Prefacio:
Recientemente aprendido algunas sintaxis básica pitón, sino también seguir los maestros Liao Xuefeng utilizan marco IO asíncrona para construir un sitio web sencillo (aunque algunos todavía no entienden), pero poco a poco, Python es también un lugar divertido para los reptiles de escritura, mientras con tiempo suficiente ahora para aprender acerca de usted, recomendar un mono pequeño círculo cursos son particularmente buen maestro
0x00: Aprenda reptiles
En la clasificación de escenario de uso reptiles
-通用爬虫:
agarrar una parte importante del sistema. Rastreo es una página entera de datos.
-聚焦爬虫:
se basa en los reptiles comunes, agarra un contenido local específica de la página.
-增量式爬虫:
actualiza los datos de los sitios de monitoreo, y la sabiduría para arrastrarse fuera del sitio de los datos más recientes actualizaciones
反爬机制: Portal, mediante agitando pueden desarrollar estrategias adecuadas para prevenir reptil reptiles datos despertó sitio web.
反反爬策略: Rastreadores también se puede desarrollar estrategias o técnicas pertinentes, para romper contra la subida del mecanismo de portales tienen, a los datos de adquirir en el portal.
robots.txtAcuerdo:pacto de caballeros. El sitio web proporciona datos que pueden ser reptiles que los datos no se pueden rastrear
0x01: http y https protocolo
http protocolo:
Servidor y el cliente como una forma de intercambio de datos
cabeceras de petición comunes:
User-Agent:请求载体的身份标识
Connection:请求完毕后,是断开连接还是保持连接
información de la cabecera común en respuesta a:
Content-Type: 服务器响应回客户端的数据类型
el protocolo https
protocolo de transferencia de hipertexto seguro, que implica el cifrado de datos
encriptación:
- claves de cifrado simétrico
- clave secreta de cifrado asimétrico
- claves de cifrado del certificado
claves de cifrado simétrico
El cliente cifra los primeros datos, y la clave y el texto cifrado se envía junto con el servidor, el servidor utilizando una llave para abrir el texto cifrado.
Desventajas: fácil de interceptar insegura
clave secreta de cifrado asimétrico
Muestra: Demostración de RSA este
claves de cifrado del certificado

