
Author | Chris
Introduction
This article describes that in order to improve the efficiency of data observation, analysis, and decision-making on the production and transportation side and support rapid business iteration, the Mobile Ecological Data R&D Department completed the upgrade of the data warehouse modeling and BI tools and adopted a solution that combines wide table modeling with the TDA platform. , one-stop self-service solution to data application needs. During this process, the data delivery model has changed, from customized R&D development to self-service acquisition of production and transportation, making business-side data acquisition more convenient, faster, and more accurate.
The full text is 3540 words, and the estimated reading time is 9 minutes.
01 Background and Objectives
1.1 Background
In the era of big data, analyzing and mining high-value information based on massive data to guide and drive rapid business development is the basic capability and value of data construction.
Data-driven business requires us to build a comprehensive, accurate, timely, and easy-to-use data warehouse on the one hand. On the other hand, we also need to build a unified data visualization platform that integrates adhoc query, data analysis, data reporting and other application capabilities to make the business efficient and Obtain data conveniently and accurately to empower business growth.
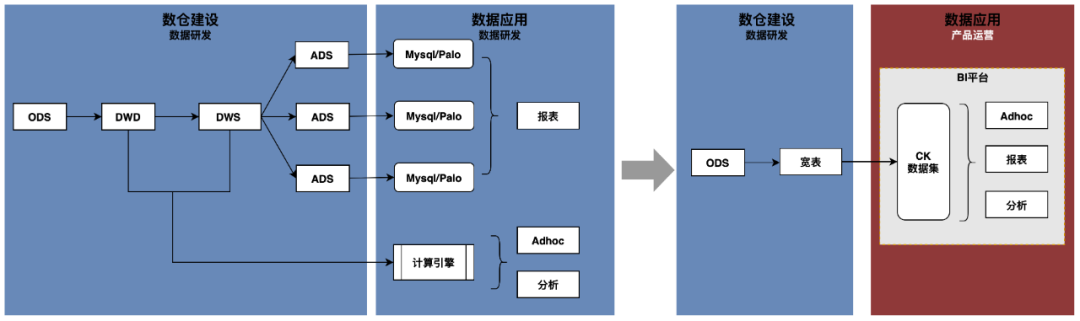
The industry usually uses hierarchical models to build data warehouses, modeling layer by layer from ODS>DWD>DWS>ADS, and customizing the development of the ADS layer to meet business side needs. Under this model, complex and changeable business scenarios require the participation of data research and development. The data acquisition time depends on the development side scheduling. The customized results are not flexible enough and require frequent iterations. The ADS layer takes up a relatively high proportion of data research and development time. As business develops faster and faster, data requirements increase significantly, the required labor costs increase, and delivery efficiency decreases. Therefore, it is necessary to explore new data development and delivery models to complete the transformation from customized R&D development to self-service acquisition of production and transportation.
Taking into account the transformation of data application groups from research and development to production and operation, the threshold for using data needs to be further lowered, and there are higher requirements for the use experience of data warehouses and data visualization platforms.
1.2 Objectives
The user experience of the data warehouse is reflected in the wide table layer of direct interaction. The ideal wide table should meet the following points:
1. Comprehensive : The coverage scenarios are rich enough to meet all business needs.
2. Accurate : The logic is unified and converged, the caliber is simple and clear, and the business usage is unambiguous.
3. Timely : Solve the barrel effect caused by the difference in upstream timeliness, and fields are output in batches
4. Ease of use : Demand scenarios can be obtained through a single wide table to avoid multi-table correlation.
The data platform needs to consider users' differentiated SQL capabilities, analysis habits, and analysis methods, and satisfy user experience in terms of data visualization, data computing performance, etc.:
1. Visualization : drag-and-drop construction, rich operators and styles
2. Computing performance : second-level query time consumption
Based on the above ideas, we explore wide table modeling to replace hierarchical modeling, and introduce the TDA platform to support self-service acquisition of required data in production and transportation through the combination of data warehouse models and data visualization platforms.
02 Wide table modeling
The B-side business scenario of the content ecosystem is complex, with 300+ ODS layer tables from traffic logs, business data and cluster data. In order to balance data timeliness and ease of use, 500+ DWD, DWS and ADS tables were constructed, with table kinship Problems include complex relationships, redundant intermediate tables, inconsistent data calibers, and high SQL complexity.
In order to solve the above problems, a wide table modeling solution is proposed: divide the theme according to product functions and business scenarios, clarify the finest granularity of the theme and all business processes, and directly build a wide table layer based on the ODS table. The wide table covers all fields required by the business and supports All data application scenarios such as ad hoc analysis and report query.
