
Based on the learning method, machine learning can be roughly divided into supervised learning and unsupervised learning. In unsupervised learning, we need to use some kind of algorithm to train the unlabeled data set, so as to help the model find the underlying structure of this set of data.
In order to do unsupervised learning, in the early days of OpenAI, they thought that compression could lead to this path. They then discovered that "predicting the next token" is exactly what unsupervised learning can pursue, and realized that prediction is compression. This is also one of the key ideas behind the success of ChatGPT.
They achieve data compression by continuously training an autoregressive generative model, which, if the data is compressed well enough, can extract all the hidden information present in it. In this way, the GPT model can accurately predict the next word, and the accuracy of text generation will be higher.
Recently, OpenAI co-founder and chief scientist Ilya Sutskever proposed in a speech at UC Berkeley that he hopes to explain unsupervised learning problems through a compressed perspective. However, it is worth mentioning that he pointed out that the GPT model can also be understood without the concept of compression.
(The following content is compiled and released by OneFlow, please contact for authorization for reprinting. https://simons.berkeley.edu/talks/ilya-sutskever-openai-2023-08-14)
Source | Simons Institute
OneFlow compilation
Translation|Wan Zilin, Yang Ting
A while ago, I shifted my research focus to the field of AI alignment , and there are some really good results, but it will take time. This time, I want to share some ideas I got at OpenAI since 2016, which deeply influenced the way I think about unsupervised learning. Some of these ideas may seem very simple, but not all of them are easy to solve, and some of them may interest you.
1
Unsupervised Learning Theory
Before discussing unsupervised learning, we need to clarify the general concept of learning. What is study? Why is learning useful? Why can computers learn? While we take for granted that neural networks learn, how do they learn, mathematically? Why can machine learning models capture data patterns? This is not a simple question.
In the field of machine learning, an important conceptual breakthrough was made many years ago, namely the discovery and formalization of supervised learning, which was done by multiple researchers.
supervised learning
Supervised learning, also known as reverse learning or statistical learning theory, has the advantage of providing explicit mathematical conditions for successful learning. When you take part of the data distribution and successfully achieve low training loss, and the model degrees of freedom parameter is smaller than the size of the training set, then you can achieve low test error on the test set.
Therefore, if you find a function in the function class that achieves a low training error, learning will be successful. This is why supervised learning is relatively easy compared to other methods.
Most of the theorems involved in supervised learning are very simple. Some of the simple mathematical reasoning involved can explain the theory of supervised learning with only three lines of theorems. Relatively speaking, it is very easy to understand.

So we know why it works, and as long as we continue to collect large supervised learning datasets, we can be sure that the performance of the model will continue to improve . At the same time, it is crucial that the test distribution and the training distribution must be consistent , only in this case, the theory of supervised learning can be useful.

We understand why supervised learning works, and why speech recognition, image classification, etc. can be achieved, they can all be attributed to supervised learning, and supervised learning has this mathematical guarantee, which is very good. For those who care about the VC dimension, much of the literature on statistical learning theory emphasizes the VC dimension as a key component, but in reality, the VC dimension is only there to allow the model to handle parameters with infinite precision.
If you have a linear classifier where every parameter has infinite precision, but in reality, all floating point numbers have finite precision, which keeps getting less accurate, and the number of functions a computer can actually perform is small, You can formulate this in the formula mentioned before, and you get almost all the optimal bounds that supervised learning can achieve. I think this is nice because the proof step only takes a few lines.

unsupervised learning
Next, let’s talk about unsupervised learning. Supervised learning is like you have some data, and then predict the label of unknown data based on these input data and labels. If the training error on these data is low, your training data size will exceed the degrees of freedom or parameters in the function class.
In my opinion, there is no satisfactory unsupervised learning discussion. We may be able to judge through intuition, but can it be proved through mathematical reasoning? The unsupervised learning goal has been achieved in the experiment. For example, the model can discover the real hidden structure existing in the data when there are only images or texts and no specific processing methods.
How did this happen? Can we predict this? Currently we don’t have anything similar to supervised learning guarantees, supervised learning can reduce training error and guarantee good learning results, but unsupervised learning does not.
As early as the 1980s, people started research on unsupervised learning, such as the early Bolson machine and so on. However, these early ideas did not work well on small-scale data. While language models such as BERT and Diffusion have made some minor improvements and were cool examples at the time, their unsupervised learning performance is still far behind current models.

