Redis is a completely open source, high-performance key-value data storage structure system that complies with the BSD protocol. It supports data persistence and can store data in memory on disk. Not only supports simple key-value data structures, but also provides list, zset, hash and other data structure storage. Redis also supports data backup in master-slave mode. The most important thing is that Redis reads and writes quickly. In practical applications, Redis will have abnormal situations such as cache avalanche, cache penetration, and cache breakdown.
overview
1. Cache avalanche: a large number of keys in redis collectively expire
2. Cache penetration: a large number of requests for keys that do not exist at all
3. Cache breakdown: A hotspot key in redis expires (a large number of users access the hotspot key, but the hotspot key expires)
1. Cache avalanche solution
- Set up the hot words in advance and adjust the key duration
- Real-time adjustment, monitoring which data is popular data, and real-time adjustment of key expiration time
- use lock mechanism
2. Cache penetration solution
- Cache empty values
- set whitelist
- use bloom filter
- internet police
3. Cache breakdown solution
- Set up the hot words in advance and adjust the key duration
- Real-time adjustment, monitoring which data is popular data, and real-time adjustment of key expiration time
- Use lock mechanism (only one thread can reconstruct hot data)
Redis cache middleware works:
When the client Client initiates a query request Request, it first goes to the Redis cache to query, if the data exists in the Redis cache, then directly returns the data in the cache to the client; if the data does not exist in the cache, then continue to query the database DB, if the data exists in the database DB, put the data into the Redis cache and return it to the client Client, if the data does not exist in the database DB, directly return null to the client Client
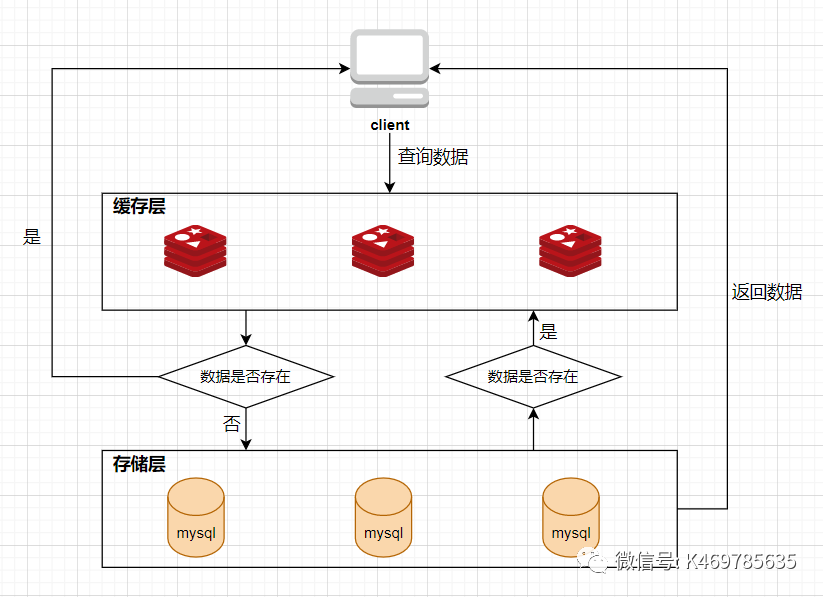
The root cause of cache avalanche, cache penetration, and cache breakdown: the Redis hit rate drops, and the request is directly hit on the DB
Under normal circumstances, a large number of resource requests will be responded to by redis, and only a small part of requests that cannot be responded to by redis will request DB, so that the pressure on DB is very small, and it can work normally (as shown in the figure below)

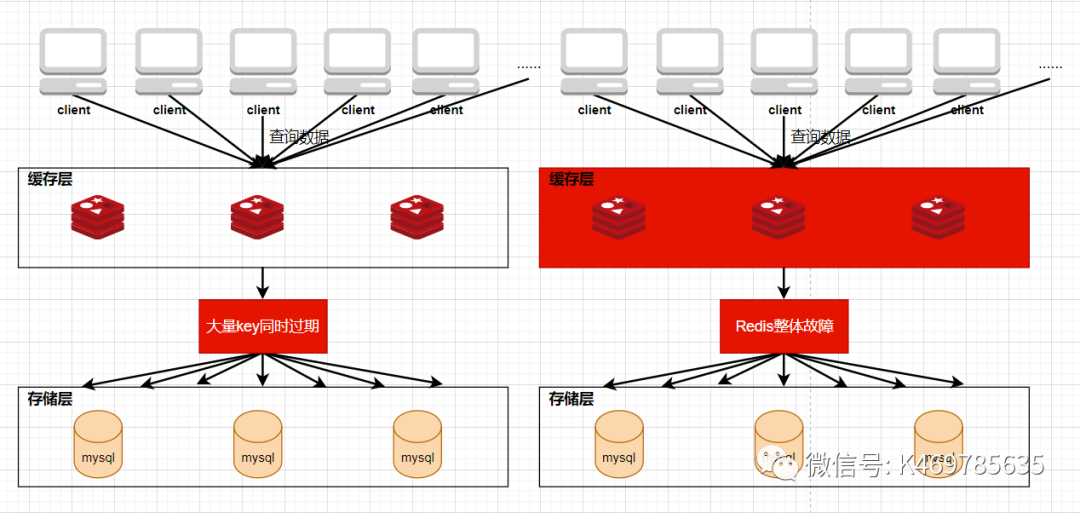
If a large number of requests are not responded to on redis, these requests will directly access the DB, causing the pressure on the DB to increase instantly and cause it to freeze or crash
1. A large number of highly concurrent requests are sent to redis
2. These requests find that there are no resources that need to be requested on redis, and the hit rate of redis decreases
3. Therefore, these large numbers of high concurrent requests turn to DB (database server) to request corresponding resources
4. The pressure on the DB increases instantly, directly destroying the DB, and then triggering a series of "disasters"
| Phenomenon | cache avalanche | cache penetration | cache breakdown |
| Whether the resource exists in the DB database server | ✅ | ❎ | ✅ |
| Whether the resource exists in Redis | ❎ | ❎ | ❎ |
| The reason why redis has no corresponding resources | Most keys collectively expire | The resource doesn't exist at all (and neither does the DB) | A hotspot key has expired |
| root cause | A large number of high-concurrency requests are sent to Redis, but it is found that there is no requested data in Redis, and the order rate of redis is reduced, so these requests can only be sent directly to the DB (database server). It will cause the DB to be directly stuck and down | ||