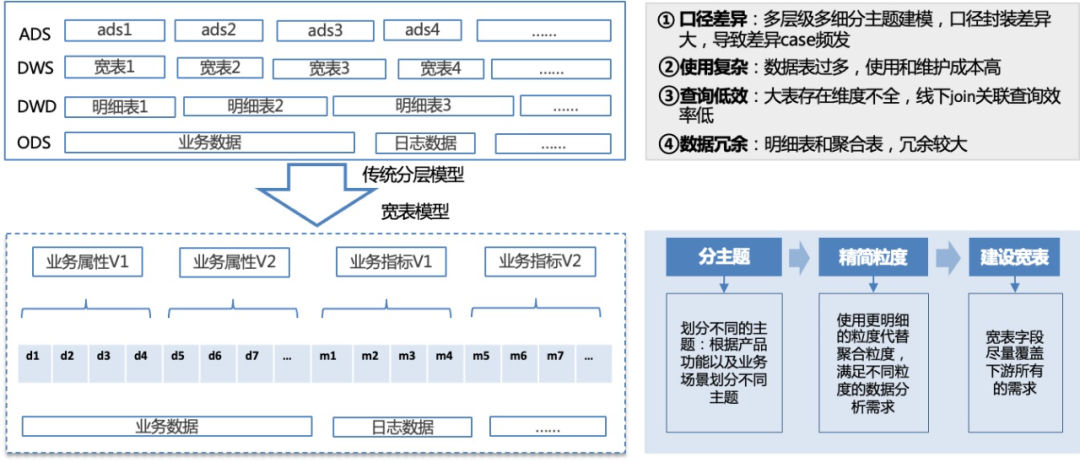
△Evolution ideas for data warehouse modeling
2.1 Technical solution
Since the wide table itself has many upstream data sources and a large amount of data, when the readiness times of multiple upstream data are different, the output timeliness of the wide table will have a barrel effect. In addition, in order to cover all business requirements as much as possible, a large amount of processing logic and associated calculations are encapsulated, making the code more complex and causing very high maintenance and backtracking costs. In order to solve the above problems, a multi-version solution for wide table modeling was explored and implemented. According to the timeliness difference of the data, the wide table is split into multiple computing tasks. Each task produces part of the fields of the wide table, and the data is merged according to the configuration, and finally a complete wide table is produced.
The output timeliness of the same version on different dates due to the influence of the upstream data source is uncontrollable. In order to improve the overall timeliness of the wide table, each version of the data needs to be merged into the wide table as soon as possible after output, and after the merger, a dependency checking mechanism needs to be provided for the downstream. Sense that the version field has been generated.
2.1.1 Multi-version merge
In order to ensure that each version of the data is merged into the wide table as soon as possible after it is produced, and to avoid data confusion caused by two merge tasks running in the same partition at the same time, a distributed lock service is introduced to determine whether a merge is required by preempting the lock successfully. The overall flow chart is as follows:
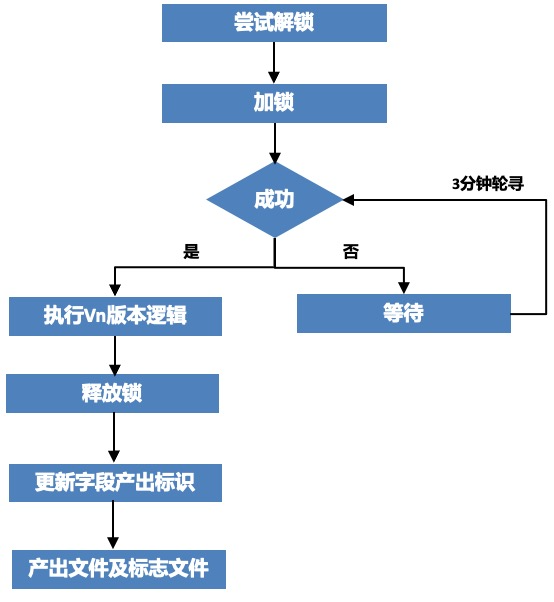
△Multi-version merging process
The dimensions of locking are table name and date partition. Whether the locking is successful is determined based on the lock status, task status and expiration time:
1. The lock is not occupied , indicating that there are currently no other merge tasks and the task is successfully locked.
2. The lock is occupied and the task status is abnormal, indicating that the current merge task failed, and the task was forced to unlock and lock successfully.
