Table of contents
3.1 Running environment construction
3.3 Download pre-trained model
3.4.1 Creating vector tables and indexes
3.4.2 Build vector encoding model
3.4.3 Data vectorization and loading
1 Project background
Artificial intelligence question answering system is an advanced form of information retrieval system. It uses accurate and concise natural language to answer questions raised by users. It is a direction that has attracted much attention and has broad development prospects in the field of NLP. Artificial intelligence question and answer systems are often used in fields such as intelligent customer service, knowledge retrieval, and technical support. The technical points involved in the intelligent question and answer system are as follows:
- How to vectorize text data through a model
- How to store vectorized text
- How to quickly retrieve massive vector data
This project is based on Google's Transformer model combined with the Milvus vector database to implement an intelligent question and answer system on the "Encyclopedia Health" data set. Readers can extend the data set to other fields to build an intelligent question and answer system that meets their own business.
2 Key technologies
2.1 Transformer model
The Transformer model is a model for machine translation proposed by Google in 2017. It completely abandons the structure of the traditional recurrent neural network and adopts a structure completely based on the attention mechanism. It has achieved quite remarkable results, and has since made complete attention The model design model of mechanism has emerged from the field of NLP to the field of computer vision. For example, VIT is a visual model based on Transformer, ending CNN's dominance in the image field for many years.
Paper address: https://arxiv.org/pdf/1706.03762.pdf
Network structure:

- Encoder: Contains two layers, a self-attention layer and a feed-forward neural network. Self-attention can help the current node not only focus on the current word, but also obtain the semantics of the context.
- Decoder: Contains the two-layer network mentioned by encoder, but there is an attention layer between these two layers to help the current node obtain the key content that needs to be paid attention to.
Characteristics of the Transformer model
Self-attention, sometimes called internal attention, is an attention mechanism that connects different positions of a single sequence to compute a representation of the sequence. Self-attention has been successfully applied to a variety of tasks, including reading comprehension, abstract summarization, discourse entailment, and sentence representation independent of learning tasks.
End-to-end memory networks are based on a repetition attention mechanism rather than sequentially consistent repetition, and perform well in simple language question answering and language modeling tasks.
Transformer is the first transduction model to rely entirely on self-attention to compute its input and output representations, without using sequence-aligned RNNs or convolutions.
Transformer library
The Transformers library is an open source library, and all pre-trained models it provides are based on the transformer model structure. We can easily download and train state-of-the-art pre-trained models using the API provided by the Transformers library. Using pre-trained models reduces computational costs and saves the time of training a model from scratch. These models can be used for tasks in different modalities, such as:
- Text: text classification, information extraction, question answering systems, text summarization, machine translation and text generation.
- Image: Image classification, object detection and image segmentation.
- Audio: Speech recognition and audio classification.
- Multi-modal: form question answering system, OCR, scanned document information extraction, video classification and visual question answering.
Code address: https://github.com/huggingface/transformers
Official documentation: https://huggingface.co/docs/transformers/index
Pre-trained models: https://huggingface.co/models
2.2 Milvus vector database
Milvus is a cloud-native vector database that features high availability, high performance, and easy scalability, and is used for real-time recall of massive vector data.
Milvus is built based on vector search libraries such as FAISS, Annoy, and HNSW. Its core is to solve the problem of dense vector similarity retrieval. Based on the vector retrieval library, Milvus supports data partitioning, data persistence, incremental data ingestion, scalar-vector hybrid query, time travel and other functions. At the same time, it greatly optimizes the performance of vector retrieval and can meet any vector retrieval scenario. application requirements. Generally, users are recommended to deploy Milvus using Kubernetes for optimal availability and resiliency.
Milvus adopts a shared storage architecture with complete separation of storage and computing, and the computing nodes support horizontal expansion. From an architectural point of view, Milvus follows the separation of data flow and control flow, and is divided into four layers, namely access layer, coordinator service, worker node and storage layer. . Each level is independent of each other, capable of independent expansion and disaster recovery.

Milvus vector database can help users easily retrieve massive unstructured data (pictures/videos/voices/texts). A single node Milvus can complete billions of vector searches within seconds, and the distributed architecture can also meet users' horizontal expansion needs.
The features of milvus are summarized as follows:
- High performance: With superb performance, it can perform vector similarity retrieval on massive data sets.
- High availability and high reliability: Milvus supports expansion on the cloud, and its disaster recovery capabilities can ensure high availability of services.
- Hybrid query: Milvus supports scalar field filtering during vector similarity retrieval to implement hybrid query.
- Developer-friendly: Supports the multi-language, multi-tool Milvus ecosystem.
