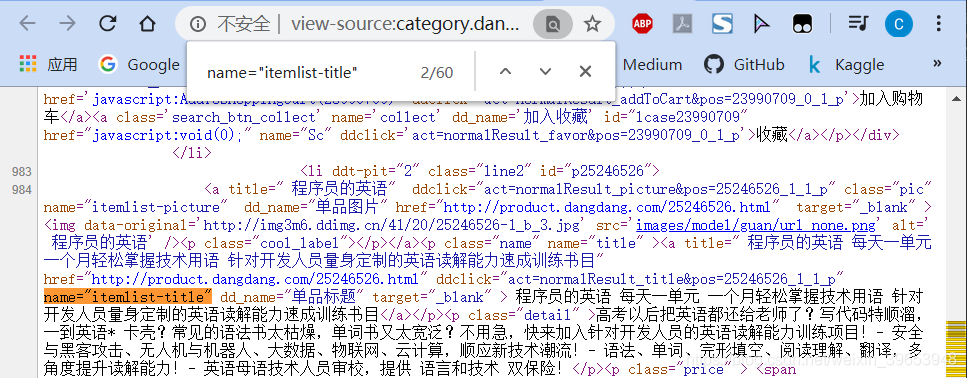
3.2 Revisión de análisis del segmento digital de Libros
Después de analizar los libros campo Nombre, analizar los comentarios segmento digital, a través de la búsqueda, se puede determinar el siguiente campo es un campo que contiene una serie de reseñas de productos, podemos utilizar este campo para construir una expresión regular.
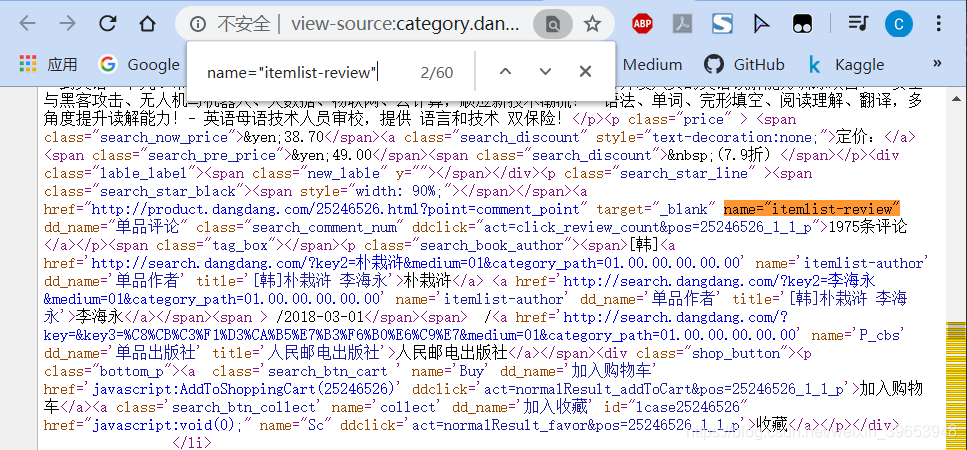
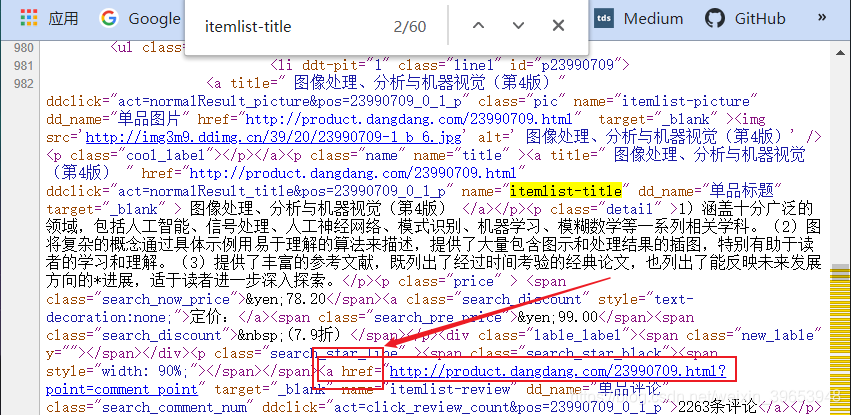
Análisis del campo de enlace 3,3 del producto
Después del análisis podemos saber, vincular campo de atributo href contiene el campo de nombre de producto, por lo que puede usar esto para construir una expresión regular.
