This blog introduces in detail the usage and main features of the Python machine learning library Scikit-learn. The content covers how to install and configure Scikit-learn, the main features of Scikit-learn, how to perform data preprocessing, how to use supervised learning and unsupervised learning algorithms, and how to evaluate models and perform parameter tuning. This article aims to help readers have a deep understanding of Scikit-learn and effectively apply it to practical machine learning tasks.

introduction
Driven by the tide of artificial intelligence, the importance of machine learning as a core technology does not need to be overemphasized. However, how to quickly and efficiently carry out machine learning experiments and development is a challenge faced by many researchers and engineers. As a concise and easy-to-read programming language with a rich scientific computing library, Python has been widely used in the field of machine learning. Among Python's many machine learning libraries, Scikit-learn has won the favor of many users for its comprehensive functions, excellent performance and ease of use. In this article, we will discuss in depth the usage and internal mechanism of Scikit-learn to help readers make better use of this tool for machine learning experiments.
The Importance of Machine Learning and Scikit-learn

As a technology that can automatically analyze and obtain models from data, and then use the models to predict unknown data, machine learning is becoming more and more widely used in all aspects of life, including search engines, automatic driving, face recognition, speech recognition etc. Among many machine learning tools, Scikit-learn has been widely used in both scientific research and industry due to its rich algorithm library, elegant API design, excellent performance, and active community support.
A basic overview of Scikit-learn
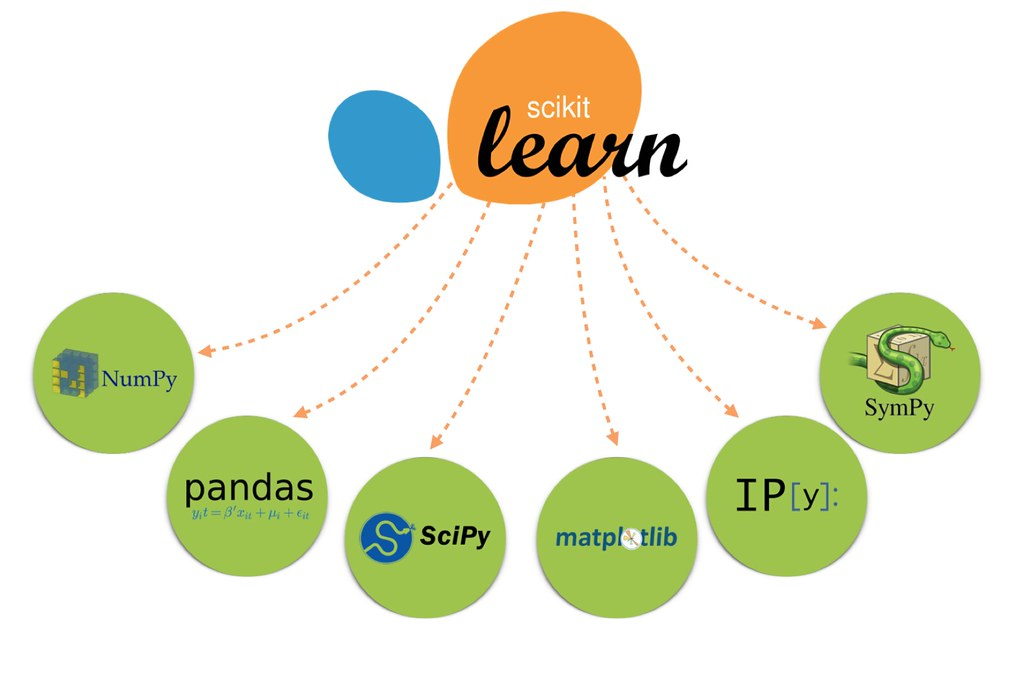
Scikit-learn is an open source machine learning library based on Python. It is based on NumPy, SciPy and matplotlib and supports various machine learning models, including classification, regression, clustering and dimensionality reduction. In addition to providing a large number of machine learning algorithms, Scikit-learn also includes a complete set of tools for model evaluation and selection, as well as functions for data preprocessing and data analysis. It is easy to use but powerful, which is an important reason for the popularity of Scikit-learn. In the next article, we will detail how to use Scikit-learn for machine learning development.