3. The lock is occupied , the task status is Accept, and the lock occupied time exceeds the expiration time. After Killing the running task, the task is forcibly unlocked and locked successfully.
In the multi-version merging solution, in order to improve the versatility of the wide table merging task, common merging logic is extracted, and based on the configuration file, the files after the versioned data are merged into the wide table. The configuration file covers multiple sets of file addresses, association conditions, association types and field information. Each file address is generated by an independent task, which is responsible for the relevant logic of the data source. Changes in the data caliber only need to change the corresponding task, and the maintenance cost is low.
2.1.2 Downstream dependencies
Fields in multi-version wide tables are generated in different versions based on time differences. Therefore, a dependency checking mechanism needs to be provided so that downstream can use ready fields in a timely manner to meet high time-efficiency data application scenarios. The solution provides three different dependency checking methods:
1. Task group dependency : Dependency check is performed through the task name of the scheduling platform, and pingo and tds scheduling platforms in the factory are supported.
2. AFS file dependency : After a certain version is merged into the wide table, an AFS identification file with a successful task for that version will be generated, which can be used for dependency checks downstream.
3. Field output detection service : For data application platforms (such as Yimai, TDA, etc.), the platform cannot rely on task groups and AFS files to identify whether the queried fields are output. For these scenarios, a field detection service is provided. After a certain version is merged into a wide table, the output identification of the relevant fields of that version in the detection service will be updated. The data application platform determines that the fields of this query are within the query time range through API interface calls. Whether the internal data is ready to ensure data availability
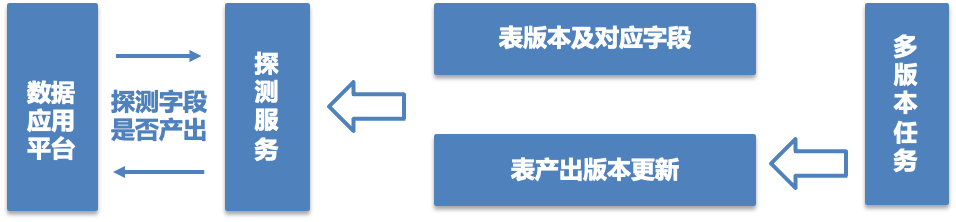
△Field detection service
2.2 Advantages of wide tables
-
In terms of cost : the classic hierarchical data warehouse has serious redundancy between layers. The use of wide table modeling avoids the construction of numerous DWD and DWS layer tables. There are only one or two wide tables in a topic. The number of tables in the data warehouse A 60% reduction and a 30% reduction in storage. In addition, the simplification of tables has reduced data tasks. Data queries have also been optimized from the association of multiple DWD and DWS tables to one wide table, avoiding a large number of shuffle operations. The time of ad hoc queries has been shortened from minutes to seconds, and computing resources have been greatly reduced. Save 20%.
-
In terms of quality : the fields of the wide table are very rich, reaching thousands, covering all business scenarios of the theme as much as possible, so the data of the application layer can be completely converged to the wide table layer, eliminating the redundancy and logic of the tables in the hierarchical data warehouse The caliber inconsistency problem caused by incomplete sinking is based on the wide surface management indicator caliber on the product side, so communication is smoother and data accuracy is higher.
-
In terms of efficiency : the wide table model is very easy to use. Complex requirements can be met with a single wide table. All data can be obtained with basic SQL capabilities, and the business experience is very good.
03 Visualization platform
Common data needs are divided into three categories: temporary data collection, report development, and data analysis. For temporary data collection scenarios, the wide table model's comprehensive business coverage and ease of data acquisition can support the production and transportation side to obtain data through simple SQL spelling; for report development scenarios, data research and development is still required to build ADS layer application tables , and synchronize to OLAP storage, and use reporting platforms such as Sugar for configuration; for data analysis scenarios, the production and operation side can obtain analysis data based on wide tables, but it needs to save flexible and changeable analysis results and display them visually, which results in a poor experience.
The wide table model greatly simplifies the complexity of data query and provides basic capabilities for self-service data acquisition. The data visualization capabilities required for reports and data analysis have become obstacles to self-service data acquisition in production and transportation. In this regard, the TDA data visualization platform is introduced to support data analysis and drag-and-drop construction of dashboards. It has rich data processing and analysis capabilities and can solve data application needs in one stop.
