1. Platform introduction
Financial self-operated billing mainly undertakes the function of transferring JD’s self-operated data from the C end to the B end in the entire supply chain. It is a later stage in the entire supply chain. The main function of the system is billing and aggregation to the B end.
2. Problem description
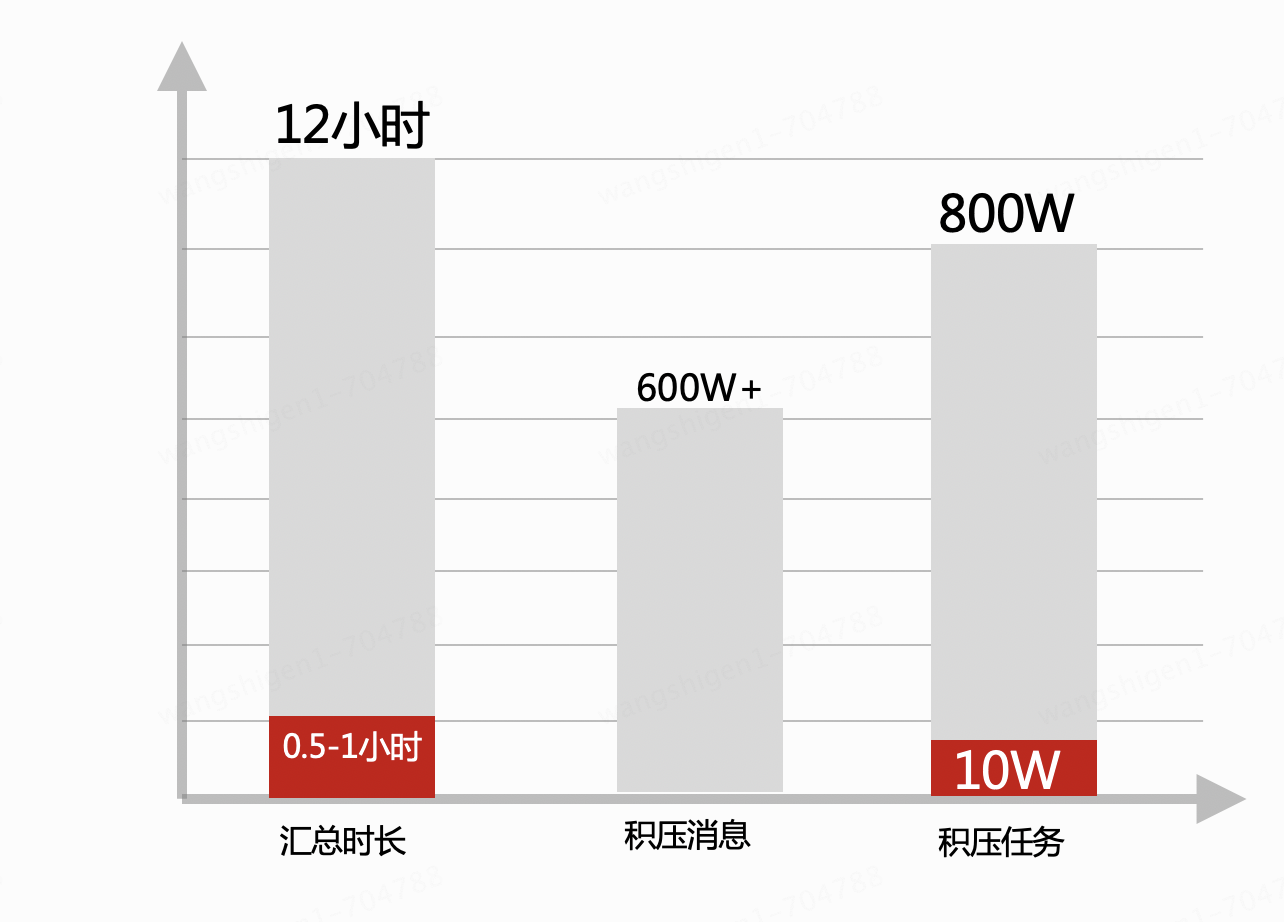
In recent years, the amount of self-operated billing data has increased significantly, with more than 10 billion data volumes, and the summary accounts for half of the database resources in a day.
