Tip: After the article is written, the table of contents can be automatically generated. How to generate it can refer to the help document on the right
Article directory
foreword
Tip: Here you can add the general content to be recorded in this article:
For example: With the continuous development of artificial intelligence, the technology of machine learning is becoming more and more important. Many people have started learning machine learning. This article introduces the basics of machine learning. content.
Tip: The following is the text of this article, and the following cases are for reference
1. Word vector
Natural language processing (NLP), to hand over natural language to algorithms in machine learning, usually requires mathematical language. The word vector is a way to mathematicize the words in the language.
Among them, there are mainly two ways of expressing
- One-Hot Representation
- Distributed Representation
1.1 One-Hot
One-Hot (one-hot encoding) is the simplest encoding method.
It is to use a very long vector to represent a word. The length of the vector is the size of the dictionary. The component of the vector has only one 1, and the others are all 0.
This method uses coefficient storage, which is very simple and easy to implement, but it has the following two disadvantages.
1. It is easy to suffer from the curse of dimensionality. When your dictionary is very large, the dimension of your word vector will be very large.
2. The similarity between words cannot be well described.
1.2 Distributed Representation
The basic idea is to represent a word directly with an ordinary vector (that is, to represent a word with low dimensions).
At that time, such a representation required some training.
The word vectors obtained in this way generally have spatial meaning, that is to say, the distance measure between the word vectors in this space can also represent the "distance" between the corresponding two words.
2. Language model
The formalized description of the language model is given a string s of T words, look at the probability P(w1,w2,…,wt) that it is a natural language. w1 to wT represent each word in this sentence in turn.
If this probability is extremely low, it means that this sentence does not appear often, so it is not considered a natural language, because it rarely appears in the corpus. If the probability of occurrence is high, it means that it is a natural language.
2.1 N-gram model
The language model requires that all the words before the word be considered in the calculation, but N-Gram only considers the first n words.
This also means that the value of n will affect the effect.
Generally speaking, we consider n to be around 3.
Of course, N-gram also has its limitations.
1. N can’t be too large. If it is too large, the corpus is often insufficient, so the downgrading method is basically used.
2. The similarity between words cannot be modeled, that is, two words often appear behind the same context, but the model cannot reflect this similarity.
3. Some n-tuples (a combination of n words, related to the order) have not appeared in the corpus, and the corresponding conditional probability is 0, so the probability of the whole sentence is 0, which is wrong. There are mainly two solutions: smoothing method (basically adding a number to both the numerator and denominator) and back-off method (using the probability of n-1 tuples to replace the probability of n-tuples)
2.2 N-pos model
Since in actual situations, many words are conditionally dependent on the grammatical function of the words in front of it, so the N-pos model first classifies the words according to the part of speech, and then calculates P.
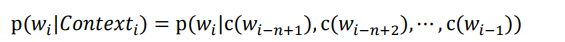
where C is the category mapping function. This will reduce the computational load of the model.
2.3 Problems and goals of the model
Since many methods use hard statistics to obtain the final result, or for example, using trigram also needs to store a huge tuple and probability mapping, which will require a very large memory, so many scientists want to use functions to fit Calculate p.
In the fitting method, there is a neural network, and word2vec is one of the methods.