URL cambia de 3,4 páginas diferentes de análisis
Dangdang resultados por página 60, si usted necesita para convertir el procesamiento de la página es necesario analizar los números de página URL variación. En primer lugar, la página web enlaces 1-5 pegado en documento de Word, para facilitar la comparación, el URL de la página se muestra en la siguiente figura diferente:

que sólo pueda ver pgel campo ha cambiado, pero la primera página no contiene este campo, podemos presente supongo, la primera URL de la página es: http://category.dangdang.com/pg1-cp01.54.26.00.00.00.html , si se abre la imagen de arriba para abrir la URL en la primera página de la interfaz es la misma, se puede demostrar nuestra conjetura es correcta. Probada, de hecho, podríamos construir la página cambia, los cambios de la URL.
4. El código completo
proyecto rastreador 4.1 Creación
scrapy startproject dangdang
cd dangdang
scrapy genspider dd_books dangdang.com
4.2 modificar el archivo items.py
import scrapy
class DangdangItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
link = scrapy.Field()
comment = scrapy.Field()
4.3 modificar / crear reptil archivo dd_books.py
import scrapy
from dangdang.items import DangdangItem
from scrapy.http import Request # 实现翻页
class DdBooksSpider(scrapy.Spider):
name = 'dd_books'
allowed_domains = ['dangdang.com']
start_urls = ['http://category.dangdang.com/pg1-cp01.54.26.00.00.00.html']
def parse(self, response):
item = DangdangItem()
item["title"] = response.xpath("//a[@name='itemlist-title']/@title").extract()
item["link"] = response.xpath("//a[@name='itemlist-title']/@href").extract()
item["comment"] = response.xpath("//a[@name='itemlist-review']/text()").extract()
