1.introduction
Based on GAN and diffusion models, it adjusts the generation process by incorporating multi-modal guidance to synthesize images from different multi-modal signals; it uses pre-trained models for multi-modal image synthesis and editing, and performs inversion in the GAN latent space. perform, apply a bootstrap function, or adjust the latent space and embedding of the diffusion model.

2.modality foundations
Every source or form of information can become a modal.
2.1 Visual guidance
Visual guidance encodes specific image properties in pixel space, providing control. Vision-guided encoding is represented as a specific type of image in 2d pixel space, so it can be directly encoded by a variety of image encoding strategies. Since the encoded features are spatially aligned with the image features, splicing, spade, cross-attention, etc. can be used. In this way, the image in webui generates an image, and init_latent is generated through autoencoderKL. The text usually passes through the cross-attention fusion model, but the input image does not.
2.2 Text guidance
clip produces informative text embeddings trained on a large number of image-text pairs and is widely used for text encoding.
2.3 Audio guidance
Unlike text and visual guidance, audio guidance provides temporal information that can be used to generate dynamic or continuous visual content. Input audio clips can be represented by a series of features, which can be spectrograms, fBanks, Mel frequency cepstrum coefficients (MFCC), and hidden layer outputs of pretrained SoundNet models.
2.4 Others modality guidance
3.Methods
Multimodal image synthesis and editing are roughly divided into 5 categories, 1. GAN-based methods, 2. Autoregressive, 3. Diffusion models, 4. Nerf, 5. Others.