Confusingly, how exactly does unsupervised learning work during optimization? We can optimize some kind of reconstruction error, denoising error, or self-supervised learning error. What is going on when one objective is optimized but another objective is focused on and the model performs well on the unoptimized objective? It's almost like magic.

Always follow positivism?
Unsupervised learning helps you achieve your goals by learning structure in the input distribution, but all unsupervised learning algorithms fail if you train through a uniform distribution. So I wanted to propose a potential way of thinking about unsupervised learning, which I found very interesting.
Unsupervised Learning via Distribution Matching
This is a non-mainstream unsupervised learning method that is not widely used, and it has a cool property: it guarantees successful learning just like supervised learning. So even if you don't label any of the input data, this mysterious unsupervised learning process still works, which is distribution matching.
What is distribution matching? Assume that there are two uncorresponding data sources in the data, namely X and Y, such as two different languages (language 1 and language 2), which can be text and voice. Now the goal is to find a function f such that the distribution generated by f(X) is similar to the distribution of Y, where some constraints need to be imposed on the function f. This constraint may make sense. This is useful in areas such as machine translation and speech recognition.
For example, I have a distribution of English sentences as input, and by applying the function f, I get a distribution very similar to that of French sentences. Then, it can be said that the true constraints of the function f are found. If the dimensions of X and Y are high enough, then f There may be a large number of constraints. In fact, the information of the function f can be almost completely restored through these information. As with supervised learning, this is also guaranteed to work. Furthermore, this framework is also suitable for tasks such as simple substitution ciphers and encryption.

In 2015, I independently discovered this method and became very interested in it. I think it is possible to describe unsupervised learning through mathematics. However, the above translation scenario settings also have some human factors, which do not fully conform to the real machine learning environment and unsupervised learning scenarios.
From a mathematical point of view, I next show the concrete core content of the method and explain how to ensure the effectiveness of unsupervised learning.
Solved by compressing
As we all know, we can think of compression as a prediction process, and each compressor can be transformed into a predictor, and vice versa. There is a one-to-one correspondence between all compressors and predictors. To illustrate thinking about unsupervised learning, I think it is advantageous to use compression for the discussion.
Let's do the following thought experiment: Suppose you have two datasets, X and Y, corresponding to two files on your hard drive, and suppose you have a very good compression algorithm, C, to compress the data. So what happens if you compress X and Y jointly, concatenate them, and feed them into the compressor?

What would a good enough compressor do in this situation? My hunch is that it will take advantage of the patterns that exist inside X to help it compress Y, and vice versa. Similar results may exist for prediction tasks, but this description is more intuitive when discussed in terms of compression. In other words, if your compressor is good enough, it should be able to make sure that concatenating and compressing large files is no worse than compressing them individually.

So the extra compression gained by concatenating the two datasets is a shared structure that the compressor notices and can handle, the better the compressor the more dynamic structure it will extract. The gap between the two compression results is called the shared structure, or algorithmic mutual information. Just like X represents an unsupervised task and Y represents a supervised task, with some kind of mathematical reasoning, patterns in X can be exploited to help process Y.