Detailed introduction to Milvus: Detailed explanation of Miluvs
3 System code implementation
3.1 Running environment construction
For details on conda environment preparation, see: annoconda
git clone https://gitcode.net/ai-medical/ai_robot.git
cd ai_robot
pip install -r requirements.txt3.2 Introduction to data sets
This project uses 30 medical and health data sets extracted from Baidu Encyclopedia for demonstration. The file name is baike_qa.csv, and the data content is as follows:
serial|question|answer
1|牙龈包住牙齿怎么办|病情分析:\n你好,牙龈出血以局部原因最为常见,但也有是其他疾病在牙龈组织上出现的一种症状.\n指导意见:\n局部原因为牙龈炎和牙周炎,主要是口腔卫生不佳,牙垢,牙结石,不良修复体,补牙材料,食物嵌塞等局部刺激因素引起牙龈充血肿胀,在刷牙,咬硬物,吃水果时发生牙龈出血,有时可有少许的自发性渗血.将刺激因素去除后,出血即会好转.牙龈外伤主要是指剔牙时造成的牙龈损伤,致使牙龈出血.这样情况应采取正确的剔牙方法,保护牙龈.全身因素有血液病如血友病,白血病,再生障碍性贫血等,有相当一部分患者是最初以牙龈出血而到口腔科就诊的.其他一些慢性疾病亦可导致牙龈出血,如糖尿病,维生素C缺乏及一些消耗性疾病.肝脏疾病可因影响凝血因素的合成,也会有牙龈出血.发现牙龈出血,不可过度紧张,应及时去医院检查,如为局部因素引起,经口腔科治疗即可.如出血量多不易止血时,应到内科诊治,要及时做血液系统检查。
2|你好我家宝宝7多月,这几天拉肚子,去医院检查说是细菌感染肠炎,吃什么药?|给宝宝吃点妈咪爱。
3|工作太累会造成便秘吗?整天干重体力劳动,大便老是不通,排不净|工作不会直接影响大便,但是由于工作是定时的,当在工作的时候往往会忽略便意,而便意是很短暂的,如果没有及时去解手,就不再有大便的感觉了。时间久了,肠子的运动功能会削弱。\r\n\r\n另外,身体虚弱的人,包括亚健康的人,内脏功能较差,肠蠕动也慢,常常伴有体虚型便秘,这时候如果用泻药犹如雪上加霜,从中医角度来说,正确的方法是以补促泻,也就是通过滋补让身体强壮,提高肠子运动力,达到治本的目的。\r\n\r\n干重体力活的人要注意饭后休息至少半小时,在这段时间培养便意,特别是早饭后不论有没有便意都要养成上厕所的习惯,坚持一段时间会让肠子产生反射,便秘问题就可以从根本上解决了。\r\n\r\n良好的排泄功能于健康很重要,所以,为了健康快快调整生活习惯吧,祝你健康。
4|怀孕什么时候能感觉到?初期症状都有什么?怀孕什么时候能感觉到?初期症状都有什么?|1、停经:月经过期10日以上怀疑妊娠.2、早孕反应:60%以上的妇女在妊娠6周以后会出现畏寒、头晕、乏力、流涎、嗜睡、食欲不振、喜食酸物或厌食油腻、恶心和晨起呕吐等现象,称早孕反应,持续2个月后自行消失\n 3、尿频。\n 4、乳房变化:查体时可见乳房逐渐变大,有胀痛感。\n 5、妊娠早期乳房增大明显,充血水肿,随着乳腺管的增生,皮下浅静脉清晰可见。6、受精卵着床部位变软,妊娠6-7周后双合诊检查子宫峡部极软,子宫体和宫颈似不相连,称黑加征,是早期妊娠的特征性变化。\n 7、B超早期检查最早以妊娠囊为判断妊娠标准。\n 8、超生多普勒检查\n 9、宫颈粘液检查未见羊齿植物叶状结晶,妊娠的可能性大。\n 10、妊娠试验:妊娠7-9日后可以查妇女血β-HCG判断妊娠。\n 11、基础体温BBT的测定:如果高温相持续18日不降,妊娠可能性大;如果持续3周不降,妊娠的可能性更大。