1. Cache Avalanche
Cache avalanche refers to when a large number of keys in the cache expire at the same time, or Redis directly crashes, causing a large number of query requests to reach the database, resulting in a sudden increase in the query pressure of the database, or even directly hanging up, causing the entire system to crash. Causing chain effects like an avalanche
problem causes
1. A large amount of cached data expires at the same time, resulting in the need to obtain data from the database again when the cache should be requested
2. If Redis itself fails and cannot process the request, it will naturally request to the database again
solution
1. Simultaneous expiration for a large number of keys
[1] Disperse the expiration time; by using automatic random number generation, fine-tuning, uniform setting, etc., the expiration time of the key is randomized to prevent collective expiration
[2] Use multi-level architecture; use nginx cache + redis cache + other caches, different layers use different caches, and the reliability is stronger
[3] Set the cache flag; record whether the cache data is expired, if it expires, it will trigger a notification to another thread to update the actual key in the background (use a scheduled task or message queue to update or remove the redis cache, etc.)
[4] Add a mutex; so that the operation of building the cache will not be performed at the same time
2. A failure occurred against redis
[1] At the prevention level, build a high-availability cluster through the master-slave node mode, so that after the master Redis hangs up, other slave databases can quickly switch to the master database and continue to provide services
[2] In order to prevent the database from being crashed by a large number of requests, service fusing or request flow limiting can be used. The service fuse is relatively rough, stop the service until the Redis service is restored, and the request flow limit is relatively gentle to ensure that some requests can be processed.
2. Cache penetration
Cache penetration means that the data is neither in the Redis cache nor in the DB database. As a result, every time a request comes, after the corresponding key cannot be found in the Redis cache, the DB database must be queried again every time. It is found that it does not exist in the DB database, which is equivalent to performing 2 invalid queries.
In this way, the request can bypass the Redis cache and directly query the DB database. If there is a malicious hacker attacking the system, you can use empty values or other non-existing values to make frequent requests, which will put a lot of pressure on the database, or even hang up.

solution
1. Cache empty or default values
If the data cannot be fetched from the Redis cache, nor can it be fetched from the DB database, the result is still cached and a short expiration time is set at the same time
2. Illegal request restriction
Parameter verification, authentication verification, intercepting a large number of illegal requests at the beginning, and not allowing these requests to reach Redis and DB
3. Bloom filter
A Bloom filter is a data structure consisting of a bit array with a length of m bits and n hash functions. The initial value of each element in the bit array is 0. When initializing the Bloom filter, all keys will be hashed n times first, so that n positions can be obtained, and then the elements at these n positions will be changed to 1. In this way, it is equivalent to saving all the keys in the Bloom filter.
