This article is a basic tutorial on how to use word2vec. The article is relatively basic and I hope it will be helpful to you!
Official website C language download address: http://word2vec.googlecode.com/svn/trunk/Official
website Python download address: http://radimrehurek.com/gensim/models/word2vec.html
Reference: "The core architecture and application of Word2vec · Xiong Fulin, Deng Yihao, Tang Xiaosheng · Beijing University of Posts and Telecommunications 2015" "Study on the
working principle and application of Word2vec · Zhou Lian · Xi'an University of Electronic Science and Technology 2014" "
Research on clustering Chinese words using Word2vec · Zheng Wenchao, Xu Peng · Beijing University of Posts and Telecommunications 2013》
PS: The first part is mainly to introduce basic content to you. There are many such articles. I hope you can learn more and better basic content by yourself. This blog is mainly to introduce Usage of Word2Vec for Chinese text.
(1) Statistical language model
The general form of statistical language model is to solve the conditional probability of the next word given a known set of words. The form is as follows:
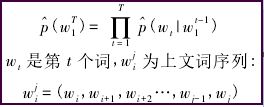
The general form of the statistical language model is intuitive and accurate. In the n-gram model, it is assumed that without changing the order of words in the context, the closer the relationship between words that are close to each other, and the farther the relationship between words that are farther away. When the distance is far enough, There is no correlation between words.
However, this model does not fully utilize the information of the corpus:
1) It does not consider the relationship between words that are further away and the current word, that is, words beyond the range n are ignored, and the two are likely to be related.
For example, "Washington is the capital of the United States" is the current sentence, and "Beijing is the capital of China" appears more than n words later. In the n-ary model, "Washington" and "Beijing" are not related. However, These two sentences imply a grammatical and semantic relationship, that is, "Washington" and "Beijing" are both nouns, and they are the capitals of the United States and China respectively.
2) The similarity between words is ignored, that is, the above model cannot consider the grammatical relationship of words.
For example, "fish swimming in the water" in the corpus should help us generate sentences such as "horses running on the grassland", because in the two sentences "fish" and "horse", "water" and "grassland", and "swim" ” has the same grammatical characteristics as “run”, “中” and “上”.
In the neural network probabilistic language model, these two kinds of information will be fully utilized.
(2) Neural network probabilistic language model
The neural network probabilistic language model is an emerging natural language processing algorithm. This model obtains word vectors and probability density functions by learning training corpus. The word vector is a multi-dimensional real number vector, and the vector contains natural language. The semantic and grammatical relationships between words, the size of the cosine distance between word vectors represents the distance of the relationship between words, and the addition and subtraction of word vectors is the computer's "choosing words to create sentences".
The neural network probabilistic language model has gone through a long development stage. The neural network language model NNLM (Neural network language model) proposed by Bengio et al. in 2003 is the most famous, and future development work will refer to this model. After more than ten years of research, the neural network probabilistic language model has made great progress.
Nowadays, in terms of architecture, there are CBOW models and Skip-gram models that are simpler than NNLM; secondly, in terms of training, Hierarchical Softmax algorithm and negative sampling algorithm (Negative Sampling) have appeared, and in order to reduce the accuracy of frequent word pairs and training speed The subsampling technology introduced due to the influence of
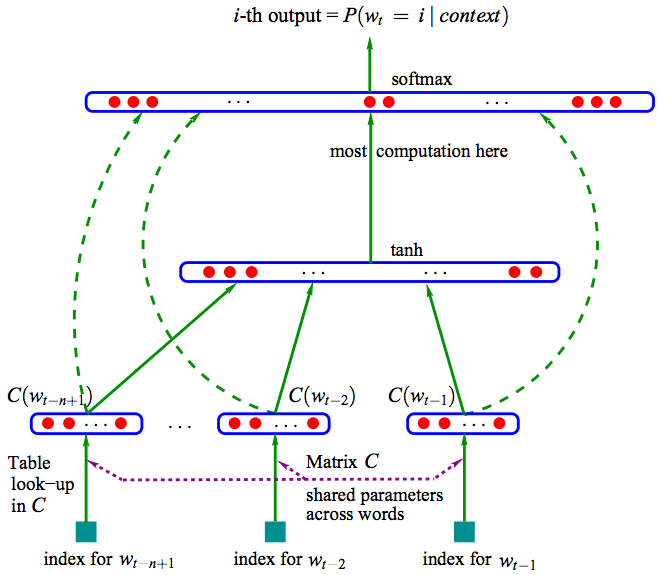
The picture above is a natural language estimation model NNLM (Neural Network Language Model) based on a three-layer neural network. NNLM can calculate the probability that the next word in a certain context is wi, that is (wi=i|context), and the word vector is a by-product of its training. NNLM generates the corresponding vocabulary V based on the corpus C.
