Overview
String matching (search) is a basic operation on strings: given a text string S with a matching query and a target substring T, T is also called a pattern string. Find a substring in text S that matches pattern T and return the position of the substring in the text.
Brute force matching
Brute Force Algorithm, also called Naive String Matching Algorithm.
The basic idea is to compare characters one by one:
- If the first characters of the two strings S and T are the same, compare the second characters, and if they are the same, continue;
- If one of the characters is different, the T string is shifted back one bit, and the second character of the S string is compared with the first character of the T string again.
- Repeatedly until the end
accomplish
public static int bf(String text, String pattern) {
int m = text.length();
int n = pattern.length();
for (int i = 0; i <= m - n; i++) {
boolean flag = true;
for (int j = 0; j < n; j++) {
if (text.charAt(i + j) != pattern.charAt(j)) {
flag = false;
break;
}
}
if (flag) {
return i;
}
}
return -1;
}
KMP
DEKnuth, JHMorris and VRPRatt invented an improved string matching algorithm that uses the information after the matching fails to minimize the number of matches between the pattern string and the main string to achieve fast matching. The KMP algorithm only needs to search the text string once, and its time complexity is O(n).
The key to the KMP algorithm is to find the next array. The length of the next array is the length of the pattern string. Each value in the next array represents the length of the same prefix and suffix in the string preceding the current character in the pattern string.
principle
Violent matching:
Given strings A and B, determine whether B is a substring of A. Violent matching method: starting from the first character of A, compare the first character of A and the first character of B to see if they are the same. If they are the same, compare the second character of A with the second character of B. If they are not the same, , then start from the second character of A and compare with the first character of B. And so on. This is equivalent to moving B to the right step by step.
Brute force matching has low efficiency, which is reflected in the step-by-step movement, especially when the first n-1character of B can be matched successfully, but the last character fails to match, or the substring of B is long. KMP utilizes the concept of matching tables to optimize matching efficiency.
Matching table
for a given string B, such as abcab:
- Prefix: All sequential combinations except the last character: a, ab, abc, abca
- Suffix: Except for the first character, all sequential combinations: bcab, cab, ab, b
Matching value: Find the prefix and suffix for each character combination of the substring, and compare whether there are the same ones. How many of the same character combinations are there? The matching value is how many.
For example, for a given string abcab, the matching value string is 00012:
- a, no suffix or suffix, matching value = 0
- ab, prefix {a}, suffix {b}, no common characters, matching value = 0
- abc, prefix {a}{ab}, suffix {c}{bc}, no common characters, matching value = 0
- abca, prefix {a}{ab}{abc}, suffix {a}{ca}{bca}, common character {a}, matching value=1
- abcab, prefix {a}{ab}{abc}{abca}, suffix {b}{ab}{cab}{bcab}, common character {ab}, matching value = 2
Based on the matching table, there is no need to move one by one 移动步数 = 成功匹配的位数 - 匹配表里面的匹配值.
accomplish
Give a KMP algorithm implementation:
/**
* 利用KMP算法求解pattern是否在text中出现过
*
* @param text 文本串
* @param pattern 模式串
* @return pattern在text中出现,则返回true,否则返回false
*/
public static boolean kmpSearch(String text, String pattern) {
// 部分匹配数组
int[] partMatchTable = kmpNext(pattern);
// text中的指针
int i = 0;
// pattern中的指针
int j = 0;
while (i < text.length()) {
if (text.charAt(i) == pattern.charAt(j)) {
// 字符匹配,则两个指针同时后移
i++;
j++;
} else if (j > 0) {
// 字符失配,则利用next数组,移动j指针,避免i指针回退
j = partMatchTable[j - 1];
} else {
// pattern中的第一个字符就失配
i++;
}
if (j == pattern.length()) {
// 搜索成功
return true;
}
}
return false;
}
private static int[] kmpNext(String pattern) {
int[] next = new int[pattern.length()];
next[0] = 0;
int j=0;
for (int i = 1; i < pattern.length(); i++) {
while (j > 0 && pattern.charAt(i) != pattern.charAt(j)){
//前后缀相同
j = next[j - 1];
}
if (pattern.charAt(i) == pattern.charAt(j)){
//前后缀不相同
j++;
}
next[i] = j;
}
return next;
}
Boyer-Moore
The Boyer-Moore algorithm is more efficient than the KMP algorithm in practical applications. It is said that the search functions of various text editors, including the grep command in Linux, all use the Boyer-Moore algorithm. This algorithm has two concepts 坏字符: and 好后缀, and strings are matched from back to front. In general, it is 3-5 times faster than the KMP algorithm.