yield item
for i in range(2, 3):
url = "http://category.dangdang.com/pg"+str(i)+"-cp01.54.26.00.00.00.html"
yield Request(url, callback=self.parse)
pipeline.py escrita 4.4 archivo
En esta sección se implementa una operación de escritura PyMySQL la base de datos, si no es necesario configurar la configuración de MySQL, si no quiere escribir, esta parte de la observación a cabo muy bien.
import pymysql
class DangdangPipeline(object):
def process_item(self, item, spider):
conn = pymysql.connect("localhost", "root", "mysql105", "ddbooks", charset='utf8')
for i in range(0, len(item["title"])):
title = item["title"][i]
link = item["link"][i]
comment = item["comment"][i]
sql = "insert into dangdang(title, link, comment) values('"+title+"', '"+link+"', '"+comment+"')"
conn.query(sql)
conn.commit()
conn.close()
return item
4.5 Modificar setting.py
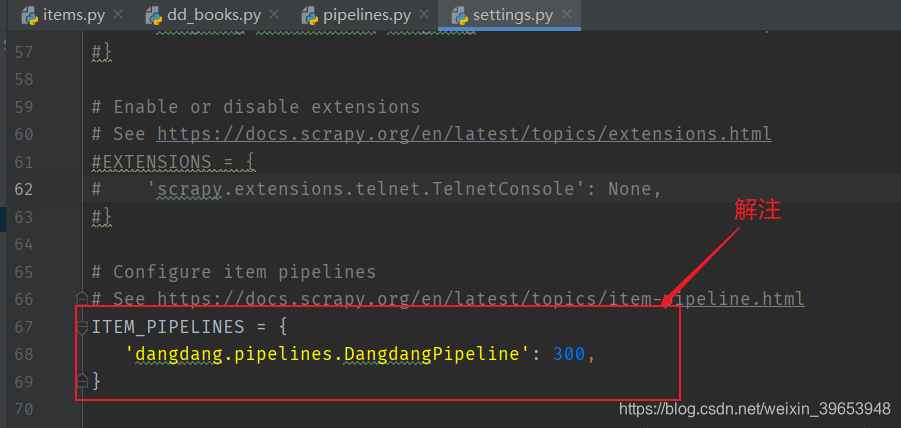
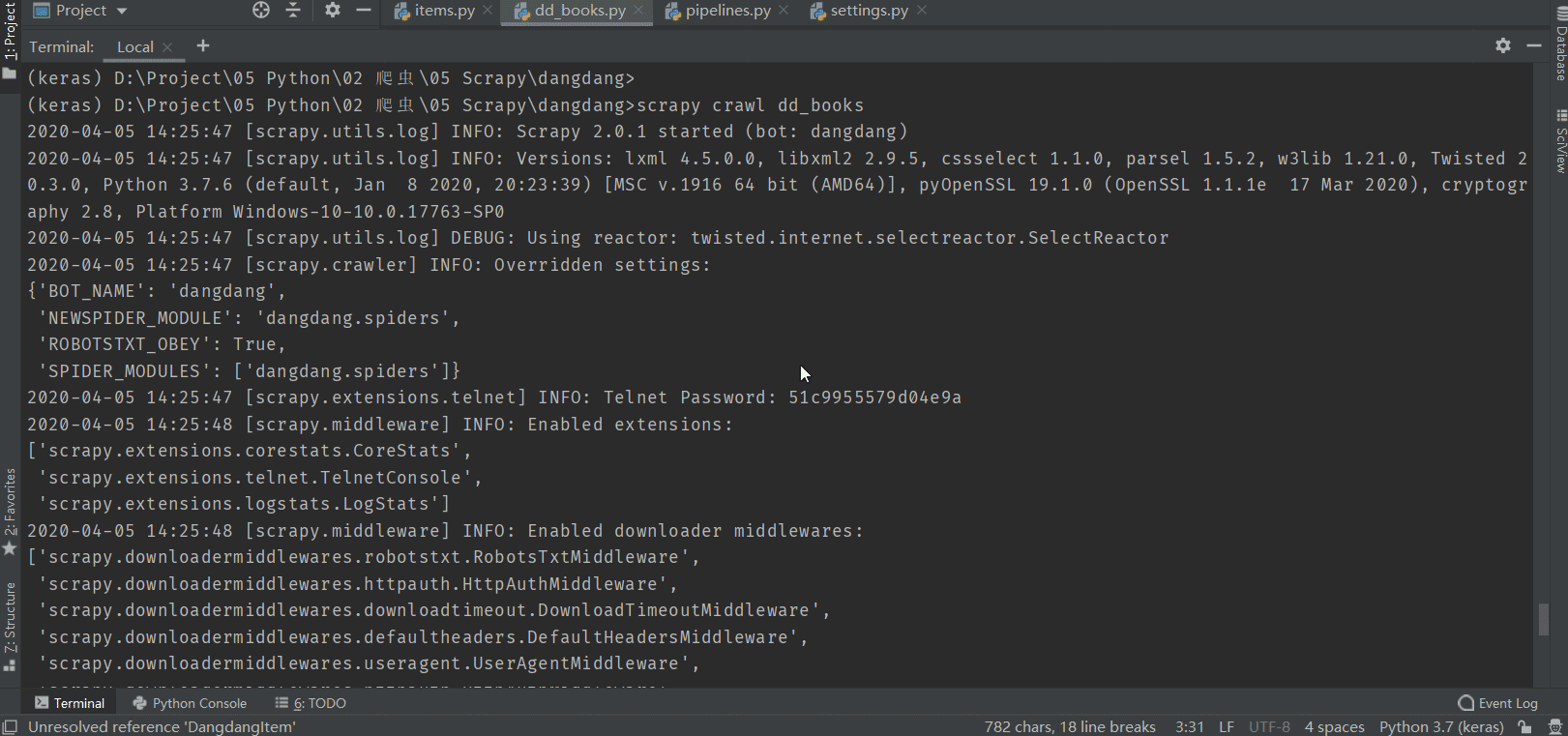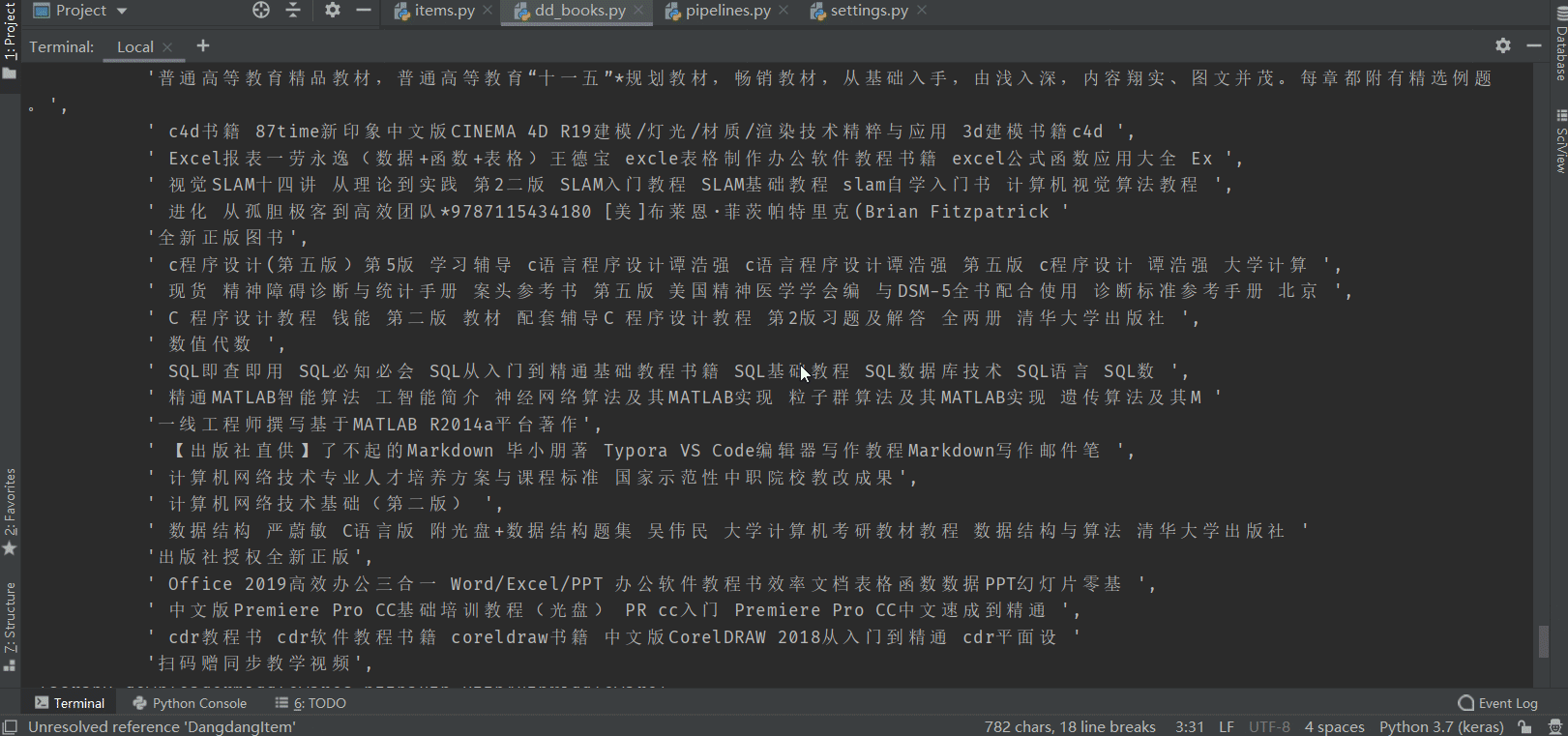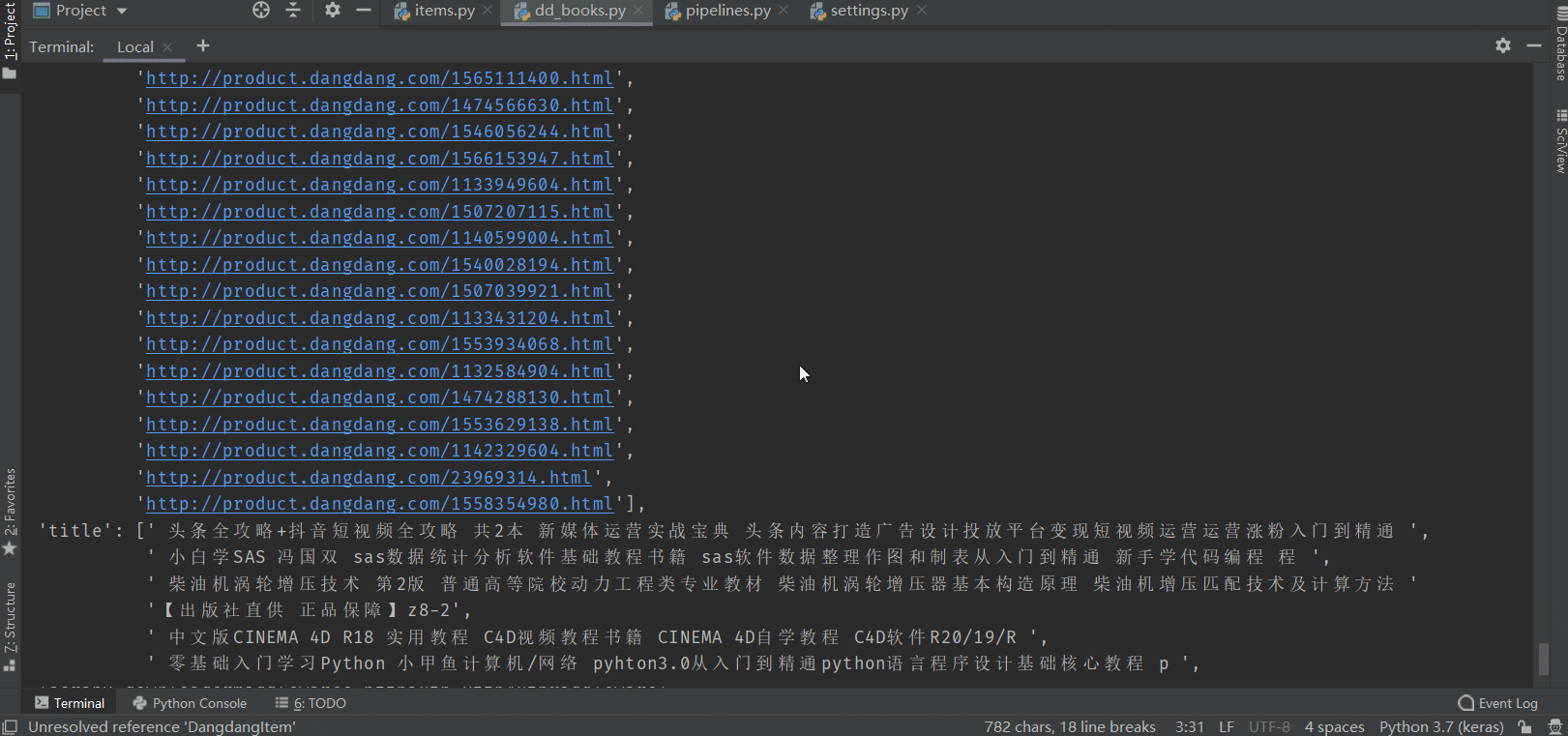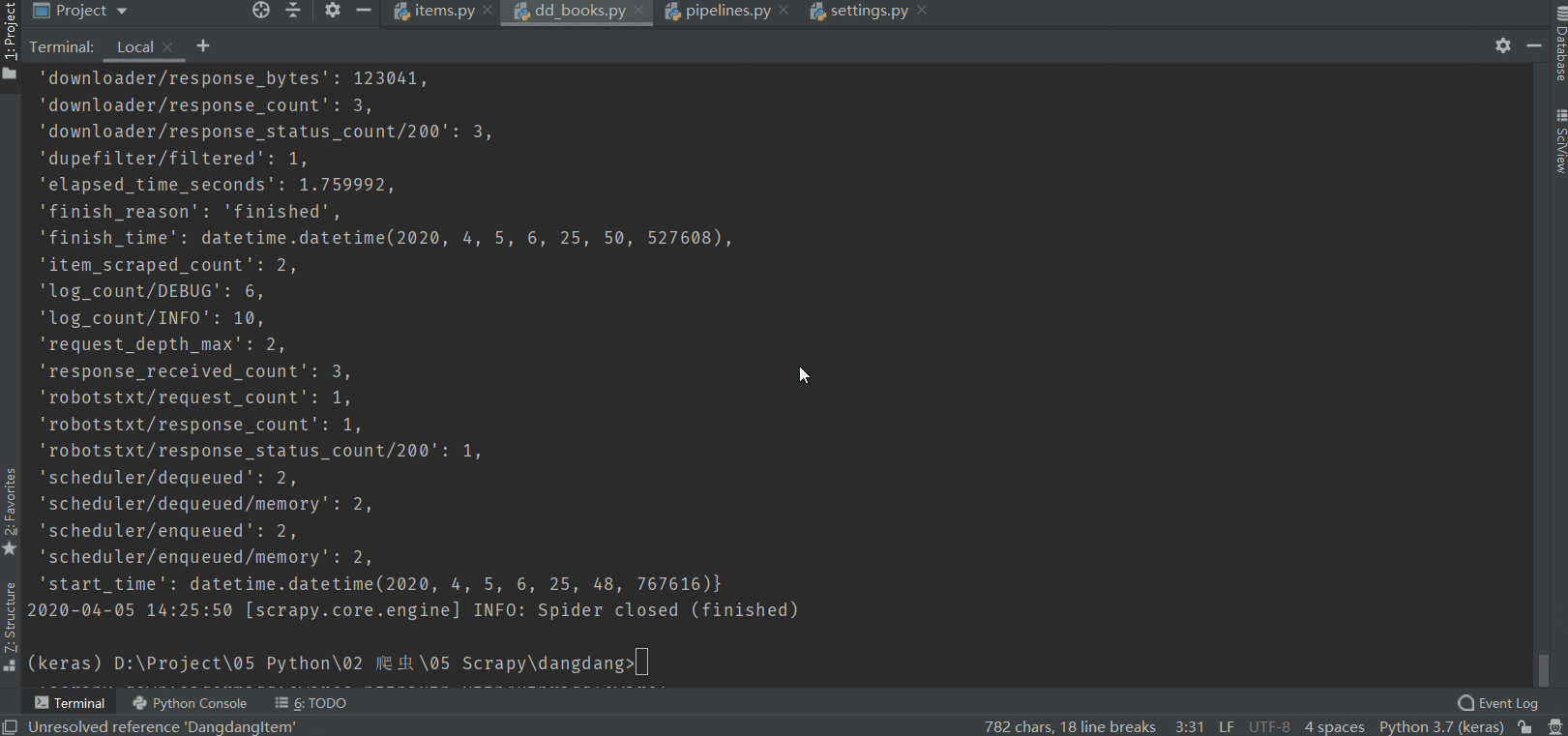
4.6 línea de comandos para iniciar el rastreador
