This is an article published in 2022 IEEE TRANSACTIONS ON INFORMATION FORENSICS AND SECURITY (TIFS)
Table of contents
abstract
Traditional federated learning is susceptible to poisoning attacks by malicious clients and servers. In this paper, a privacy-preserving Byzantine robust federated learning (PBFL) based on a blockchain system is designed. We use cosine similarity to determine the maliciousness of uploaded files by malicious clients. gradient. Finally, we use blockchain system to facilitate transparent processes and implementation of regulations. Finally, we use a blockchain system to facilitate transparent processes and enforcement of regulations.
Main contributions
1. We provide a privacy-preserving training mechanism by using the fully homomorphic encryption (FHE) scheme CKKS
, which not only greatly reduces the computing and communication overhead, but also prevents attackers from snooping on the client's local data . 2. We use cosine similarity Removing malicious gradients provides a trustworthy global model that is resistant to poisoning attacks.
3. We use blockchain to promote transparent processes and enforcement of regulations. The server performs off-chain calculations and uploads the results to the blockchain , which achieves efficiency and credibility
4. Experimental comparison
II. RELATED WORK
B. Blockchain-Based Federated Learning
Traditional federated learning relies heavily on the participation of servers, resulting in single points of failure.
Blockchain decentralization replaces servers, eliminating the threat of single points of failure and malicious behavior of servers.
Ramanan et al. [18] introduced a blockchain-based FL solution named BAFFLE, which uses smart contracts (SC) to aggregate local models. Compared with traditional methods, baffles avoid single points of failure and reduce gas costs for blockchain FL. Similarly, Kim et al. [37] proposed BlockFL, where local model updates are exchanged and verified through smart contracts pre-deployed on the blockchain. BlockFL not only overcomes the single point of failure problem, but also facilitates the integration of more devices and a larger number of training samples by providing incentives proportional to the training sample size. However, the above solutions aggregate local models through smart contracts , which imposes heavy computational and communication burdens on nodes in the blockchain network . Furthermore, these solutions cannot distinguish malicious gradients. To address these issues, Li et al. [33] proposed a blockchain-based federated learning framework for committee consensus (BFLC), which effectively reduces the amount of consensus calculation and prevents malicious attacks. However, the committee's selection criteria is an issue that needs to be addressed.
III. PRELIMINARIES
A.Federated Learning
In the standard federated learning setting, nnn customers{ C 1 , C 2 , . . . , C n } \{C_1,C_2,...,C_n\}{
C1,C2,...,Cn} Each client has a local data setD j , j = 1 , 2 , 3 , . . . , n D_j,j=1,2,3,...,nDj,j=1,2,3,...,n且D = { D 1 , D 2 , . . . , D n } D=\{D_1,D_2,...,D_n\}D={
D1,D2,...,Dn} represents the combined data set,iii round clientC j C_jCjUse local data set and model parameters wi − 1 w_{i-1} received from central serverwi−1To train the local model, the optimized objective function is as equation (1)
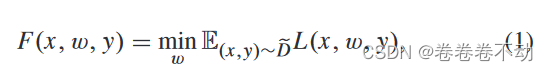
xxx is the training data,yyy is the labelL ( x , w , y ) L(x,w,y)L(x,w,y ) is the empirical loss function. The central aggregation receives parameters from the client such as equation (2), whereζ ij = ∣ D j ∣ ∣ D ∣ \zeta_i^j=\frac{|D_j|}{|D| }gij=∣D∣∣Dj∣
B. Poisoning Attacks
It is well known that federated learning is vulnerable to poisoning attacks. In a poison attack, the opponent controls κ κκThe client manipulates the local model and ultimately affects the global modelwww accuracy. Depending on the opponent's goals, poisoning attacks can be divided into targeted attacks and untargeted attacks. Targeted attacks, such as scaling attacks, target only one or a few data categories in a dataset while maintaining the accuracy of other categories of data. Non-target attacks, such as Krum attacks and Trim attacks, are indiscriminate attacks that aim to reduce the accuracy of all data categories.
