Las cadenas y tuplas son muy similares y no se pueden modificar fácilmente una vez que se definen
Si tiene que modificarlo, puede usar porciones y concatenaciones
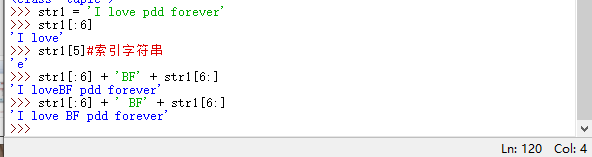
para que la cadena anterior str1 todavía esté allí, y se sobrescriba después de la asignación. El mecanismo de recolección de basura de Python eliminará las cadenas sin etiquetas.

Métodos integrados para cadenas
| método | sentido |
|---|---|
| capitalizar() | Cambie el primer carácter de la cadena a mayúsculas y todos los demás caracteres a minúsculas |
| casefold () | Todas las letras de la nueva cadena se vuelven minúsculas |
| centro (ancho, fillchar = '') | Devuelve una nueva cadena de caracteres centrada (ancho <= longitud de la cadena, nueva cadena = cadena original; ancho> ancho de la cadena, todos los caracteres están centrados, la izquierda y la derecha se rellenan con los caracteres especificados por el parámetro fillchar) |
| contar (sub [, inicio [, final]]) | Devuelve el número de apariciones no superpuestas de sub en la cadena. Los parámetros opcionales start y end se utilizan para especificar las posiciones inicial y final. |
| termina con (sufijo [, inicio [, final]]) | Si la cadena termina con la subcadena especificada por el sufijo, devuelva True; de lo contrario, devuelva False; los parámetros opcionales start y end se utilizan para especificar las posiciones inicial y final |
| expandtabs ([tabsize = 8]) | Devuelve una nueva cadena usando espacios para reemplazar las pestañas. Si no se especifica el parámetro de tamaño de pestaña, entonces 1 pestaña = 8 espacios por defecto |
| buscar (sub [, inicio [, final]]) | Busque la subcadena en la cadena y devuelva el valor de índice más bajo de la coincidencia; los parámetros opcionales start y end se utilizan para especificar las posiciones inicial y final; si la subcadena no coincide, devuelve -1 |
| unirse (iterable) | Concatenar varias cadenas y devolver una nueva cadena; use la cadena que llama a este método como separador e insértelo en el medio de cada cadena especificada por el parámetro iterable; |
| codificar (codificación = 'utf-8', errores = 'estricto') | Codifique la cadena en el formato de codificación especificado por el parámetro de codificación. El parámetro errors especifica la solución cuando ocurre un error de codificación: el 'estricto' predeterminado significa que si ocurre un error, se lanzará un UnicodeEncodeError. Otros valores de parámetro disponibles son 'ignorar', 'reemplazar' y 'xmlcharrefreplace' |
| formato (* argumentos, ** kwargs) | Devuelve una nueva cadena formateada; usa parámetros posicionales (args) y argumentos de palabras clave (kwargs) para reemplazar |
| format_map (mapeo) | Devuelve una nueva cadena formateada; usa parámetros de mapeo (mapeo) para reemplazar |
| índice (sub [, inicio [, final]]) | Busque la subcadena en la cadena y devuelva el valor de índice más bajo de la coincidencia; los parámetros opcionales start y end se utilizan para especificar las posiciones inicial y final; si la subcadena no coincide, se lanza una excepción ValueError |
| isalnum () | Si hay al menos un carácter en la cadena y todos los caracteres son letras o números, devuelve True; de lo contrario, devuelve False |
| isalpha () | Si hay al menos un carácter en la cadena y todos los caracteres son letras, devuelve Verdadero; de lo contrario, devuelve Falso |
| isascii () | Si todos los caracteres de la cadena son ASCII, devuelve Verdadero; de lo contrario, devuelve Falso; el rango de codificación de caracteres ASCII es U + 0000 ~ U + 007F, y la cadena vacía también es ASCII |
| isdecimal () | Si hay al menos un carácter en la cadena y todos los caracteres son números decimales, devuelve True; de lo contrario, devuelve False |
| isdigit () | Si hay al menos un carácter en la cadena y todos los caracteres son números, devuelve True; de lo contrario, devuelve False |
| Identificador () | Si la cadena es un identificador Python válido, devuelve Verdadero; de lo contrario, devuelve Falso; llame a keyword.iskeyword (s) para verificar si la cadena es un identificador reservado (como "si" o "para") |