This part will provide readers with the fundamental concepts of machine learning and Scikit-learn, as well as their application and importance in the field of modern technology. Subsequently, we will explore in detail the main features and functions of the Scikit-learn library, and how to use it for data processing and machine learning model building, optimization, and evaluation.
Install and configure
Before we can start using Scikit-learn, we need to install and configure it first. In this section, we will detail how to install Scikit-learn in a Python environment, and how to install the necessary dependencies.
How to install Scikit-learn
Scikit-learn can be easily installed through Python's package manager pip. Open a terminal or command line interface and enter the following command:
pip install -U scikit-learn
This command will install or upgrade Scikit-learn to the latest version. If you are using a specific Python environment, such as Anaconda, you can also install via conda:
conda install scikit-learn
Install the necessary dependencies
The operation of Scikit-learn depends on some Python libraries, including NumPy and SciPy. These libraries are generally installed automatically when Scikit-learn is installed. If it is not installed automatically, or you need to update to the latest version, you can use the following command:
pip install -U numpy scipy
In addition, for data processing and visualization, we usually need to install pandas and matplotlib. Likewise, it can be installed with the following command:
pip install -U pandas matplotlib
The above installation process is suitable for most situations. If you encounter any problems during the installation process, you can refer to the official documentation of Scikit-learn, or seek help in relevant forums and communities. After the installation is complete, you can start using Scikit-learn to learn and develop machine learning.
Key Features of Scikit-learn