For knowledge about the general network, you can refer to my previous blog: Introduction to Neural Networks and Machine Learning Basics Sharing
NNLM Recommended Articles by Rachel-Zhang: word2vec - efficient word feature extraction
In recent years, neural network probabilistic language models have developed rapidly, and Word2vec is the latest technology A collection of theories.
Word2vec is a software tool for training word vectors opened by Google in 2013. Therefore, before talking about word2vec, let me first introduce you to the concept of word vectors.
(3) Word vector
reference: licstar’s NLP article Deep Learning in NLP (1) Word vectors and language models
As the author said: Deep Learning algorithms have achieved amazing results in the image and audio fields, but have not yet achieved success in the NLP field. Such exciting results to see. There is a saying that language (words, sentences, chapters, etc.) is a high-level cognitive abstract entity produced in the human cognitive process, while speech and images are lower-level original input signals, so the latter two are more suitable for deep learning. Learning features.
However, representing words in the form of "word vectors" can be said to be a core technology that introduces Deep Learning algorithms into the field of NLP. The first step in converting natural language understanding problems into machine learning problems is to mathematicalize these symbols through a method.
词向量具有良好的语义特性,是表示词语特征的常用方式。词向量的每一维的值代表一个具有一定的语义和语法上解释的特征。故可以将词向量的每一维称为一个词语特征。词向量用Distributed Representation表示,一种低维实数向量。
例如,NLP中最直观、最常用的词表示方法是One-hot Representation。每个词用一个很长的向量表示,向量的维度表示词表大小,绝大多数是0,只有一个维度是1,代表当前词。
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …] 即从0开始话筒记为3。
但这种One-hot Representation采用稀疏矩阵的方式表示词,在解决某些任务时会造成维数灾难,而使用低维的词向量就很好的解决了该问题。同时从实践上看,高维的特征如果要套用Deep Learning,其复杂度几乎是难以接受的,因此低维的词向量在这里也饱受追捧。
Distributed Representation低维实数向量,如:[0.792, −0.177, −0.107, 0.109, −0.542, …]。它让相似或相关的词在距离上更加接近。
总之,Distributed Representation是一个稠密、低维的实数限量,它的每一维表示词语的一个潜在特征,该特征捕获了有用的句法和语义特征。其特点是将词语的不同句法和语义特征分布到它的每一个维度上去表示。
推荐我前面的基础文章:Python简单实现基于VSM的余弦相似度计算
(4) Word2vec
参考:Word2vec的核心架构及其应用 · 熊富林,邓怡豪,唐晓晟 · 北邮2015年
Word2vec是Google公司在2013年开放的一款用于训练词向量的软件工具。它根据给定的语料库,通过优化后的训练模型快速有效的将一个词语表达成向量形式,其核心架构包括 CBOW和Skip-gram。
在开始之前,引入模型复杂度,定义如下:
O = E * T * Q
其中,E表示训练的次数,T表示训练语料中词的个数,Q因模型而异。E值不是我们关心的内容,T与训练语料有关,其值越大模型就越准确,Q在下面讲述具体模型是讨论。
NNLM模型是神经网络概率语言模型的基础模型。在NNLM模型中,从隐含层到输出层的计算时主要影响训练效率的地方,CBOW和Skip-gram模型考虑去掉隐含层。实践证明新训练的词向量的精确度可能不如NNLM模型(具有隐含层),但可以通过增加训练语料的方法来完善。
Word2vec包含两种训练模型,分别是CBOW和Skip_gram(输入层、发射层、输出层),如下图所示:
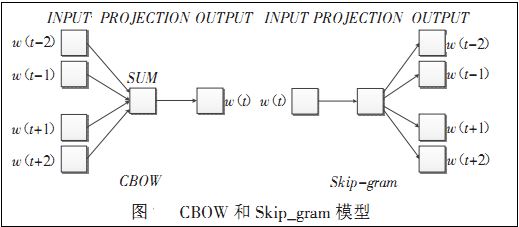
CBOW模型:
理解为上下文决定当前词出现的概率。在CBOW模型中,上下文所有的词对当前词出现概率的影响的权重是一样的,因此叫CBOW(continuous bag-of-words model)模型。如在袋子中取词,取出数量足够的词就可以了,至于取出的先后顺序是无关紧要的。
Skip-gram模型:
Skip-gram模型是一个简单实用的模型。为什么会提出该问题呢?
