Table of contents
1. SSM project integrates Redis
1.3 spring context configuration
2. Redis annotation development
3. Solve the buffering, breakdown, penetration and avalanche problems in Redis
3.1 Buffering problem - Quartz framework
3.2 Three common problem solutions
1. SSM project integrates Redis
Redis is a nosql database, and mysql is a sql database. They are both databases, so you can refer to the process of integrating the ssm project with mysql.
1.1 Import pom dependencies
<properties>
<redis.version>2.9.0</redis.version>
<redis.spring.version>1.7.1.RELEASE</redis.spring.version>
</properties>
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>${redis.version}</version>
</dependency>
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-redis</artifactId>
<version>${redis.spring.version}</version>
</dependency>
</dependencies>1.2 spring-redis.xml
- Register redis.properties
- Configure data source
- connection factory
- Configure serialization
- Configure redis key generation strategy
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context"
xmlns:cache="http://www.springframework.org/schema/cache"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd
http://www.springframework.org/schema/context
http://www.springframework.org/schema/context/spring-context.xsd
http://www.springframework.org/schema/cache
http://www.springframework.org/schema/cache/spring-cache.xsd">
<!-- 1. 引入properties配置文件 -->
<context:property-placeholder location="classpath:redis.properties" />
<!-- 2. redis连接池配置-->
<bean id="poolConfig" class="redis.clients.jedis.JedisPoolConfig">
<!--最大空闲数-->
<property name="maxIdle" value="300"/>
<!--连接池的最大数据库连接数 -->
<property name="maxTotal" value="${redis.maxTotal}"/>
<!--最大建立连接等待时间-->
<property name="maxWaitMillis" value="${redis.maxWaitMillis}"/>
<!--逐出连接的最小空闲时间 默认1800000毫秒(30分钟)-->
<property name="minEvictableIdleTimeMillis" value="${redis.minEvictableIdleTimeMillis}"/>
<!--每次逐出检查时 逐出的最大数目 如果为负数就是 : 1/abs(n), 默认3-->
<property name="numTestsPerEvictionRun" value="${redis.numTestsPerEvictionRun}"/>
<!--逐出扫描的时间间隔(毫秒) 如果为负数,则不运行逐出线程, 默认-1-->
<property name="timeBetweenEvictionRunsMillis" value="${redis.timeBetweenEvictionRunsMillis}"/>
<!--是否在从池中取出连接前进行检验,如果检验失败,则从池中去除连接并尝试取出另一个-->
<property name="testOnBorrow" value="${redis.testOnBorrow}"/>
<!--在空闲时检查有效性, 默认false -->
<property name="testWhileIdle" value="${redis.testWhileIdle}"/>
</bean>
<!-- 3. redis连接工厂 -->
<bean id="connectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory"
destroy-method="destroy">
<property name="poolConfig" ref="poolConfig"/>
<!--IP地址 -->
<property name="hostName" value="${redis.hostName}"/>
<!--端口号 -->
<property name="port" value="${redis.port}"/>
<!--如果Redis设置有密码 -->
<property name="password" value="${redis.password}"/>
<!--客户端超时时间单位是毫秒 -->
<property name="timeout" value="${redis.timeout}"/>
</bean>
<!-- 4. redis操作模板,使用该对象可以操作redis
hibernate课程中hibernatetemplete,相当于session,专门操作数据库。
-->
<bean id="redisTemplate" class="org.springframework.data.redis.core.RedisTemplate">
<property name="connectionFactory" ref="connectionFactory"/>
<!--如果不配置Serializer,那么存储的时候缺省使用String,如果用User类型存储,那么会提示错误User can't cast to String!! -->
<property name="keySerializer">
<bean class="org.springframework.data.redis.serializer.StringRedisSerializer"/>
</property>
<property name="valueSerializer">
<bean class="org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer"/>
</property>
<property name="hashKeySerializer">
<bean class="org.springframework.data.redis.serializer.StringRedisSerializer"/>
</property>
<property name="hashValueSerializer">
<bean class="org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer"/>
</property>
<!--开启事务 -->
<property name="enableTransactionSupport" value="true"/>
</bean>
<!-- 5.配置缓存管理器 -->
<bean id="redisCacheManager" class="org.springframework.data.redis.cache.RedisCacheManager">
<constructor-arg name="redisOperations" ref="redisTemplate"/>
<!--redis缓存数据过期时间单位秒-->
<property name="defaultExpiration" value="${redis.expiration}"/>
<!--是否使用缓存前缀,与cachePrefix相关-->