principle
Assume that the length of the text string S is n and the length of the pattern string T is m. The main characteristics of the BM algorithm are:
- Compare and match from right to left (general string search algorithms such as KMP match from left to right);
- The algorithm is divided into two stages: preprocessing stage and search stage;
- The time and space complexity of the preprocessing stage are both
O(m+), which is the character set size, generally 256; - The time complexity of the search phase is
O(mn); - When the pattern string is aperiodic, in the worst case the algorithm needs to perform 3n character comparison operations;
- The algorithm is achieved in the best case
O(n/m), i.e. onlyn/mone comparison is required.
The BM algorithm moves the pattern string from left to right, and compares it from right to left.
The essence of the BM algorithm is that BM(text, pattern)the BM algorithm can skip more than one character at a time when there is no match. That is, it does not need to compare the characters in the searched string one by one, but will skip some parts. Generally, the longer the search keyword, the faster the algorithm is. Its efficiency comes from the fact that for every failed matching attempt, the algorithm is able to use this information to eliminate as many unmatched positions as possible. That is, it makes full use of some characteristics of the string to be searched to speed up the search steps.
The BM algorithm contains two parallel algorithms (that is, two heuristic strategies): bad-character shift and good-suffix shift. The purpose of these two algorithms is to move the pattern string as far as possible to the right each time (that is, as BM()large as possible).
accomplish
/**
* Boyer-Moore算法是一种基于后缀匹配的模式串匹配算法,后缀匹配就是模式串从右到左开始比较,但模式串的移动还是从左到右的。
* 字符串匹配的关键就是模式串的如何移动才是最高效的,Boyer-Moore为了做到这点定义了两个规则:坏字符规则和好后缀规则<br>
* 坏字符规则<bR>
* 1.如果坏字符没有出现在模式字符中,则直接将模式串移动到坏字符的下一个字符:<br>
* 2.如果坏字符出现在模式串中,则将模式串最靠近好后缀的坏字符(当然这个实现就有点繁琐)与母串的坏字符对齐:<br>
* 好后缀规则<bR>
* 1.模式串中有子串匹配上好后缀,此时移动模式串,让该子串和好后缀对齐即可,如果超过一个子串匹配上好后缀,则选择最靠靠近好后缀的子串对齐。<br>
* 2.模式串中没有子串匹配上后后缀,此时需要寻找模式串的一个最长前缀,并让该前缀等于好后缀的后缀,寻找到该前缀后,让该前缀和好后缀对齐即可。<br>
* 3.模式串中没有子串匹配上后后缀,并且在模式串中找不到最长前缀,让该前缀等于好后缀的后缀。此时,直接移动模式到好后缀的下一个字符。<br>
*/
public static List<Integer> bmMatch(String text, String pattern) {
List<Integer> matches = new ArrayList<>();
int m = text.length();
int n = pattern.length();
// 生成模式字符串的坏字符移动结果
Map<Character, Integer> rightMostIndexes = preprocessForBadCharacterShift(pattern);
// 匹配的节点位置
int alignedAt = 0;
// 如果当前节点在可匹配范围内,即当前的A[k]必须在A[0, m-n-1)之间,否则没有必要做匹配
while (alignedAt + (n - 1) < m) {
// 循环模式组,查询模式组是否匹配 从模式串的最后面开始匹配,并逐渐往前匹配
for (int indexInPattern = n - 1; indexInPattern >= 0; indexInPattern--) {
// 1 定义待查询字符串中的当前匹配位置.