在NLP中,语料的选取是一个相当重要的问题。
首先,语料必须充分。一方面词典的词量要足够大,另一方面尽可能地包含反映词语之间关系的句子,如“鱼在水中游”这种句式在语料中尽可能地多,模型才能学习到该句中的语义和语法关系,这和人类学习自然语言是一个道理,重复次数多了,也就会模型了。
其次,语料必须准确。所选取的语料能够正确反映该语言的语义和语法关系。如中文的《人民日报》比较准确。但更多时候不是语料选取引发准确性问题,而是处理的方法。
由于窗口大小的限制,这会导致超出窗口的词语与当前词之间的关系不能正确地反映到模型中,如果单纯扩大窗口大小会增加训练的复杂度。Skip-gram模型的提出很好解决了这些问题。
Skip-gram表示“跳过某些符号”。例如句子“中国足球踢得真是太烂了”有4个3元词组,分别是“中国足球踢得”、“足球踢得真是”、“踢得真是太烂”、“真是太烂了”,句子的本意都是“中国足球太烂”,可是上面4个3元组并不能反映出这个信息。
此时,使用Skip-gram模型允许某些词被跳过,因此可组成“中国足球太烂”这个3元词组。如果允许跳过2个词,即2-Skip-gram,那么上句话组成的3元词组为:

由上表可知:一方面Skip-gram反映了句子的真实意思,在新组成的这18个3元词组中,有8个词组能够正确反映例句中的真实意思;另一方面,扩大了语料,3元词组由原来的4个扩展到了18个。
语料的扩展能够提高训练的准确度,获得的词向量更能反映真实的文本含义。
下载地址:http://word2vec.googlecode.com/svn/trunk/
使用SVN Checkout源代码,如下图所示。
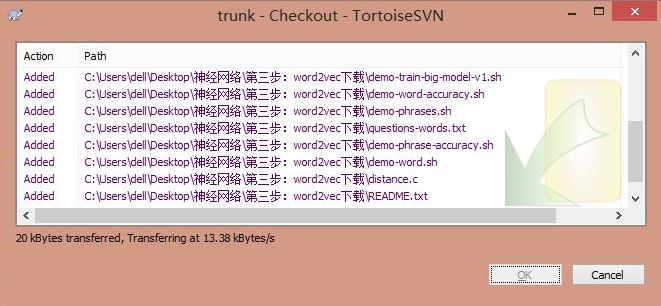
PS:最后附有word2vec源码、三大百科语料、腾讯新闻语料和分词python代码。
中文语料可以参考我的文章,通过Python下载百度百科、互动百科、维基百科的内容。
[python] lantern访问中文维基百科及selenium爬取维基百科语料
[Python爬虫] Selenium获取百度百科旅游景点的InfoBox消息盒
下载结果如下图所示,共300个国家,百度百科、互动百科、维基百科各自100个,对应的编号都是0001.txt~0100.txt,每个txt中包含一个实体(国家)的信息。