For example, if we have a total of 3 keys, we perform three hash operations on these three keys, and the results of key1 after three hash operations are 2/6/10, then put the Bloom filter in the The value of the element marked 2/6/10 is updated to 1, and then the same operation is performed on key2 and key3 respectively, and the result is as follows:

In this way, when the client queries, it also performs 3 hash operations on the queried key to obtain 3 positions, and then checks whether the value of the corresponding position element in the Bloom filter is 1, if all the values of the corresponding position elements are 1, It proves that the key exists in the library, and then continue to query downward; if the value of any one of the three positions is not 1, then it proves that the key does not exist in the library, and it is sufficient to directly return the client to empty. As shown below:
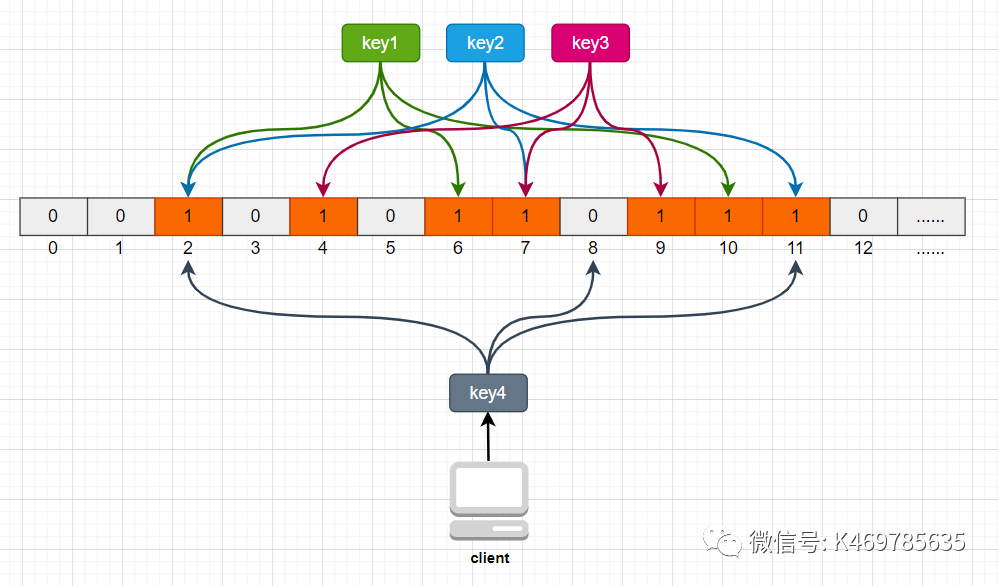
When the client queries key4, in the three hash operations of key4, there is a value of 0 in position 8, which means that key4 does not exist in the library, and the client can directly return empty.
Therefore, the Bloom filter is equivalent to an interceptor between the client and the cache layer, responsible for judging whether the key exists in the collection. As shown below:
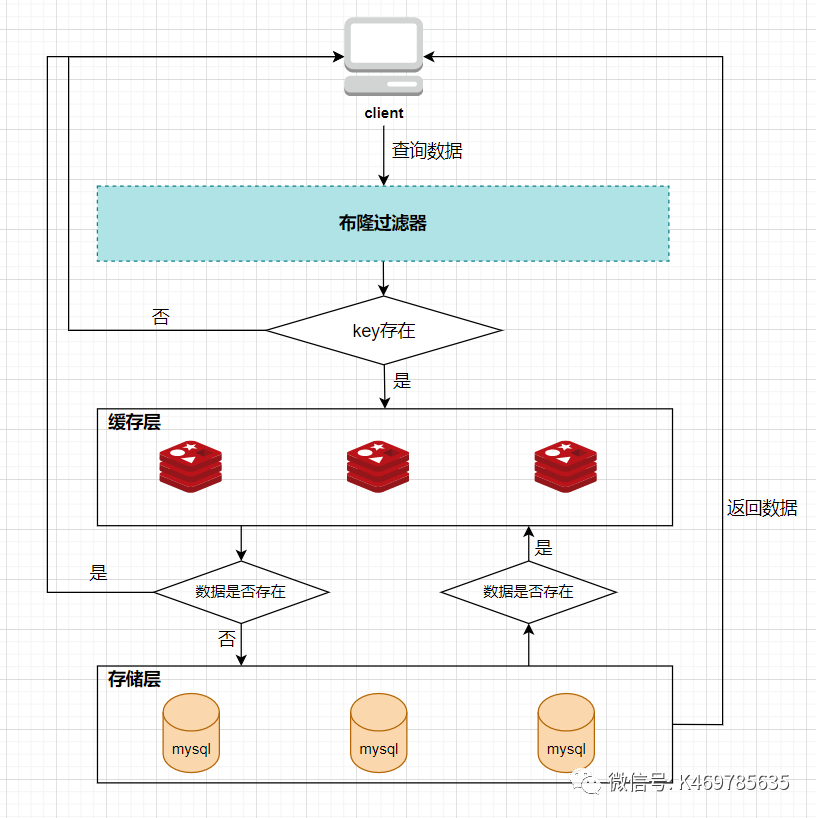
The advantage of the Bloom filter is to solve the deficiency of the first type of cache null value, but the Bloom filter also has defects. First, it may misjudgment. For example, in the above diagram where the client queries key4, if key4 passes The positions obtained by the three hash operations are 2/4/6 respectively. Since the values of these three positions are all 1, the Bloom filter thinks that key4 exists in the library, and then continues to query downwards. Therefore, the key that the Bloom filter judges to exist may not actually exist, but the key that the Bloom filter judges does not exist must not exist. Its second disadvantage is that it is difficult to delete elements. For example, if you want to delete the element key2 now, you need to change the element values at the three positions of 2/7/11 to 0, but this will affect the judgment of key1 and key3