<property name="usePrefix" value="true"/>
<!--配置缓存前缀名称-->
<property name="cachePrefix">
<bean class="org.springframework.data.redis.cache.DefaultRedisCachePrefix">
<constructor-arg index="0" value="-cache-"/>
</bean>
</property>
</bean>
<!--6.配置缓存生成键名的生成规则-->
<bean id="cacheKeyGenerator" class="com.zking.ssm.redis.CacheKeyGenerator"></bean>
<!--7.启用缓存注解功能-->
<cache:annotation-driven cache-manager="redisCacheManager" key-generator="cacheKeyGenerator"/>
</beans>redis.properties Configuration file:
redis.hostName=localhost redis.port=6379 redis.password=123456 redis.timeout=10000 redis.maxIdle=300 redis.maxTotal=1000 redis.maxWaitMillis=1000 redis.minEvictableIdleTimeMillis=300000 redis.numTestsPerEvictionRun=1024 redis.timeBetweenEvictionRunsMillis=30000 redis.testOnBorrow=true redis.testWhileIdle=true redis.expiration=3600
1.3 spring context configuration
applicationContext.xml:
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns:context="http://www.springframework.org/schema/context" xmlns:tx="http://www.springframework.org/schema/tx"
xmlns:aop="http://www.springframework.org/schema/aop"
xsi:schemaLocation="http://www.springframework.org/schema/beans http://www.springframework.org/schema/beans/spring-beans.xsd http://www.springframework.org/schema/context http://www.springframework.org/schema/context/spring-context.xsd http://www.springframework.org/schema/tx http://www.springframework.org/schema/tx/spring-tx.xsd http://www.springframework.org/schema/aop http://www.springframework.org/schema/aop/spring-aop.xsd">
<!--1. 引入外部多文件方式 -->
<bean id="propertyConfigurer"
class="org.springframework.beans.factory.config.PropertyPlaceholderConfigurer">
<property name="systemPropertiesModeName" value="SYSTEM_PROPERTIES_MODE_OVERRIDE" />
<property name="ignoreResourceNotFound" value="true" />
<property name="locations">
<list>
<value>classpath:jdbc.properties</value>
<value>classpath:redis.properties</value>
</list>
</property>
</bean>
<!-- 随着后续学习,框架会越学越多,不能将所有的框架配置,放到同一个配制间,否者不便于管理 -->
<import resource="applicationContext-mybatis.xml"></import>
<import resource="spring-redis.xml"></import>
<import resource="applicationContext-shiro.xml"></import>
</beans>
2. Redis annotation development
First, a buffering strategy class is needed to store information.
package com.ycxw.ssm.redis;
import lombok.extern.slf4j.Slf4j;
import org.springframework.cache.interceptor.KeyGenerator;
import org.springframework.util.ClassUtils;
import java.lang.reflect.Array;
import java.lang.reflect.Method;
@Slf4j
public class CacheKeyGenerator implements KeyGenerator {
// custom cache key
public static final int NO_PARAM_KEY = 0;
public static final int NULL_PARAM_KEY = 53;
@Override
public Object generate(Object target, Method method, Object... params) {
StringBuilder key = new StringBuilder();
key.append(target.getClass().getSimpleName()).append(".").append(method.getName()).append(":");
if (params.length == 0) {
key.append(NO_PARAM_KEY);
} else {
int count = 0;
for (Object param : params) {
if (0 != count) {//参数之间用,进行分隔
key.append(',');
}
if (param == null) {
key.append(NULL_PARAM_KEY);
} else if (ClassUtils.isPrimitiveArray(param.getClass())) {
int length = Array.getLength(param);
for (int i = 0; i < length; i++) {
key.append(Array.get(param, i));
key.append(',');
}
} else if (ClassUtils.isPrimitiveOrWrapper(param.getClass()) || param instanceof String) {
key.append(param);
} else {//Java一定要重写hashCode和eqauls
key.append(param.hashCode());
}
count++;
}
}
String finalKey = key.toString();
// IEDA要安装lombok插件
log.debug("using cache key={}", finalKey);
return finalKey;
}
}
2.1 Cacheable annotation
1. Define the query interface using Cacheable annotations
Spring will cache the return value after it is called to ensure that the next time the method is executed with the same parameters, the results can be obtained directly from the cache without the need to execute the method again. When Spring caches the return value of a method, it caches it as a key-value pair, and the value is the return result of the method.