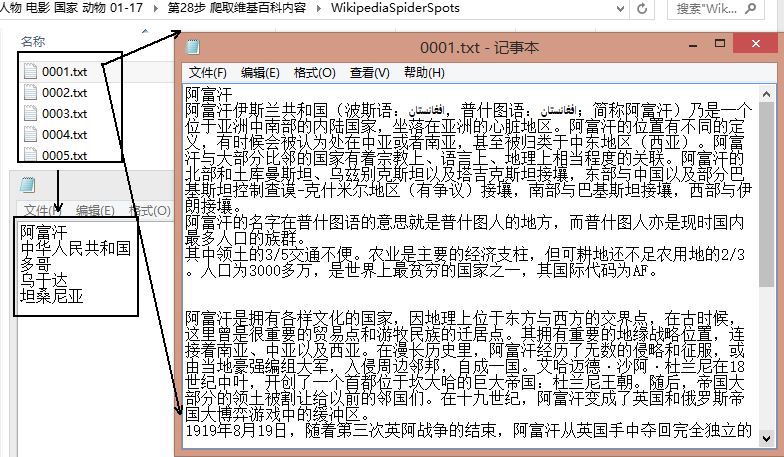
然后再使用Jieba分词工具对齐进行中文分词和文档合并。
上面只显示了对百度百科100个国家进行分词的代码,但核心代码一样。同时,如果需要对停用词过滤或标点符号过滤可以自定义实现。
分词详见: [python] 使用Jieba工具中文分词及文本聚类概念
分词合并后的结果为Result_Country.txt,相当于600行,每行对应一个分词后的国家。
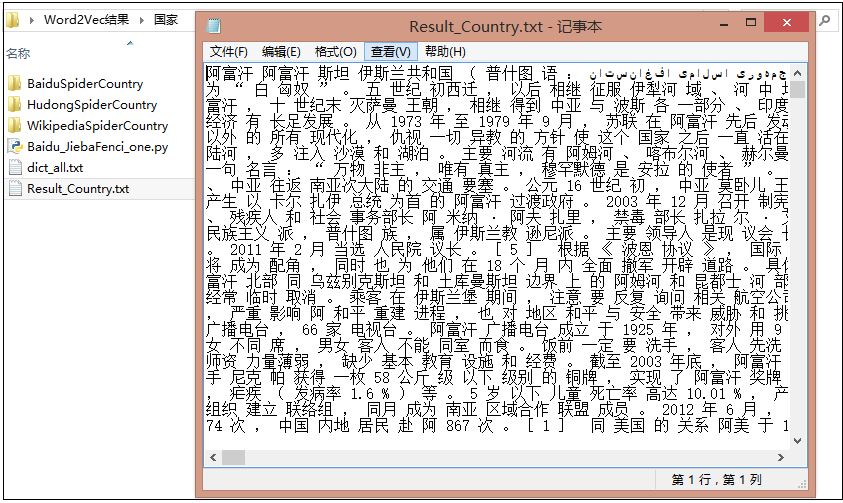
强烈推荐三篇大神介绍word2vec处理中文语料的文章,其中Felven好像是师兄。
Windows下使用Word2vec继续词向量训练 - 一只鸟的天空
利用word2vec对关键词进行聚类 - Felven
http://www.52nlp.cn/中英文维基百科语料上的word2vec实验
word2vec 词向量工具 - 百度文库
因为word2vec需要linux环境,所有首先在windows下安装linux环境模拟器,推荐cygwin。然后把语料Result_Country.txt放入word2vec目录下,修改demo-word.sh文件,该文件默认情况下使用自带的text8数据进行训练,如果训练数据不存在,则会进行下载,因为需要使用自己的数据进行训练,故注释掉下载代码。
demo-word.sh文件修改如下:
下图参数源自文章:Windows下使用Word2vec继续词向量训练 - 一只鸟的天空

运行命令sh demo-word.sh,等待训练完成。模型训练完成之后,得到了vectors.bin这个词向量文件,可以直接运用。
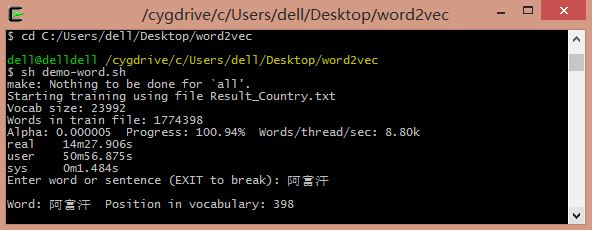
通过训练得到的词向量我们可以进行相应的自然语言处理工作,比如求相似词、关键词聚类等。其中word2vec中提供了distance求词的cosine相似度,并排序。也可以在训练时,设置-classes参数来指定聚类的簇个数,使用kmeans进行聚类。
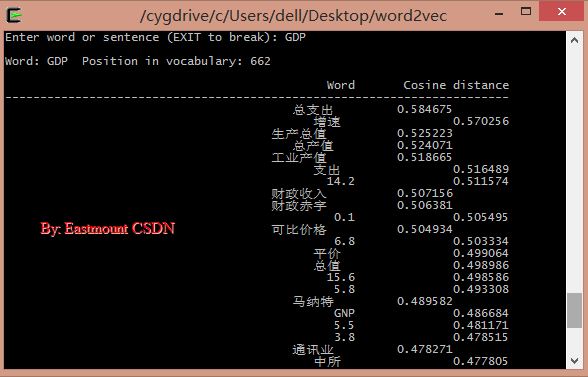
输入阿富汗:喀布尔(首都)、坎大哈(主要城市)、吉尔吉斯斯坦、伊拉克等。