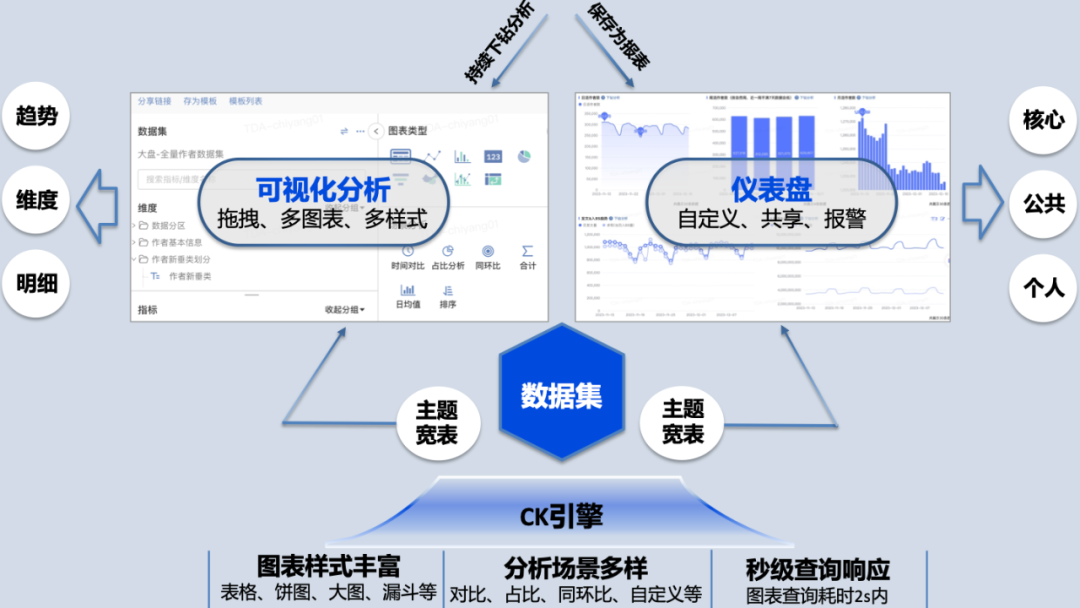
△Self-service idea
Under this mode, data R&D students are responsible for the construction, synchronization and query performance optimization of subject wide tables, data product students are responsible for the configuration of data sets, and operation students conduct visual analysis and dashboard configuration based on data sets to achieve self-service data applications.
Wide table construction: Build a topic wide table according to the idea of wide table modeling.
Data synchronization: Data is synchronized from HDFS to ClickHouse. The synchronization task is started after each version of the data warehouse wide table is produced, and the keys of distinct query scenarios are shuffled during the data synchronization phase.
Performance optimization: In order to optimize query time, two mechanisms, caching and automatic rolling, are introduced. Caching includes two situations: the first time the user queries, the query results are cached; based on the user query history, user queries are simulated through offline task polling, and the query results are updated in the cache. Automatic scrolling is based on the characteristics of user historical query records and performs projection aggregation on high-frequency dimensions. Currently, for tens of millions of data query scenarios, the query takes seconds.
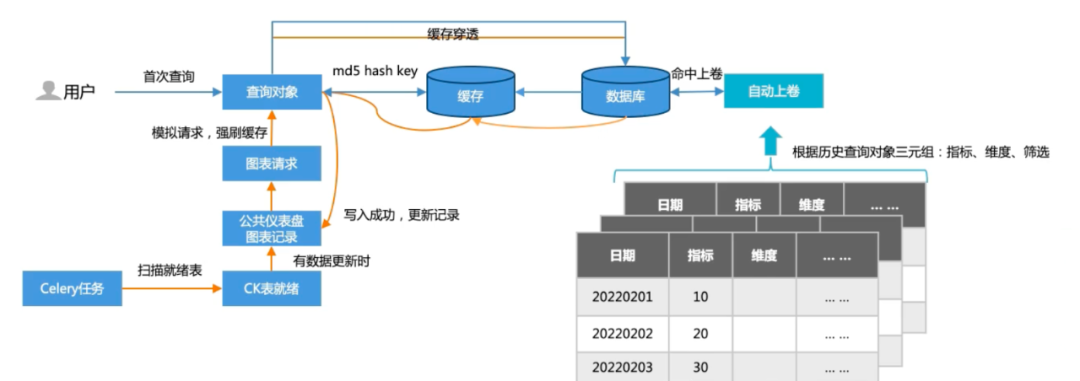
△Cache + automatic rolling mechanism
04 Summary
Through the combination of the data warehouse wide table model and the data visualization platform, the transformation of data requirements from R&D customized development to self-service acquisition of production and transportation has been completed. The flexibility and efficiency of data analysis have been greatly improved, and labor costs have been reduced.