package com.ycxw.ssm.biz;
import com.zking.ssm.model.Clazz;
import com.zking.ssm.util.PageBean;
import org.springframework.cache.annotation.Cacheable;
import java.util.List;
import java.util.Map;
public interface ClazzBiz {
@Cacheable("clz")
Clazz selectByPrimaryKey(Integer cid);
}2. Write test classes
package com.ycxw.shiro;
import com.zking.ssm.biz.ClazzBiz;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.test.context.ContextConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
@RunWith(SpringJUnit4ClassRunner.class)
@ContextConfiguration(locations={"classpath:applicationContext.xml"})
public class ClazzBizTest {
@Autowired
private ClazzBiz clazzBiz;
@Test
public void test1(){
System.out.println(clazzBiz.selectByPrimaryKey(10));
System.out.println(clazzBiz.selectByPrimaryKey(10));
}
}
When running for the first time: (query twice)
Second time running: (no query statement)

When running the same data again, there is no query anymore and the data is taken directly from the buffer:

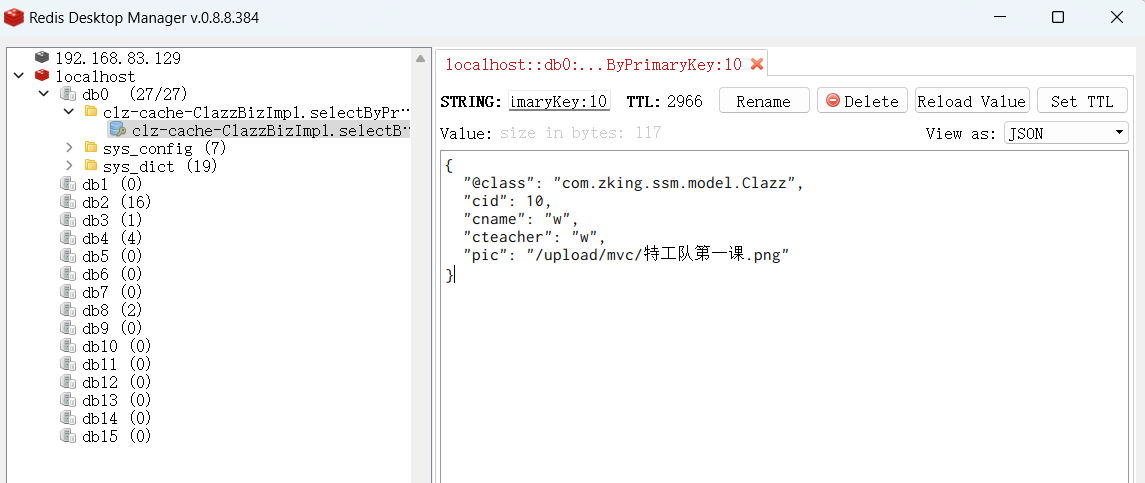
2.2 Custom strategies
@Cacheable can specify three attributes, value, key and condition.
I can define the key value to modify the key value we save to the redis buffer, and use conditions to specify when buffering is needed to further optimize performance.
Custom strategy, buffering only if the cid of the query is greater than 6
package com.ycxw.ssm.biz;
import com.zking.ssm.model.Clazz;
import com.zking.ssm.util.PageBean;
import org.springframework.cache.annotation.Cacheable;
import java.util.List;
import java.util.Map;
public interface ClazzBiz {
@Cacheable(value = "clz",key = "'cid:'+#cid",condition = "#cid > 6")
Clazz selectByPrimaryKey(Integer cid);
}2.3 CachePut annotations
Its use is consistent with that of Cacheable, and their differences are:
- Cacheable: will store data in redis and also read data at the same time
- CachePut: will only store data in redis and will not perform reading operations.