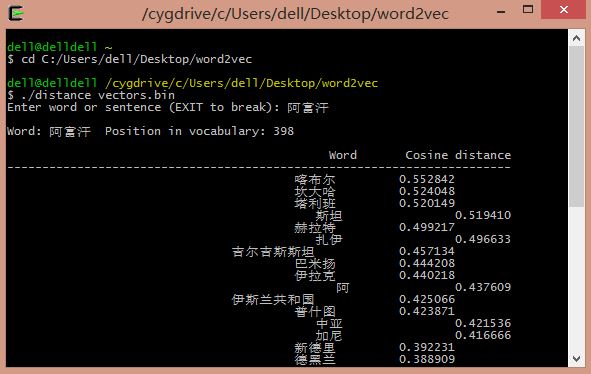
输入国歌:
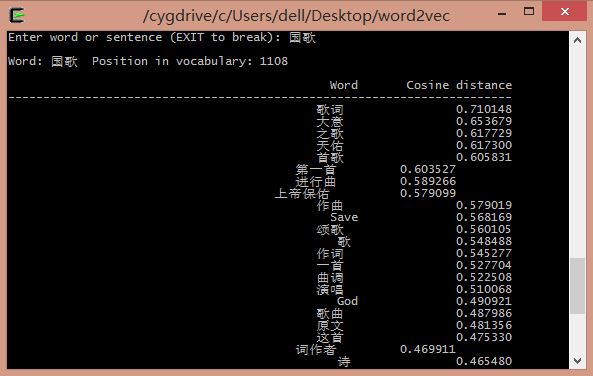
输入首都:
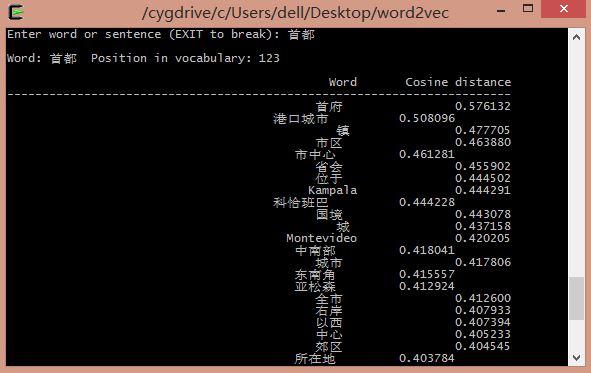
输入GDP:
Official website C language download address: http://word2vec.googlecode.com/svn/trunk/Official
website Python download address: http://radimrehurek.com/gensim/models/word2vec.html
1. Brief introduction
Reference: "The core architecture and application of Word2vec · Xiong Fulin, Deng Yihao, Tang Xiaosheng · Beijing University of Posts and Telecommunications 2015" "Study on the
working principle and application of Word2vec · Zhou Lian · Xi'an University of Electronic Science and Technology 2014" "
Research on clustering Chinese words using Word2vec · Zheng Wenchao, Xu Peng · Beijing University of Posts and Telecommunications 2013》
PS: The first part is mainly to introduce basic content to you. There are many such articles. I hope you can learn more and better basic content by yourself. This blog is mainly to introduce Usage of Word2Vec for Chinese text.