3. Cache breakdown
Cache breakdown means that when a hot data in the cache expires, a large number of query requests pass through the cache and directly query the database before the hot data is reloaded into the cache. This situation will cause the pressure on the database to increase suddenly, causing a large number of requests to be blocked, or even hang up directly
Cache breakdown generally occurs in high-concurrency systems, where a large number of users simultaneously request data that is not in the Redis cache but is in the DB database. That is, at the same time, the read cache does not read the data, and at the same time fetches the data from the DB database, causing the pressure on the database to increase instantly
Difference between cache avalanche and cache breakdown
Cache breakdown refers to the same piece of data. Cache avalanche means that different data have expired, and many data are queried in the database.
solution
1. When setting a hotspot key, do not set an expiration time for the key
When setting a hotspot key, just do not set an expiration time for the key. However, there is another way to achieve the purpose of not expiring the key, which is to set the expiration time for the key normally, but start a scheduled task in the background to update the cache regularly

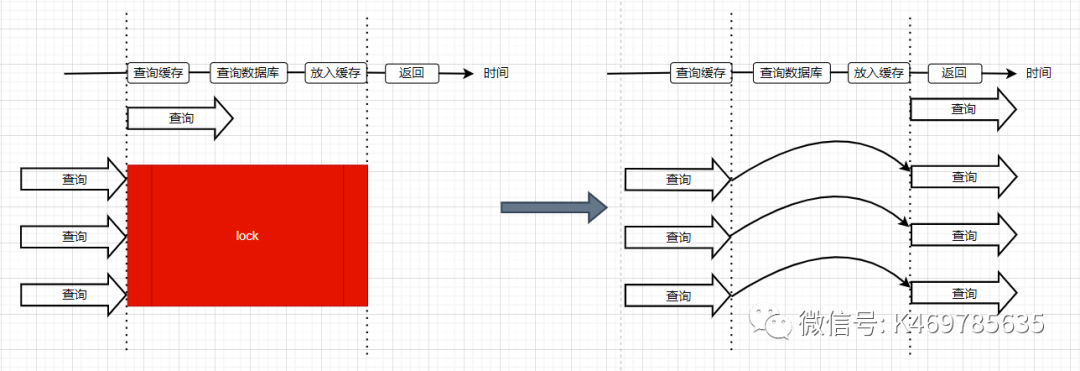
2. Use distributed locks to ensure that only one query request reloads hotspot data into the cache at the same time
The locking method is used, and the object of the lock is the key. In this way, when a large number of requests for the same key are sent in concurrently, only one request can acquire the lock, and then the thread that acquires the lock queries the database, and then puts the result into to the cache, and then release the lock. At this time, other requests that are waiting for the lock can continue to execute. Since there is already data in the cache at this time, the data is directly obtained from the cache and returned without querying the database.

Summarize
