Disclaimer: This article is a blogger original article, shall not be reproduced without the bloggers allowed. https://blog.csdn.net/weixin_43215250/article/details/90638627
-
By PSQL load
usage:
bin/psql.py [-t table-name] [-h comma-separated-column-names | in-line] [-d field-delimiter-char quote-char escape-char]<zookeeper> <path-to-sql-or-csv-file>...parameter description -a,–array-separator Array element separator, default ':' -b,–binaryEncoding Specifies the binary coding -d,–delimiter Providing custom separator parse CSV file -e,–escape-character Provide custom escape characters, the default is a backslash -h,–header Covering the column name mapped to the CSV data, case sensitive. Inline special value, a map showing a first row of the CSV file to determine data column -l,–local-index-upgrade Means for upgrading by local index data index data is moved from the table into a separate table in the same individual column group. -m,–map-namespace A mapping table for matching to a schema name space requirements phoenix.schema. isNamespaceMappingEnabled enabled -q,–quote-character Custom phrase separator, default double quotes -s,–strict Run in strict mode, an exception is thrown in error when parsing CSV -t,–table Load the name of the table data. By default, the name of the table is taken from the name of the CSV file, this parameter is case sensitive. Example:
[root@cdh01 ~]# cd /opt/cloudera/parcels/APACHE_PHOENIX/bin [root@cdh01 bin]# ./phoenix-psql.py -t MY_SCHEMA.PERSONAS -d '\t' localhost /root/part-m-00017.csv SLF4J: Class path contains multiple SLF4J bindings. SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/APACHE_PHOENIX-4.14.0-cdh5.12.2.p0.3/lib/phoenix/phoenix-4.14.0-cdh5.12.2-client.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: Found binding in [jar:file:/opt/cloudera/parcels/CDH-5.12.1-1.cdh5.12.1.p0.3/jars/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class] SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation. SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory] 19/05/28 14:00:58 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable csv columns from database. CSV Upsert complete. 1 rows upserted Time: 0.351 sec(s) -
By MapReduce load
usage:
HADOOP_CLASSPATH=$(hbase mapredcp):/path/to/hbase/conf \ hadoop jar phoenix-<version>-client.jar \ org.apache.phoenix.mapreduce.CsvBulkLoadTool \ --table EXAMPLE \ --input /data/example.csvparameter list:
parameter description -a,–array-delimiter Separator elements of an array (optional) -b,–binaryEncoding Binary coded format -c,–import-columns To import a list of columns, separated by commas -d,–delimiter Delimiter input, the default is a comma -e,–escape Provide custom escape characters, the default is a backslash -g,–ignore-errors Ignore input error -h,–help Print help explain -i,–input CSV input path for hdfs path (required) -it,–index-table You need to load the index table -o,–output Temporary HFiles output path (optional) -q,–quote Custom phrase separator, default double quotes -s,–schema schema name (optional) -t,–table Phoenix table name (required) -z,–zookeeper Zookeeper connection address (optional) Example:
HADOOP_CLASSPATH=/opt/cloudera/parcels/CDH/lib/hbase/hbase-protocol.jar:/opt/cloudera/parcels/CDH/lib/hbase/conf \ hadoop jar /opt/cloudera/parcels/APACHE_PHOENIX/lib/phoenix/phoenix-4.14.0-cdh5.12.2-client.jar \ org.apache.phoenix.mapreduce.CsvBulkLoadTool \ --table MY_SCHEMA.PERSONAS \ --delimiter '\t' \ --input /tmp/hbase/test/part-m-00017Note:
Phoenix-4.14.0-cdh5.12.2-client.jar need to add the clusterhbase-site.xmlconfiguration file.
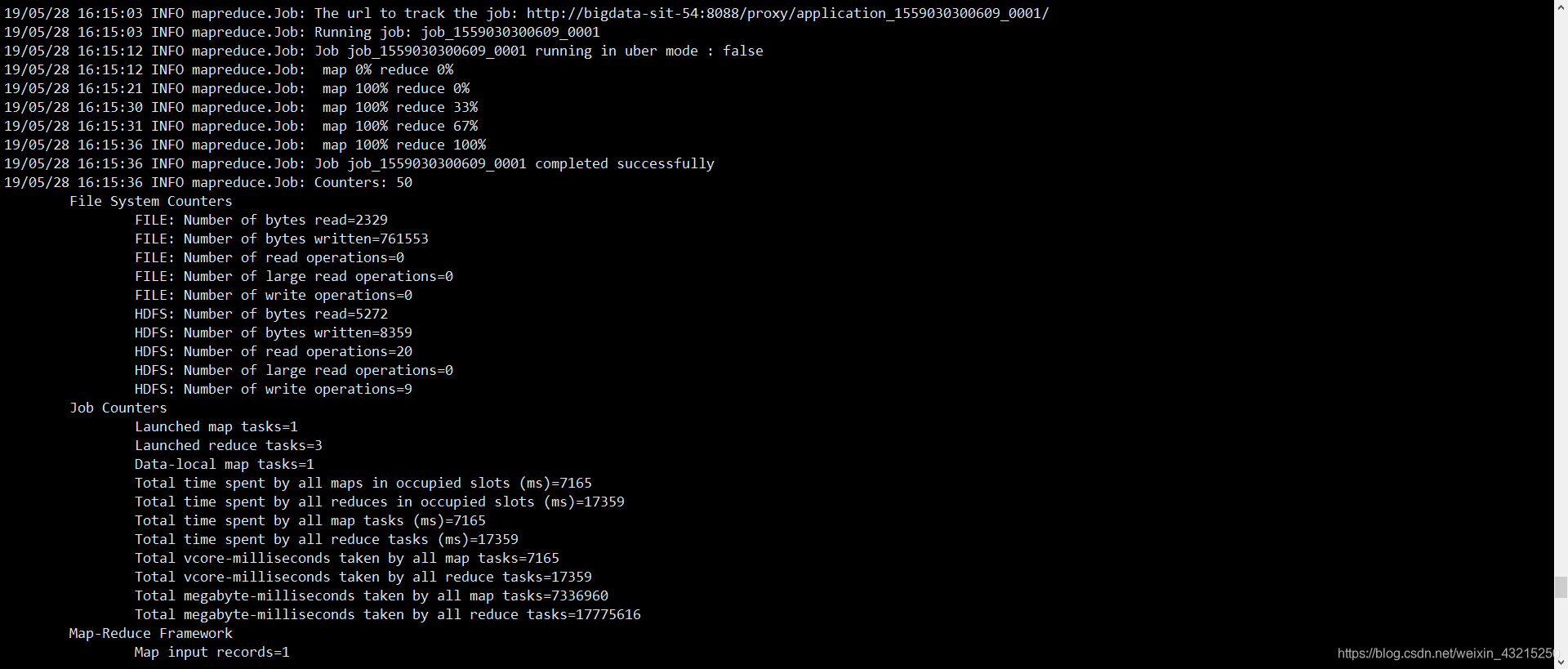
Reference: https://phoenix.apache.org/bulk_dataload.html