In order to reduce the global model www accuracy, data poisoning attacks and model poisoning attacks are usually launched based on the opponent's capabilities. In a data poisoning attack (i.e., label flipping attack), the adversary indirectly poisons the global model by poisoning the local data of the device. In a model poisoning attack, the adversary can directly manipulate and control model updates communicated between the device and the server, which directly affects the accuracy of the global model. Therefore, model poisoning attacks usually have a greater impact on FL than data poisoning attacks.
Cheon-Kim-Kim-Song (A FHE sheme)
CKKS allows encryption on floating point numbers and vectors, with its own unique encoding, decoding and rescaling mechanisms.


smart contract
A smart contract is a piece of code written on the blockchain. Once an event triggers the terms in the contract, the code is automatically executed. In other words, it will be executed when conditions are met, without human control. Blockchain is very consistent with smart contracts, because many characteristics of blockchain, such as decentralization, non-tampering of data, etc., can be used from a technical perspective. Solve the problem of trust between strangers.
IV. PROBLEM FORMULATION
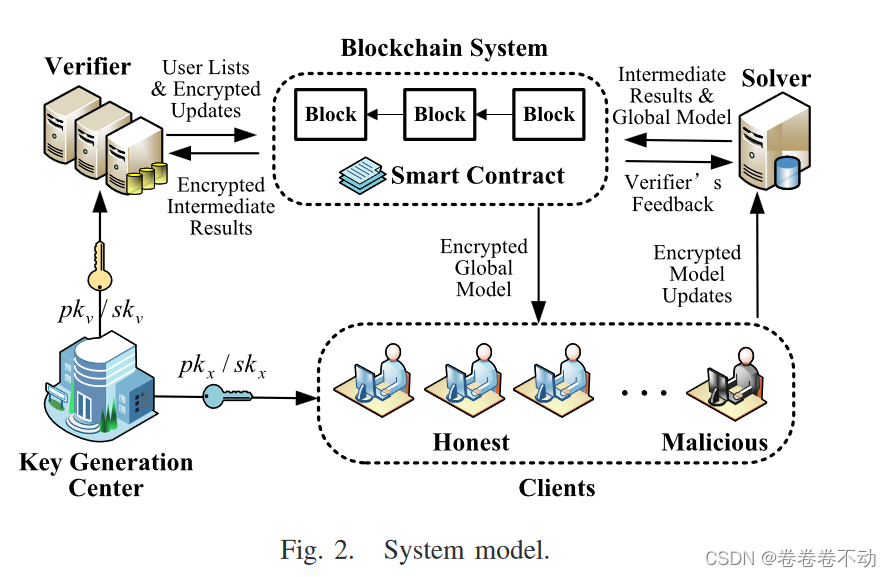
The system model includes five entities: key distribution center, client, solver, verifier, and blockchain center system.
Key Generation Center (KGC) : a trusted authoritative center that generates public and private key pairs for clients and verifiers;
Clients : data owners, clients have (pkk, skk) (pk_k,sk_k) provided by KGC(pkk,skk) , the purpose is to benefit from the common global model.
Solver: Have a small and clean data setD 0 D_0D0A central server, the solver, is responsible for aggregating all gradients submitted by clients.
Verifier : A non-colluding central server that cooperates with the solvers and also has a pair of KGCs controlled by KGCK GC generated public key private key pair(pkv, skv) (pk_v,sk_v)(pkv,skv)
Blockchain System: To avoid selfish behavior, the central server needs to place deposits on SC (smart contracts) to obtain potential penalties. In addition, the results need to be uploaded to the blockchain to achieve a transparent calculation process.
The process of the entire system entity is:
First, the client performs normalization, usingpkv pk_vpkvThe local gradients are encrypted, and the solver and verifier communicate in multiple rounds to build a user list without leaking privacy, where the client normalizes the gradients honestly. The communication process is recorded in the blockchain, and the solver aggregates the gradients of the clients in the user list to obtain a pkx pk_xpkxEncrypted global model, stored in the blockchain. Both solver and validator clients need to pay a deposit to the smart contract.