(1) Statistical language model
The general form of statistical language model is to solve the conditional probability of the next word given a known set of words. The form is as follows:
The general form of the statistical language model is intuitive and accurate. In the n-gram model, it is assumed that without changing the order of words in the context, the closer the relationship between words that are close to each other, and the farther the relationship between words that are farther away. When the distance is far enough, There is no correlation between words.
However, this model does not fully utilize the information of the corpus:
1) It does not consider the relationship between words that are further away and the current word, that is, words beyond the range n are ignored, and the two are likely to be related.
For example, "Washington is the capital of the United States" is the current sentence, and "Beijing is the capital of China" appears more than n words later. In the n-ary model, "Washington" and "Beijing" are not related. However, These two sentences imply a grammatical and semantic relationship, that is, "Washington" and "Beijing" are both nouns, and they are the capitals of the United States and China respectively.
2) The similarity between words is ignored, that is, the above model cannot consider the grammatical relationship of words.
For example, "fish swimming in the water" in the corpus should help us generate sentences such as "horses running on the grassland", because in the two sentences "fish" and "horse", "water" and "grassland", and "swim" ” has the same grammatical characteristics as “run”, “中” and “上”.
In the neural network probabilistic language model, these two kinds of information will be fully utilized.
(2) Neural network probabilistic language model
The neural network probabilistic language model is an emerging natural language processing algorithm. This model obtains word vectors and probability density functions by learning training corpus. The word vector is a multi-dimensional real number vector, and the vector contains natural language. The semantic and grammatical relationships between words, the size of the cosine distance between word vectors represents the distance of the relationship between words, and the addition and subtraction of word vectors is the computer's "choosing words to create sentences".
The neural network probabilistic language model has gone through a long development stage. The neural network language model NNLM (Neural network language model) proposed by Bengio et al. in 2003 is the most famous, and future development work will refer to this model. After more than ten years of research, the neural network probabilistic language model has made great progress.
Nowadays, in terms of architecture, there are CBOW models and Skip-gram models that are simpler than NNLM; secondly, in terms of training, Hierarchical Softmax algorithm and negative sampling algorithm (Negative Sampling) have appeared, and in order to reduce the accuracy of frequent word pairs and training speed The subsampling technology introduced due to the influence of
The picture above is a natural language estimation model NNLM (Neural Network Language Model) based on a three-layer neural network. NNLM can calculate the probability that the next word in a certain context is wi, that is (wi=i|context), and the word vector is a by-product of its training. NNLM generates the corresponding vocabulary V based on the corpus C.
For knowledge about the general network, you can refer to my previous blog: Introduction to Neural Networks and Machine Learning Basics Sharing
NNLM Recommended Articles by Rachel-Zhang: word2vec - efficient word feature extraction
In recent years, neural network probabilistic language models have developed rapidly, and Word2vec is the latest technology A collection of theories.
Word2vec is a software tool for training word vectors opened by Google in 2013. Therefore, before talking about word2vec, let me first introduce you to the concept of word vectors.
(3) Word vector
reference: licstar’s NLP article Deep Learning in NLP (1) Word vectors and language models
As the author said: Deep Learning algorithms have achieved amazing results in the image and audio fields, but have not yet achieved success in the NLP field. Such exciting results to see. There is a saying that language (words, sentences, chapters, etc.) is a high-level cognitive abstract entity produced in the human cognitive process, while speech and images are lower-level original input signals, so the latter two are more suitable for deep learning. Learning features.
However, representing words in the form of "word vectors" can be said to be a core technology that introduces Deep Learning algorithms into the field of NLP. The first step in converting natural language understanding problems into machine learning problems is to mathematicalize these symbols through a method.
