introduction
Intelligent question and answer systems are widely used to answer questions asked by people in the form of natural language. Classic application scenarios include: intelligent voice interaction, online customer service, knowledge acquisition, emotional chat, etc. According to QA tasks, QA can be roughly divided into five categories:
text-based QA (TBQA),
knowledge base question answering (KBQA),
community question answering (CQA)
table question and answer (Table Question Answering, TQA),
Visual Question Answering (VQA)
. Below are the tasks (what is the answer), methods (how to answer, only the deep learning part is sorted out, traditional algorithms are skipped), sample projects (practical or Online experience), conclusion (personal reflection and measurement).
Text-based QA (TBQA)
1: Task
Based on the given text, generating answers corresponding to the questions can also be called machine reading comprehension (MRC).
Processing process:
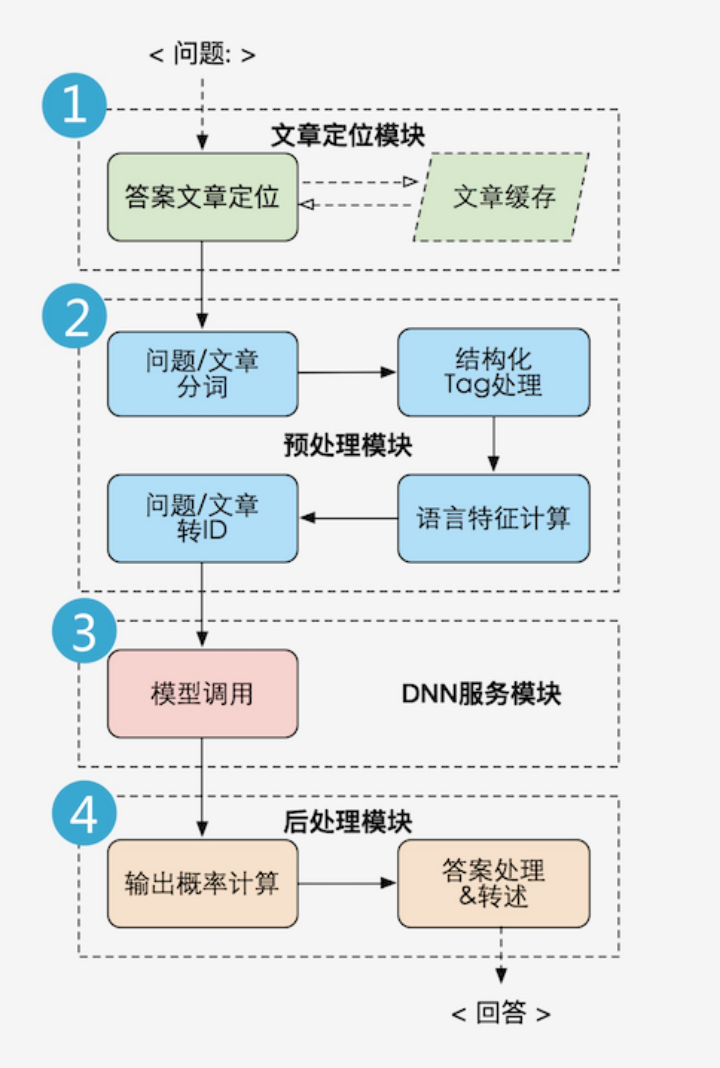
1) Article positioning module Text
reading:
According to user questions, use text classification, retrieval and other algorithms to obtain a collection of paragraphs with a high probability
2) Pre-processing module
Sentence vectorization, format normalization, feature calculation, etc.
3) DNN service module
Load the deep learning model and predict the answer score
4) Post-processing module
selects the best answer output based on dynamic programming
Depending on the task, it can be divided into the following situations:
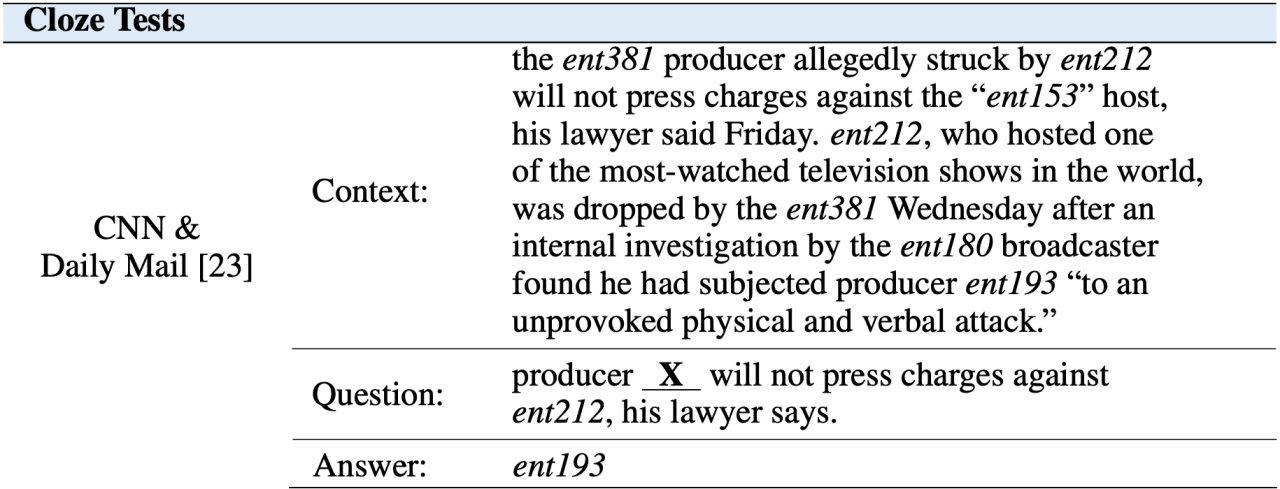
Fill in the blanks with your answers, similar to cloze.