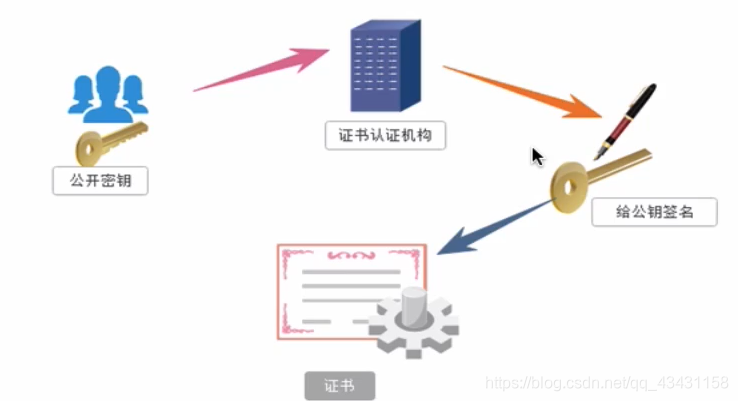
0x02: módulo de solicitud
requestMódulo es un módulo de Python solicitudes de red basadas forma nativa, muy potente y muy eficiente, el papel es simular un navegador inicia una petición, ya que es el navegador analógico para iniciar una solicitud, sería necesario requesthacer el mismo módulo y el navegador trabajo
requestproceso de codificación:
- URL especificada
- Iniciar una solicitud
- Obtener los datos de respuesta
- almacenamiento persistente
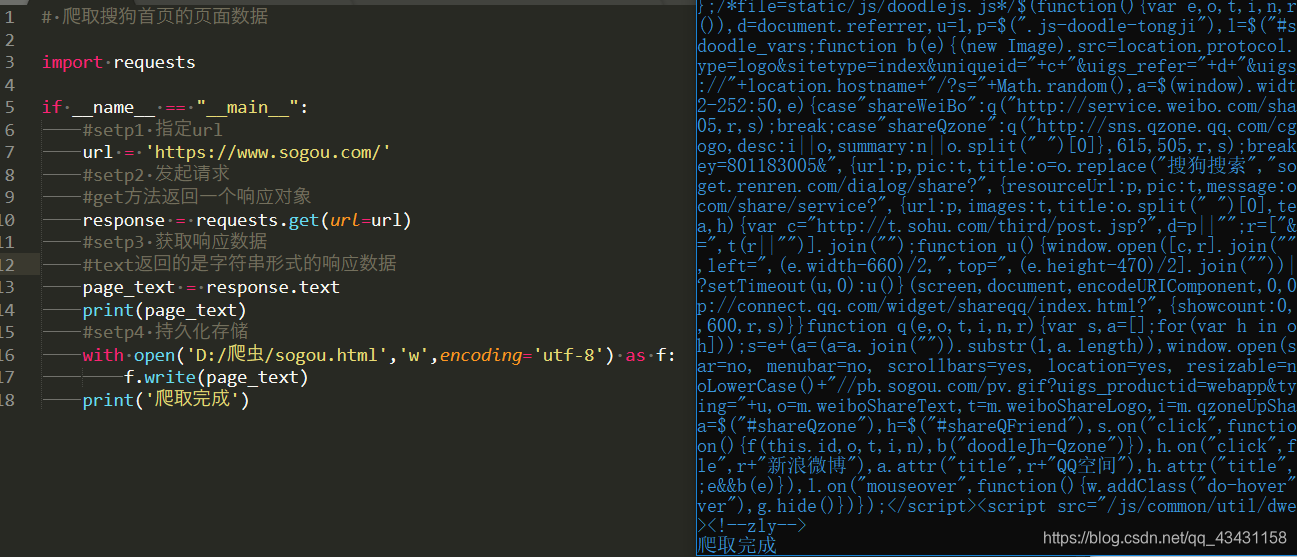
Ejercicio 1: arrastrándose Sogou datos de la página de inicio (flujo básico)
Código de rastreo:
# 爬取搜狗首页的页面数据
import requests
if __name__ == "__main__":
#setp1 指定url
url = 'https://www.sogou.com/'
#setp2 发起请求
#get方法返回一个响应对象
response = requests.get(url=url)
#setp3 获取响应数据
#text返回的是字符串形式的响应数据
page_text = response.text
print(page_text)
#setp4 持久化存储
with open('D:/爬虫/sogou.html','w',encoding='utf-8') as f:
f.write(page_text)
print('爬取完成')
respuesta:
Segundo ejercicio: colector web (GET)
Antes de escribir, es necesario comprender algunos de los mecanismos de lucha contra la subida:
UA: User-Agent (identidad de la identificación del vehículo requirente)
UA检测: El servidor detecta la solicitud portal correspondiente de la identidad del transportista, si detecta la identidad de la petición del portador para un cartel con un navegador, la petición es una petición normal, sin embargo, si se detecta un portador de identidad identidad de la solicitud no se basa en navegador párrafo, entonces la petición no es una petición normal (reptiles), el servidor es probable que rechazar los tiempos de solicitud.
UA伪装: El paquete de agente de usuario correspondiente a un diccionario, se añade el código.
Aquí se arrastra Sogou navegador