B.Problem definition
Different from the traditional secure aggregation scenario, we consider a federated learning scenario with nnkkamong n clientsk malicious client. First, we willkkThe knowledge and capabilities of k malicious clients are defined as follows:
(1) A malicious client may retain its own poisonous data, but cannot access the local data of other honest clients.
(2) A malicious client can obtain the encrypted global model and decrypt it to obtain information. However, local model updates uploaded by a single honest client cannot be observed.
(3) Malicious clients can collude with each other and have a common goal to expand the impact of their malicious attacks.
(4) Malicious clients can launch targeted attacks or untargeted attacks.
Malicious clients can steer the global model in the wrong direction.
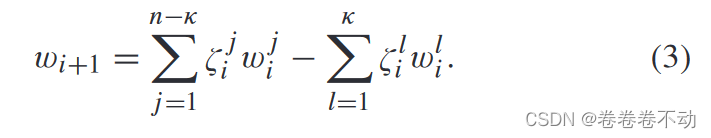
A malicious client can also affect the accuracy of the global model.
C. Threat model
KGC KGCK GC is an honest third party. Solvers and verifiers are not colluding, but are honest and curious. They will implement the established protocol honestly, but may be curious to infer some sensitive information. This article considers two types of customers: 1. Honest gains from the global model, uploading real gradients trained on local data sets. 2. Malicious clients upload malicious gradients to reduce the accuracy of the global model. The threats posed are as follows:
Poisoning attack: The goal of a malicious client is to affect the performance of the global model without being detected. Malicious clients can launch poisoning attacks in a variety of ways. For example, he/she changes the labels of the data and uploads gradients trained on toxic data.
Data leakage: Since the gradient is a mapping of the client's local data, if the client directly uploads the plaintext gradient, the attacker can infer or obtain the original information of the honest client to a certain extent, resulting in client data leakage.
Inference attack: In our scheme, solver andVerifier VerifierVeri fier exchanges some intermediate results to complete the aggregation of local updates . Therefore, they may attempt to infer sensitive information from intermediate results.
D.Design goals
Our goal is to design a blockchain-based privacy-preserving FL scheme that can resist poisoning attacks, reduce computational overhead, and provide privacy guarantees. At the same time, our scheme should achieve the same or almost the same accuracy as FedAvg or FedSGD. Specifically, we are committed to achieving the following goals:
primarily achieving robustness, privacy, efficiency, accuracy, and reliability.
Design
This solution uses CKKS homomorphic encryption. Compared with Pillier through experiments, CKKS has higher efficiency.
Additionally, we need to consider that a malicious client may disrupt the training process by sending malicious gradients, while an "honest but curious" central server may infer sensitive information about the client.
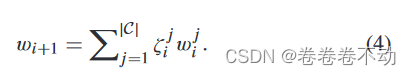
C \mathcal{C}C is defined as the set of honest normalized clients selected according to our rules∣ C ∣ |\mathcal{C}|∣C∣ is the quantity.
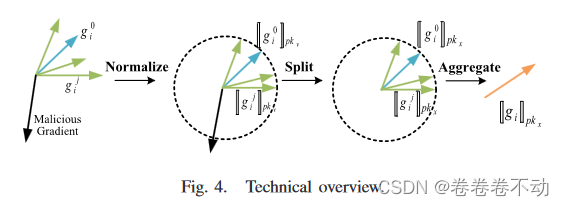
Each client encrypts and normalizes local updates and sends them to the Solver (solver). The normalized gradients are put into the setC \mathcal{C}C and use cosine similarity to judge honest and malicious gradients. Specific method: Store a clean and small data set D 0 D_0
in SolverD0(root data set), and maintain a global model w 0 w_0 based on this data setw0if gj 0 g_j^0gj0and gij g_i^jgijThe cosine similarity of is less than 0, then client C j C_jCjIt's just malicious. A Solver will be in the iiDiscardgij g_i^j in round igij
The gradient size will also affect the global model. In case the client will use a larger gradient to increase its influence, it needs to be normalized before sending to the solver. However, a malicious client may upload gradients that have not been normalized. In order to solve this problem, the plan introduces a central Solver that will not collude. Through communication between Solver and Verifier, Solver obtains the honest and normalized client set and uses pkx pk_xpkxEncrypted local updates. Finally, the solver aggregates local updates to obtain the global model.