(keras)D:\Project\05 Python\02 爬虫\05 Scrapy\dangdang>scrapy crawl dd_books
salida:

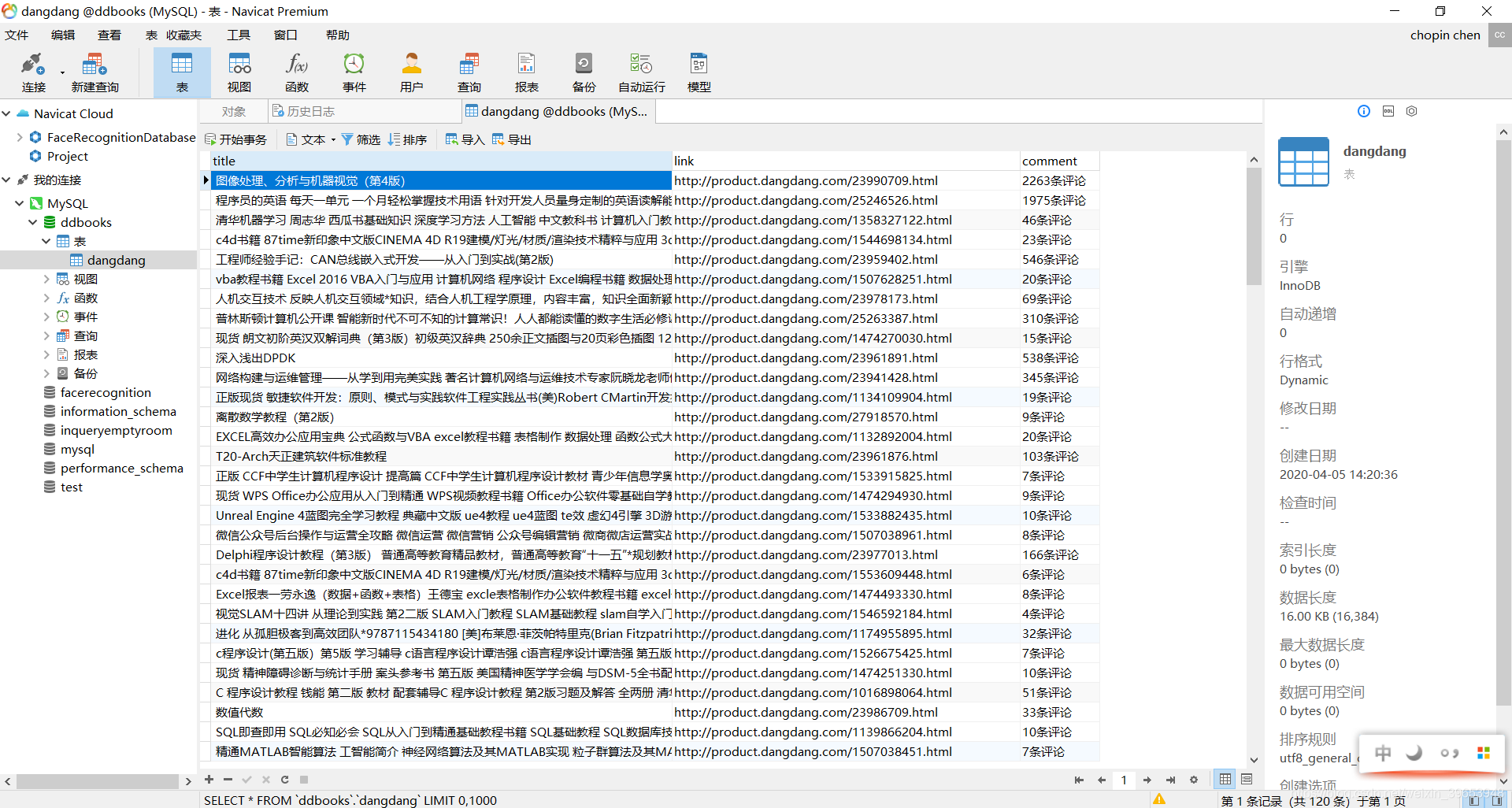
resultados de base de datos:
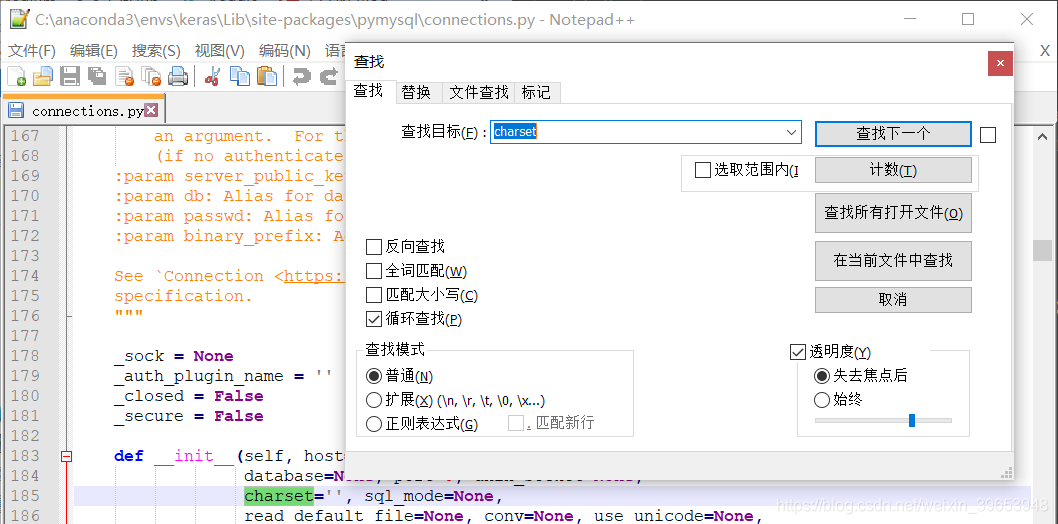
Nota: Las conexiones del módulo de modificación pymysql, para evitar la distorsión, set de juego de caracteres utf8, no UTF-8!
Referencia:
documento oficial Scrapy: https://doc.scrapy.org/en/latest/intro/tutorial.html
Scrapy chino documento: https://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
cursos relacionados: https://edu.aliyun.com/course/1994
