1 Documentation Description
This document describes the real-time processing architecture with Storm as the main body, which includes the data collection part, the real-time processing part, and the data landing part.
The technical selection of different parts is related to business requirements and personal familiarity with related technologies, and will be analyzed one by one.
This architecture is a architecture that I have mastered, and may have similar parts to other architectures, and I will explain my understanding of it one by one.
This article is written in great detail, and I believe it will be helpful for everyone to understand the overall understanding of real-time processing.
2 Real-time processing architecture
2.1 Overall Architecture Diagram
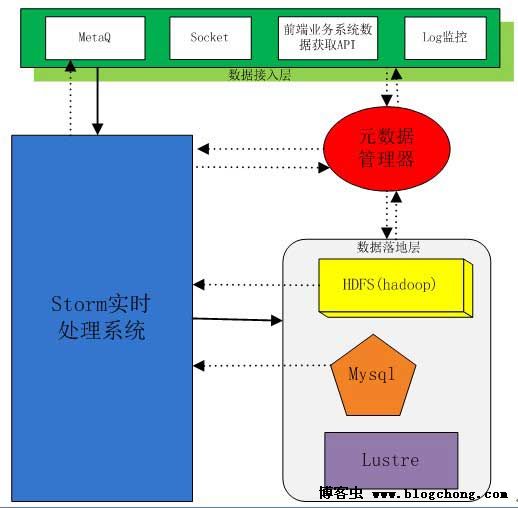
Architecture Description:
The entire data processing process includes four parts, one part is the data access layer, which obtains data from the front-end business system; the middle part is the most important real-time processing part of Storm, the data is accessed from the access layer, and the data is passed in after real-time processing. The landing layer; the third part is the data landing layer, which specifies the landing method of the data; the fourth part is the metadata manager.
2.2 Data Access Layer
There are various data collection methods in this part, including using message queue (MetaQ) to transmit data directly through network sockets, proprietary data collection APIs for front-end business systems, and regular monitoring of log prices.
2.2.1 MetaQ
Why choose message queue?
This may be a place where everyone is more confused, and they will wonder why the data is not directly imported into Storm. The reason for using the message queue as the data intermediate processing component is that when processing large batches of data, the front-end business data may be generated very quickly, and the real-time processing or other processing speeds cannot keep up, which will affect the processing performance of the entire system. The introduction of message queues After that, we can temporarily store the data in the message queue, and the back-end processing speed will not affect the generation of front-end business data. The more professional term is called decoupling, which increases the scalability of the system, and the various components of the system run asynchronously.
Why use MetaQ?
In terms of message queue selection, kafka is a relatively general message publishing and subscription system with a long open source time, while MetaQ is developed based on kafka and is developed in Java, which we are familiar with, and some improvements have been made on this basis. Such as data reliability and transaction processing. On the other hand, this is something that is open sourced by Chinese people, and the documents in all aspects are relatively complete, and there are related instance interfaces. Therefore, using MetaQ as the message middleware has lower development cost and better performance.
2.2.2 Socket
Some people use network socket programming to realize the data access of Storm. This is a relatively straightforward data collection method, and indeed some Storm-related projects use this data access method.
This data access method is relatively simple, and the maintenance cost is low, but the amount of data is relatively small compared to the use of message middleware.
difficulty:
The troublesome thing about using Socket to collect data is that because the address of Storm's Spout is uncertain and its address cannot be determined, the front-end business system cannot accurately send the data to a port on a specific IP address. The workaround is as follows:
(1) We can use zookeeper as the transmission station. After the Spout is executed, the information such as the local valid IP address and the available port being monitored is written into the zookeeper, and the front-end business system obtains the information from the zookeeper directory.
(2) Using metadata to guide the data transmission of the front-end business system, Spout stores the local IP and port information in the metadata manager, and the front-end business system obtains the parameter information from the metadata manager.
2.2.3 Front-end business system data collection API
This data collection method will not be discussed further. The front-end business system is a data collection API specially designed for Spout. Spout can obtain data only by calling this API.
2.2.4 Log file monitoring
Sometimes our data source is the log file that has been saved, so Spout must monitor the change of the log file and extract the changed part of the data into Storm in time, which is difficult to achieve complete real-time.
2.3 Storm real-time processing system
2.3.1 Description
The previous part of the data access layer actually already contains some Storm-related content. For example, some data collection interfaces belong to the Spout part of Storm. I took this part out separately to take the core part of real-time processing as a large chapter, that is, real-time processing. Parts (except for data access and data landing interfaces).
2.3.2 Reasons for using Storm
Why choose Storm as the core of real-time processing? Storm, as a real-time processing system with an early open source, has relatively complete functions, and its failover mechanism is quite powerful. Whether it is a worker, a supervisor, or even a task, it can be automatically restarted as long as it hangs; its performance has been tested and is quite good. At present, there are many network-related materials, which means that the development cost will be much lower; its scalability is very good, and it can scale horizontally. The current shortcoming of Storm is that it has a single point with nimbus. If nimbus fails, the entire system will fail. This is where Storm needs to improve. However, the system pressure of nimbus is not large, and there will be no downtime under normal circumstances.