como en la búsqueda de Arte espada, seguido por un grupo de parámetros, pero no es un parámetro queryparticularmente evidente, este argumento es que queremos consulta, dejando sólo los parámetros que se encuentran o se pueden consultar en la siguiente dirección URL especificar mejor
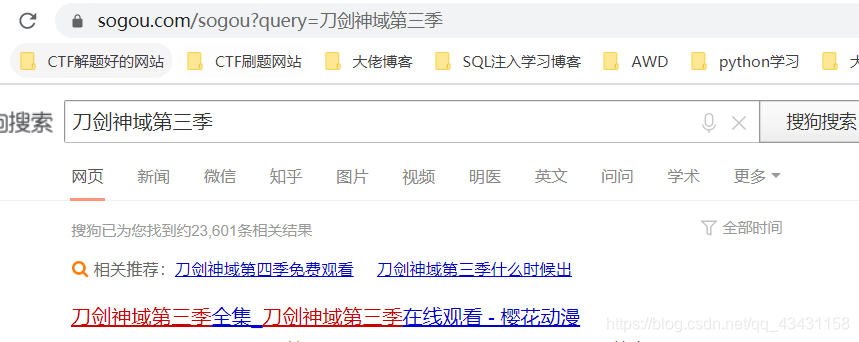
Además, también tenemos que añadir el camuflaje UA, prevenir la negación

Aquí está a escribir código que se arrastran:
import requests
if __name__ == "__main__":
#UA伪装,封装到一个字典中
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
#指定url
url = "https://www.sogou.com/sogou"
#自定义参数
kw = input('please input param')
#将参数封装到字典中
param = {
'query': kw
}
#发起请求,第二个参数将自定义的参数传进去,第三个参数传入header
reponse = requests.get(url=url,params=param,headers=header)
#获取响应信息
page_text = reponse.text
#保存信息
fileName = kw+'.html'
with open(fileName,'w',encoding='utf-8') as f:
f.write(page_text)
print("爬取成功")
Arrastrándose éxito

si se va a rastrear otros contenidos sólo se necesita cambiar los parámetros
Ejercicio tres: grieta traducción Baidu (Post)
Antes de escribir primero debe buscarAjax
AJAXEs una tecnología para la creación de páginas web dinámicas rápidamente.
Mediante el intercambio de pequeñas cantidades de datos con el servidor en segundo plano, AJAX puede hacer actualizaciones de la página asíncronos. Esto significa que, para ciertas partes de la página que se actualizan sin necesidad de recargar la página completa
Traducción abierta Baidu, refresco de página parcial encontrado, utilizado aquí Ajax, la solicitud se realiza correctamente después de una actualización será local, por lo que siempre que la captura de la correspondiente Ajaxsolicitud, los resultados se pueden almacenar en la traducción correspondiente de jsonun archivo de texto, que
¿Por que se almacena en jsonun archivo de texto que captan lo que el servidor devuelve la información se puede saber

al lado fue a capturar Ajaxla solicitud, tales como entrada dog, para capturar los parámetros correspondientes, a continuación, escribir el código de rastreo
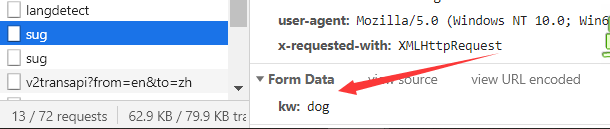
import requests
import json
#指定post的url
post_url = 'https://fanyi.baidu.com/sug'
#UA伪装
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
#自定义post参数
word = input('please input')
data = {
'kw': word
}
#发起请求
post_response = requests.post(url=post_url,data=data,headers=headers)
#获取响应
#注:获取响应数据json()方法返回的是obj(如果确认响应数据是json,才可以使用json())
dict_text = post_response.json()
# print(dict_text)
#保存数据
fileName = word+'.json'
fp = open(fileName,'w',encoding = 'utf-8')
#注:因为返回来的json串是中文的,所以ensure_ascii为false,不能使用ascii进行编码
json.dump(dict_text,fp=fp,ensure_ascii=False)
print('Finish')
arrastrándose éxito