Given text content, predict the missing words or phrases in the question. The form of data sets for this type of questions is mostly [background, question, answer] triples, such as:
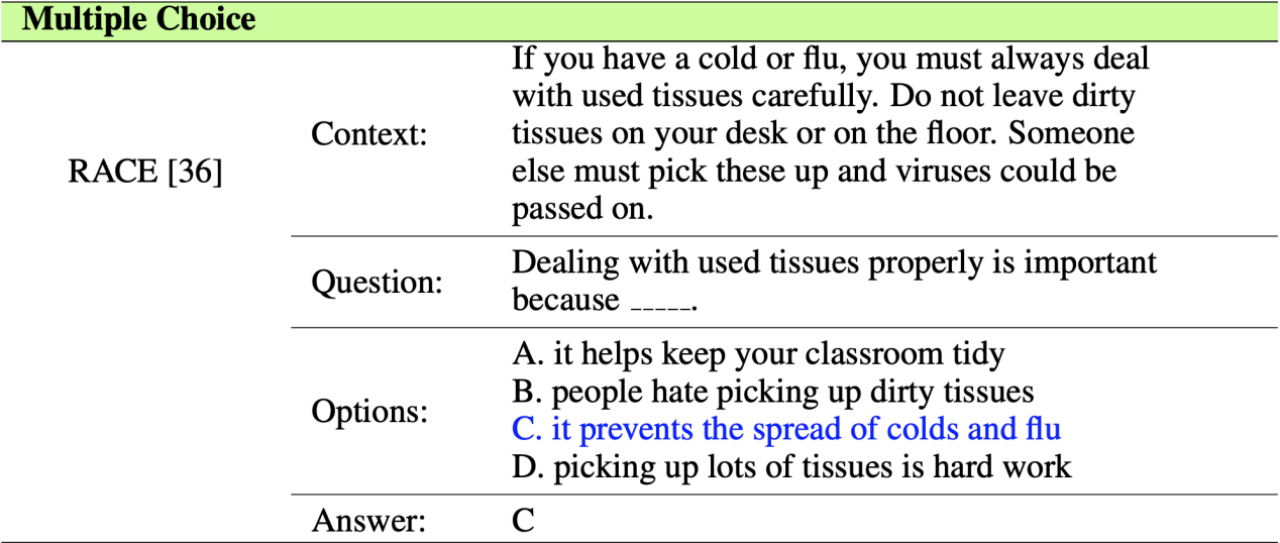
Answer selection is similar to multiple choice questions.
Given the text content and given several answer candidates corresponding to the question, sort these answer candidates and select the most likely answer candidate. The data set for this type of question is usually the English test reading comprehension, such as: 3)
Answers Extraction, fragment extraction.
Extract answers from text based on given questions. The answer here could be any fragment from the text. Most of the data sets for this type of questions are in the form of [original text, question, answer] triples.

Summary of answers, free Q&A.
Based on the given question and text, generate a summary that can answer the question. The answer fragment here may not appear in the corresponding text. Most of the data set forms of this type of questions are: ID text ID text ID question [label] answer [label]

Knowledge-Based Machine Reading Comprehension (Knowledge-Based MRC)
Answers that require external knowledge. The data set form of the question here is usually: several text overviews in a field, and dialogue questions and answers around the given text. The dialogues are relatively short, usually only one or two pairs of dialogues. for example:

Machine reading comprehension with unanswerable questions (MRC with Unanswerable Questions)
Answers that cannot be obtained from context and external knowledge.

Conversational Question Answering
Given a question and answer, A asks a question, B replies with an answer, and then A continues to ask questions based on the answer. This approach is somewhat similar to a multi-turn conversation.

In short, no matter what kind of task, you need to read and understand a given text passage, and then answer questions based on it.