5|拉肚子以后,身体虚弱,应该吃些什么东西调养,有什么应该注意的?|一、饮食治疗目的\r预防并纠正水及电解质平衡失调;供给充足营养,改善营养状况。避免机械性及性刺激,使肠道得到适当休息,有利于病情早日恢复。\r\r二、饮食治疗原则\r(一)怠性腹泻饮食治疗\r1.急性期禁食:急性水泻期需暂时禁食,使肠道完全休息。必要时由静脉输液,以防失水过多而脱水。\r2.清淡流质饮食:不需禁食者,发病初宜给清淡流质饮食。如蛋白水、果汁、米汤、薄面汤等,以咸为主。早期禁牛奶、蔗糖等易产气的流质饮食。有些患者对牛奶不适应,服牛奶后常加重腹泻。\r3.根据病情调整饮食:排便次数减少,症状缓解后改为低脂流质饮食,或低脂少渣、细软易消化的半流质饮食,如大米粥、藕粉、烂面条、面片等。\r4.饮食选择:腹泻基本停止后,可供给低脂少渣半流质饮食或软食。少量多餐,以利于消化;如面条、粥、馒头、烂米饭、瘦肉泥等。仍应适当限制含粗纤维多的蔬菜水果等,以后逐渐过渡到普食。
6|生活饮食习惯对人体健康的影响饮食的健康会对人体产生怎样的影响?|现在的人工作压力都很大,不按时吃饭的大有人在,暴饮暴食的也很多。这就是为什么现在亚健康的人群巨大的原因。良好的饮食习惯对你以后上了岁数会有很大帮助,会长寿的。
7|维生素C什么时候吃好饭前还是饭后,有没有副作用|维生素C是水溶性维生素,什么时候服用都可以,一般在空腹时服用效果最好。 \r\n注意要点,水溶性维生素不能在体内保存,吃多了会排出。
8|乙肝患者的饮食的宜忌|不喝酒,少吃脂肪高的食物。
9|15个月的宝宝消化不好呕吐,拉肚子能吃点肠炎宁吗|病情分析: 考虑是消化不良,引起的肠胃炎,急性肠胃炎是胃肠粘膜的急性炎症,临床表现主要为恶心、呕吐、腹痛、腹泻、发热等。本病常见于夏秋季,其发生多由于饮食不当,暴饮暴食;或食入生冷腐馊、秽浊不洁的食品。中医根据病因和体质的差别,将胃肠炎分为湿热、寒湿和积滞等不同类型。\n意见建议:孩子发烧可用恬倩退烧,呕吐,拉肚子,可用思密达和肠炎宁一起服用,如效果不佳请及时就诊。
10|验血看结果两次都是血小板平均体积mpv小于正常值,请问有什么问题?|血小板平均体积mpv小于正常值,如果血小板计数不低,那没什么临床意义,因为现在都是仪器检测的,所测值只是供临床参考,还要结合其他情况一起分析,如其他一切正常的话根本不用管它。
11|椎管狭窄对身体有什么影响?|这要看个人的具体的情况\r\n有些人也没什么事,像 我,也是比正常的狭窄了一点,可以没有什么问题。当然,女性的话,对生殖是有点影响。
12|小孩子抽搐是什么情况引起的?|家族是否有癫痫病史,如果有,应该给孩子做个脑电图检验是否有放电异常的现象,如果有异常,就给孩子按照癫痫来治疗。如果没有放电异常,不要轻易给孩子下病因定论,使用抗癫药物,时间特长,对孩子影响很大。家长要慎重处理。
13|秋天爱出汗我一到秋天就特别爱出汗,坐在这里什么也不干也会无缘无故出汗|1.有的人特别爱出汗,无论是夏天还是冬天,吃顿饭、做点事情常常是满头大汗,稍一紧张就汗流浃背,这种人在医学上称为多汗症。多汗症可由发热性疾病、代谢性疾病,以及精神因素等引起。夏天气候炎热,人处于高温之下,多汗是一种正常现象,如果在气温低的情况下也是这样,就应注意一下了。 \r\r引起多汗症的疾病主要有以下几种: \r 一是低血糖症。引起低血糖症的原因很多,发作时以交感神经过度兴奋症状为主要表现,因血糖突然下降刺激交感神经兴奋,释放出大量肾上腺素可导致病人面色苍白、出冷汗、手足震颤等。 \r 二是甲状腺机能亢进,简称为甲亢。怕热多汗是这一疾病的特征之一,而且还表现为精神紧张、性格改变、烦躁不安、注意力不能集中、难以入睡等症状。另外,患了甲亢,食欲增大,吃得多,人反而消瘦。甲亢使胃肠功能增强,多数患者大便次数增多,同样有心慌、工作效率下降等症状。