Ejercicio cuatro: IMDb arrastrándose
Sólo pide un tipo de película, cuando se observa la siguiente para encontrar que cada vez que una página es de 20 películas, un poco más adelante se puede seguir viendo más películas no se muestran abajo de la página no hay ningún cambio, sólo parcial cambios, para que pueda capturar lo Ajaxpedido
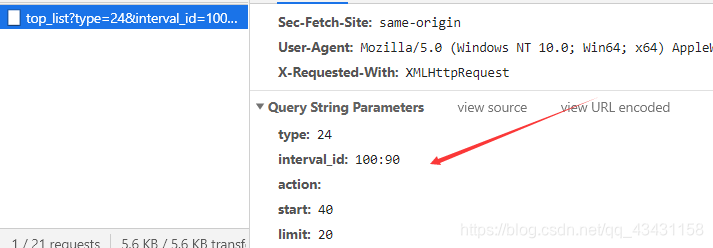
Ajaxestará llevando estos parámetros de la petición, ya que sabemos que la realización de qué parámetros, se puede escribir un script de rastreo
# 爬取豆瓣电影
import requests
import json
if __name__ =="__main__":
url="https://movie.douban.com/j/chart/top_list"
#参数
params = {
"type":"24",
"interval_id": "100:90",
"action":"",
"start": "0",
"limit": "20",
}
#UA伪装
headers={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36"
}
#请求
r=requests.get(url=url,params=params,headers=headers)
#反应
data=r.json()
#存储
fp = open("电影.json","w",encoding="utf-8")
#indent: 缩进(例如indent=4,缩进4格);
json.dump(data,fp=fp,ensure_ascii=False,indent=4)
print("爬取成功")
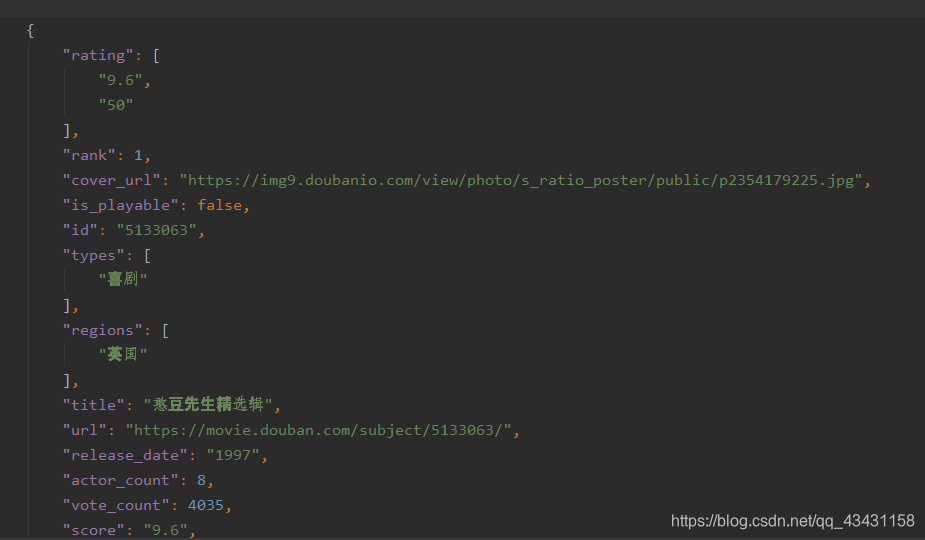
Trabajo: arrastrándose KFC ubicación del restaurante
Cuando un restaurante consulta, sólo ha cambiado una parte de la página, se puede determinar Ajax, por lo que la captura de lo que la solicitud
es por POSTmedio de una petición al

señalar aquí ya no es el jsontipo, sino más bien text,
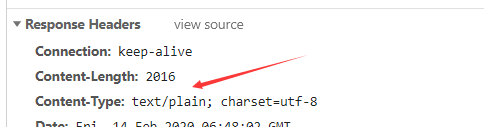
escribir reptiles Código:
import requests
if __name__ == "__main__":
url='http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.130 Safari/537.36'
}
key = input("Please enter the query address\n")
page = input("Please enter the query page number\n")
data = {
'cname':'',
'pid': '',
'keyword':key,
'pageIndex':page,
'pageSize': '10',
}
reponse = requests.post(url=url,data=data,headers=headers)
data = reponse.text
print(data)
fileName = key+'.txt'
with open(fileName,'w',encoding='utf-8') as fp:
fp.write(data)
print("爬取成功")
arrastrándose éxito

resumen:
Esto primero aprender aquí, aprender esta gran cosecha, el próximo disco será más divertido viaje reptil! !