1. Locate tens of thousands of data from tens of millions of W+ in a single table every day to perform summary, that is, perform group by operation on all databases and all tables, 32 databases * 32 tables, which takes 12 hours to process every day.
2. During the aggregation period, the system basically stagnated, resulting in slow processing of messages and tasks, a large backlog, and the inability to charge data in a timely manner.
3. The database is under great pressure and is at risk of crashing at any time.
4. It affects the supplier experience. During the big promotion period, suppliers need to check sales data and battle reports in real time, and the system cannot respond in time.
3. Introduction to original technology
The core of the system summary relies on the MySQL physical machine to perform group by in each database and each table. The summary is divided and conquered by expense type. Each type of summary dimension is different. Every time a new summary dimension is introduced, it needs to be written from front to back. The new summary logic is mainly to lock the data range of the new dimension and determine the new group by field. The previous logic had to be regression tested, which is stupid, I think.
4. Ideas and methods for solving problems
Based on the above background and problems, determine a rough solution to the problem
1. First of all, we must break away from MySQL summary. The database is very fragile. We must protect the database, otherwise the magnitude will keep increasing and the sky will fall one day.
2. Incidentally solve the disadvantages of repeated development of new requirements.
5. Description of the practical process
Due to the large volume, T+1 processing is allowed in the business. Since it is offline data processing, spark, spring batch, finlk, etc. can generally be thought of. In the technical research stage, maturity and community activity are mainly considered, and spark technology is mainly used. Divide the summary process into 4 steps. In order to make it easier to understand, the following content simplifies the logic and briefly describes it.