In order to prevent malicious behavior of the central server and reduce the risk of single point of failure, user list C \mathcal{C}The intermediate results of C and the collaborative calculation of Solver and Verifier need to be saved to the blockchain. Specifically, Solver and Verifier pay a deposit to the smart contract to encourage them to perform correct calculations. In addition, the intermediate results of each training iteration and the encrypted global model are saved to the blockchain for timely backtracking in the event of a central server failure, increasing the reliability of the scheme.
B. Construction of PBFL
PBFL has three processes: local calculation, normalized judgment, and model aggregation.
local computing
Local computation: includes local training, normalization, encryption, and model updates.
Local Training


Normalization
The aggregation rule is based on cosine similarity. To make our aggregation rule work in ciphertext, we normalize the local gradients before encryption. Gradient is treated as a direction vector.
For each client C j C_jCjUse the following equation to normalize.

Each client needs to normalize local gradients before encryption. First, the normalization operation allows our aggregation rules to be applied directly to the ciphertext without any changes. Because we convert the cosine similarity into the inner product of vectors due to normalization. Second, the vectors are of the same size, which mitigates the impact of malicious gradients. This is based on the intuition that malicious clients tend to upload local gradients with larger magnitudes in order to amplify their impact.
Encryption
Client C j C_jCjUse public key pkv pk_vpkvTo encrypt g ~ ij \tilde{g}_i^jg~ij(CKKS), gradients are usually signed floating point numbers. If another encryption scheme is used, such as Paillier, we first need to quantize and clip the gradient values, and then encrypt each value individually, which will undoubtedly incur high computational overhead. Therefore, we use CKKS to encrypt local gradients.
Put g ~ ij \tilde{g}_i^j of each layerg~ijTreated as a vector, specifically the public key pkv pk_v of each client using VerifierpkvDirectly encrypt the gradients of different layers. If the length of the vector is too long, we encrypt it multiple times. For the rest of the vectors, we encrypt it once.
Model update
client C j C_jCjDownload the latest global model from the blockchain using the private key skx sk_xskxGet the plaintext global model wi − 1 w_{i-1}wi−1The local model is updated as follows:
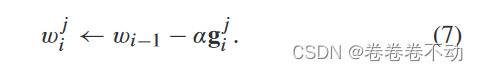
α \alphaα is the learning rate
normalized judgment
The Solver needs to determine whether the gradient is truly normalized after receiving it from the client.
After receiving the encrypted gradient [ [ g ~ ij ] ] pkv [\![\tilde{g}_i^j]\!]_{pk_v}[[g~ij]]pkvSolver will calculate [ [ g ~ ij ] ] pkv ⊙ [ [ g ~ ij ] ] pkv [\![\tilde{g}_i^j]\!]_{pk_v}\odot[\![ \tilde{g}_i^j]\!]_{pk_v}[[g~ij]]pkv⊙[[g~ij]]pkvSent to Verifier, ⊙ \odot⊙ stands for inner product.
Specifically, CKKS uses polynomials because it provides a good trade-off between safety and efficiency compared to standard calculations of vectors. Once a message has been encrypted into several polynomials, CKKS provides several operations that can be performed on it, such as addition, multiplication, and rotation. The specific details are as follows.