3.1 GAN-based Methods
3.1.1 Conditional GANs
CGAN conditions the generation process with additional information. This is achieved by inputting additional information into the generator and discriminator networks as additional guidance, and the generator learns to generate samples that can both fool the discriminator and match the specified conditional information.
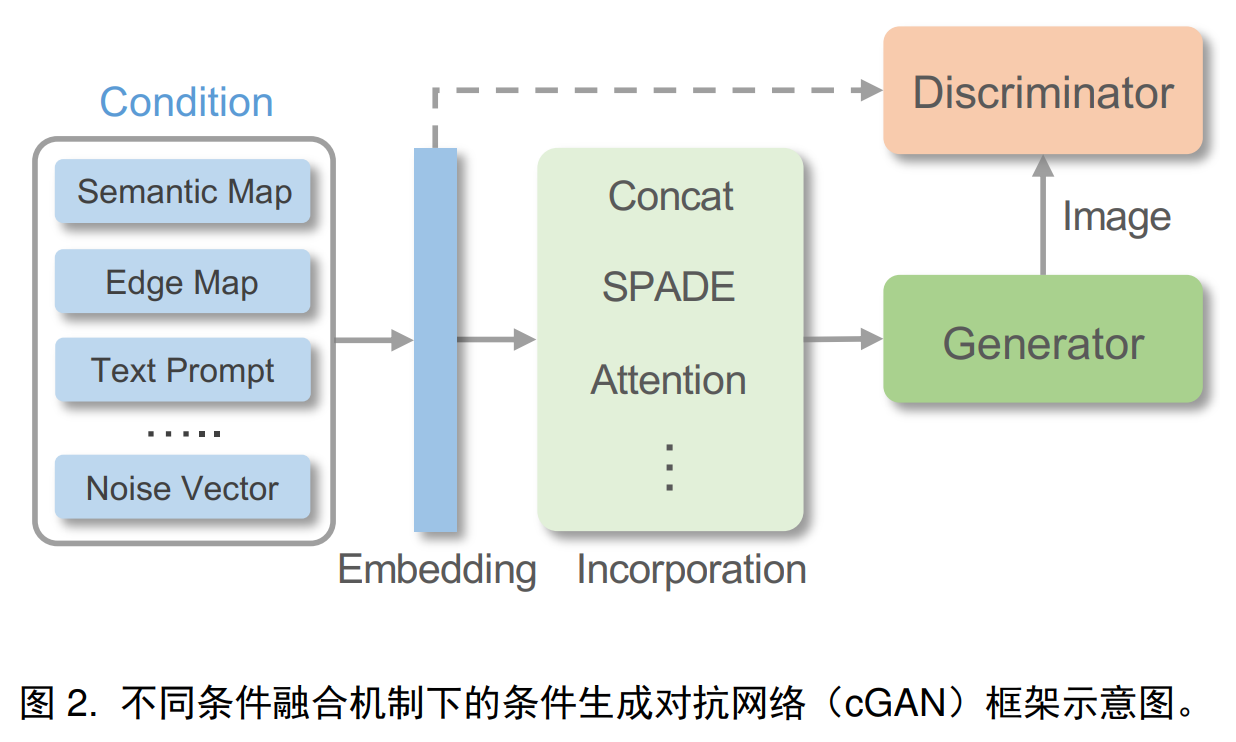
Conditional fusion: For visual guidance on spatial alignment of target images, conditions can be directly encoded into 2D features that provide accurate spatial guidance for generation or editing. When different viewing angles or severe deformations exist, it is difficult for the encoded 2D features to capture the guidance and For complex scene structural relationships between real images, attention modules can be used to align guidance with target images. Simply using deep networks to encode visual guidance is suboptimal because part of the guidance information will be lost in the normalization layer. SPADE, spatially-adaptive de-normalization can be used to effectively inject guidance features. Complex conditions can also be mapped to intermediate representations for more accurate image generation, and audio clips can be mapped to facial feature points or 3DMM parameters for speaking face generation.
Model structure:
Loss function: gan loss, perceptual loss, cycle loss, contrast loss
3.1.2 Inversion of Unconditional GAN
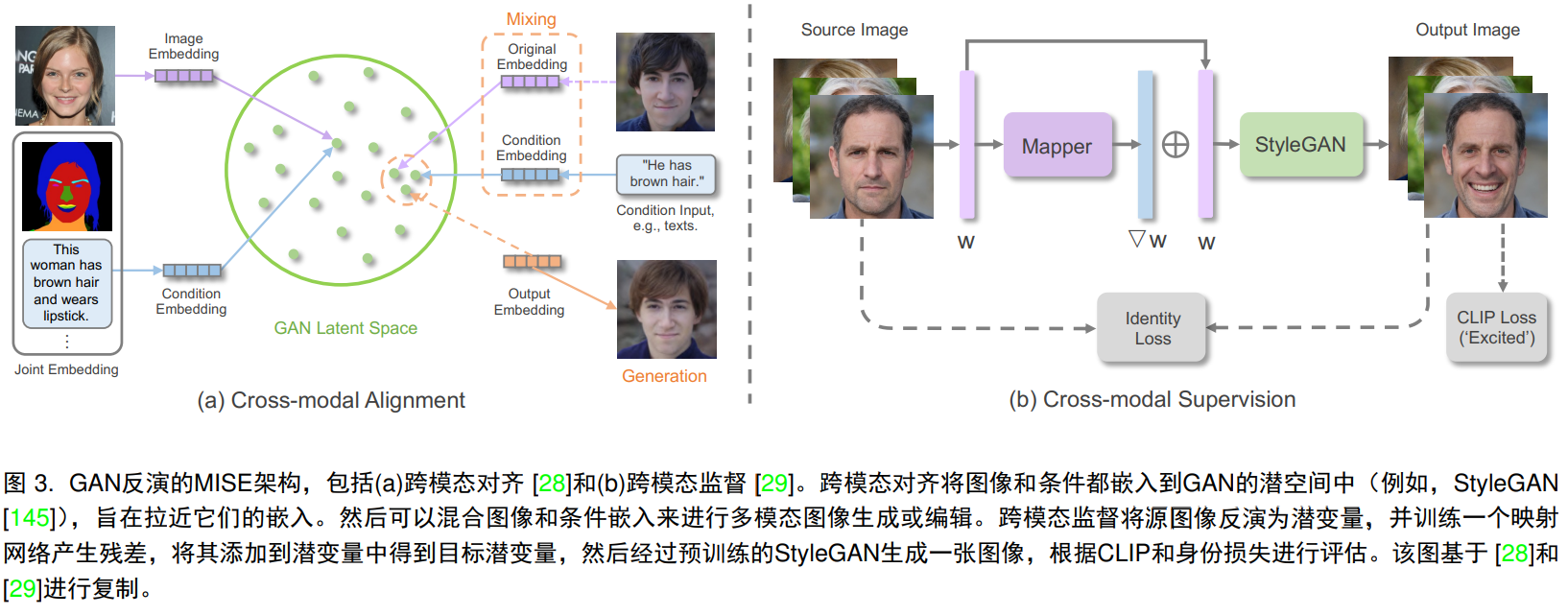
Through the pre-trained GAN model, the given image is reversely mapped into the latent space of the GAN, which is called GAN inverse. Specifically, the pre-trained GAN learns the mapping from latent codes to real images, while the GAN inverse maps the image back to the latent code. This