1 Classification of machine learning
According to different learning paradigms, machine learning can be divided into supervised learning, unsupervised learning, semi-supervised learning, and reinforcement learning.
Supervised learning:
The training data has labels, and the mapping relationship between the data input and the label is learned through algorithm modeling, so as to predict the label of the future input. According to the "discrete" or "continuous" of labeled information, supervision is divided into two categories: "classification" and "regression (prediction)". For example, neural network, support vector machine, Gaussian mixture model, naive Bayesian method, decision tree, etc.
Unsupervised learning:
The training data is unlabeled, and through algorithmic modeling, the common patterns in the data are learned and summarized, so as to encode and cluster future data. For example, PCA, k-means clustering, etc.
Semi-supervised learning:
There are a small number of labeled samples and a large number of unlabeled samples in the training data. Semi-supervised learning is a learning technique between supervised learning and unsupervised learning. It uses both labeled samples and unlabeled samples for learning. Through algorithm modeling, the mapping relationship between data input and label is learned, so as to predict the label of future input.
Reinforcement Learning:
The training data has no labels, but it needs feedback from the learning environment, and based on the feedback given by the environment, it can continuously optimize and adjust its own behavior decisions. So as to give the optimal decision for future behavior. For example, Q-Learning, DQN, Monte Carlo methods, etc.
1.2 Definition of Reinforcement Learning
Reinforcement learning is a kind of machine learning learning method. It is to let the computer operate completely randomly from the beginning, and summarize the best behavior decision for each step through continuous trial and error, and adjust itself based on the feedback given by the environment. Behavioral decision-making, so as to give the optimal decision for future behavior. Reinforcement learning has been widely used in unmanned driving, robot control, game playing, and recommendation systems.
1.3 Reinforcement Learning Components
Reinforcement learning is mainly composed of two main bodies and four parts.
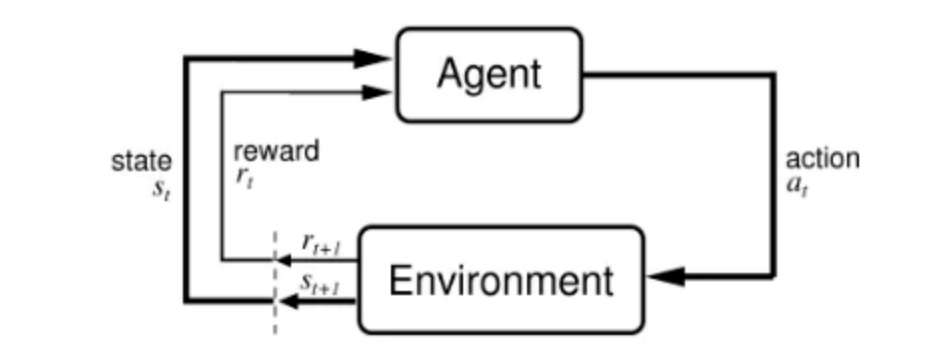
two subjects
-
Agent: An agent, that is, an individual who takes action, such as a player.
-
Environment: Environment, which can generate feedback on actions, such as game rules.
four parts
<A, S, R, P> Action space , State space ,Reward, Policy
-
A: Action space, that is, all action spaces in which the Agent takes actions. For example, for the snake game, it is the discrete operation space of up, down, left, and right; for driving games, it is the continuous space of left to right and liquid nitrogen acceleration.
-
S: State space, the feedback state after the Agent takes action. The body length position of the greedy snake, the speed position of the kart, etc., are all States.
-
R: Reward, real value, as the name suggests, is reward or punishment.
-
P: Strategy, that is, what action the Agent will take in the state s ∈ S s\in Ss∈S a ∈ A a\in Aa∈A.
Reinforcement learning is the process in which the agent takes action A according to the state S in the environment E, and continuously trains the generation strategy P in order to obtain the maximum reward R.
2 Classification of Reinforcement Learning
2.1 According to whether the environment is modeled (whether the environment is known)
-
(1) Model-Free RL (do not model the environment)
model is to use the model to represent the environment mentioned above, without trying to understand the environment, what the environment gives us is what the environment gives us, get feedback from the environment and learn from it, the environment Unknown, such as in a park, without a map, to find the exit through trial and error. Such as Q learning, Sarsa, Policy Gradients, etc. -
(2) Model-Based RL (modeling the environment)
through past experience, first understand what the real world is like, and build a model to simulate the feedback of the real world, not only in the real world, but also in the real world. Action in a virtual environment. Be able to predict all the situations that will happen next through imagination, and then choose the best of these imaginary situations, and take the next step according to this situation. The environment is known, such as in a park, there is a map, Dynamic programming can find the exit, which is what alphaGo uses. Still the above method, just join and model the environment.
2.2 According to learning objectives
(1) Policy-Based RL (based on probability)
Analyze the environment through the senses, directly output the probability of various actions to be taken in the next step, and then take actions according to the probability, so each action may be selected, but the probability is different. For example, Policy Gradients and so on.
(2) Value-Based RL (based on value)
Output the value of all actions, and choose the action based on the highest value. For example, Q learning, Sarsa, etc. (For discontinuous actions, both methods work, but for continuous actions, the value-based method cannot be used. We can only use a probability distribution to select specific actions among continuous actions).
(3)Actor-Critic
We can also combine these two methods to establish an Actor-Critic method, which will give the action based on the probability and the value of the action based on the value.
2.3 According to the strategy update method
(1) Monte-Carlo update (round update)
The model parameters (code of conduct) are updated once from the beginning of the game to the end. For example, the basic version of Policy Gradients, Monte-Carlo Learning, etc.
(2) Temporal-Difference update (single-step update)
The model parameters (code of conduct) are updated at each step from the beginning to the end of the game. For example, Q Learning, Sarsa, upgraded Policy Gradient, etc.
2.4 According to the learning style
(1) online RL (online reinforcement learning)
During the learning process, the agent needs to interact with the real environment (learn while playing). And online reinforcement learning can be divided into on-policy RL and off-policy RL. The on-policy uses the data collected by the current policy to train the model, and each piece of data is used only once. The data used in off-policy training does not need to be collected by the current policy. For example, Sarsa, Sarsa lambda, etc.
(2) offline RL (offline reinforcement learning)
During the learning process, it does not interact with the real environment, and only learns directly from past experience (dataset), while the dataset is data collected using other strategies, and the strategy of collecting data is not an approximate optimal strategy. For example, Q learning and so on.