Note also how this approach generalizes to distribution matching. Suppose we are in the distribution matching situation, where X represents language 1 and Y represents language 2, there exists some simple function f that transforms one distribution into another, and if your compressor is good enough, it will definitely Notice this, take advantage of it, and even try to restore the function internally. It would be really cool if we could close the loop on this process.
Can unsupervised learning be formalized?
So how do we formalize unsupervised learning? In what follows, I'll use compression and prediction scenarios interchangeably to describe them. Suppose you have a machine learning algorithm A which is trying to compress Y, if algorithm A has access to X, where X file number is 1, and Y file number is 2, you want the machine learning algorithm (i.e. the compressor) to be able to compress Y, And this can be achieved by using X. So what are the regrets of using this particular algorithm?
If the task is done well enough, the regret level is low, which means I have gotten all the help possible from the unlabeled data, I have no regrets about it, there is no other predictive value in the data that a better algorithm can use , I've gotten the most out of the unlabeled data, I've done it to the extreme.

In my opinion, this is an important step in thinking about unsupervised learning. You don't know if your unsupervised dataset is really useful, it could be very useful and contain the answer, it could be useless, it could be a uniformly distributed dataset. However, if you have less regrets with supervised learning algorithms, you can tell whether your unsupervised dataset is the first or the second case. I'm sure I've done my best to get the most out of unlabeled data and no one can do it better than me.
2
Kolmogorov complexity as the ultimate compressor
Next, let's talk about Kolmogorov complexity (Kolmogorov complexity), which is called the ultimate compressor and can provide the ultimate ultra-low regret algorithm. Actually, Kolmogorov complexity is not a computable algorithm. Many people may not understand it, but it is actually very simple.

Suppose you give me some data, I will provide the shortest program possible to compress it, and if you run this shortest program, it will output the data. The shortest program length of this output Y is equal to the Kolmogorov complexity K(X). Intuitively, it can be seen that this compressor is very effective, because the theorem is easy to prove. If the string is compressed with the Kolmogorov compressor, there will be little regret in the quality of the compression. If you want to compress a string X, then the length of the shortest program that outputs X is shorter than the output length required by the compressor, and no matter how much the compressor compresses the data, it will result in a small term that implements The number of code characters required by the compressor.

Intuitively, the simulation argument makes sense. Suppose there is an awesome compressor C, does this compressor come with a computer program? Can this computer program be given to K to run? While not explaining the details, Kolmogorov complexity simulates how a computer program simulates the operation of a compression algorithm, which is why it's not computable, because what it does is a simulation, free to simulate all possible computer programs, but it might It is the best compressor algorithm in existence.
"Compute" K(X)
Now let's generalize the Kolmogorov complexity to call other information. It's important to reiterate that the Kolmogorov compressor is non-computable and non-decidable, but it searches all programs. Just like you do stochastic gradient descent (SGD) on some 100-layer neural network parameters, it is automatically like doing a program search on a computer with a certain memory size and number of steps, which is somewhat similar to In terms of the tiny Kolmogorov compressor, there are very subtle similarities between the two.

Neural networks can simulate small programs, which are like small computers, made of circuits, the basic building blocks of a computer, which is essentially a machine. Stochastic gradient descent (SGD) searches procedurally, the whole deep learning revolves around SGD, and we can actually use SGD to train these computers to find circuits from data. We can therefore calculate our tiny Kolmogorov compressor, and the simulation argument applies here as well.
Conditional Kolmogorov complexity as a solution
By the way, have you tried to design a better neural network architecture, you will find that it is a bit difficult, which is equivalent to searching for a better program in the program space.
Why is it so difficult? Because your new architecture can perform relatively simple simulations of the old architecture, except in some rare cases, which can produce significant improvements, such as going from RNN to Transformer. RNN has a bottleneck, the hidden state, so it will have difficulty implementing Transformer. But if we can find a way to design a very large hidden state, maybe RNN will have the same performance as Transforme again.
So this is the process from the formal land to the neural network, and there are certain similarities between them. Conditional Kolmogorov complexity can be used as a solution for supervised learning.

As shown, this is an ultra-low regret solution for unsupervised learning, and although it is not computable, I think it is a useful framework. The condition here is a dataset, not an example. Here we are conditioning on a dataset rather than a single sample, and this method will extract all predicted Y values from X.

