Article directory
Paper information
A vertical federated learning framework for graph convolutional network

原文地址:A vertical federated learning framework for graph convolutional network:https://arxiv.org/pdf/2106.11593.pdf
Summary
Recently, Graph Neural Network (GNN) has achieved remarkable success in various real-world problems on graph data. However in most industries,data exists in the form of isolated islands and the data privacy and security is also an important issue.In this paper, we propose FedVGCN, a federated GCN learning paradigm for privacy-preserving node classification task under data vertically partitioned setting, which can be generalized to existing GCN models. Specifically, we split the computation graph data into two parts. For each iteration of the training process, the two parties transfer intermediate results to each other under homomorphic encryption. We conduct experiments on benchmark data and the results demonstrate the effectiveness of FedVGCN in the case of GraphSage.
Recently, Graph Neural Network (GNN) has achieved remarkable success in various practical problems on graph data. However, in most industries, data exists in the form of isolated islands, and data privacy and security is also an important issue. In this paper, we propose FedVGCN, a federated GCN learning framework, for the task of privacy-preserving node classification under the data vertical partition setting, and this paradigm can be generalized to existing GCN models. Specifically, we split the computational graph data into two parts. For each iteration of the training process, both parties pass intermediate results to each other under homomorphic encryption. We conduct experiments on benchmark data, and the results demonstrate the effectiveness of FedVGCN in the case of GraphSage.
Contributions
- Introduces a longitudinal federated learning algorithm for graph convolutional networks in a privacy-preserving environment, providing solutions to federated problems that cannot be solved by existing federated learning methods;
- Provides a new approach employing additive homomorphic encryption (HE) to ensure privacy while maintaining accuracy. Experimental results on 3 benchmark datasets show that our algorithm significantly outperforms GNN models trained on isolated data and achieves comparable performance to conventional GNNs trained on combined plaintext data.
Preliminaries
Orthogonal polynomial
The set of functions {Ψ0,Ψ1,...,Ψn} in the interval [a, b] is a set of orthogonal functions about the weight function Ω, if
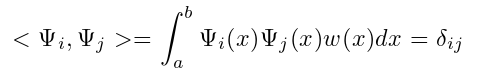
least squares approximation
Assuming f ∈ C[a, b], find an orthogonal polynomial Pn ( x ) of degree n at most to approximate f such that it is 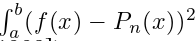 minimized.
minimized.
Make the polynomial 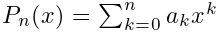 minimize the error:
minimize the error:
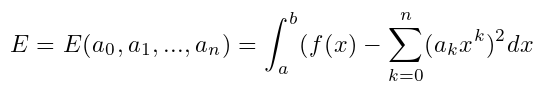
the problem is to find a0,...,an that minimizes E. The necessary condition for minimizing E is ∂E/∂aj = 0, thus giving the normal equation:
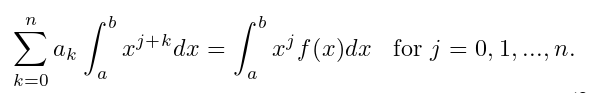
we can now find a least-squares polynomial approximation of this form:
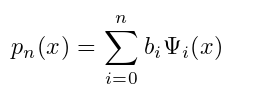
where {Ψi}i∈{0,1...,n} is A set of orthogonal polynomials. Legendre polynomials 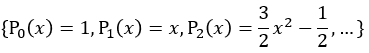 are a group of orthogonal functions about the weight function w ( x ) = 1 on the interval [ -1 , 1]. In this case, the coefficients p n of the least-squares polynomial approximation are expressed as follows:
are a group of orthogonal functions about the weight function w ( x ) = 1 on the interval [ -1 , 1]. In this case, the coefficients p n of the least-squares polynomial approximation are expressed as follows:
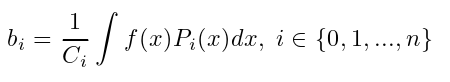
Based on this method, we can approximate the ReLU function with a quadratic polynomial as:
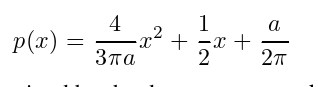
Among them, a is determined by the processed data.
Paillier Homomorphic Encryption
Homomorphic encryption allows secure computation on encrypted data. To cope with operations in deep neural networks (mainly multiplication and addition), we employ Paillier, a well-known partially homomorphic encryption system. Paillier homomorphic encryption supports unrestricted addition between ciphertexts and multiplication between ciphertexts and a scalar constant. Given a ciphertext {[[M1]], [[M2]], , [[Mg]]} and a scalar constant {s1, s2, , sg}, one can Next calculate 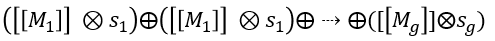 . Among them, [ [ Mg ] ] represents the ciphertext, ⊕ is the homomorphic addition with the ciphertext, and ⊗ is the homomorphic multiplication between the ciphertext and a scalar constant.
. Among them, [ [ Mg ] ] represents the ciphertext, ⊕ is the homomorphic addition with the ciphertext, and ⊗ is the homomorphic multiplication between the ciphertext and a scalar constant.
Methodology
Additive homomorphic encryption and polynomial approximation have been widely used in privacy-preserving machine learning, and the trade-off between efficiency and privacy using this type of approximation has also been discussed in depth. Here we use the second-order Taylor approximation to compute the loss and the gradient:
define: 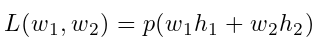 , then derive:
, then derive:
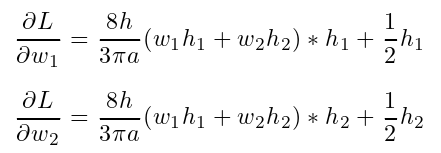
apply homomorphic encryption to L and ∂L/∂wi
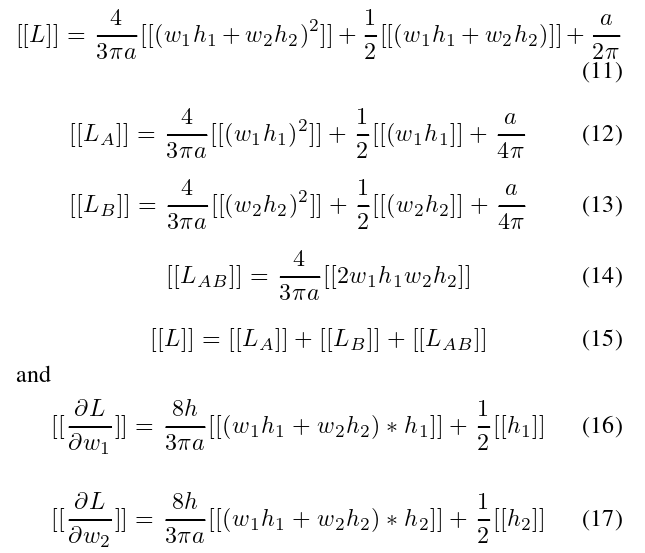
where [[x]] is the ciphertext of x. The reason for using a quadratic orthogonal polynomial to approximate/replace the relu activation is to preserve multiplication/addition under homomorphic encryption.
Suppose companies A and B want to jointly train a machine learning model, and their respective business systems have their own data. In addition, Company B also has label data that the model needs to predict. We call Company A the passive party and Company B the active party. For data privacy and security considerations, the passive and active parties cannot directly exchange data. In order to ensure the confidentiality of the data during the training process, a third-party collaborator C, called the server side, is introduced. Here we assume that the server is honest but curious, and does not collude with the passive or active party, but the passive and active parties are honest but curious. It is a reasonable assumption that the passive party trusts the server, because the server can be played by an authority such as a government, or it can be replaced by a secure computing node, such as Intel Software Guard Extensions (SGX).
Unsupervised loss function
Existing FL algorithms are mainly aimed at supervised learning. To learn useful, predictive representations in a fully unsupervised setting, we employ a graph-based loss function that encourages neighboring nodes to have similar representations, while enforcing that the representations of different nodes are highly different: where v is the