is achieved by feeding the latent code into the pre-trained GAN and reconstructing the image through optimization. The reconstruction metric is based on l1, l2, perceptual loss or lpips, can include specific constraints on facial identity or latent code during the optimization process. By obtaining the latent code, the original image can be reconstructed and realistic image operations can be performed in the latent space.
Explicit cross-modal alignment:
Implicit cross-modal supervision: In addition to explicitly projecting the guided modality into the latent space, another is to guide synthesis or editing by defining a consistency loss between the generated results and the guided modality. styleclip uses cosine similarity between clip representations to supervise text-guided operations.
3.2 Diffusion-based methods
3.2.1 Conditional Diffusion models
Conditional information can be directly integrated into the denoising process to specify a conditional diffusion model.

Conditional fusion: Use specific conditional encoders to project multi-modal conditions into embedding vectors, which are further incorporated into the model. Specific conditional encoders can be learned along with the model, or they can be borrowed directly from a pre-trained model, such as Clip, where in LDM the conditional embeddings are mapped to intermediate layers of the diffusion model via cross-attention.
Diffusion of latent spaces: Learning latent spaces with autoencoders that are perceptually equivalent to image spaces, VQ-VAE, dalle2:clip latent spaces.
3.2.2 Pre-trained diffusion models
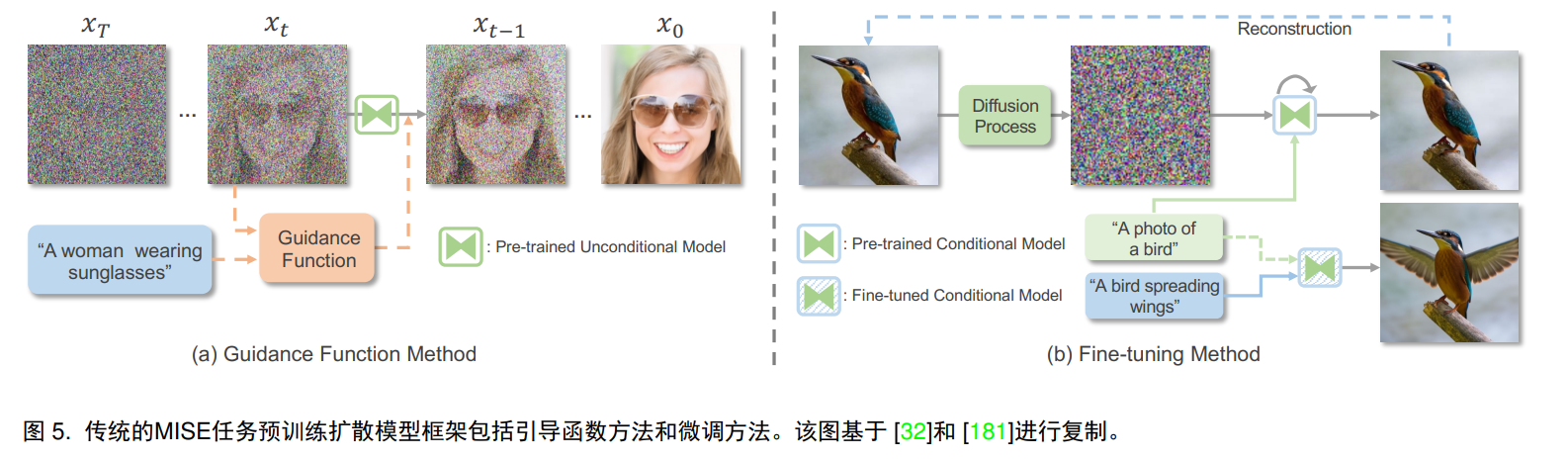
As opposed to retraining the diffusion model, another path is to guide the denoising process through appropriate simplicity, or fine-tuning.