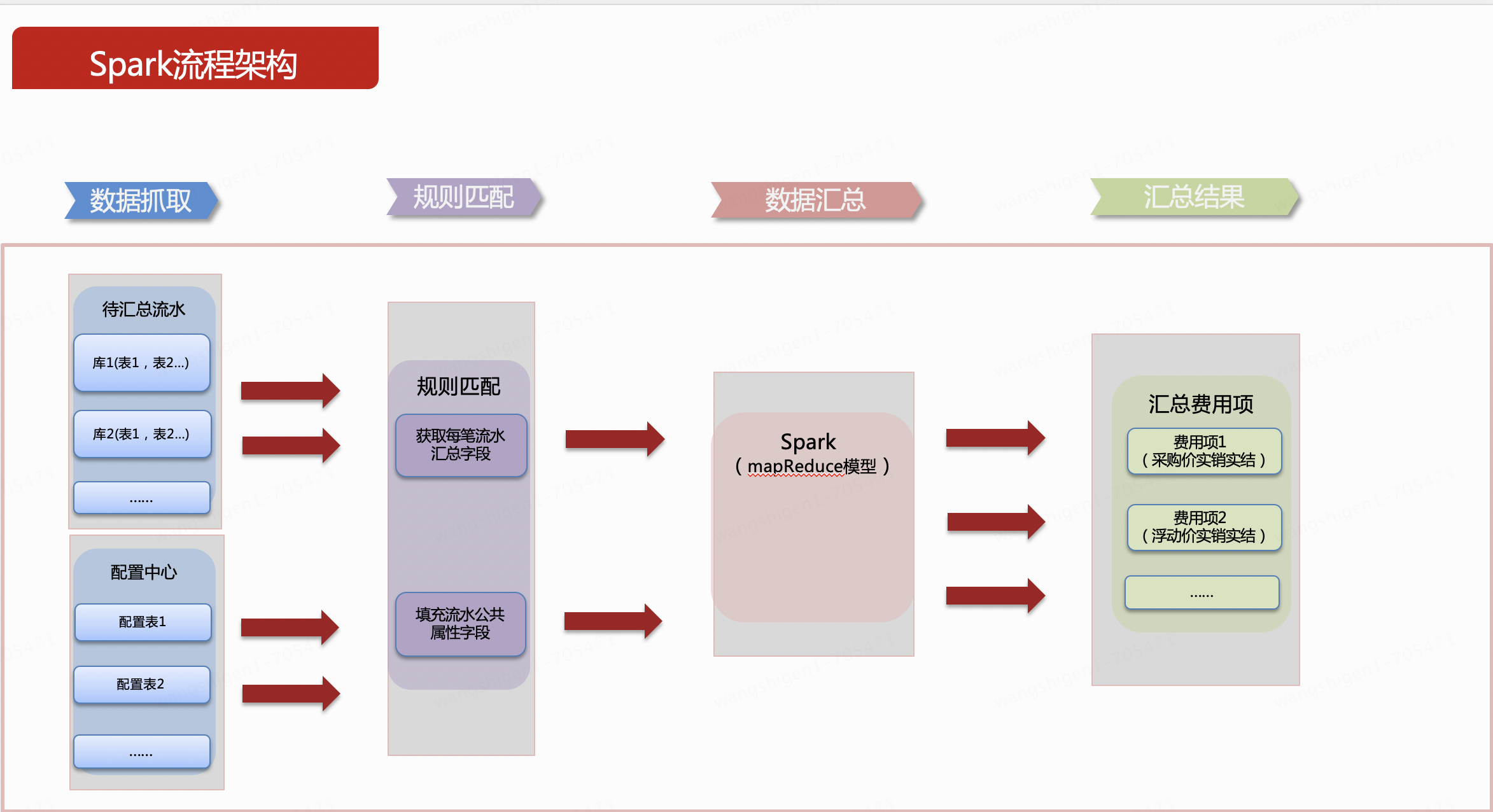
1. Data capture
The data before aggregation is business data. Type generally refers to the field that divides the data cost type in the business data. ou and dept generally refer to the dimensions of the source data, which can be one or more other fields. Amount is the field to be summarized and summed. Expressed here is the amount.
The configuration table is derived from the source data. There can be many configuration data, which is a general term. This system only uses one table. type indicates that the expense type is used to associate with the source data. The association can be associated with one or more fields. Here, a field is used as an example. merge_key is a summary field, and the field value is one or more from the table structure of the source data. Field composition. invoice_type represents the public fields that need to be filled in the aggregated result set, and is generally referred to as invoice type here. It can be expanded according to the filled fields. If expanded, just add columns later in the configuration table. The following example diagram expresses this meaning in a single field.
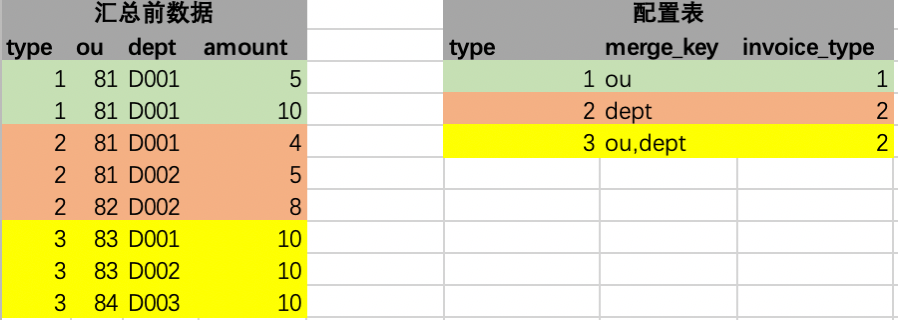
2. Rule matching
The first processing is performed, that is, each row in the source data is associated with the only row in the configuration table, as shown in the figure below. Under special instructions, each row of source data can be associated with only one row of configuration in the configuration table. That is, left join, which cannot be associated, that is, has no configuration, is filtered out, and is not summarized . The first step of the processing operation is completed in memory.