词向量具有良好的语义特性,是表示词语特征的常用方式。词向量的每一维的值代表一个具有一定的语义和语法上解释的特征。故可以将词向量的每一维称为一个词语特征。词向量用Distributed Representation表示,一种低维实数向量。
例如,NLP中最直观、最常用的词表示方法是One-hot Representation。每个词用一个很长的向量表示,向量的维度表示词表大小,绝大多数是0,只有一个维度是1,代表当前词。
“话筒”表示为 [0 0 0 1 0 0 0 0 0 0 0 0 0 0 0 0 …] 即从0开始话筒记为3。
但这种One-hot Representation采用稀疏矩阵的方式表示词,在解决某些任务时会造成维数灾难,而使用低维的词向量就很好的解决了该问题。同时从实践上看,高维的特征如果要套用Deep Learning,其复杂度几乎是难以接受的,因此低维的词向量在这里也饱受追捧。
Distributed Representation低维实数向量,如:[0.792, −0.177, −0.107, 0.109, −0.542, …]。它让相似或相关的词在距离上更加接近。
总之,Distributed Representation是一个稠密、低维的实数限量,它的每一维表示词语的一个潜在特征,该特征捕获了有用的句法和语义特征。其特点是将词语的不同句法和语义特征分布到它的每一个维度上去表示。
推荐我前面的基础文章:Python简单实现基于VSM的余弦相似度计算
(4) Word2vec
参考:Word2vec的核心架构及其应用 · 熊富林,邓怡豪,唐晓晟 · 北邮2015年
Word2vec是Google公司在2013年开放的一款用于训练词向量的软件工具。它根据给定的语料库,通过优化后的训练模型快速有效的将一个词语表达成向量形式,其核心架构包括 CBOW和Skip-gram。
在开始之前,引入模型复杂度,定义如下:
O = E * T * Q
其中,E表示训练的次数,T表示训练语料中词的个数,Q因模型而异。E值不是我们关心的内容,T与训练语料有关,其值越大模型就越准确,Q在下面讲述具体模型是讨论。
NNLM模型是神经网络概率语言模型的基础模型。在NNLM模型中,从隐含层到输出层的计算时主要影响训练效率的地方,CBOW和Skip-gram模型考虑去掉隐含层。实践证明新训练的词向量的精确度可能不如NNLM模型(具有隐含层),但可以通过增加训练语料的方法来完善。
Word2vec包含两种训练模型,分别是CBOW和Skip_gram(输入层、发射层、输出层),如下图所示:
CBOW模型:
理解为上下文决定当前词出现的概率。在CBOW模型中,上下文所有的词对当前词出现概率的影响的权重是一样的,因此叫CBOW(continuous bag-of-words model)模型。如在袋子中取词,取出数量足够的词就可以了,至于取出的先后顺序是无关紧要的。
Skip-gram模型:
Skip-gram模型是一个简单实用的模型。为什么会提出该问题呢?
在NLP中,语料的选取是一个相当重要的问题。
首先,语料必须充分。一方面词典的词量要足够大,另一方面尽可能地包含反映词语之间关系的句子,如“鱼在水中游”这种句式在语料中尽可能地多,模型才能学习到该句中的语义和语法关系,这和人类学习自然语言是一个道理,重复次数多了,也就会模型了。
其次,语料必须准确。所选取的语料能够正确反映该语言的语义和语法关系。如中文的《人民日报》比较准确。但更多时候不是语料选取引发准确性问题,而是处理的方法。
由于窗口大小的限制,这会导致超出窗口的词语与当前词之间的关系不能正确地反映到模型中,如果单纯扩大窗口大小会增加训练的复杂度。Skip-gram模型的提出很好解决了这些问题。
Skip-gram表示“跳过某些符号”。例如句子“中国足球踢得真是太烂了”有4个3元词组,分别是“中国足球踢得”、“足球踢得真是”、“踢得真是太烂”、“真是太烂了”,句子的本意都是“中国足球太烂”,可是上面4个3元组并不能反映出这个信息。
此时,使用Skip-gram模型允许某些词被跳过,因此可组成“中国足球太烂”这个3元词组。如果允许跳过2个词,即2-Skip-gram,那么上句话组成的3元词组为:
由上表可知:一方面Skip-gram反映了句子的真实意思,在新组成的这18个3元词组中,有8个词组能够正确反映例句中的真实意思;另一方面,扩大了语料,3元词组由原来的4个扩展到了18个。
语料的扩展能够提高训练的准确度,获得的词向量更能反映真实的文本含义。
2.下载源码
下载地址:http://word2vec.googlecode.com/svn/trunk/
使用SVN Checkout源代码,如下图所示。
3.中文语料
PS:最后附有word2vec源码、三大百科语料、腾讯新闻语料和分词python代码。
中文语料可以参考我的文章,通过Python下载百度百科、互动百科、维基百科的内容。
[python] lantern访问中文维基百科及selenium爬取维基百科语料
[Python爬虫] Selenium获取百度百科旅游景点的InfoBox消息盒
下载结果如下图所示,共300个国家,百度百科、互动百科、维基百科各自100个,对应的编号都是0001.txt~0100.txt,每个txt中包含一个实体(国家)的信息。
然后再使用Jieba分词工具对齐进行中文分词和文档合并。