Two: Method
Methods based on pre-training models
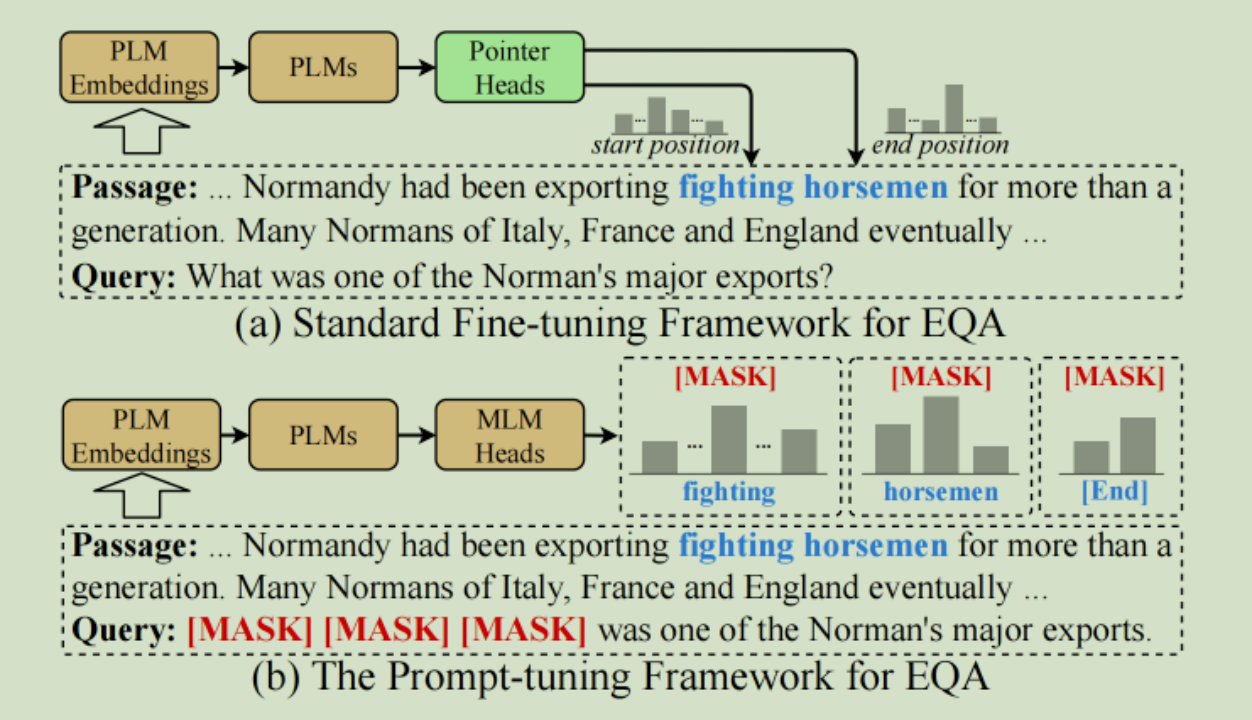
(1) In recent years, the NLP field has been trained through a large amount of general domain data, and a number of excellent pre-trained language models such as ELMO, GPT, BERT, and ENRIE have been born. In specific reading comprehension tasks, the learned sentence feature information can be applied to specific tasks by performing domain fine-tuning, data fine-tuning, and task fine-tuning. (BERT: Combining the advantages of GPT and ELMO, introducing the Transformer coding model, using a two-way language model, and adding a mask language model and the task of judging the order of sentences during training, which can obtain more language representations) query and context concat
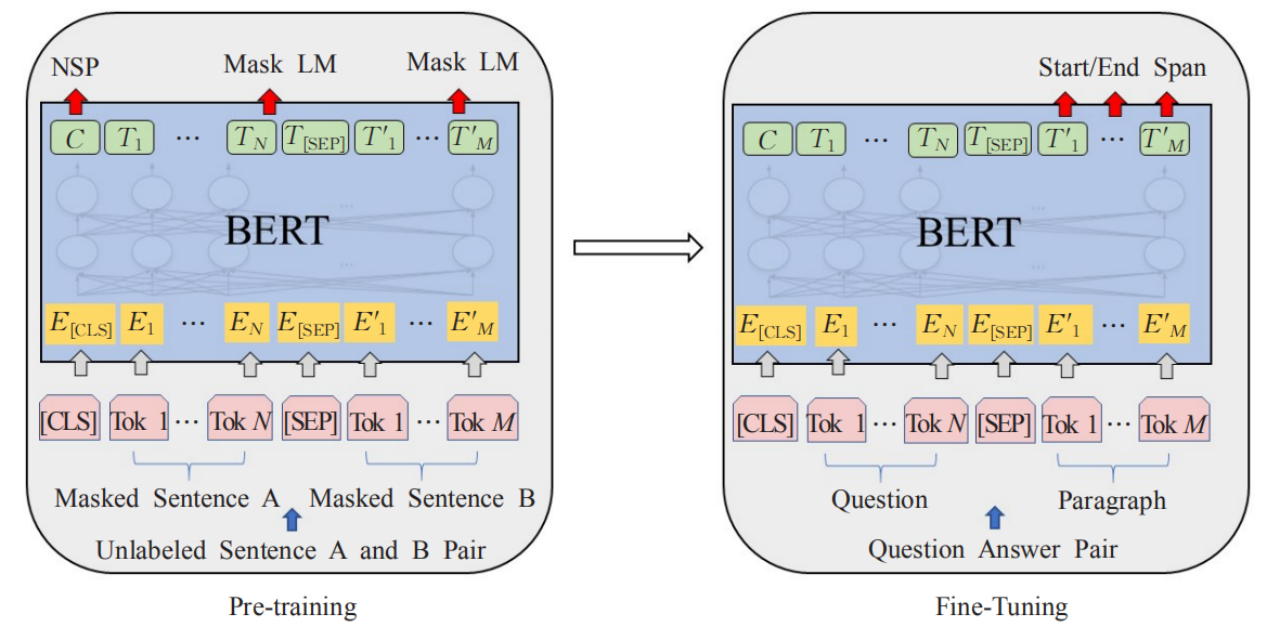
input Get the vector representation of each token in BERT. The input form is: CLS “query” SEP context. After BERT training, find the span that needs to be extracted. (2) The contrastive prompt
adjustment framework (KECP) based on knowledge enhancement is a kind of small sample learning The algorithm uses Prompt-Tuning as the basic learning paradigm, and extracts text that meets the requirements from a given article as the answer when only a very small amount of training data needs to be annotated.

Three: Sample project
1:easyNLP
Project address: https://github.com/alibaba/EasyNLP
Project description: 1.4K collection, 179 clones, and has been maintained. It was updated a few hours ago. It is a project of the Alibaba Cloud team that was included in EMNLP2022, the top conference.
Paper: KECP: Knowledge-Enhanced Contrastive Prompting for Few-shot Extractive Question Answering https://arxiv.org/abs/2205.03071
Explanation: The algorithm KECP is included in EMNLP and can achieve machine reading comprehension with very little training data
https:/ /zhuanlan.zhihu.com/p/590024650
2:DuReader
Project address: https://github.com/baidu/DuReader/tree/master/DuReader-2.0
project collection 998, clone 312, is a project of Baidu team that was once included in ACL2022 of Dinghui. However, this is an open domain question answering system, the data set is complex in shape, the data set is noisy, and it requires a large amount of data.