| es bajo() | Si la cadena contiene al menos una letra inglesa que distingue entre mayúsculas y minúsculas, y todas estas letras son minúsculas, devuelve True, de lo contrario devuelve False |
| isnumeric () | Si hay al menos un carácter en la cadena y todos los caracteres son números, devuelve True; de lo contrario, devuelve False |
| imprimible () | Si la cadena es imprimible, devuelve True; de lo contrario, devuelve False |
| isspace () | Si hay al menos un carácter en la cadena y todos los caracteres son espacios, devuelva True; de lo contrario, devuelva False |
| lista () | Si la cadena es una cadena con título (todas las palabras comienzan con mayúsculas, el resto de las letras están en minúsculas), devuelve True, de lo contrario devuelve False |
| isupper () | Si la cadena contiene al menos una letra inglesa que distingue entre mayúsculas y minúsculas, y estas letras están todas en mayúsculas, devuelva True; de lo contrario, devuelva False |
| unirse (iterable) | Concatenar varias cadenas y devolver una nueva cadena; use la cadena que llama a este método como separador e insértelo en el medio de cada cadena especificada por el parámetro iterable; |
| brillante (ancho) | Devuelve una nueva cadena con caracteres alineados a la izquierda (ancho <= longitud de la cadena, nueva cadena = cadena original; ancho> ancho de cadena, todos los caracteres están alineados a la izquierda y el lado derecho se llena con los caracteres especificados por el parámetro fillchar) |
| inferior() | Devuelve una nueva cadena con todas las letras en inglés convertidas a minúsculas |
| lstrip (chars = None) | Devuelve una nueva cadena con los caracteres en blanco a la izquierda eliminados; el parámetro chars se puede usar para especificar la cadena que se eliminará |
| partición (sep) | Busque el separador especificado por el parámetro sep en la cadena. Si lo encuentra, devuelva una tupla de 3 ('la parte antes de sep', 'sep', 'la parte después de sep'); si no lo encuentra, devuelva ('Cadena original ',' ',' ') |
| removeprefix (prefijo) | Si existe la subcadena de prefijo especificada por el parámetro de prefijo, devuelve una nueva cadena con el prefijo eliminado; si no existe, devuelve una copia de la cadena original |
| removesuffix (sufijo) | Si hay una subcadena de sufijo especificada por el parámetro de sufijo, devuelve una nueva cadena con el sufijo eliminado; si no existe, devuelve una copia de la cadena original |
| reemplazar (antiguo, nuevo, recuento = -1) | 返回一个将所有 old 参数指定的子字符串替换为 new 的新字符串;count 参数指定替换的次数,默认是 -1,表示替换全部 |
| rfind(sub[, start[, end]]) | 在字符串中自右向左查找 sub 子字符串,返回匹配的最高索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,返回 -1 |
| rindex(sub[, start[, end]]) | 在字符串中自右向左查找 sub 子字符串,返回匹配的最高索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,抛出 ValueError 异常 |
| rjust(width, fillchar=’ ') | 返回一个字符右对齐的新字符串(width <= 字符串长度,新字符串 = 原字符串;width > 字符串宽度,所有字符右对齐,左侧使用 fillchar 参数指定的字符填充) |
| rpartition(sep) | 在字符串中自右向左搜索sep参数指定的分隔符,如果找到,返回一个 3 元组 (‘在sep前面的部分’, ‘sep’, ‘在sep后面的部分’);如果未找到,则返回 (’’, ‘’, ‘原字符串’) |
| rsplit(sep=None, maxsplit=-1) | 将字符串自右向左进行分割,并将结果以列表的形式返回;sep 参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit 参数用于指定分割的次数(注意:分割 2 次的结果是 3 份),默认是不限制 |
| rstrip(chars=None) | 返回一个去除右侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串 |
| split(sep=None, maxsplit=-1) | 将字符串进行分割,并将结果以列表的形式返回;sep 参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit参数用于指定分割的次数(注意:分割 2 次的结果是 3 份),默认是不限制 |
| splitlines(keepends=False) | 将字符串按行分割,并将结果以列表的形式返回;keepends 参数指定是否包含换行符,True 是包含,False 是不包含 |
| startswith(prefix[, start[, end]]) | 如果存在 prefix 参数指定的前缀子字符串,则返回 True,否则返回 False;可选参数 start 和 end 用于指定起始和结束位置;prefix 参数允许以元组的形式提供多个子字符串 |
| strip(chars=None) | 返回一个去除左右两侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串 |
| swapcase() | 返回一个大小写字母翻转的新字符串 |
| title() | 返回标题化(所有的单词都是以大写开始,其余字母均小写)的字符串。 |
| translate(table) | 返回一个根据 table 参数转换后的新字符串;table 参数应该提供一个转换规则(可以由 str.maketrans(‘a’, ‘b’) 进行定制,例如 “FishC”.translate(str.maketrans(“FC”, “15”)) -> ‘1ish5’) |
| upper() | 返回一个所有英文字母都转换成大写后的新字符串 |
| zfill(width) | 返回一个左侧用 0 填充的新字符串(width <= 字符串长度,新字符串 = 原字符串;width > 字符串宽度,所有字符右对齐,左侧使用 0 进行填充) |
capitalize():将字符串的第一个字符修改为大写,其他字符全部改为小写