The feasibility of "compressing everything"
Next we talk about another small technical problem: conditional Kolmogorov complexity, which involves compression algorithms, the compressor will try to compress one data when it is exposed to another data, in the context of machine learning, especially dealing with big data When set, this situation is not natural.
The above equations show that if you make predictions on a supervised task Y, then using an old-fashioned Kolmogorov compressor to compress the concatenated data of X and Y is as good as using a conditional Kolmogorov compressor. Here I only give a brief introduction, and there are more subtleties in the details. This basically proves what we said earlier, that supervised learning problems can be solved with conditional Kolmogorov compressors.
That said, we could also use the regular Kolmogorov compressor, which simply collects all the data and concatenates all the files together for compression, which predicts well the supervisory tasks we care about.

Here is some analysis of the above results, but its proof process is relatively complicated, so it will not be discussed in depth here.
In summary, the solution for unsupervised learning is to feed all the data into a Kolmogorov compressor for Kolmogorov complexity computation.
3
If there is no overfitting, then joint compression is maximum likelihood

The last thing I want to say is: If there is no overfitting, then joint compression is maximum likelihood estimation. If you have a dataset, then the sum of the likelihoods for the given parameters is the cost of compressing the dataset, plus you pay the cost of compressing the parameters. But if you now want to compress two datasets, then just add more datasets to the sum.
In the context of machine learning, this way of jointly compressing data by concatenation is very natural. That's why we took the time to demonstrate conditional Kolmogorov complexity, and while I can't yet provide strong support for the above arguments, we're still valid by compressing all Kolmogorov complexity.
I'm bullish on the above, and it shows that neural networks are working. Stochastic Gradient Descent (SGD) on large neural networks is equivalent to large program search, the larger the neural network, the better it can approximate the Kolmogorov compressor, which is probably one of the reasons we like large neural networks, because we can use This idea of the conventional Kolmogorov compressor without regrets is approximately unrealizable, and it is hoped that as the trained neural network becomes larger and larger, the degree of regret becomes lower and lower.
4
Is it suitable for compression of GPT models?