package com.ycxw.ssm.biz;
import com.zking.ssm.model.Clazz;
import com.zking.ssm.util.PageBean;
import org.springframework.cache.annotation.Cacheable;
import java.util.List;
import java.util.Map;
public interface ClazzBiz {
@CachePut(value = "clz",key = "'cid:'+#cid",condition = "#cid > 6")
Clazz selectByPrimaryKey(Integer cid);
}test:
public class ClazzBizTest {
@Autowired
private ClazzBiz clazzBiz;
@Test
public void test1(){
System.out.println(clazzBiz.selectByPrimaryKey(9));
System.out.println(clazzBiz.selectByPrimaryKey(9));
}
}
No matter how many times it is run, it will still query the database, even if the data has been stored in redis

3. Solve the buffering, breakdown, penetration and avalanche problems in Redis
3.1 Buffering problem - Quartz framework
Now simulate a scenario: I have added a piece of data to a system, and the data will be displayed in the main interface. The data is taken from the buffer, but the new data is not immediately added to the buffer. So how do we ensure the consistency between redis data and database data?
Option 1:Manually refresh the data synchronization policy
In this way, every time we add new data, we need to manually click the refresh buffer key, which is obviously inconvenient for managers.
Option 2:Use the Quartz job scheduling framework to refresh tasks regularly
Quartz is an open source job scheduling framework used to implement task scheduling and scheduled task management in Java applications. It provides a simple and powerful way to schedule and execute various types of jobs, including scheduled tasks, periodic tasks and asynchronous tasks.
The core concepts of the Quartz framework are jobs (Jobs) and triggers (Triggers). A job is a task to be executed, and a trigger defines when and how often the job is executed. Flexible task scheduling and execution can be achieved by configuring jobs and triggers.
In Redis, it does not directly use the Quartz framework. However, we can use a combination of Quartz and Redis to achieve some specific Function, for example:
- Use Quartz to schedule tasks and store the execution results of the tasks in Redis so that other systems or modules can read and process them.
- Use Quartz to regularly clean expired data in Redis to ensure that Redis storage space is effectively used.
- Use Quartz to periodically refresh cached data in Redis to keep the data up-to-date.
- Use Quartz and Redis to implement a distributed lock mechanism to ensure that task scheduling on multiple nodes does not conflict.
3.2 Three common problem solutions
1. Cache Miss Penetration refers to when a cache key (key) does not exist in the cache but is requested in large numbers under high concurrency conditions. When queried at the same time, these requests will directly access the database, causing excessive pressure on the database. In this case, the cache cannot function, and the database may crash as a result.
solution:
- Use a mutex lock or a distributed lock to protect database access to ensure that only one request can access the database while other requests wait for results.
- Set a short-lived Null Value in the cache to prevent a large number of requests from querying the same cache key at the same time.
2. Cache Penetration Penetration means that when a cache key does not exist in the cache and is queried by a large number of requests at the same time, these requests will access it directly database, causing excessive pressure on the database. Unlike penetration, penetration occurs because the queried key simply does not exist in the cache.
solution:
- Before querying the database, you can add a Bloom Filter to quickly determine whether the queried key exists in the cache. If it does not exist, you can directly return an empty result instead of accessing the database.
- For the case where the query result is empty, the empty result can also be cached for a period of time to avoid frequent database queries.
3. Cache Avalanche Avalanche refers to a large number of cache keys in the cache that expire or become invalid at the same time, resulting in a large number of requests directly accessing the database, causing excessive pressure on the database. Even crash.
solution:
- When setting the expiration time of cache keys, you can introduce random values to spread the expiration times of cache keys and avoid a large number of cache keys from expiring at the same time.
- Use the hot data preloading (Cache Pre-warming) strategy to load hot data into the cache in advance to reduce the possibility of cache keys becoming invalid at the same time.
- Use a multi-level cache architecture to divide the cache into multiple levels to reduce the risk of overall cache failure.
Summary: When solving these problems, we need to comprehensively consider the concurrency, availability and performance of the system. Through reasonable caching strategies, lock mechanisms, preloading, and the use of scheduling frameworks, breakdown, penetration, and avalanche problems in Redis can be effectively solved and the stability and performance of the system can be improved.