Guided function method: The guided function calculates the consistency between xt and y, which can be measured by some kind of similarity index cosine similarity or l2 distance. You can use clip as an image encoder and a text-oriented conditional encoder.
Fine-tuning: This can be achieved by modifying the latent encoding or adjusting the pre-trained diffusion model. In order to adapt to the text guidance, the input image is first transformed into the latent space through forward diffusion, and then the diffusion model is fine-tuned through the reverse direction to generate a model driven by the target text and clip loss. For an image, for a pre-trained conditional model (usually text), similar to GAN inversion, the text latent embedding or diffusion model can be fine-tuned to reconstruct the image. An alternative approach is to utilize stepwise diffusion sampling to provide content- and structure-preserving fractional guidance at an early stage of the denoising process.
3.3 Autoregressive methods

By treating the flattened image sequence as discrete markers, an autoregressive model can be used, including first: a vector quantization stage to produce a unified discrete representation and achieve data compression, second: an autoregressive modeling stage, which uses raster The order of lattice scans establishes dependencies between discrete tags.
3.3.1 Vector quantization
Treating all image pixels directly as a sequence for autoregression is too expensive, so the compressed discretization of the image is important. VQVAE consists of an encoder, a feature quantizer and a decoder. The image is input to the encoder to learn the continuous representation, and then through the features The quantizer quantizes it into features closest to the codebook entry, and the decoder reconstructs the original image from the quantized features.
Loss function: gan loss, perceptual loss,
codebook: Ordinary VQVAE uses argmin (to obtain the nearest codebook entry), which will lead to serious codebook collapse problems. Only a few codebook entries are effectively utilized for quantification. Gumbel-softmax is introduced to replace argmin. Gumbel-softmax allows pass-through The gradient estimator samples discrete representations in a differentiable manner, increasing codebook utilization.
3.3.2 Autoregressive modeling
Autoregression is used to adapt to sequence dependence and conforms to the chain rule of probability. The probability of each marker in the sequence is conditional on all previous predictions. The resulting joint distribution of the sequence is the product of conditional probabilities. In reasoning During the process, each marker performs autoregressive prediction in sequence. A sliding window strategy can be used to exploit the prediction results in a local window. In the multi-modal image generation task, the autoregressive model generates images pixel by pixel based on a conditional probability distribution that takes into account previously generated pixels and given conditional information, thereby enabling the model to capture complex dependencies and generate Visually coherent images.
Network structure: PixelCNN, Parti
Bidirectional context: Only focusing on previously generated results, this one-way strategy will be affected by order bias, ignoring a large amount of contextual information before the autoregression is close to completion, and ignoring a large amount of contextual information at different scales, ImageBart. There are also bidirectional transformers, accompanied by occlusion visual markup modeling MVTM or occlusion language modeling MLM mechanisms.
Self-attention mechanism: NUMA
3.4 NeRF-based methods
Neural Radiation Field By parameterizing the color and density of a three-dimensional scene with a neural field, a fully connected neural network is used in NeRF, taking as input the spatial position (x, y, z) and the corresponding viewing direction (θ, φ), and The corresponding volume density and emitted radiance are given as outputs. To render a 2D image from an implicit 3D representation, differentiable volume rendering is performed via a numerical integrator to approximate the difficult-to-compute volume projection integral.