1. The demand for R&D undertakings dropped by 57%, of which the proportion of data application demand dropped from 60% to 10%.
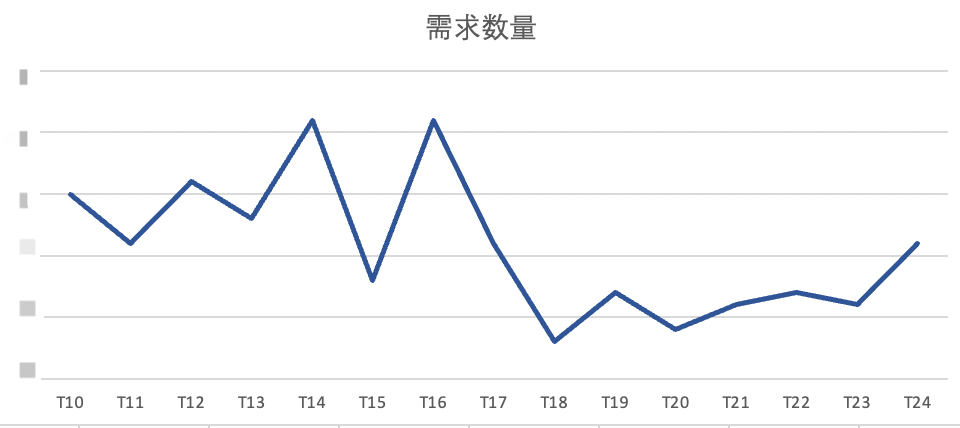
△Required quantity
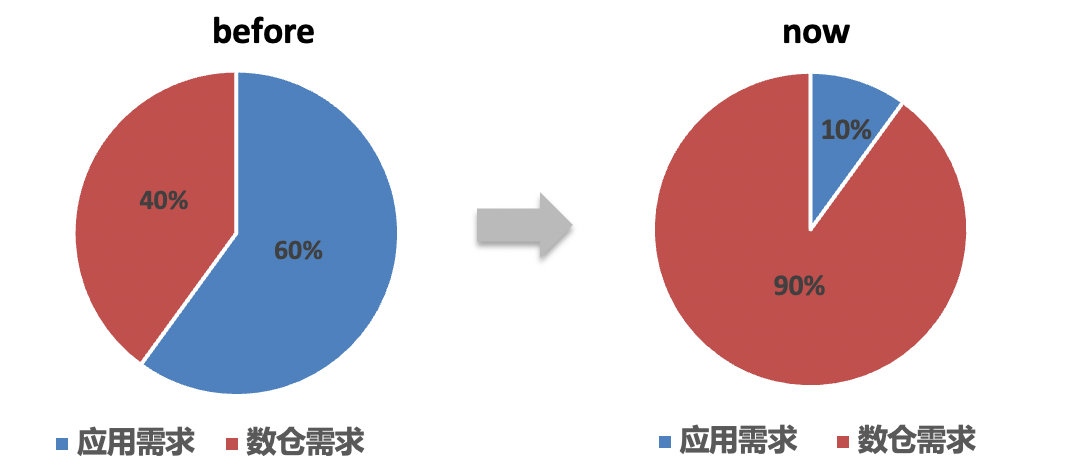
2. The visual analysis scenario has a daily PV of 4,000+, and the overall data demand self-service rate reaches 92%.
3. The time taken for a single query is shortened from minutes to seconds.
4. The report development cycle is shortened from days to hours.
——END——
Recommended reading
Baidu search exgraph graph execution engine design and practice
Sharing experience of “stepping on pitfalls”: Swift language implementation practice
Mobile anti-screenshot and screen recording technology is implemented in Baidu account system
AI Native Engineering: Baidu App AI Interactive Technology Practice
TIOBE 2023 Programming Language of the Year: C# A middle school purchased an "intelligent interactive catharsis device" - which was actually a shell for Nintendo Wii. Follow-up to the incident of female executives firing employees: The company chairman called employees "habitual offenders" and questioned the "falsification of academic qualifications and resumes" open source artifact LSPosed announced that it would stop updating. The author said that he had suffered a large number of malicious attacks and was illegally fired by a female executive. Employees spoke out and were targeted for opposing the use of pirated EDA tools to design chips. Linux Kernel 6.7 was officially released. Luo Yonghao claimed that "Glory Any Door" plagiarized the Hammer open source software One Step Chinese JDK. The tutorial website is officially launched to help developers master the Java programming language . In 2024, will the development language of the Linux kernel be converted from C to C++? "Xie Yihui", a well-known developer in the R language community, was fired from RStudio/Posit