Assumen ∗ n^*n∗ -dimensional vector[ [ g ~ ij ] ] pkv [\![\tilde{g}_i^j]\!]_{pk_v}[[g~ij]]pkvExpressed as [ [ p 1 , p 2 . . . pn ∗ ] ] pkv [\![p_1,p_2...p_{n^*}]\!]_{pk_v}[[p1,p2...pn∗]]pkv, obtain the inner product by multiplication [ [ p 1 2 , p 2 2 . . . pn ∗ 2 ] ] pkv [\![p_1^2,p_2^2...p_{n^*}^2] \!]_{pk_v}[[p12,p22...pn∗2]]pkv Rotate to obtain [ [ p 2 2 , p 3 2 . . . pn ∗ 2 , p 1 2 ] ] pkv [\![p_2^2,p_3^2...p_{n^*}^2,p_1 ^2]\!]_{pk_v}[[p22,p32...pn∗2,p12]]pkvThen add these two vectors. Repeat the rotation and addition operations ( n ∗ − 1 n^*-1n∗−1 time), obtain[ [ r 1 , r 2 . . . rn ∗ ] ] pkv [\![r_1,r_2...r_{n^*}]\!]_{pk_v}[[r1,r2...rn∗]]pkvRatio r 1 = p 1 2 + p 2 2 + p 3 2 + . . . . . . . . pn ∗ 2 r_1=p_1^2+p_2^2+p_3^2+...p_{n^*}^2r1=p12+p22+p32+...pn∗2Then [ [ r 1 , r 2 . . . rn ∗ ] ] pkv [\![r_1,r_2...r_{n^*}]\!]_{pk_v}[[r1,r2...rn∗]]pkvWith [ 1 , 0 , 0 , . . . 0 ] [1,0,0,...0][1,0,0,...0 ] multiply to obtain[ [ r 1 ] ] pkv = [ [ g ~ ij ] ] pkv ⊙ [ [ g ~ ij ] ] pkv [\![r_1]\!]_{ pk_v}=[\![\tilde{g}_i^j]\!]_{pk_v}\odot[\![\tilde{g}_i^j]\!]_{pk_v}[[r1]]pkv=[[g~ij]]pkv⊙[[g~ij]]pkv

Model aggregation
After receiving user list CC from VerifierAfter C , the Solver safely aggregates the collectionCCClient-uploaded gradients in C. Specifically, the solver and verifier first safely execute a protocol that enables the solver to obtain intermediate results and usepkx pk_xpkxEncrypted local model updates. The Solver then obtains the encrypted global model based on predefined aggregation rules and uploads it to the blockchain.
Two-party calculation: Sover will first calculate [ [ g ~ i 0 ] ] pkv [\![\tilde{g}_i^0]\!]_{pk_v}[[g~i0]]pkv和 [ [ g ~ i j ] ] p k v [\![\tilde{g}_i^j]\!]_{pk_v} [[g~ij]]pkvThe cosine similarity is then communicated with Verifier. Our aggregation rules rely on the honest root node D 0 D_0D0and the associated model w 0 w^0w0 , this is also used to decide the expected update direction of the global model, so it is the same asgi 0 g_i^0gi0More similar directions will have greater weight
D 0 D_0 during aggregationD0Data set can be achieved by manual labeling, collecting trusted root data set D 0 D_0D0and the cost of manual labeling is usually affordable by the solver
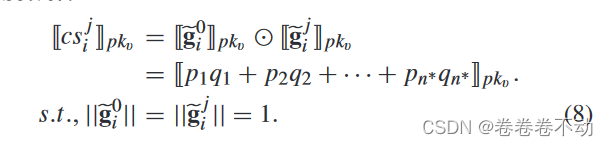
in Section iiDuring the i- round iteration, the Solver is in the data set D 0 D_0D0On training, obtain gradient update gi 0 g_i^0gi0After using g ~ i 0 = gi 0 / ∣ ∣ gi 0 ∣ ∣ \tilde{g}_i^0=g_i^0/||g^0_i||g~i0=gi0/∣∣gi0∣∣Normalization . Solver encryption obtains[ [ g ~ i 0 ] ] pkv [\![\tilde{g}_i^0]\!]_{pk_v}[[g~i0]]pkv, and then calculate the cosine similarity according to the above formula. where C j C_jCjObtain g ~ ij = [ p 1 , p 2 , . . . pn ∗ ] \tilde{g}_i^j=[p_1,p_2,...p_{n^*}]g~ij=[p1,p2,...pn∗],Solver获得 g ~ i 0 = [ q 1 , q 2 , . . . q n ∗ ] \tilde{g}_i^0=[q_1,q_2,...q_{n^*}] g~i0=[q1,q2,...qn∗] The gradient after encryption is[ [ p 1 , p 2 , . . . pn ∗ ] ] pkv [\![p_1,p_2,...p_{n^*}]\!]_{pk_v}[[p1,p2,...pn∗]]pkv和 [ [ q 1 , q 2 , . . . q n ∗ ] ] p k v [\![q_1,q_2,...q_{n^*}]\!]_{pk_v} [[q1,q2,...qn∗]]pkv, Because of the normalization operation, the calculation of the cosine similarity of the two vectors becomes the calculation of the inner product.