14|如何恢复视力我的眼睛还算比较好,但是最近有所下降,有什么有效方法?|放心吧!暂时的近视是可以恢复的。\r\n\r\n关键是:1)保持良好的用眼习惯。每次看书40~50分钟,应该让眼睛尽量看看远处的绿色植物,以达到放松眼睛的目的。\r\n\r\n 2)看书的光线一定要够300勒克斯(两支40W的日光灯,一支处于桌子正前方上约1.5m,另一支位于侧面),并且是均匀的光线,禁止用台灯。\r\n 台灯是导致眼睛近视的根源----使眼睛处于“明”“暗”强烈对比的光线环境中,极易造成眼睛疲劳,引起近视)\r\n\r\n许多家庭的灯光都不适合看书学习,光线太暗-----导致近视。\r\n\r\n祝你顺利!"}
15|去医院检查腰疼,医生说骨头都没问题,有点肾气不足,肾气不足怎么办?|肾气不足我建议是吃黑豆。还有同时吃黑五类也是对肾气和肾阴虚都是很好的,黑五类有黑豆,黑芝麻,黑枣,黑米,核桃。都是非药用补肾的食物,慢慢的吃这些食物,肾精显头发,头发会变得越来越黑,手指甲上的白色月牙会越来越多,抵抗力会越来越强。
16|糖尿病高血压病人能否服用口腔溃疡意可贴?|糖尿病人应慎用激素类药物。\r\n虽然糖尿病由于疾病本身的原因,引起代谢紊乱,免疫力下降,消化功能紊乱及营养缺乏,容易发生口腔溃疡。但糖尿病人自身免疫力下降,容易诱发感染,而且有时感染是致命的。控制血糖和预防感染是糖尿病人尤为应重视的问题。\r\n意可贴的成分为醋酸地塞米松,可局部抑制口腔溃疡炎症,减轻疼痛。但其副作用是诱发口腔内细菌及念珠菌感染,和其他激素类的副作用。所以糖尿病人应慎用意可贴。可选用比较安全的不含激素的治疗口腔溃疡药物,如氨来?闩悼谇惶取?\n同理,由于激素的副作用可引起水钠储留和肾上腺的代谢,诱发血压增高,所以高血压病人也应慎用意可贴、氯已定地塞米松等激素类药物。
17|左肾多个结石,右肾囊,怎样治疗是最好的办法,病情严重吗?|你好,你的情况治疗上要分两方面,分别为多发结石和囊肿两部分, \r\n 1,针对多发结石,囊肿若在0.5厘米之内,常规服用排石汤即可;结石体积在0.5-0.8之间,建议在碎石后在给与溶石汤治疗;如若结石>0.8厘米建议手术处理. \r\n 具体治疗除了要依据结石的大小、数量、位置,还要依据结石梗阻是否引发了积水等 \r\n 2,囊肿的治疗,囊肿体积在4厘米之内,如无明显症状,可暂不处理;体积在4厘米可选择穿刺抽液或微创手术处理;若为多发就不适合外科治疗,因为大的囊肿去除后小囊肿会失去周围的压力而迅速长大,只可应用中药活性物质经皮肤渗透直接作用于肾脏,扩张肾脏血管,增加肾脏的血流灌注,改善肾脏的微循环,加速囊液的自行吸收。
18|为什么冬天人的脸上会出现脱皮的现象?|冬天的冷空气把皮肤的水分和油脂带走了,皮肤没有了保护膜就会缺水,处于不良状态,所以会有一切表皮细胞死亡。
19|右腿酸我今年26岁,最近一段时间总是感觉右腿有酸酸的感觉。我平时很少,出门总是开车。|哪个部位酸, 大腿、小腿、还是膝盖? 另外,已经持续多长时间了?
20|亚健康吃什么好呢如题,有什么好的保健品可以治疗啊。感觉许多保健品|我不知道什么保健品,但是我认为如果能有规律地吃健康食物,如五谷杂粮,水果,蔬菜,豆类,核桃,芝麻,等等。你的身体就会慢慢变好的。我认为什么药物都是有副作用的,食物是最好的药物。供你参考。祝你越来越健康。
21|低血糖该如何治疗?我经常会感到很困,尤其是夏天热的时候就会浑身软|低营养与饮食疗法\r低血糖是糖尿病的反面:身体分泌的胰岛素超过所需,造成胰岛素过度地把葡萄糖载离血液,无法留下足够的葡萄糖提供活力所需。低血糖不会致命,但会让你很难受。没有糖尿病的人可能受低血糖所苦,糖尿病患者如果注射胰岛素的时间和身体需求不一致,同样也会出现低血糖症状。\r 遗传可能是造成因素,然最常见的还是由饮食不当所造成的。这里指的即是机能性低血糖症(functional hypoglycemia,简称fh)。fh的症状直接与最后一餐所吃的种类及用餐时间有关。低血糖症可能出现下列任何一项或全部的症状:疲劳、头晕、头痛及不适(当错过一餐时)、忧郁、焦虑、渴望甜食、头脑错乱、盗汗、腿软无力、足部肿大、胸部紧闷、经常饥饿、身体各部疼痛(尤其是眼睛)、习惯性紧张、精神不定、失眠。