Scikit-learn is a powerful Python machine learning library, whose design philosophy focuses on ease of use and unity. Next, we will introduce the main features of Scikit-learn one by one.
Powerful preprocessing function
In the process of machine learning, data preprocessing is an essential step. Scikit-learn provides a wealth of data preprocessing functions, including data cleaning, encoding, standardization, feature extraction, and feature selection.
from sklearn import preprocessing
# 以数据标准化为例,以下是使用Scikit-learn进行标准化的代码
X = [[ 1., -1., 2.],
[ 2., 0., 0.],
[ 0., 1., -1.]]
scaler = preprocessing.StandardScaler().fit(X)
print(scaler.transform(X))
Numerous Machine Learning Algorithms
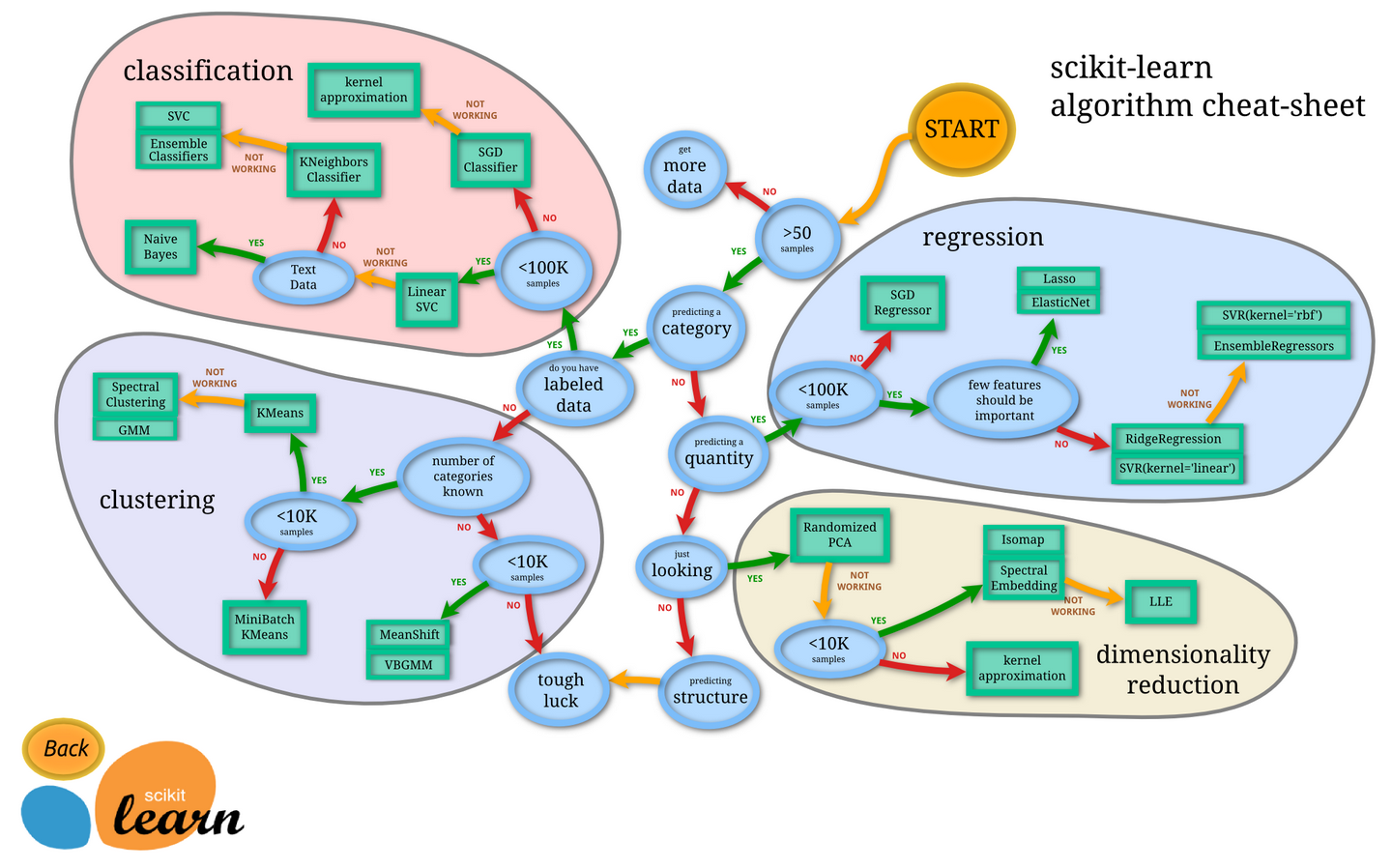
Scikit-learn provides a variety of commonly used supervised learning and unsupervised learning algorithms, including regression, classification, clustering, dimensionality reduction, etc. The API design of these algorithms is unified and consistent, making it very simple to switch between different algorithms.
from sklearn import svm
# 以SVM为例,以下是使用Scikit-learn进行模型训练和预测的代码
X = [[0, 0], [1, 1]]
y = [0, 1]
clf = svm.SVC()
clf.fit(X, y)
print(clf.predict([[2., 2.]]))
Effect evaluation and model selection
Scikit-learn also provides a comprehensive set of model evaluation and selection tools, including cross-validation, grid search, and various evaluation metrics.
from sklearn import metrics
from sklearn.model_selection import cross_val_score
# 以交叉验证为例,以下是使用Scikit-learn进行交叉验证的代码
scores = cross_val_score(clf, X, y, cv=5)
print(scores)
visualization tool
Although Scikit-learn itself does not provide plotting functions, it can be used well with Python plotting libraries such as matplotlib to visualize data and model effects.
import matplotlib.pyplot as plt
from sklearn import datasets
# 以下是一个简单的Scikit-learn数据可视化示例
iris = datasets.load_iris()
X = iris.data[:, :2] # 我们只取前两个特征
y = iris.target
plt.scatter(X[:, 0], X[:, 1], c=y)
plt.show()
The above are the main features of Scikit-learn. In the next sections, we will detail how to use these features for various stages of machine learning.