2.3.3 Real-time processing business interface
This part needs to provide an interface for real-time business processing, that is, to convert the user's business layer requirements into a specific mode of real-time processing. For example, imitating Hive to provide a Sql-like business interface, we describe a type of data in the metadata manager as a table, and different fields are different fields in the table
select ---------------------------- Fixed data query (exception or dirty data processing),
max/min/avg-------------------maximum and minimum
count/sum----------------------Sum or count (such as pv, etc.)
count(distinct)------------------Deduplication count (typically such as UV)
order by--------------sort (take the most recent users)
group by + clustering function + order by-----sort after clustering (such as topN products with the most visits)
This is just a simple analogy. We can convert the business requirements of real-time processing into Sql-related statements, execute Sql-like statements at the upper layer, and translate them into specific topology components and node parameters at the bottom layer.
2.3.4 Specific business requirements
(1) Conditional filtering
This is Storm's most basic processing method. It filters the qualified data in real time and saves the qualified data. This kind of real-time query business requirement is very common in practical applications.
(2) Intermediate calculation
We need to change a field in the data (for example, a value), we need to use an intermediate value to change the value after calculation (value comparison, sum, average, etc.), and then re-output the data.
(3) Find TopN
I believe that everyone is familiar with the business needs of the TopN category. Within a specified time window, the TopNs that appear in statistical data are more common in shopping and e-commerce business needs.
(4) Recommendation system
As shown in my architecture diagram, sometimes the information in the database is obtained from mysql and hadoop during real-time processing. For example, in a movie recommendation system, the incoming data is the user's current on-demand movie information, and what is obtained from the database is The user's previous on-demand movie information statistics, such as the most on-demand movie types, the most recently on-demand movie types, and on-demand information in their social relationships, combined with this click and the information obtained from the database, generate a piece of recommendation data and recommend it to the user. And the click record will update the reference information in its database, thus realizing a simple intelligent recommendation.
(5) Distributed RPC
Storm has a special design for RPC. Distributed RPC is used to perform parallel computing on a large number of function calls on Storm, and finally return the result to the client. (I don't really understand this part)
(6) Batch processing
The so-called batch processing means that the data is accumulated to a certain trigger condition, and then it is output in batches. The so-called trigger conditions are similar to when the time window has arrived, the number of statistics is sufficient, and the incoming of certain data is detected, etc.
(7) Heat Statistics
The heat statistics implementation relies on the TimeCacheMap data structure, which is able to keep recently active objects in memory. We can use it to achieve, for example, the calculation of hot post rankings in forums.
2.4 Data landing layer
2.4.1 MetaQ
As shown in the diagram, Storm and MetaQ are connected by a dotted line. Some data needs to be written into MetaQ after real-time processing, because the back-end business system needs to obtain data from MetaQ. This is not strictly a data landing, because the data is not actually written to disk for persistence.
2.4.2 Mysql
Mysql listed here means that the interfaces of traditional databases and Storm are almost similar. In general, when the amount of data is not very large, Mysql can be used as the storage object for data landing. Mysql is also more convenient for the subsequent processing of data, and there are many operations on Mysql on the network. The development cost is relatively small, and it is suitable for small and medium data storage.
2.4.3 HDFS
HDFS and Hadoop-based distributed file system. Many log analysis systems are built based on HDFS, so it is necessary to develop the data landing interface between Storm and HDFS. For example, large batches of data are processed in real time and stored in Hive, and provided to back-end business systems for processing, such as log analysis, data mining, and so on.
2.4.4 Lustre
I wrote this data landing method, on the one hand, because I have been studying Lustre recently, and I am familiar with it; on the other hand, it is more suitable for some applications. For example, the application scenario of Lustre as a data landing is that the amount of data is large, and The post-processing purpose is to be processed as an archive. In this case, Lustre can provide a relatively large (considerable) data directory for the data for data archiving.
The architecture of Lustre can adopt the architecture of Lustre+drbd+heartbeat, which can not only provide a large-capacity archive and unified namespace for the entire system, but also ensure data security (dual-system hot backup).
2.5 Metadata Manager
2.5.1 Design purpose
The design purpose of the metadata manager is that the whole system needs a unified and coordinated component to guide the data writing of the front-end business system, notify the real-time processing of some data types and other data descriptions, and guide how to land the data. The metadata manager runs through the entire system and is an important part.
2.5.2 Metadata Design
Metadata design can use mysql to store metadata information, combined with open source software design of caching mechanism.
3 Related instructions
3.1 About Storm and Hadoop comparison
Storm is concerned with data being processed multiple times and written once, while Hadoop is concerned with data being written once and processed multiple times (queries). After the Storm system is running, it is continuous, while Hadoop often only calls data when the business needs it.
The directions of attention and application of the two are different.
3.2 Application Prospects of Storm
At present, more and more companies are using Storm, such as some recommendation systems, financial systems, and also in smaller application scenarios, such as early warning systems, website statistics, etc. It has a natural ability in data processing. Advantage.
Overall, Storm still has a good prospect in the case of an increasing amount of data and more and more data needs to be processed and mined.