22|为什么肚子老是饭后就痛呢?我每次吃完一样东西后肚子就会痛,那是怎么回事?|胃不好,别跑什么的。
23|肋软骨炎的治疗?求求求有什么好的治疗肋软骨炎的方法没有的?|肋软骨炎是指发生在肋软骨部位的慢性非特异性炎症, 又称非化脓性肋软骨炎,肋软骨增生病。思华堂认为:营卫不和,气血虚弱,风寒湿邪乘虚入侵,阻塞筋络,以致胸胁气血运行不通,不通则痛。思华堂骨科舒肋消肿膏为传统黑膏药,使用时直接贴敷于患处体表,药效透皮吸收,祛风除湿,温经通络,使气血运行通畅,从而迅速消除肋软骨炎胸胁疼痛的症状。中医认为,肋软骨炎疼痛窜及胸胁, 上臂乃气滞; 局部隆起,压痛明显,痛点固定不移乃血瘀。气滞血瘀,风热入侵经络,毒热交炽,气血壅遏不通。 不通则痛。\r\n\r\n肋软骨炎的日常护理要点\r\n1、劳动时,注意提高防护意识,最好不要搬抬重物,做其他事时不要用力过猛,提防胸肋软骨、韧带的损伤。注意劳逸结合,不要过于疲惫。\r\n2、要经常开窗通气,保持室内空气新鲜,多参加体育活动,增强自身的抵抗力。\r\n3、平时注意保暖,防止受寒。\r\n4、经常感冒者,必要时可以注射流感疫苗。\r\n5、衣着要松软、干燥、避免潮湿。
24|肾结石是怎么回事啊?得了之后应该怎样治疗啊?我朋友说自己得了肾结。|你跟朋友说,结石是种常见病,不用太过紧张。\r\n至于原理和症状表现,楼上的贴的太全面,你慢慢看,但我想你不是医学专业,理解上有点困难。\r\n我简单的告诉你:如果你朋友的结石直径小于6cm,是可以用多喝水、多蹦跳的方法自己排出来的,如果稍大,就去医院开点排石的中成药服药,配合喝水及蹦跳。如果腰疼了就要吃消炎药了,而且结石痛用消炎药一般止不了,真到那一步,就必须在医院打止痛针了,然后体外碎石。结石多于夜间痛,让你朋友多吃西瓜等利尿水果。
25|眼睛流泪我有时候晚上睡觉时右眼老流泪怎么回事?|可能是眼睛太疲劳了,就像我有时上网时间太长也会出现这样的症状。如果没有用眼过度,可能是得了沙眼了,建议你去眼科检查一下。
26|心脑血管疾病主要包括哪些?|您好,希望我的回答对您有所帮助,心脑血管疾病是心脏血管和脑血管疾病的总称,也被成为富贵病,老年人是主要患者,很多人患有高血压的同时还患有高血糖或高血脂,心脑血管疾病的发病率很高,死亡率和复发率比比较频繁,所以患者要特别注意控制治疗。平时除了在饮食上需要多注意,多吃些鱼肉或者是富含叶酸的食物,比如菠菜、苹果、豆类、龙须菜、芦笋、洋葱、菠萝、山楂、海带、橄榄油之类的,除了食物预防治疗的同时也可以针对患者所需适当的服用一些常用改善心脑血管的保健品--绿色动力1型益康胶囊,达到有效的改善老年人的心脑血管系统功能,提高身体活力,延缓衰老。
27|如何锻炼心肺功能?我有哮喘史,不能做较激烈的运动。|上楼梯,跳绳,散步,深呼吸。
28|对糖尿病人有益的食品有哪些?|南瓜,南瓜中含有能促使胰岛素分泌作用的物质。其实,让糖尿病人每天煮吃新鲜南瓜400~500克,照样能取得满意的效果。\r 苦瓜,苦瓜是蔬菜中唯一以“苦”而独具特色的瓜果菜。苦瓜虽苦,但它味苦性凉、爽口不腻,人吃了以后会感到凉爽舒适。近年来科学家们发现,苦瓜中含有类似胰岛素的物质,有明显的降低血糖作用,是糖尿病患者理想的疗效食品。可用苦瓜250克,洗净切块,烧、炒后随饭吃,宜经常服用。\r 黄鳝 据临床观察,黄鳝对糖尿病有良好的治疗作用。糖尿病主要表现为血糖升高。而黄鳝体内含有两种物质,即黄鳝素A、B。这两种物质有显著的降血糖的作用,因而治疗糖尿病效果较好。糖尿病患者如常吃黄鳝,既能补充蛋白质,又有助于治疗,一举两得。
29|幼儿咳嗽引起呕吐怎么办?我的女儿28个月大。感冒咳嗽已有十天左右|建议到医院看看医生,原因之一可能是孩子痰液比较多,又不会吐,直接经食道吞咽到胃,刺激消化道引起的呕吐。其二,剧烈咳嗽刺激延髓中枢,引起呕吐。最好到医院看看是不是转为肺炎了,及时治疗,以免延误病情!