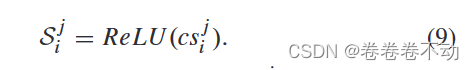
csij cs_i^jcsijMeasured [ [ g ~ i 0 ] ] pkv [\![\tilde{g}_i^0]\!]_{pk_v}[[g~i0]]pkv和 [ [ g ~ i j ] ] p k v [\![\tilde{g}_i^j]\!]_{pk_v} [[g~ij]]pkvSimilarity, negative values represent the direction opposite to the gradient direction of the data set, which will have a negative impact on the global model,
so the Relu function is used here to limit the list CCGradient in C
max function understanding
Numerical method for comparison on homomorphically encrypted numbers
Using the ReLu function requires homomorphic ciphertext comparison. The article selected the algorithm from the 2019 Yami paper "Numerical method for comparison on homomorphically encrypted numbers>". After being reminded by the teacher at the group meeting, I also looked for the algorithms in the relevant parts of the paper after the meeting. This actually first involves the calculation of the square root of positive real numbers. The original paper first proposed S qrt ( x ; d ) Sqrt (x; d)Sqrt(x;d ) Algorithm:
[The external link image transfer failed. The source site may have an anti-leeching mechanism. It is recommended to save the image and upload it directly (img-ydBrsOzr-1679397343958)(./pic/20230321_sqrt.png)] The
paper points out the above algorithm The output isS qrt ( x ; d ) Sqrt(x;d)Sqrt(x;d ) relative tox \sqrt{x}xBounded by ( 1 − x 4 ) 2 d + 1 (1-\frac{x}{4})^{2d+1}(1−4x)2 d + 1 Usually this error is negative, that is to sayS qrt ( x ; d ) Sqrt (x; d)Sqrt(x;d ) is usually less thanx \sqrt{x}x.Proof
: Because − 1 ≤ b 0 ≤ 0 -1\leq b_0\leq0−1≤b0≤0 for alln ∈ N n\in \mathbb{N}n∈N can be obtained as− 1 ≤ bn ≤ 0 -1\leq b_n\leq0−1≤bn≤0 so there are∣ bn + 1 ∣ = ∣ bn ∣ ⋅ ∣ bn ( bn − 3 ) 4 ∣ ≤ ∣ bn ∣ |b_{n+1}|=|b_n|·|\frac{b_n(b_n-3)} {4}|\leq|b_n|∣bn+1∣=∣bn∣⋅∣4bn(bn−3)∣≤∣bn∣So∣ bn + 1 ∣ ≤ ∣ bn ∣ 2 ⋅ ( 1 − x 4 ) |b_{n +1}|\leq |b_n|^2·(1-\frac{x}{4})∣bn+1∣≤∣bn∣2⋅(1−4x) gets∣bn∣ |b_n|∣bn∣ and∣bn + 1 ∣ |b_{n+1}|∣bn+1The recurrence relation of ∣
can be obtained by recursion: ∣ bd ∣ ≤ ∣ b 0 ∣ 2 d ⋅ ( 1 − x 4 ) 2 d − 1 < ( 1 − x 4 ) 2 d − 1 |b_d|\leq | b_0|^{2^d}·(1-\frac{x}{4})^{2^d-1}<(1-\frac{x}{4})^{2^d-1}∣bd∣≤∣b0∣2d⋅(1−4x)2d−1<(1−4x)2d −1,
bybn b_nbn和an a_nanThe definition of can be obtained by the equation x ( 1 + bn ) = an 2 x(1+b_n)=a_n^2x(1+bn)=an2Further get the relationship:
∣ an − xx ∣ = 1 − 1 + bn < ∣ bn ∣ |\frac{a_n-\sqrt{x}}{\sqrt{x}}|=1-\sqrt{1+b_n}< |b_n|∣xan−x∣=1−1+bn<∣bn∣So
if we take a large integer d, the error will be very small, so the algorithmx \sqrt{x}xThe correctness can be verified.