We can apply the above method to the GPT model, but the tricky thing is that the behavior of the GPT model can also be explained without citing compression, we can simply explain the behavior of the GPT model as the conditional distribution learning on the text of the Internet . It is conceivable to imagine a document with repeating patterns, and these patterns may persist, so the behavior of the GPT model can be intuitively explained as the fusion behavior of these patterns, and this explanation does not need to refer to a specific theory of compression. Behavior can be explained without involving compression theory.
So, can we find another field for a direct test of this theory? Such as the field of vision. The field of vision has data at the pixel level, and we can try to apply this theory at the pixel level and see if this method can achieve good unsupervised learning results. The answer is yes, and it has been demonstrated experimentally that by applying this theory, we can achieve efficient unsupervised learning at the pixel level.
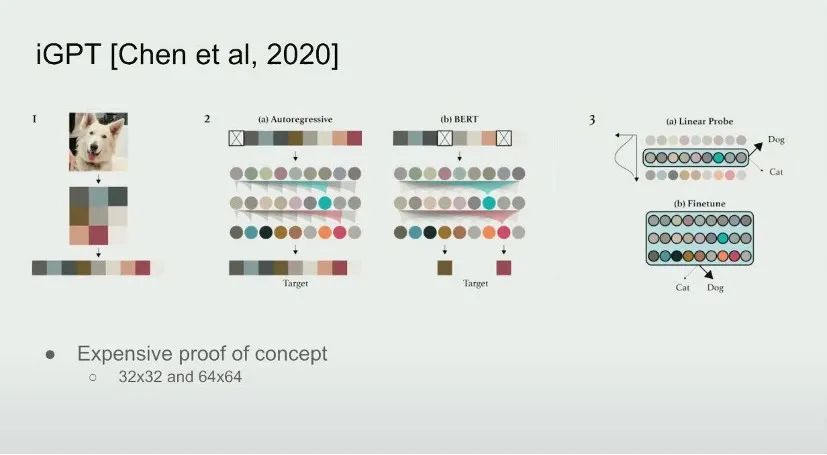
This is a study we conducted in 2020 called iGPT. iGPT is a very expensive proof-of-concept study that has no practical application yet. The results of the iGPT study show that if you have a very good next step predictor (next step predictor), then you can get great supervised learning results, and this concept has been verified in the image field.
Specifically, you need to convert the image into a sequence of pixels, assign each pixel a certain discrete intensity value, and then use the same Transformer to predict the next pixel. Unlike BERT, only the next token is predicted here, because this maximizes the likelihood of the compressor.
