cache penetration
understand:
Cache penetration refers to querying a data that does not exist at all, and neither the cache layer nor the persistence layer will hit. In daily work, for the sake of fault tolerance, if the data cannot be found from the persistence layer, it will not be written to the cache layer. Cache penetration will cause non-existent data to be queried at the persistence layer every time. After losing the cache protection Enduring meaning.
For example: A product is participating in a promotional activity, but the back-end operation and maintenance personnel delete the product information, and the product information is no longer in the database. At this time, there are still a large number of get requests to access the current product information. This is called the cache penetration problem.
solution:
(1) Cache empty objects: refers to set (key,null) on the key when the persistence layer does not hit
There are two problems with caching empty objects:
First, a value of null does not mean that it does not occupy memory space. Null values are cached, which means that more keys are stored in the cache layer and more memory space is required. A more effective method is to set a relatively small value for this type of data. Short expiration time, let it be automatically removed.
Second, the data in the cache layer and the storage layer will be inconsistent for a period of time, which may have a certain impact on the business. For example, the expiration time is set to 5 minutes. If the data is added to the storage layer at this time, there will be inconsistencies between the cache layer and the storage layer data during this period. At this time, the message system or other methods can be used to clear the empty space in the cache layer. object.
(2) Bloom filter interception
Before accessing the cache layer and storage layer, save the existing key in advance with the Bloom filter, and do the first layer of interception. When receiving a request for the key, first use the Bloom filter to verify whether the key exists. If it exists Into the cache layer, storage layer. A bitmap can be used as a Bloom filter. This method is suitable for application scenarios where the data hit rate is not high, the data is relatively fixed, and the real-time performance is low. The code maintenance is more complicated, but the cache space occupies less.
A Bloom filter is actually a long binary vector and a series of random mapping functions. Bloom filters can be used to retrieve whether an element is in a set.
Its advantage is that the space efficiency and query time are far more than the general algorithm, and the disadvantage is that there is a certain rate of misidentification and difficulty in deletion.
Bloom filter notes:
A Bloom Filter is essentially a bit vector or bit list (a list containing only 0 or 1 bit values) of length m, initially all values are set to 0, as shown in the figure below.

To add a data item to a Bloom filter, we provide K different hash functions and set the value of the corresponding bit in the resulting position to "1". In the hash table mentioned earlier, we are using a single hash function, so only a single index value can be output. And for Bloom filter, we will use multiple hash functions, which will produce multiple index values.
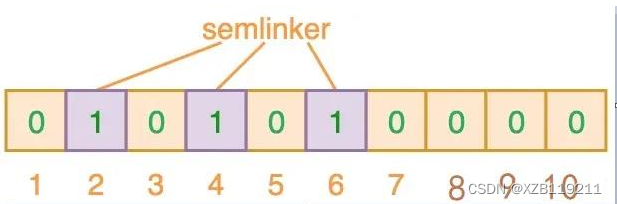
As shown in the figure above, when "semlinker" is input, the preset 3 hash functions will output 2, 4, 6, and we set the corresponding bit to 1. Assuming another input "kakuqo", the hash function outputs 3, 4 and 7. You may have noticed that index bit 4 has been marked by the previous "semlinker". At this point, we have filled the bit vector with the two input values "semlinker" and "kakuqo". The flag state of the current bit vector is:
When searching for a value, similar to a hash table, we will hash the "searched value" using 3 hash functions and see the resulting index value. Suppose, when we search for "fullstack", the 3 index values output by the 3 hash functions are 2, 3 and 7 respectively:
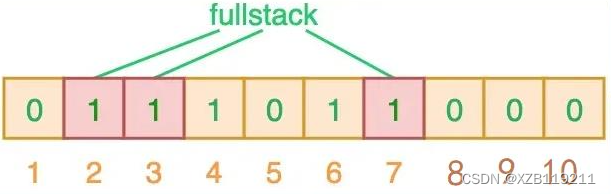
As can be seen from the above figure, the corresponding index bits are all set to 1, which means we can say that "fullstack" may have been inserted into the collection. In fact this is a case of false positives, caused by coincidences caused by hash collisions where different elements are stored on the same bit.
So how do we choose the number of hash functions and the length of the Bloom filter
? Obviously, if the Bloom filter is too small, all the bits will be 1 soon, then any value of query will return "may exist", and it will not be able to filter purpose. The length of the Bloom filter will directly affect the false positive rate, and the longer the Bloom filter, the smaller the false positive rate.
In addition, the number of hash functions also needs to be weighed. The more the number, the faster the bit position of the Bloom filter is set to 1, and the lower the efficiency of the Bloom filter; but if it is too small, then our error Rates will increase.
(3) Scheme comparison

cache breakdown
understand:
In the e-commerce platform, there is a problem that a large number of products need to be imported in batches, and the redis cache expiration time of these products is 24 hours, then after 24 hours, the data of this large number of products expire at the same time, and the products at this time The demand for access is still very high, which will double the pressure of querying the database in the direct area. This is the problem of redis cache breakdown.
solution:
(1) Commodity settings never expire
(2) Set a random value for the commodity expiration time
cache avalanche
understand:
If the cache fails within a period of time, a large number of cache penetrations will occur, and all queries will fall on the database, causing a cache avalanche.
solution:
(1) The cache layer is highly available:
The cache layer can be designed to be highly available, even if individual nodes, individual machines, or even computer rooms are down, services can still be provided. Use sentinel or cluster to achieve.
(2) Do secondary cache, or double cache strategy:
Multi-level cache is adopted, local process is used as the first-level cache, and redis is used as the second-level cache. Different levels of caches have different timeouts. Even if a certain level of cache expires, there are other levels of cache.
(3) Data preheating:
You can use the cache reload mechanism to update the cache in advance, and then manually trigger the loading of different keys in the cache before a large concurrent access occurs, and set different expiration times to make the cache failure time as uniform as possible.