int indexInText = alignedAt + indexInPattern;
// 2 验证带查询字符串的当前位置是否已经超过最长字符,如果超过,则表示未查询到.
if (indexInText >= m) {
break;
}
// 3 获取到带查询字符串和模式字符串中对应的待匹配字符
char x = text.charAt(indexInText);
char y = pattern.charAt(indexInPattern);
// 4 验证结果
if (x != y) {
// 4.1 如果两个字符串不相等,则寻找最坏字符串的结果,生成下次移动的队列位置
Integer r = rightMostIndexes.get(x);
if (r == null) {
alignedAt = indexInText + 1;
} else {
// 当前坏字符串在模式串中存在,则将模式串最靠近好后缀的坏字符与母串的坏字符对齐,shift 实际为模式串总长度
int shift = indexInText - (alignedAt + r);
alignedAt += shift > 0 ? shift : 1;
}
// 退出匹配
break;
} else if (indexInPattern == 0) {
// 4.2 匹配到的话 并且最终匹配到模式串第一个字符,便是已经找到匹配串,记录下当前的位置
matches.add(alignedAt);
alignedAt++;
}
}
}
return matches;
}
/**
* 坏字符串
* 依据待匹配的模式字符串生成一个坏字符串的移动列,该移动列中表明当一个坏字符串出现时,需要移动的位数
*/
private static Map<Character, Integer> preprocessForBadCharacterShift(String pattern) {
Map<Character, Integer> map = new HashMap<>();
for (int i = pattern.length() - 1; i >= 0; i--) {
char c = pattern.charAt(i);
if (!map.containsKey(c)) {
map.put(c, i);
}
}
return map;
}
Reference: Baidu Encyclopedia
Sunday
A string pattern matching algorithm proposed by Daniel M.Sunday in 1990. Its efficiency is faster than other matching algorithms when matching random strings. The average time complexity is O(n)and the worst case time complexity is O(n*m).
principle
The Sunday algorithm is the same as the KMP algorithm, matching from front to back. When the match fails, focus on the character next to the last character in the text string that participates in the match. If the character is not in the pattern string, the entire pattern string is moved after the character. If the character is in the pattern string, shift the pattern string to the right to align the corresponding characters.
The Sunday algorithm is slightly different from the BM algorithm in that the Sunday algorithm matches from front to back. When the match fails, it focuses on the next character of the last character in the main string that participates in the match.
- If the character does not appear in the pattern string, it is skipped directly, that is, the number of moving digits = pattern string length + 1;
- Otherwise, the number of shifting digits = length of the pattern string - the rightmost position of the character (starting with 0) = distance from the rightmost position of the character in the pattern string to the tail + 1.
Give an example of the Sunday algorithm. Suppose now we want substring searchingto find the pattern string in the main string search:
- Initially, align the pattern string to the left of the text string:
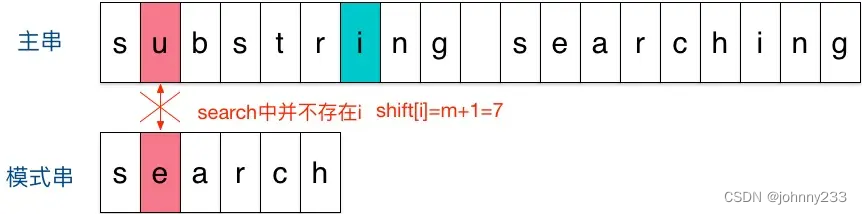
- It turns out that a mismatch is found at the second character. When there is a mismatch, focus on the character next to the last character in the main string that participates in the match, that is, the bold character. It does not exist in the pattern string search, and the pattern string jumps