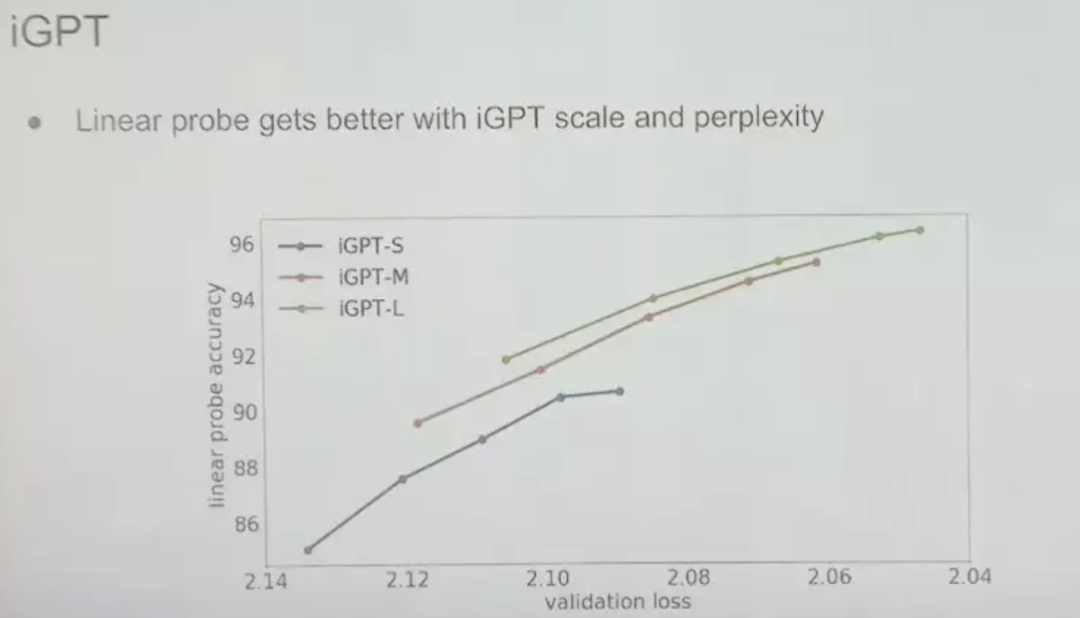
This is the next-step prediction accuracy of iGPT models of different sizes in the pixel prediction task. The vertical axis is the linear probe accuracy on the best layer of the neural network. We add a linear classifier to it and check the running status. Then we get three curves of different colors in the above figure. The gap between the three curves gradually Shrink, tend to be similar. This is what we expected, showing that pixel-by-pixel predictions are as effective as next-word predictions, and that this approach also improves the model's performance in unsupervised learning.
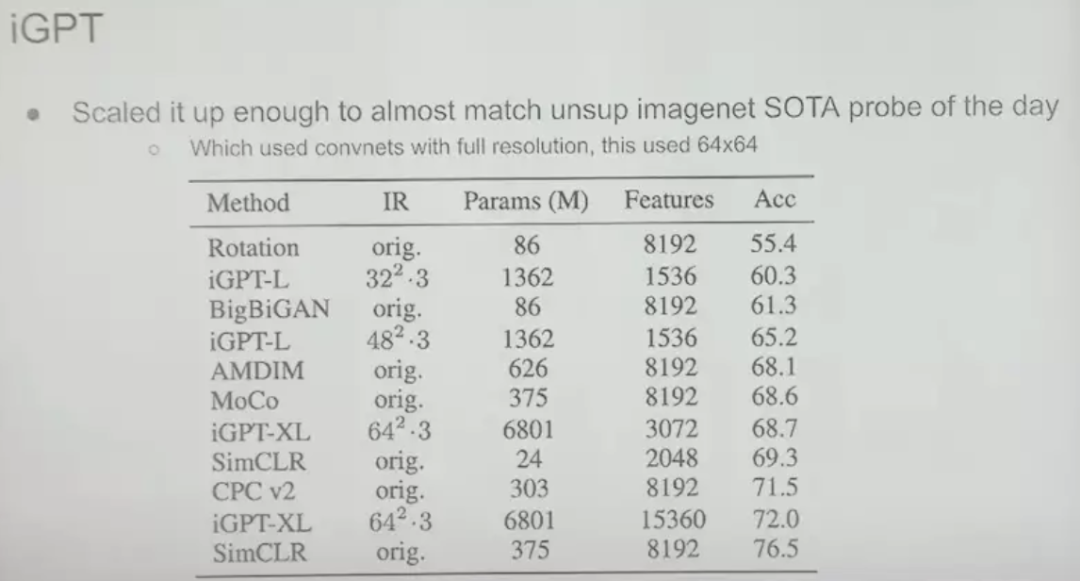
Through experiments, on ImageNet, we found that the performance of multi-scaled iGPT can be close to the best supervised learning today, but there is still a gap, but this is only a computational problem, because the latter uses large high-resolution images , and we used relatively small 64x64 pixel images on the giant Transformer (with 6 billion parameters, which is not large by today's standards, but was a huge model at the time). So this approach is like predicting the next pixel in an unsupervised way on a large image dataset, and fitting a linear probe on ImageNet gives great results.
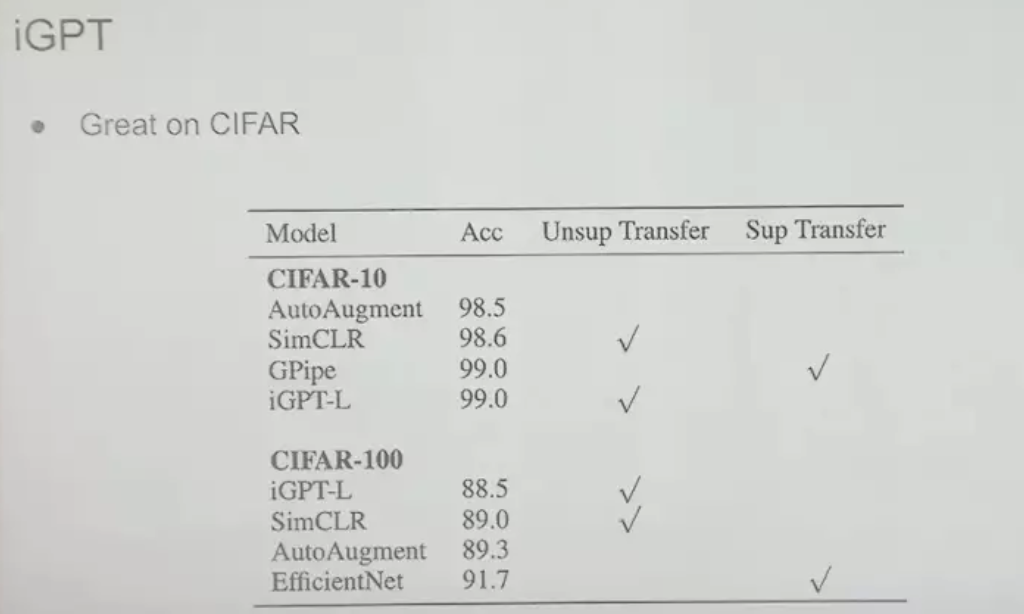
On the CIFAR-10 dataset, 99% accuracy can be achieved using this method. Although this is an achievement in 2020 and there may be other more advanced methods now, at the time this result was very desirable.
5
linear representation