Paper: DuReadervis: A Chinese Dataset for Open-domain Document Visual Question Answering https://aclanthology.org/2022.findings-acl.105/Explanation
: ACL2022 | Open-domain Document Visual Question Answering Dataset for Chinese real search scenarios
https: //blog.csdn.net/qq_27590277/article/details/125326071
This project has been implemented in the automotive industry: "Cross-modal Intelligent Questions and Answers in Automobile Instructions"
Address: https://aistudio.baidu.com/aistudio/projectdetail/4049663
4. Conclusion
Machine Reading Comprehension Question and Answer (MRCQA) is a method of training by giving an article and then asking and answering questions based on the article as labels. During the training process,
first of all, in order to obtain more accurate words and sentences related to the question, many attention mechanisms have been proposed. This is a point worth studying.
Secondly, judging from several cases of task segmentation, most MRC solutions retrieve answers by matching from the original document, which is actually different from human reading comprehension (people will use a priori to a greater or lesser extent. knowledge), so how to make the model obtain prior knowledge is also something worth studying.
Cutting to our current actual question and answer task, I personally think:
to determine the shape of the data set, we learn from kecp. The input is not the conventional Q+P, but Qprompt +P. The Qprompt here
can be regarded as the data in the Qprompt compared to Q. Attention is done at the level.
Knowledge Base Question Answering (KBQA)
1: Task
Knowledge Base/Knowledge Graph includes three types of elements: entity, relationship, and attribute. Entities represent some people or things, and relationships are used to connect two entities and represent some connections between them. KBQA is to analyze and convert questions into queries in the knowledge graph. After the query results are obtained, they are filtered and translated into answers for output.
Application scenarios: Mostly used in structured data scenarios, such as e-commerce, medicine, etc. The most representative knowledge graph question and answer systems are various search engines, such as Baidu, Google, etc.