30|视神经炎如何治疗,方法有哪些?|病因分析:视神经炎或视神经乳头炎是指视神经任何部位发炎的总称,临床上根据发病的部位不同,视神经炎分为球内和球后两种,前者指视盘炎,后者系球后视神经炎。\r\n 就医指导:以清肝平火,清散风热,祛风止痒,滋阴祛火,养阴生津,消炎止痛,祛淤明目为原则,达到平稳眼压,平衡房水生成和排除,营养视神经、视乳头、视网膜,扩大视野的功效,坚持治疗,是可以有比较理想的效果的。 根据您的描述尚不能确诊分型为哪一种。视神经炎的症状有视力突然下降,进展有快有慢,眼球转动有痛感等。\r\n 指导意见:\r\n 建议进一步检查排除鞍区占位并确诊分型。目前治疗主要有激素,活血化淤药物,抗感染,及b族维生素的对症支持治疗。预后好坏需要看疾病类型。视神经炎可以选择中医的方法来进行治疗,中医对视神经炎的治疗效果还是不错的,也是目前临床上应用较为广泛的治疗方法。3.3 Download pre-trained model
Model download address: https://huggingface.co/bert-base-chinese/tree/main
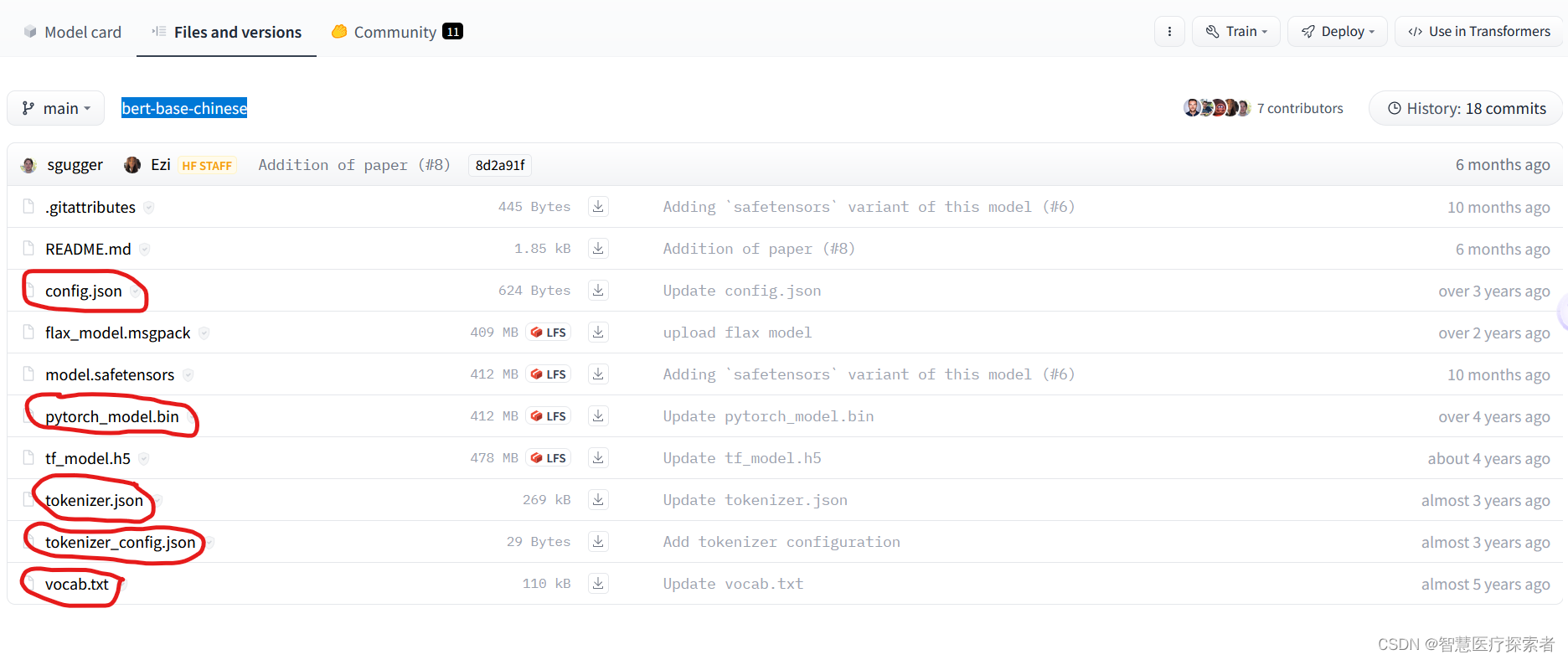
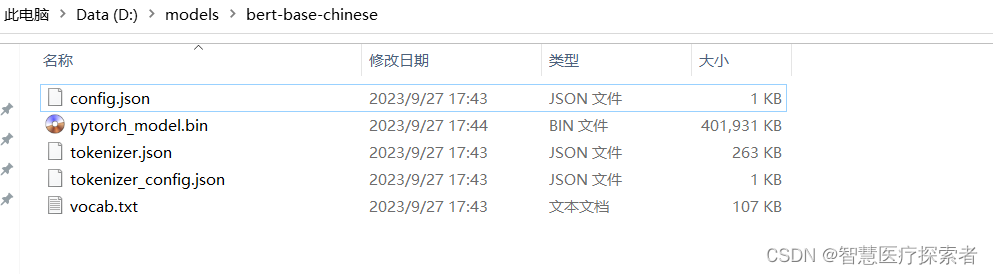
Download the 5 files marked in red and put them in the D:\models\bert-base-chinese directory. After the download is completed, it will look as follows
3.4 Code implementation
3.4.1 Creating vector tables and indexes
from pymilvus import connections, db
conn = connections.connect(host="192.168.1.156", port=19530)
database = db.create_database("ai_robot_db")
db.using_database("ai_robot_db")
print(db.list_database())Create a collection
from pymilvus import CollectionSchema, FieldSchema, DataType
from pymilvus import Collection, db, connections
conn = connections.connect(host="192.168.1.156", port=19530)
db.using_database("ai_robot_db")
m_id = FieldSchema(name="m_id", dtype=DataType.INT64, is_primary=True,)
embeding = FieldSchema(name="embeding", dtype=DataType.FLOAT_VECTOR, dim=768,)
question = FieldSchema(name="question", dtype=DataType.VARCHAR, max_length=512,)
answer = FieldSchema(name="answer", dtype=DataType.VARCHAR, max_length=2048,)
schema = CollectionSchema(
fields=[m_id, embeding, question, answer],
description="intelligence answer table",
enable_dynamic_field=True
)
collection_name = "question_answer_vector"
collection = Collection(name=collection_name, schema=schema, using='default', shards_num=2)Create index
from pymilvus import Collection, utility, connections, db
conn = connections.connect(host="192.168.1.156", port=19530)
db.using_database("ai_robot_db")
index_params = {
"metric_type": "IP",
"index_type": "IVF_FLAT",