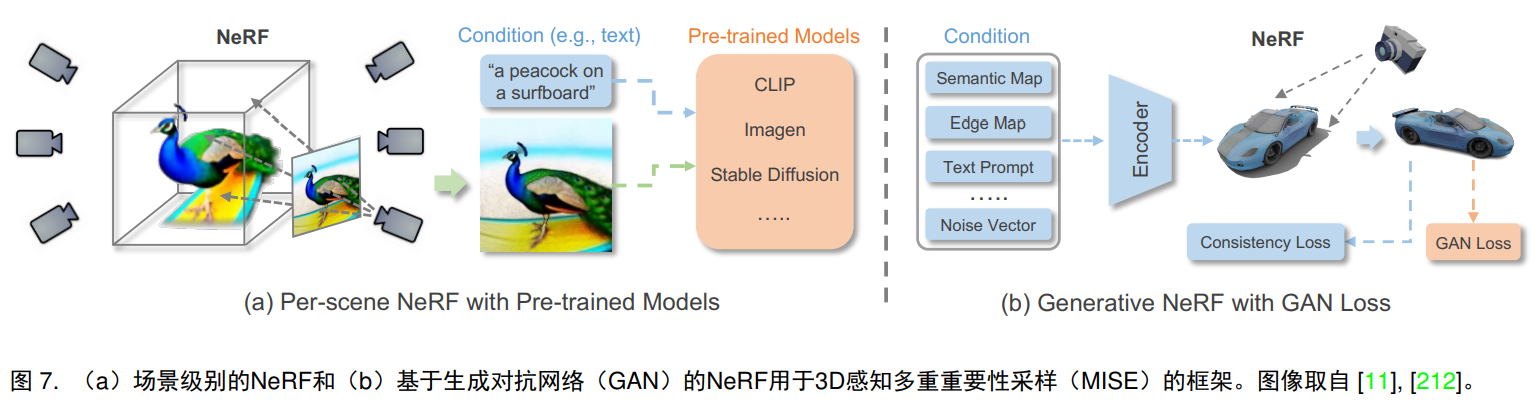
3.4.1 Per-scene NeRF
Consistent with the original NeRF model, per-scene NeRF is designed to optimize and represent individual scenes through images or specific pre-trained models.
Image supervision: NeRF can be trained conditionally by paired guidance information and corresponding view images. AD-NeRF.
Pre-trained model supervision: AvatarCIP, DreamFusion, Magic3D, Ref-NeRF
3.4.2 Generative NeRF
Unlike NeRF, which is optimized on a scene-by-scenario basis, generative NeRF can be generalized to different scenarios by integrating NeRF with the generative model.
3.5 Other methods
3.6 Comparsion and discussion
GAN achieves high-fidelity image generation on FID and Inception scores, and has fast inference speed. However, GAN training is unstable and prone to mode collapse problems. Compared with likelihood-based diffusion models and autoregressive models, GAN pays more attention to fidelity. degree rather than capturing the diversity of the training data distribution. In addition, GANs usually adopt convolutional networks, which are difficult to generalize to multi-modal,transformers. Autoregressive models can handle different multi-modal synthesis tasks in a general way. However, since auto-regressive models need to predict labels, inference Slower speed, diffusion is also slow inference speed. The autoregressive model and the diffusion model are generative models based on likelihood, with stable training objectives and good training stability. Dalle2 indicates that diffusion is slightly better than the autoregressive model.
Different from the above generation methods that mainly target 2D images and require less training data, NeRF-based methods process 3D scenes and have higher requirements for training data. NeRF based on scene optimization requires standard multi-view images or videos. sequence.