Then proceed to the second step of processing. In this step, we need to further parse the merge_key field taken out from the configuration table into the specific value of the field corresponding to the current left join row. The parsed result is as shown below. Under the explanation of this step, according to the field of merge_key, such as the first row ou, the field value of the corresponding column of this row is obtained, which is 81. The principle is implemented through Java reflection. There are now various open source tools The package can be used directly, such as spring expressions and other tools. By analogy, the values of multiple fields can also be obtained. Multiple fields can be spliced according to certain connection symbols. This figure is spliced with _. Filled fields are also added simultaneously.
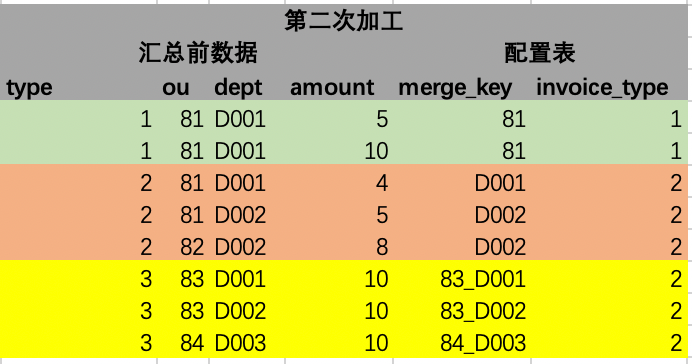
3. Data summary
After the rule matching data is processed, we only need to summarize the processed merge_key field. The summary engine only needs to follow the fixed summary field (the example here is the merge_key field after the second step is processed), and the summary logic is It can be solidified, and only one general SQL is needed to implement the summary of all expense types, and the final summary result is generated.
4. Summary results
The aggregated data can maintain the same results as the data aggregated through the original technology, and at the same time, some common fields can be filled in. As shown in the figure below, the green 2 rows of source data are summarized by ou and become 1 row in the result table; the orange 3 rows of source data are summarized by dept and become 2 rows in the result table; the yellow source data are summarized by ou and dept fields. The summary becomes 3 lines.

Finally, write the summary results back to MySQL.
6. Practical process thinking and effect evaluation
1. During the test environment verification process, the test table and the online table have different numerical levels. When first going online, reading data is extremely slow. Since Spark reads a single table very quickly, the efficiency of reading data from sub-databases and sub-tables plummets. Here, a multi-threading method is used to read the unsummarized data that meets the conditions, and finally summarizes a large set.
2. After going online and running stably for a period of time, the performance comparison chart shows that by stripping away the group by operation in MySQL, the summary time has been reduced, the database performance has improved, and the ability to process messages and asynchronous tasks has also improved. And affect the overall situation.
3. When new summary requirements come online in the future, the new dimension summary function can be implemented through configuration, which simplifies research and development work and improves the timeliness of demand delivery. There are also disadvantages. At present, the fields of summary dimensions must be taken from the main table, because Spark only reads the main table when reading business data, and does not read the extended table. If you are confident about the data quality of the hive table in the future, you can change it to spark to directly read the hive table, or read from es, ck and other libraries.
4. Through the introduction of the spark framework, the large database summary is changed from online to offline, which relieves the pressure on the database. After the database performance is improved, the effectiveness of billing is also improved. It also increases the stability of the system and improves the supplier's experience.
Author: Wang Shigen
Source: JD Cloud Developer Community Please indicate the source when reprinting
npm is abused - someone uploaded more than 700 Wulin Gaiden slice videos "Linux China" The open source community announced that it will cease operations Microsoft formed a new team to help rewrite the core Windows library with Rust JetBrain bundled AI assistant caused user dissatisfaction Deutsche Bahn is recruiting people familiar with MS - IT administrators of DOS and Windows 3.11 VS Code 1.86 will cause the remote development function to be unavailable. FastGateway: a gateway that can be used to replace Nginx. Visual Studio Code 1.86 is released . Seven departments including the Ministry of Industry and Information Technology jointly issued a document: Develop the next generation operating system and promote open source technology. , Building an open source ecosystem Windows Terminal Preview 1.20 released