"params": {"nlist": 1024}
}
collection = Collection("question_answer_vector")
collection.create_index(
field_name="embeding",
index_params=index_params
)
utility.index_building_progress("question_answer_vector")3.4.2 Build vector encoding model
Load the pre-trained model, encode the text through the transformer model, and the output feature dimension after encoding is 768
import torch
from transformers import BertTokenizer, BertModel
class TranseformerEmbeding:
device = "cuda" if torch.cuda.is_available() else "cpu"
model_path = r"D:/models/bert-base-chinese"
def __init__(self):
self.model = BertModel.from_pretrained(self.model_path)
self.tokenizer = BertTokenizer.from_pretrained(self.model_path)
def embeding(self, text: str):
inputs = self.tokenizer(text, return_tensors='pt', padding=True)
outpus = self.model(input_ids=inputs['input_ids'], attention_mask=inputs['attention_mask'], return_dict=True)
# shape is [batch_size, seq_len, hidden_size]
text_embeddings = outpus.last_hidden_state[:, 0, :]
return text_embeddings[0]
transeformer_embeding = TranseformerEmbeding()
if __name__ == "__main__":
result = transeformer_embeding.embeding("今天心情不错")
print(result)3.4.3 Data vectorization and loading
from transefromer_embeding import transeformer_embeding
from milvus_operator import text_vector, MilvusOperator
import pandas as pd
def update_text_vector(data_path, operator: MilvusOperator):
idxs, embedings, questions, answers = [], [], [], []
df = pd.read_csv(data_path, delimiter='|')
for idx in range(len(df['serial'])):
idxs.append(int(df['serial'][idx]))
text_encode = transeformer_embeding.embeding(df['question'][idx])
embedings.append(text_encode.detach().numpy().tolist())
questions.append(df['question'][idx])
answers.append(df['answer'][idx])
data = [idxs, embedings, questions, answers]
operator.insert_data(data)
print(f'finish update {operator.coll_name} items:{len(idxs)}')
if __name__ == '__main__':
data_dir = '../data/baike_qa.csv'
update_text_vector(data_dir, text_vector)
3.4.4 Build search web