casefold() :新字符串的所有字母变为小写

center(width, fillchar=’ ') : 返回一个字符居中的新字符串(width <= 字符串长度,新字符串 = 原字符串;width > 字符串宽度,所有字符居中,左右使用 fillchar 参数指定的字符填充)

count(sub[, start[, end]]): 返回 sub 在字符串中不重叠的出现次数,可选参数 start 和 end 用于指定起始和结束位置

endswith(suffix[, start[, end]]): 如果字符串是以 suffix 指定的子字符串为结尾,那么返回 True,否则返回 False;可选参数 start 和 end 用于指定起始和结束位置

expandtabs([tabsize=8]) :返回一个使用空格替换制表符的新字符串,如果没有指定 tabsize 参数,那么默认 1 个制表符 = 8 个空格

find(sub[, start[, end]]) :在字符串中查找 sub 子字符串,返回匹配的最低索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,返回 -1

index(sub[, start[, end]]) :在字符串中查找 sub 子字符串,返回匹配的最低索引值;可选参数 start 和 end 用于指定起始和结束位置;如果未能匹配子字符串,抛出 ValueError 异常
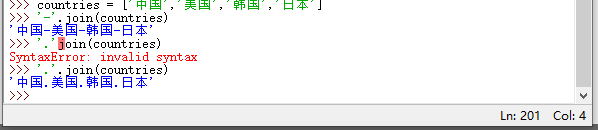
join(iterable) :连接多个字符串并返回一个新字符串;以调用该方法的字符串作为分隔符,插入到 iterable 参数指定的每个字符串的中间;
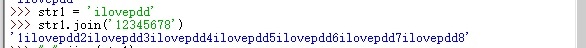
join()方法代替加号来拼接字符串
istitle():如果字符串是标题化字符串(所有的单词都是以大写开始,其余字母均小写)则返回 True,否则返回 False

lstrip(chars=None):返回一个去除左侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串
rstrip(chars=None):返回一个去除右侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串

partition(sep) 在字符串中搜索 sep 参数指定的分隔符,如果找到,返回一个 3 元组 (‘在sep前面的部分’, ‘sep’, ‘在sep后面的部分’);如果未找到,则返回 (‘原字符串’, ‘’, ‘’)
replace(old, new, count=-1) 返回一个将所有 old 参数指定的子字符串替换为 new 的新字符串;count 参数指定替换的次数,默认是 -1,表示替换全部

split(sep=None, maxsplit=-1) 将字符串进行分割,并将结果以列表的形式返回;sep 参数指定一个字符串作为分隔的依据,默认是任意空白字符;maxsplit参数用于指定分割的次数(注意:分割 2 次的结果是 3 份),默认是不限制

strip(chars=None) 返回一个去除左右两侧空白字符的新字符串;通过 chars 参数可以指定将要去除的字符串


swapcase() 返回一个大小写字母翻转的新字符串

translate(table) 返回一个根据 table 参数转换后的新字符串;table 参数应该提供一个转换规则(可以由 str.maketrans(‘a’, ‘b’) 进行定制,例如 “FishC”.translate(str.maketrans(“FC”, “15”)) -> ‘1ish5’)

Task
0. 还记得如何定义一个跨越多行的字符串吗(请至少写出两种实现的方法)?
【1】三重引号字符串
【2】转义字符\n

【3】
>>> str3 = ('待卿长发及腰,我必凯旋回朝。'
'昔日纵马任逍遥,俱是少年英豪。'
'东都霞色好,西湖烟波渺。'
'执枪血战八方,誓守山河多娇。'
'应有得胜归来日,与卿共度良宵。'
'盼携手终老,愿与子同袍。')
1. 三引号字符串通常我们用于做什么使用?
三引号字符串不赋值的情况下,通常当作跨行注释使用
2. file1 = open ('C: \ windows \ temp \ readme.txt', 'r') significa abrir el archivo de texto "C: \ windows \ temp \ readme.txt" en modo de solo lectura, pero de hecho esta declaración informará un error, ¿sabe por qué? ¿Cómo lo modificarías?
"\ T" y "\ r" significan "tabulación horizontal (TAB)" y "retorno de carro" respectivamente
>>> file1 = open(r'C:\windows\temp\readme.txt', 'r')
3. Hay una cadena: str1 = '<a href="http://www.fishc.com/dvd" target="_blank"> Empaquetado de recursos Fish C', cómo extraer la subcadena: 'www.fishc. com '
>>> str1 = '<a href="http://www.fishc.com/dvd" target="_blank">鱼C资源打包</a>'
>>> str1[16:29]

4. Si utiliza un número negativo como valor de índice para la operación de corte, ¿puede detectar visualmente correctamente el resultado de acuerdo con la tercera pregunta?
>>> str1 = '<a href="http://www.fishc.com/dvd" target="_blank">鱼C资源打包</a>'
>>> str1[-45:-32]

5. Es la cadena en la pregunta 3. ¿Qué se mostrará en la oración a continuación?
>>> str1[20:-36]
'pezc'
6. Se dice que solo el aceite de pescado con un coeficiente intelectual superior a 150 puede desbloquear esta cadena (revertida a una cadena significativa): str1 = 'i2sl54ovvvb4e3bferi32s56h; $ c43.sfc67o0cm99'

(No sé mucho, ?????)
7. Escriba un código para la verificación de seguridad de la contraseña: check.py (pensando ...)
# 密码安全性检查代码
#
# 低级密码要求:
# 1. 密码由单纯的数字或字母组成
# 2. 密码长度小于等于8位
#
# 中级密码要求:
# 1. 密码必须由数字、字母或特殊字符(仅限:~!@#$%^&*()_=-/,.?<>;:[]{}|\)任意两种组合
# 2. 密码长度不能低于8位
#
# 高级密码要求:
# 1. 密码必须由数字、字母及特殊字符(仅限:~!@#$%^&*()_=-/,.?<>;:[]{}|\)三种组合
# 2. 密码只能由字母开头
# 3. 密码长度不能低于16位