max algorithm
This part is also easier to understand. For finding min (a, b) min(a,b)min(a,b)和 m a x ( a , b ) max(a,b) max(a,b ) Subsystem:
min ( a , b ) = a + b 2 − ∣ a − b ∣ 2 = a + b 2 − ( a − b ) 2 2 min(a,b)=\frac{a+ b}{2}-\frac{|ab|}{2}=\frac{a+b}{2}-\frac{\sqrt{(ab)^2}}{2}min(a,b)=2a+b−2∣a−b∣=2a+b−2(a−b)2
m a x ( a , b ) = a + b 2 + ∣ a − b ∣ 2 = a + b 2 + ( a − b ) 2 2 max(a,b)=\frac{a+b}{2}+\frac{|a-b|}{2}=\frac{a+b}{2}+\frac{\sqrt{(a-b)^2}}{2} max(a,b)=2a+b+2∣a−b∣=2a+b+2(a−b)2
Correctness verification is also easier to obtain, for max maxUnder the condition of ma x , it is divided into a >= b a>=ba>=b和 a < b a<b a<After discussing the case of b , we can get max (a, b) max(a,b)max(a,b ) are respectively equal toa 2 + a 2 \frac{a}{2}+\frac{a}{2}2a+2a和 b 2 + b 2 \frac{b}{2}+\frac{b}{2} 2b+2b
So in the end we can get:
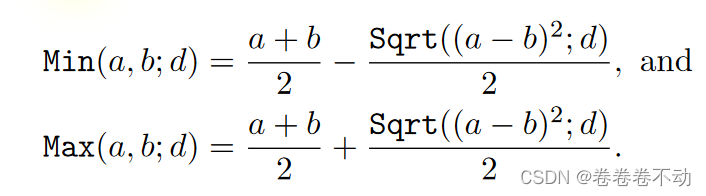
The final algorithm is

summarized as given in the paper: The design ideas here can be referred to, starting with the homomorphic ciphertext comparison algorithm on Dinghui (sub-crypto), because it meets the required range of the algorithm, and the ReLu function is transformed , which is also an idea to increase innovation points.
The calculation of the Relu function under ciphertext is given.

There is a numerical comparison method for homomorphic ciphertext in the range of [0,1], but the cosine similarity falls in [-1,1], you can add [ [ 1 ] ] [\![1]\! ][[1]] Then multiply by 1/2, so 0 becomes 1/2, change the ReLU function to ReLU'.
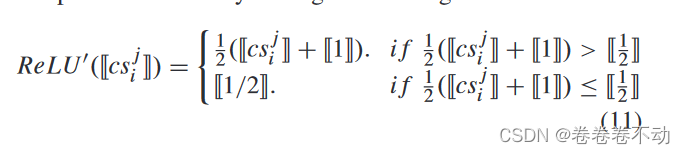
After obtaining all the scores of the client, the Solver and Verifier work together to obtain the required model aggregation without leaking privacy. value.

In previous work, dual servers were used for ciphertext level comparison, which can also be implemented in this system. IfGetParamReLu function in G e tP a r am , covering csij cs_i^jcsijThe following situations may occur. (1) The dual-server architecture may infer cjij cj_i^jcjijsymbol, which is bad for the client. (2) The communication cost between the two servers may increase.
Previous work has made it easier to implement ciphertext-level operations. Use Max Max in this scenarioThe M a x algorithm implements the ReLU function, effectively protecting the privacy of the client and reducing the total amount of communication.
polymerization:

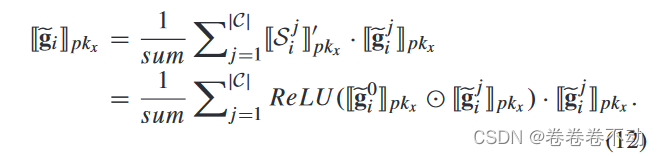

In addition, both Solver and Verifier need to submit deposits to the smart contract before joint training starts, and receive rewards for client deposits at the end of the task. Because we believe financial incentives motivate servers to perform correct calculations rather than submit meaningless or malicious results.