import gradio as gr
import torch
import argparse
from net_helper import net_helper
from transefromer_embeding import transeformer_embeding
from milvus_operator import text_vector
def text_search(text):
if text is None:
return None
# clip编码
imput_embeding = transeformer_embeding.embeding(text)
imput_embeding = imput_embeding.detach().cpu().numpy()
results = text_vector.search_data(imput_embeding)
answers = []
for result in results:
answers.append(result['question']+'\r\n\r\n'+result['answer'])
return answers
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument("--share", action="store_true",
default=False, help="share gradio app")
args = parser.parse_args()
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
css = "h1 { text-align: center } .about { text-align: justify; padding-left: 10%; padding-right: 10%; }" \
".gradio-container {background-color: #445566}"
app = gr.Blocks(theme='Monochrome', title="patent", css=css)
with app:
with gr.Tabs():
with gr.TabItem("人工智能问答系统"):
with gr.Row():
with gr.Column():
text = gr.TextArea(label="Text", placeholder="description", value="",)
btn = gr.Button(label="search")
with gr.Column():
with gr.Row():
output_texts = [gr.outputs.Textbox() for _ in range(3)]
btn.click(text_search, inputs=text, outputs=output_texts, show_progress=True)
ip_addr = net_helper.get_host_ip()
app.queue(concurrency_count=3).launch(show_api=False, share=True, server_name=ip_addr, server_port=9099)
3.5 Operation results
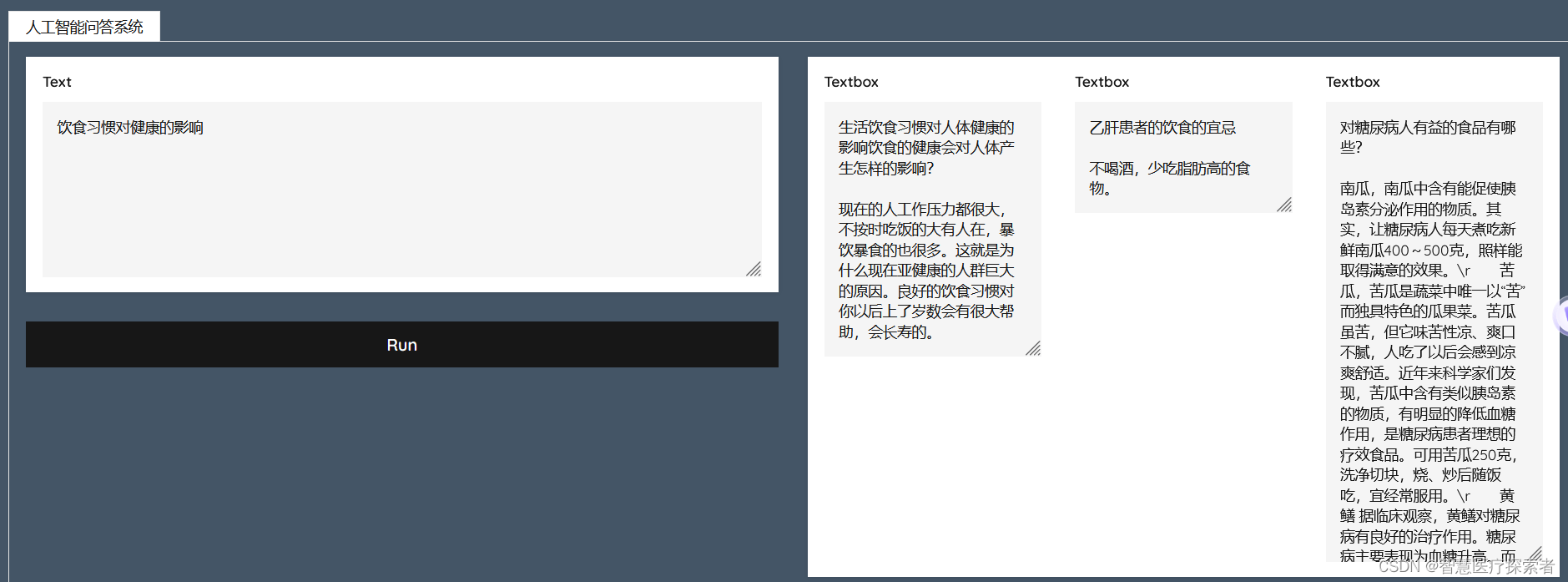
3.6 Complete code
Code address: https://gitcode.net/ai-medical/ai_robot
4 Summary
This project builds an artificial intelligence question and answer system based on two key technologies of Google's Transformer model and milvus vector database. After encoding by the Transformer model, the output vector dimension of each question is 768, which is stored in the milvus vector database. In order to ensure the efficiency of vector retrieval, Vector indexes were built in the milvus vector database through scripts.