idirectlyi. After a large area, move the number of digits to the right = matching string length + 1 = 6 + 1 = 7, and start the next matching step from the character after i (i.e. character n):
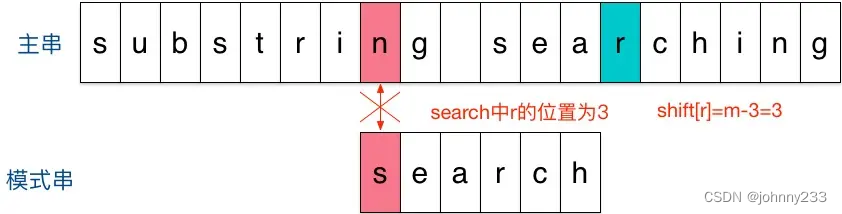
- As a result, the first character does not match. Then look at the character next to the last matching character in the main string
r. It appears in the third to last character in the pattern string, so the pattern string is moved to the right by 3 bits (m - 3 = 6 - 3 = distance from r to the end of the pattern string + 1 = 2 + 1 =3), aligning the twor:
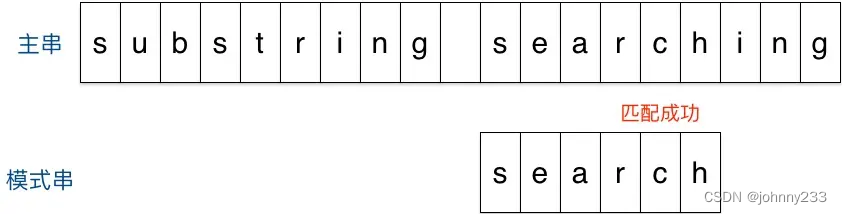
- Match successful.
Disadvantages of the Sunday algorithm: The core of the algorithm relies on the move array, and the value of the move array depends on the pattern string, so there may be pattern strings that construct poor move arrays.
accomplish
/**
* sunday 算法
*
* @param text 文本串
* @param pattern 模式串
* @return 匹配失败返回-1,匹配成功返回文本串的索引(从0开始)
*/
public static int sunday(char[] text, char[] pattern) {
int tSize = text.length;
int pSize = pattern.length;
int[] move = new int[ASCII_SIZE];
// 主串参与匹配最末位字符移动到该位需要移动的位数
for (int i = 0; i < ASCII_SIZE; i++) {
move[i] = pSize + 1;
}
for (int i = 0; i < pSize; i++) {
move[pattern[i]] = pSize - i;
}
// 模式串头部在字符串位置
int s = 0;
// 模式串已经匹配的长度
int j;
// 到达末尾之前
while (s <= tSize - pSize) {
j = 0;
while (text[s + j] == pattern[j]) {
j++;
if (j >= pSize) {
return s;
}
}
s += move[text[s + pSize]];
}
return -1;
}
Compared
This is just an example, different algorithms perform inconsistently in different situations. Relates to the string literal to be searched and the pattern matching string.
public static void main(String[] args) {
String text = "abcagfacjkackeac";
String pattern = "ackeac";
Stopwatch stopwatch = Stopwatch.createStarted();
int bfRes = bf(text, pattern);
stopwatch.stop();
log.info("bf result:{}, take {}ns", bfRes, stopwatch.elapsed(TimeUnit.NANOSECONDS));
stopwatch.reset();
stopwatch.start();
boolean kmpRes = kmpSearch(text, pattern);
stopwatch.stop();
log.info("kmp result:{}, take {}ns", kmpRes, stopwatch.elapsed(TimeUnit.NANOSECONDS));
stopwatch.reset();
stopwatch.start();
List<Integer> bmMatch = bmMatch(text, pattern);
stopwatch.stop();
log.info("bmMatch result:{}, take {}ns", bmMatch, stopwatch.elapsed(TimeUnit.NANOSECONDS));
stopwatch.reset();
stopwatch.start();
int sunday = sunday(text.toCharArray(), pattern.toCharArray());
stopwatch.stop();
log.info("sunday result:{}, take {}ns", sunday, stopwatch.elapsed(TimeUnit.NANOSECONDS));
}
A certain output result:
bf result:10, take 8833ns
kmp result:true, take 4541ns
bmMatch result:[10], take 90500ns
sunday result:10, take 5458ns
Test results are for reference only.