common Nodes appearing near u, σ is the sigmoid function, Pn is the negative sampling distribution, and Q defines the number of negative samples.
algorithm

In isolated GNNs, both node features and edges are held by different parties. The first step under vertical data splitting is safe ID alignment, also known as private set intersection. That is, data holders align their nodes without exposing nodes that do not overlap each other. In this work, we assume that data holders have previously aligned their nodes and are ready for privacy-preserving GNN training.
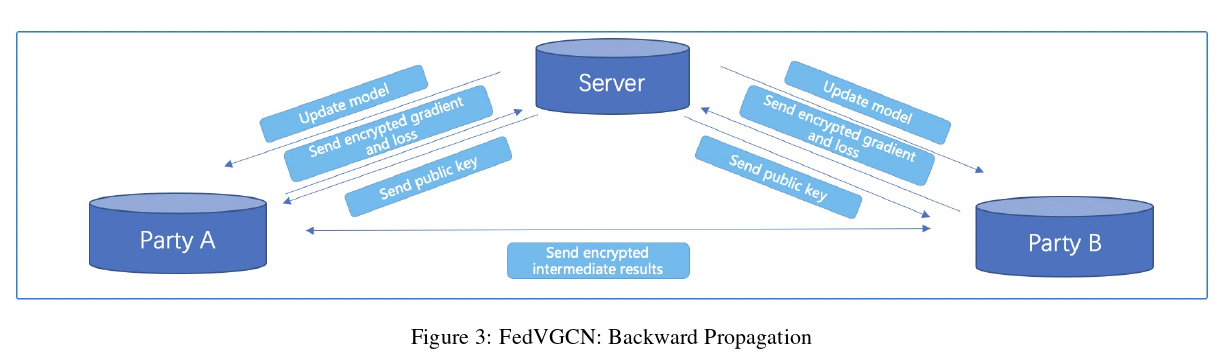
For GCN, the forward propagation and backward propagation of our proposed vertical federation algorithm are given in Algorithm 1 and Algorithm 2, respectively. In the formula, Ni is the number of sides of the i-th side. The backpropagation algorithm can be illustrated with Figure 3.

Conclusion
In this work, we introduce a new longitudinal federated learning algorithm for graph neural networks. We employ additive homomorphic encryption to guarantee privacy while maintaining accuracy. Experimental results on three benchmark datasets show that our algorithm significantly outperforms GNN models trained on isolated data and has comparable performance to conventional GNNs trained on combined plaintext data. In this paper, we mainly study the vertically federated GNN based on GraphSAGE, in the future we will extend our method to more complex GNN models, such as GAT, GIN, etc. We also plan to apply our method to real industrial applications.