I love compression theory, and for a long time I've been stuck with the fact that unsupervised learning doesn't allow you to think rigorously, but now we can do it to a certain extent. Compression theory does not currently explain why representations are linearly separable, nor why linear probes are needed. Linear representations are ubiquitous, and the reasons for their formation must be profound, and perhaps we will be able to clarify this clearly in the future.
I also observed an interesting phenomenon: the automatic next pixel prediction model (or autoregressive model) performs better than BERT in terms of linear representation. I'm not yet sure why, but it might help if we could understand what makes linear representations possible.
In my opinion, the next pixel prediction task needs to be predicted from all previous pixels, so the long range structure needs to be considered. Whereas in BERT you have your own vector representation, let's say in this case you discard 25% of the tokens or pixels, any prediction you make can actually be pretty well complemented by looking a little bit at the past and the future Complete. In contrast, the hardest prediction task in the next pixel is much harder than the hardest prediction task in BERT, which is only a guess at the moment, but we can verify it through experiments.
6
Answer audience questions
Q: Is there a more robust 2D version of the next pixel prediction model?
Answer: Any transformation of a neural network into a probabilistic model that assigns probabilities to different inputs can be seen as a more robust 2D version of the next pixel prediction model. Diffusion models are another common next-token prediction model. Diffusion models used in high-quality image generation do not really maximize the likelihood of their input steps, they have different goals. However, the original formulation does maximize the likelihood.
It should be noted that the diffusion model and the next lemma prediction model are mutually exclusive. I think that for the same reasons as the BERT model, the representation of the diffusion model is worse than that of the next lemma prediction model, which further adds to the mystery of why the linear representation is formed.
Q: Is Transformer SGD the best compressor program out there?
Ilya Sutskever: Yes, there is another hypothesis. Suppose we have a neural network (not necessarily a Transformer) that can assign log probabilities to data. Given a large number of training samples, we can run this neural network and calculate the log probability of each sample, and then These probabilities are summed to get the log probability that the neural network assigns to the entire dataset. However, this particular form of neural network cannot explicitly notice temporal or other structures in the order of the data. Still, I thought it would be possible to calculate the log probability for the entire dataset, and thus get the negative log probability, actually using this neural network as a compressor to compress the number of bits needed to compress that dataset.
Q: You mentioned compression as a framework for understanding and advancing unsupervised learning. Also, you mentioned at the end that it might be superficial if you apply this framework to language model next word prediction, since any text task can be converted to a next word prediction task. Thus, for text tasks, unsupervised learning is superficially similar to supervised learning. Image GPT, however, does not define text tasks as well as predicting the next pixel, but we can leverage linear representations, showing that compression can lead to good unsupervised learning. However, a highly efficient compressor may not provide a useful linear representation. Therefore, I wonder if there are cases where unsupervised learning and supervised learning are not superficially the same, but there is no need for a compressor to provide an efficient linear representation to justify compression as a good unsupervised learning goal.
A: A good linear representation is just an added benefit, it doesn't mean that a linear representation should be there, but the theory does argue that there should be good fine-tuning. Because joint compression is like approximate lookup with a bad search algorithm (SGD). Early experiments show that BERT learns linear representations that are worse than next-pixel predictions when run on images, and perhaps the same is true for diffusion models. So it's interesting to compare the results of fine-tuned diffusion models, and maybe someone has already done that.
everyone else is watching
The secret to 100K context windows for large language models
Infinite Context for Large Models and the Art of Dataset Composition
The author of Transformer: the method of constructing instructional agents
Head of OpenAI Alignment: Four-year plan to "drive" superintelligence
Try OneFlow: github.com/Oneflow-Inc/oneflow/