The following is a simple example:
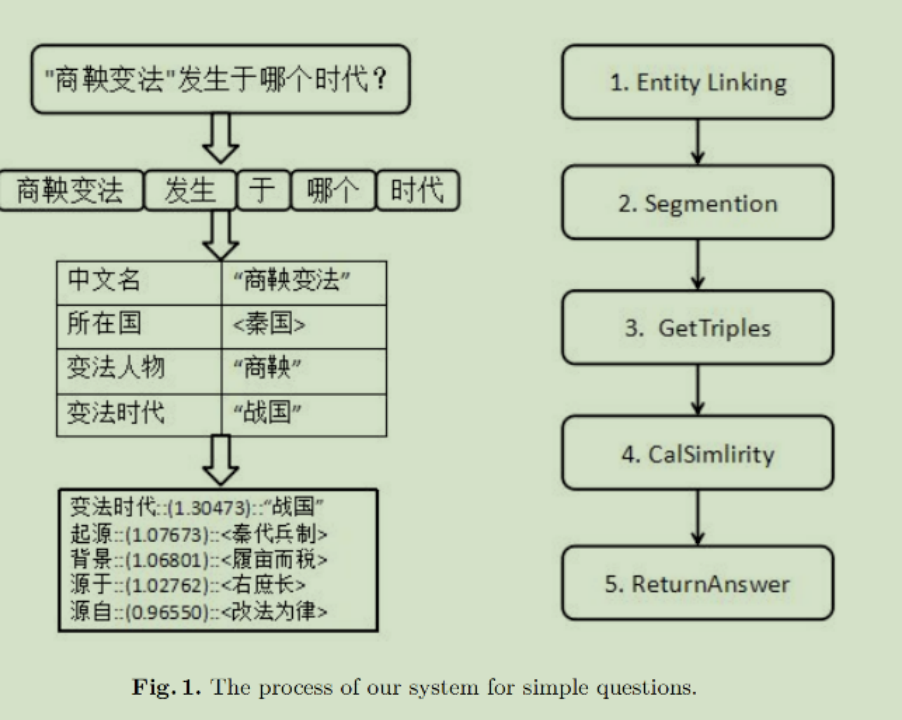
Question: In which dynasty did "Shang Yang's Reform" occur?
The knowledge graph question answering system obtains the answer in 5 steps:
1: Determine the entity mentioned in the question; 2: Segment other parts of the question; 3: Obtain all triples containing the entity through the web interface; 4. Calculate " "Relationship" and the similarity between segmentation words, 5: Sort those triples based on the similarity results to return the correct answer;
Two: Method
1: Construction of knowledge graph
What: KBQA, first of all, is a very important process in the construction of the knowledge graph, that is, the construction of the data set. According to different fields, we build knowledge graphs in different fields, such as Alibaba product knowledge graph, zego metaverse knowledge graph, etc. After the data set is constructed, add a QA system to it, and it becomes a robot that can answer XX related questions.
How: (1) You can simply build your own knowledge graph data set through Neo4j. For
specific practical procedures, please refer to: https://blog.csdn.net/jesseyule/article/details/110453709 (2) Build a practical reference
through OpenNRE
: http://pelhans.com/2019/01/04/kg_from_0_note9/
ccks2019_sample subset: Structured triplet form, which is currently the most widely used.

2: Conversion of questions asked into graph queries
This step can be done through semantic analysis to construct a graph query for this question and get the answer; it can also be based on information extraction, extract entities from the question, then match the question in the existing knowledge graph, and finally sort and select the results.
Here is an analysis of Meituan Knowledge Graph Q&A: https://tech.meituan.com/2021/11/03/knowledge-based-question-answering-in-meituan.html
Three: Sample project
One: Question and answer system for NBA related questions: https://github.com/wey-gu/nebula-siwi/
Two: KBQA-BERT
project address: https://github.com/WenRichard/KBQA-BERT
project collection 1.3K , clone 342, last updated 4 years ago, using bert for document feature extraction and sentence similarity calculation. An older method.
Three: Intelligent question and answer system QASystemOnMedicalKG project address based on medical knowledge graph
: https://github.com/liuhuanyong/QASystemOnMedicalKG
project collection 4.7K, clone 1.8K, last updated 3 years ago. Similarly, there are intelligent question and answer systems based on criminal knowledge graphs, intelligent question and answer systems based on military knowledge graphs, etc. These are relatively unpopular and have low engineering popularity.
Four: haystack
project address: https://github.com/deepset-ai/haystack
project collection 6.9K, clone 1K, and has been maintained by people. It was updated a few hours ago to implement document-based semantic analysis and question and answer, which can be quickly It is an end-to-end framework for building Chatgpt-like question answers, semantic search, text generation, etc. Reference document: https://docs.haystack.deepset.ai/docs/knowledge_graph
Five: intelligent_question_answering_v2
project address: https://github.com/milvus-io/bootcamp/tree/master/solutions/nlp/question_answering_system
Project collection 1.1K, clone 442, last updated 3 months ago. Use Milvus for similarity calculation and search to find questions similar to those in the data set, and then match the answers to similar questions. FastAPI is used for interactive interfaces, which is relatively simple to build.
Four conclusions:
(1) Compared with MRC, KBQA’s corpus is in a question-and-answer format and is easy to obtain. KBQA requires a structured knowledge base, which is more difficult to obtain.
(2) The KBQA process is to identify the problematic entities and then construct a graph query, while MRC needs to understand a bunch of unstructured corpus. Both in terms of speed and efficiency, KBQA is better than MRC.