Regarding the data flow of the above process: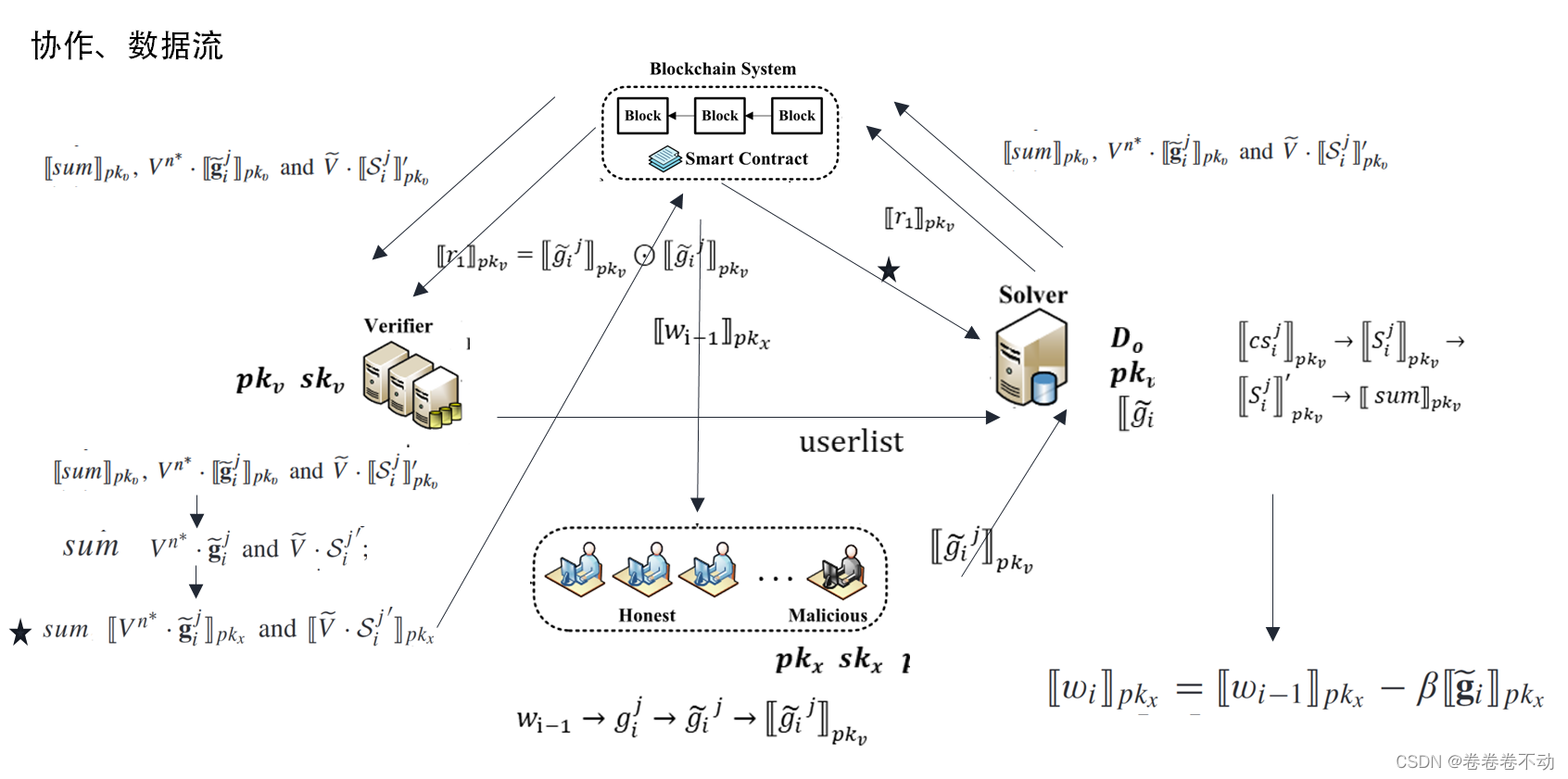
Summarize:
