Previous blog wrote deploy development environment of machine learning, machine learning, data preprocessing for the record, is scikit-learn using the built-in iris data - Iris plant data (classification). Including how to load and print assignment
First, tell us about what scikit-learn is:
-
scikit-learn is a machine learning tool based on the Python language.
-
Simple and efficient data mining and data analysis tools
-
Available to everyone reused in a variety of environments
-
Based on NumPy, SciPy and matplotlib
Secondly iris is a class of multivariate analysis of the data set.
-
For 150 contains three types of records, each record has four attributes.
-
Calyx are length, width calyx, petal length, petal width.
-
By these four properties may be predicted iris Hui belongs (Setosa, Versicolour, Virginica) what kind of three categories.
The next step is pretreated in jupyter the iris data.
First, open the Anaconda, click jupyter, new a python3.
Load_iris loading method using iris data sets:
-
from sklearn import datasets
-
iris=datasets.load_iris()
iris.data print output values can be seen a plurality of records, each record contains the aforementioned four properties.

Some methods of iris
-
iris.data// spent four properties
-
iris.feature_names // output each column name
-
iris.target// expressed in digital output Category 0/1/2
-
iris.target_name // output category name
-
type () to confirm data type
-
iris.data.shap // confirm dimensions
Do the following
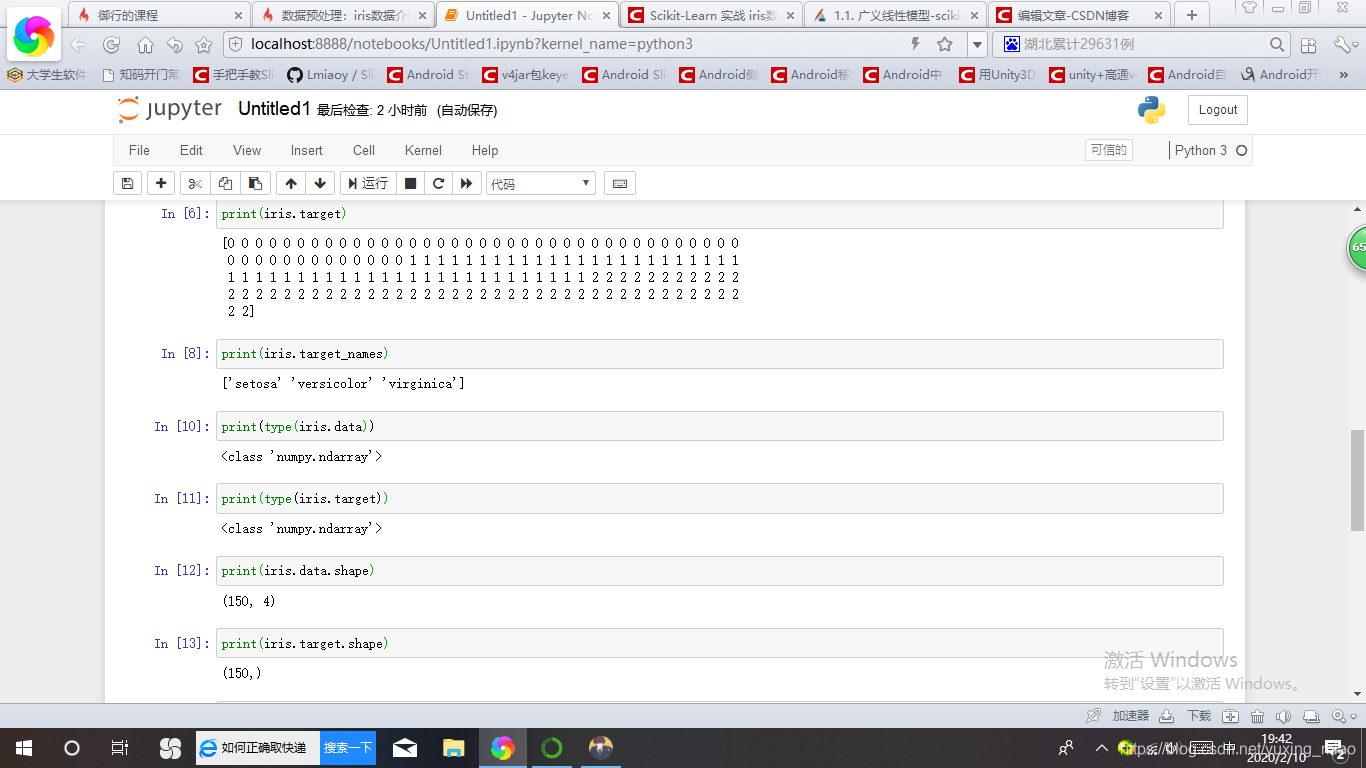
You can see, iris.data and iris.target attribute data and result data types are numpy
Assignment:
X=iris.data
Y = iris.data