(3) Cutting into our current actual question and answer tasks, I personally think:
① If you want the algorithm to be implemented quickly, it is recommended to use MRC because its data set is easy to obtain and clean.
② If you want to pursue fast response time and high accuracy, it is recommended to use KBQA. Then it is particularly important to build our own knowledge graph. Whether the answer produced by the subsequent model is accurate has a lot to do with the knowledge graph.
Community Question Answering (CQA)
One: Task
The technical point lies in the problem of semantic text matching and the problem of calculating the similarity and correlation between texts. According to task division, CQA can be further divided into:
1.FAQ
Automatic answers to business knowledge questions frequently asked by users.
https://github.com/Bennu-Li/ChineseNlpCorpus
For example, legal document matching example:

2.CQA
Q&A pairs questions and answers from users in community forums, which are relatively easy to obtain, have no manual annotation, and are of relatively low quality.
Two: Method
The commonly used twin network compares the similarity of two inputs
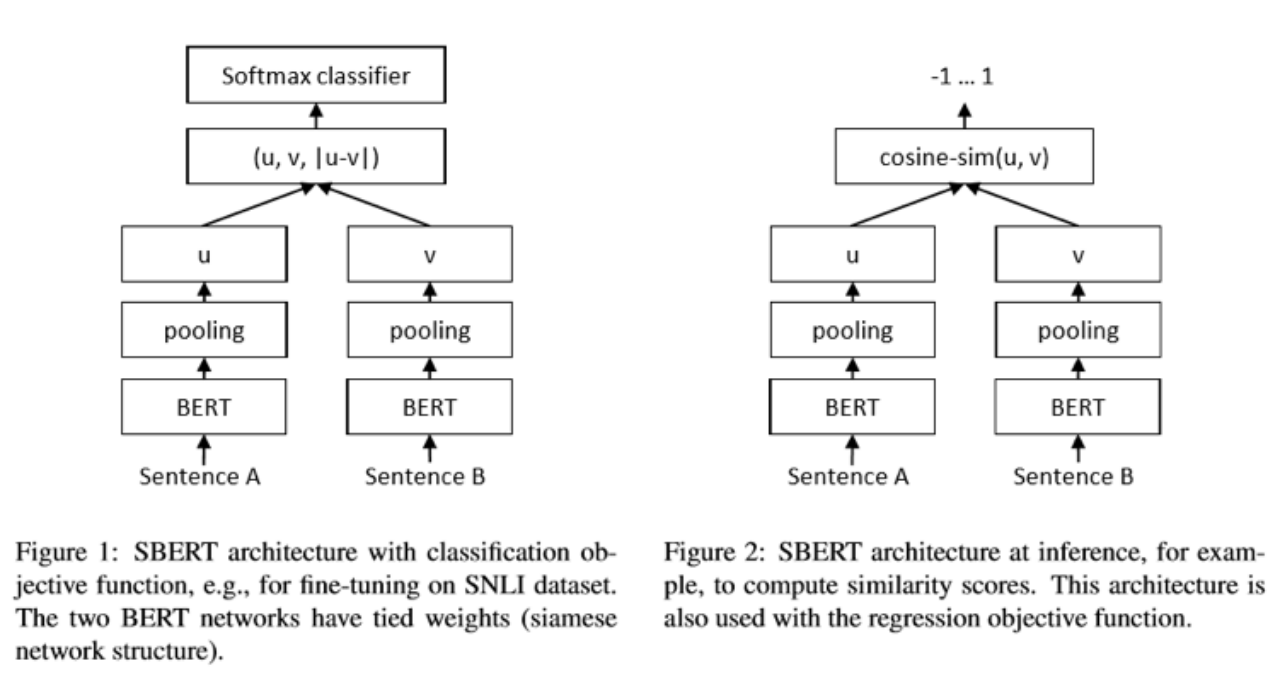
. It can be used as a classification task to output whether sentenceA is similar to sentenceB. It can also be used as a regression task to output the degree of similarity between sentenceA and sentenceB.
Four conclusions:
CQA is mainly used for semantic similarity matching, such as medical question and answer matching, so-and-so customer service question matching, so-and-so demand and result matching, etc. It is weakly related to our current actual question and answer tasks, and there is not much research.