Data preprocessing for Scikit-learn
In machine learning tasks, data preprocessing is a very important job. Preprocessing includes steps such as data cleaning, data transformation, and feature extraction to convert raw data into a format suitable for use by machine learning models. Scikit-learn provides a powerful set of data preprocessing tools to meet these needs.
data cleaning
Data cleaning mainly includes dealing with missing values and outliers. Scikit-learn provides the Imputer class for handling missing values. Here is a simple example using Imputer:
from sklearn.impute import SimpleImputer
# 假设我们的数据集中有缺失值NaN
import numpy as np
X = [[1, 2], [np.nan, 3], [7, 6]]
imp = SimpleImputer(missing_values=np.nan, strategy='mean')
print(imp.fit_transform(X))
data conversion
Data conversion mainly includes steps such as standardization, normalization, and binarization. Scikit-learn provides a preprocessing module for these tasks.
from sklearn import preprocessing
# 数据标准化示例
X = [[1., -1., 2.], [2., 0., 0.], [0., 1., -1.]]
scaler = preprocessing.StandardScaler().fit(X)
print(scaler.transform(X))
# 数据归一化示例
X_normalized = preprocessing.normalize(X, norm='l2')
print(X_normalized)
Feature Extraction and Feature Selection
Scikit-learn provides a series of methods for feature extraction and feature selection. Feature extraction is mainly used to convert raw data into feature vectors, and feature selection is used to select the most valuable features from the raw features.
from sklearn.feature_extraction.text import CountVectorizer
# 特征提取示例:文本数据转换为词频向量
corpus = ['This is the first document.',
'This is the second second document.',
'And the third one.',
'Is this the first document?']
vectorizer = CountVectorizer()
X = vectorizer.fit_transform(corpus)
print(vectorizer.get_feature_names())
print(X.toarray())
# 特征选择示例:使用卡方检验选择最好的特征
from sklearn.feature_selection import SelectKBest, chi2
X, y = [[1, 2], [3, 4], [5, 6], [7, 8]], [0, 0, 1, 1]
X_new = SelectKBest(chi2, k=1).fit_transform(X, y)
print(X_new)
Through the above preprocessing work, we can convert the raw data into a format suitable for the machine learning model, which is the basis for machine learning. In the next part, we will discuss how to use Scikit-learn's API to build and train machine learning models.
Supervised Learning Algorithms in Scikit-learn
Supervised learning is one of the most common tasks in machine learning, including classification and regression. Scikit-learn provides a series of supervised learning algorithms, including common linear models, decision trees, support vector machines, etc. The following will show you how to use these algorithms in Scikit-learn.
linear model
Linear models are a common supervised learning algorithm used to solve regression and classification problems. The linear_model module in Scikit-learn provides a series of linear models, including linear regression, logistic regression, ridge regression, etc.
from sklearn.linear_model import LinearRegression
# 创建数据
X = [[1, 1], [1, 2], [2, 2], [2, 3]]
y = [1, 1, 2, 2]
# 创建线性回归模型并训练
reg = LinearRegression().fit(X, y)
# 进行预测
print(reg.predict([[3, 5]]))
decision tree
Decision trees are a simple yet effective classification and regression method. The tree module in Scikit-learn provides an implementation of decision trees.
from sklearn import tree
# 创建数据
X = [[0, 0], [1, 1]]
Y = [0, 1]
# 创建决策树模型并训练
clf = tree.DecisionTreeClassifier()
clf = clf.fit(X, Y)
# 进行预测
print(clf.predict([[2., 2.]]))
Support Vector Machines
Support Vector Machine (SVM) is a powerful classification method, but it can also be used to solve regression problems. The svm module in Scikit-learn provides an implementation of SVM.
from sklearn import svm
# 创建数据
X = [[0, 0], [1, 1]]
y = [0, 1]
# 创建SVM模型并训练
clf = svm.SVC()
clf.fit(X, y)
# 进行预测
print(clf.predict([[2., 2.]]))
Scikit-learn also includes many other supervised learning algorithms, such as neural networks, ensemble methods, etc. The use of these methods is similar to the above, and all follow the unified API design of Scikit-learn. In actual use, we can choose an appropriate algorithm for learning according to the characteristics of the data and the needs of the problem.