#encoding=utf-8
import sys
import re
import codecs
import os
import shutil
import jieba
import jieba.analyse
#导入自定义词典
jieba.load_userdict("dict_all.txt")
#Read file and cut
def read_file_cut():
#create path
pathBaidu = "BaiduSpiderCountry\\"
resName = "Result_Country.txt"
if os.path.exists(resName):
os.remove(resName)
result = codecs.open(resName, 'w', 'utf-8')
num = 1
while num<=100: #5A 200 其它100
name = "%04d" % num
fileName = pathBaidu + str(name) + ".txt"
source = open(fileName, 'r')
line = source.readline()
while line!="":
line = line.rstrip('\n')
#line = unicode(line, "utf-8")
seglist = jieba.cut(line,cut_all=False) #精确模式
output = ' '.join(list(seglist)) #空格拼接
#print output
result.write(output + ' ') #空格取代换行'\r\n'
line = source.readline()
else:
print 'End file: ' + str(num)
result.write('\r\n')
source.close()
num = num + 1
else:
print 'End Baidu'
result.close()
#Run function
if __name__ == '__main__':
read_file_cut()
上面只显示了对百度百科100个国家进行分词的代码,但核心代码一样。同时,如果需要对停用词过滤或标点符号过滤可以自定义实现。
分词详见: [python] 使用Jieba工具中文分词及文本聚类概念
分词合并后的结果为Result_Country.txt,相当于600行,每行对应一个分词后的国家。
4.运行源码
强烈推荐三篇大神介绍word2vec处理中文语料的文章,其中Felven好像是师兄。
Windows下使用Word2vec继续词向量训练 - 一只鸟的天空
利用word2vec对关键词进行聚类 - Felven
http://www.52nlp.cn/中英文维基百科语料上的word2vec实验
word2vec 词向量工具 - 百度文库
因为word2vec需要linux环境,所有首先在windows下安装linux环境模拟器,推荐cygwin。然后把语料Result_Country.txt放入word2vec目录下,修改demo-word.sh文件,该文件默认情况下使用自带的text8数据进行训练,如果训练数据不存在,则会进行下载,因为需要使用自己的数据进行训练,故注释掉下载代码。
demo-word.sh文件修改如下:
make
#if [ ! -e text8 ]; then
# wget http://mattmahoney.net/dc/text8.zip -O text8.gz
# gzip -d text8.gz -f
#fi
time ./word2vec -train Result_Country.txt -output vectors.bin -cbow 1 -size 200 -window 8 -negative 25 -hs 0 -sample 1e-4 -threads 20 -binary 1 -iter 15
./distance vectors.bin
下图参数源自文章:Windows下使用Word2vec继续词向量训练 - 一只鸟的天空
运行命令sh demo-word.sh,等待训练完成。模型训练完成之后,得到了vectors.bin这个词向量文件,可以直接运用。
5.结果展示
通过训练得到的词向量我们可以进行相应的自然语言处理工作,比如求相似词、关键词聚类等。其中word2vec中提供了distance求词的cosine相似度,并排序。也可以在训练时,设置-classes参数来指定聚类的簇个数,使用kmeans进行聚类。
cd C:/Users/dell/Desktop/word2vec
sh demo-word.sh
./distance vectors.bin 输入阿富汗:喀布尔(首都)、坎大哈(主要城市)、吉尔吉斯斯坦、伊拉克等。
输入国歌:
输入首都:
输入GDP:
最后希望文章对你有所帮助,主要是使用的方法。同时更多应用需要你自己去研究学习。
word2vec源码、语料下载地址:
http://download.csdn.net/detail/eastmount/9434889
(By:Eastmount 2016-02-18 深夜1点 http://blog.csdn.net/eastmount/ )