Table Question Answering (TQA)
1: Task:
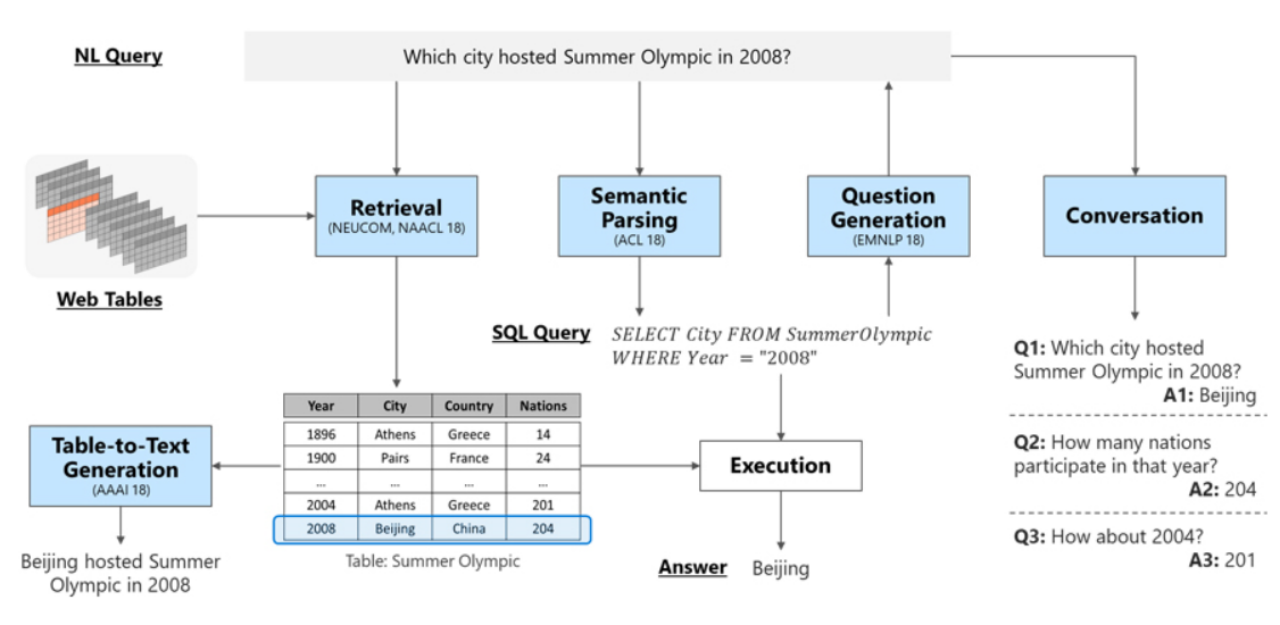
The TQA task process is divided into the above five steps, which are:
(1) Table retrieval: retrieve tables that are more relevant to the question from a pile of tables
(2) Semantic analysis: convert unstructured text questions into SQL Statement
(3) Question generation: Based on the above semantic analysis, relevant question output is generated. At the same time, the similarity between these questions and the questions asked is ranked.
(4) Dialogue: Answer the questions raised above.
(5) Text generation: describe the questions and answers listed above in natural language and output them as answers.
Visual Question Answering (VQA)
1: Task
VQA (Visual Question Answering) refers to giving the machine a picture and an open-ended natural language question, and requiring the machine to output a natural language answer. This is a relatively new and popular direction at present. VQA subdivision can also be divided into picture question and answer, video question and answer, picture and text question and answer, chart question and answer, etc.
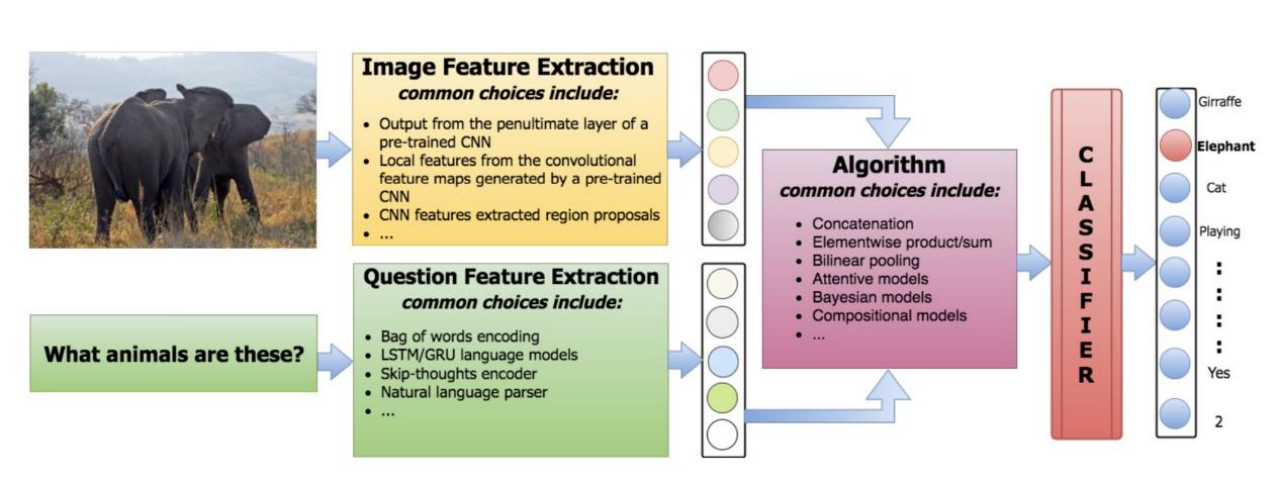
Three: Sample project
1: ERNIE-Layout: Pre-training for document understanding enhanced by layout knowledge
1: Paper address: https://arxiv.org/pdf/2210.06155v2.pdf
2: Project address: https://github.com/PaddlePaddle/PaddleNLP/ tree/develop/model_zoo/ernie-layout
3: Experience: https://huggingface.co/spaces/PaddlePaddle/ERNIE-Layout
Enter a picture, and then ask questions based on that picture, eg:
Q: What is this? Material?