Unsupervised Learning Algorithms in Scikit-learn
Unsupervised learning refers to learning data sets without labels, mainly including tasks such as clustering and dimensionality reduction. Scikit-learn provides a rich set of unsupervised learning algorithms. Next, we will introduce some of them.
clustering
Clustering is a common task in unsupervised learning, where the goal is to group similar samples together. Scikit-learn provides a variety of clustering algorithms, such as K-means, spectral clustering, DBSCAN, etc.
from sklearn.cluster import KMeans
# 创建数据
X = [[1, 2], [1, 4], [1, 0], [4, 2], [4, 4], [4, 0]]
# 创建KMeans模型并训练
kmeans = KMeans(n_clusters=2, random_state=0).fit(X)
# 查看聚类结果
print(kmeans.labels_)
Dimensionality reduction
Dimensionality reduction is another common task in unsupervised learning, where the goal is to map high-dimensional data into a low-dimensional space for easy data understanding and visualization. Scikit-learn provides a variety of dimensionality reduction algorithms, such as PCA, t-SNE, etc.
from sklearn.decomposition import PCA
# 创建数据
X = [[1, 2, 3], [4, 5, 6], [7, 8, 9]]
# 创建PCA模型并训练
pca = PCA(n_components=2)
pca.fit(X)
# 查看降维结果
print(pca.transform(X))
Scikit-learn also provides many other unsupervised learning algorithms, such as association rule learning, anomaly detection, etc. These algorithms can play a huge role in dealing with specific problems, making Scikit-learn very flexible in dealing with various machine learning tasks.
Evaluation model and parameter tuning
After creating and training a machine learning model, we need to evaluate its performance and tune the model parameters to achieve the best learning effect. Scikit-learn provides a series of tools for model evaluation and parameter tuning.
model evaluation
Scikit-learn provides a variety of methods for model evaluation, including cross-validation, calculating precision, recall, F1 score, etc.
from sklearn.model_selection import cross_val_score
from sklearn.metrics import classification_report
from sklearn.ensemble import RandomForestClassifier
from sklearn import datasets
# 加载数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 创建模型
clf = RandomForestClassifier(random_state=7)
# 交叉验证
scores = cross_val_score(clf, X, y, cv=5)
print("Cross-validation scores: ", scores)
# 训练模型
clf.fit(X, y)
# 预测结果
y_pred = clf.predict(X)
# 计算各项评价指标
print(classification_report(y, y_pred))
parameter tuning
Scikit-learn provides tools such as GridSearchCVand RandomizedSearchCVfor parameter tuning.
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
# 参数空间
param_grid = {
'C': [0.1, 1, 10, 100], 'gamma': [1, 0.1, 0.01, 0.001], 'kernel': ['rbf']}
# 创建SVC模型
svc = SVC()
# 创建GridSearchCV对象并训练
grid = GridSearchCV(svc, param_grid, refit=True, verbose=2)
grid.fit(X, y)
# 输出最优参数
print(grid.best_params_)
Through the above evaluation and tuning, we can get the optimal model and parameters. In practical machine learning tasks, model evaluation and parameter tuning are very important steps, which can significantly improve the performance and accuracy of the model.
in conclusion
Scikit-learn is a powerful and easy-to-use Python library that provides us with a complete set of machine learning tools that can be used to solve the whole process tasks from data preprocessing, to model training, to model evaluation and parameter tuning . The wide application of Scikit-learn is not only because of its powerful functions, but also because of its design concept - a unified API, which allows us to quickly switch between different models and algorithms without major changes to the code. This flexibility and ease of use makes Scikit-learn the first choice for Python machine learning libraries.
However, we also need to note that although Scikit-learn provides a series of tools, each tool has its applicable scenarios and conditions. In the process of using Scikit-learn, we need to deeply understand the principles and characteristics of each tool, so that we can choose the appropriate tool for different tasks and data to get the best results.
I hope that through this blog, you have a deeper understanding of Scikit-learn and a clearer understanding of how to use Scikit-learn. If you are interested in machine learning, then Scikit-learn will be a must-have tool for you.