4.Experimental evaluation
4.1 Datasets
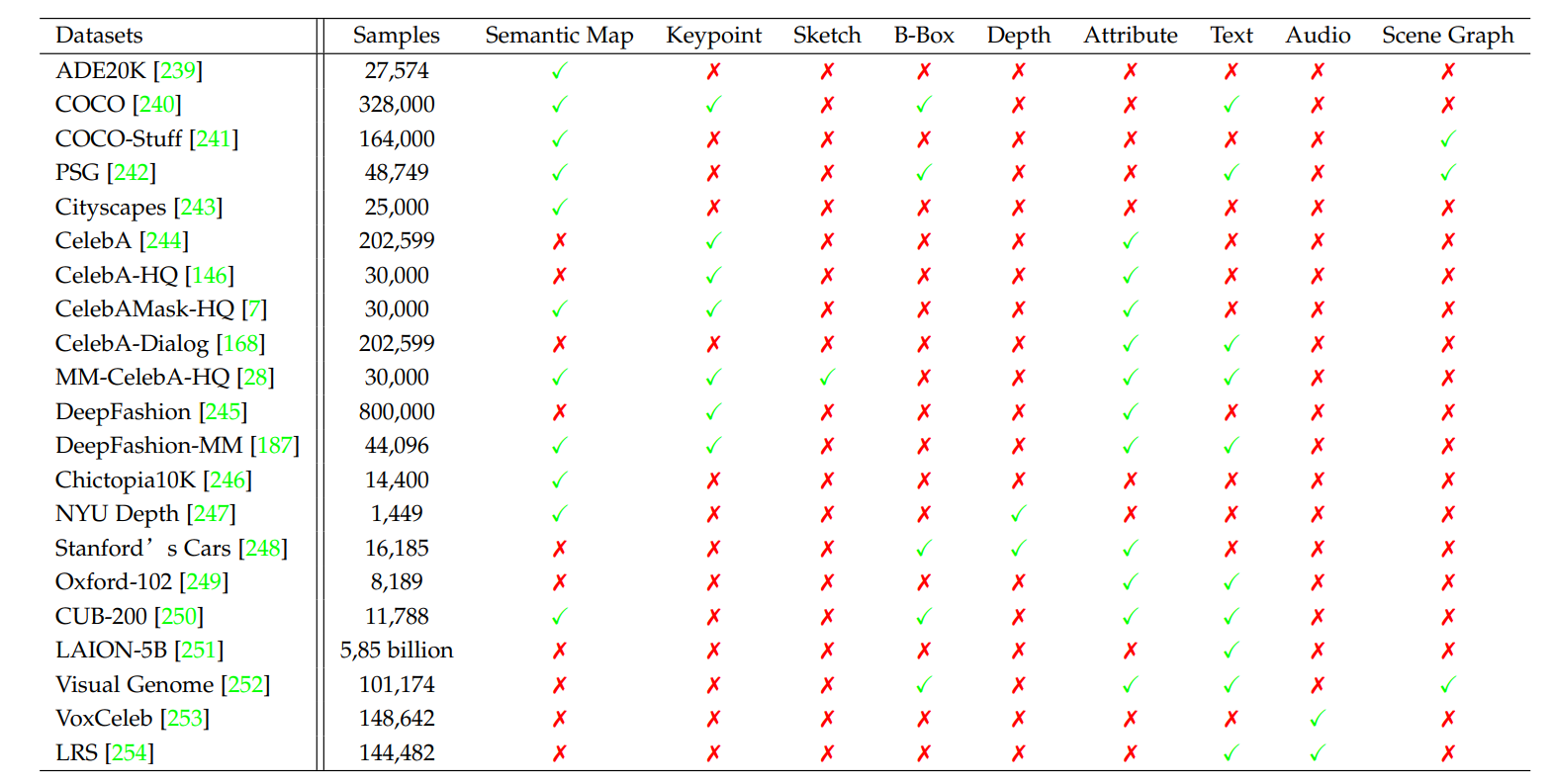
4.2 Evaluation Metrics
Inception Score and FID evaluate image quality, and LPIPS evaluates image diversity.
4.3 Experimental Results