The system automatically answers: Real estate information query result notification form
and automatically marks the location of the information on the uploaded map.
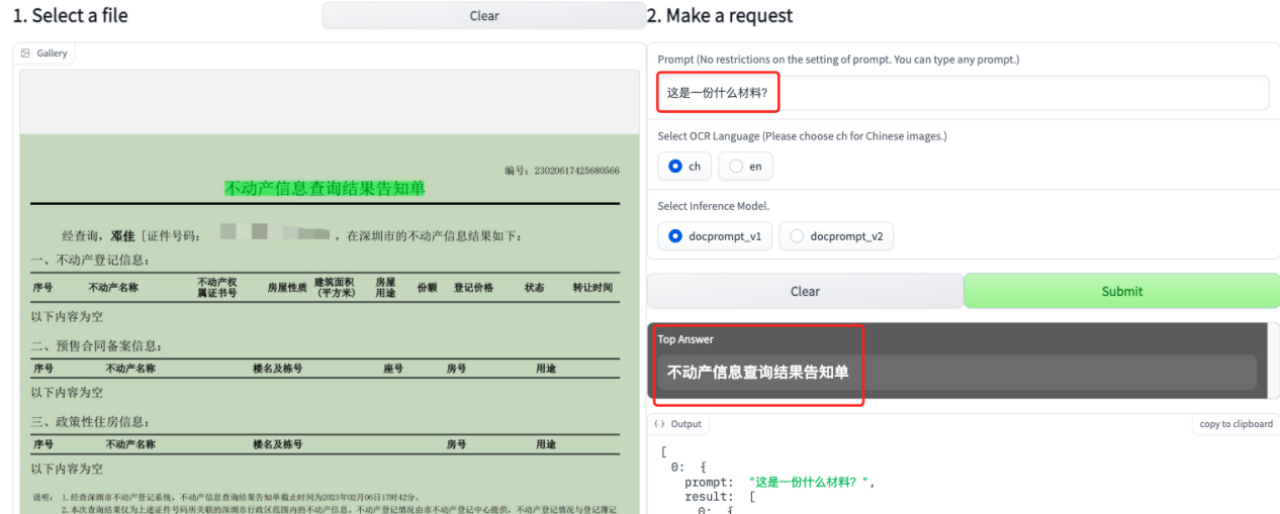
2: vilt
experience: https://huggingface.co/tasks/visual-question-answering
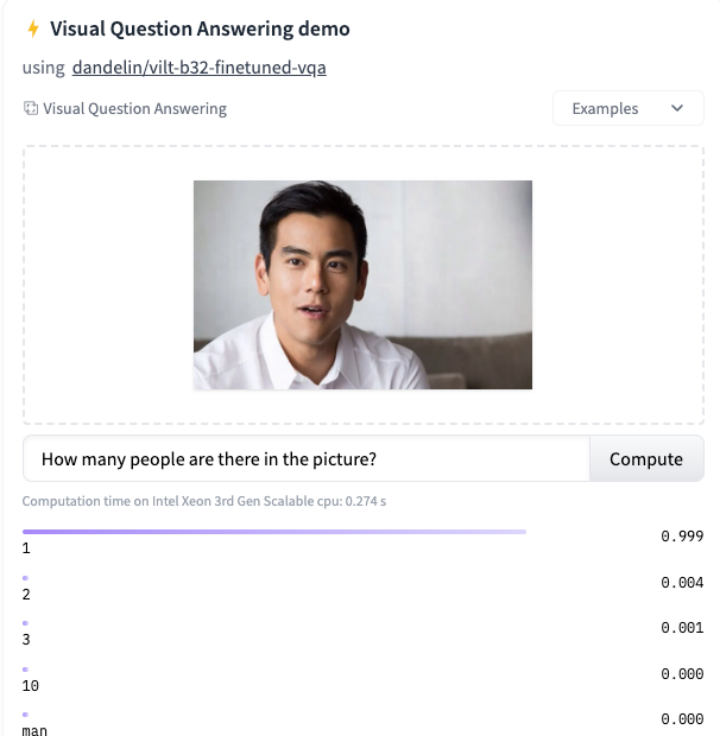
Four conclusions:
The VQA corpus is a picture, which is weakly related to our current actual question and answer tasks, but I personally feel that this area has good application prospects and is worth studying.