This article mainly introduces what aspects of python need to learn to do big data? It has a certain reference value, and friends who need it can refer to it. I hope that you will gain a lot after reading this article. Let the editor take you to understand it together.

foreword
The main technology of this article is to use the Scrapy framework of Python to crawl the rental housing data of the website, and then use Mysq to continue simple processing and storage of the data, and then to visualize the data with Flask and Highcharts. Do a simple summary and actual combat exercises for the day's study.
Note: This collection has properly controlled the collection frequency, and the collected data is only used for learning.
1. Data collection
1.1 Target website selection
First select the target website. This time I am collecting data from Lianjia.com. Special reminder: When using scrapy to crawl data, you must pay attention to the frequency of crawling, so as not to affect the normal users of the website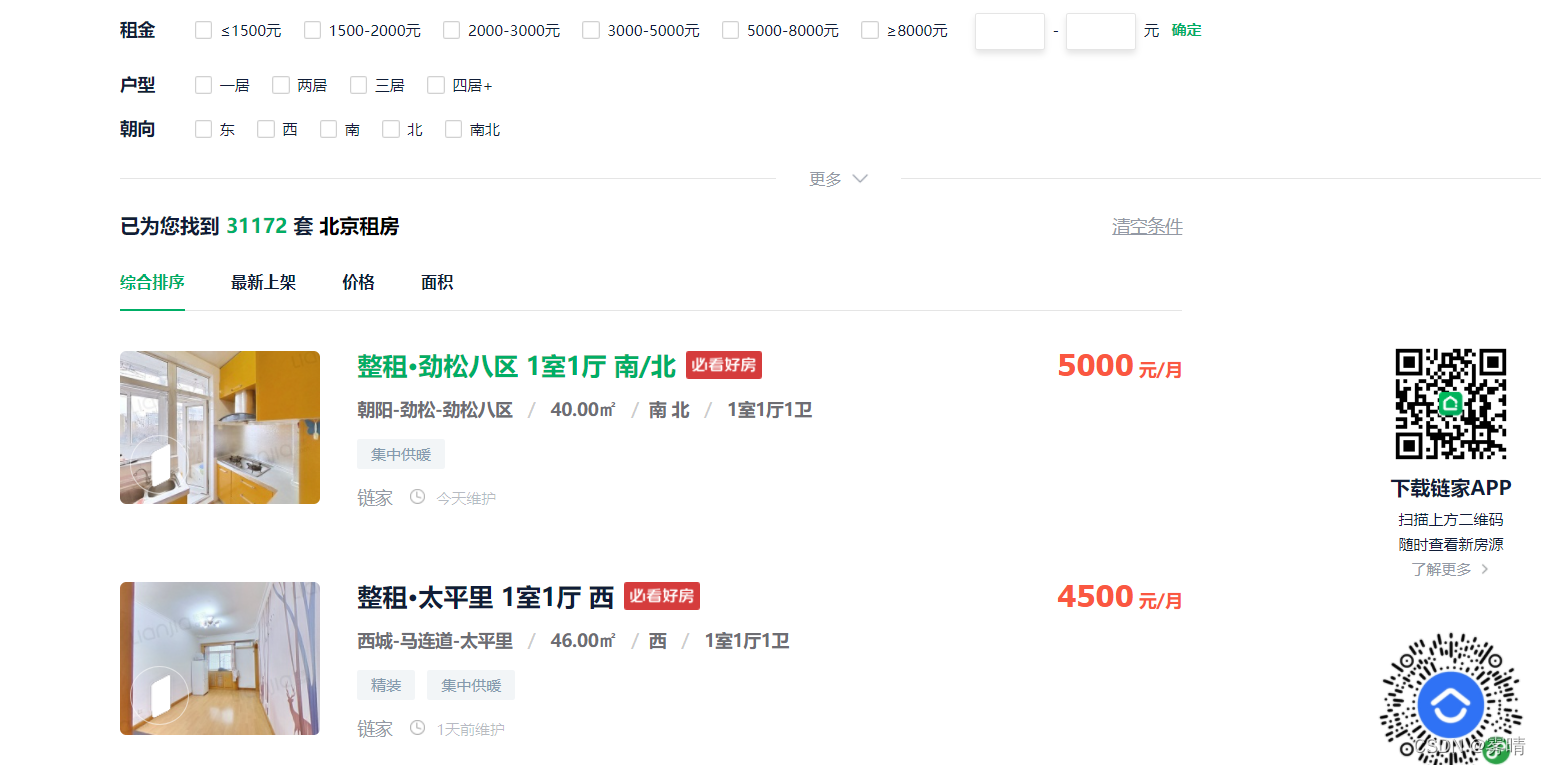
1.2 Create a crawler project
After the target website is selected, we create a crawler project. First, we need to install the scrapy library and the installation tutorial; the
installation tutorial of the Scrapy crawler
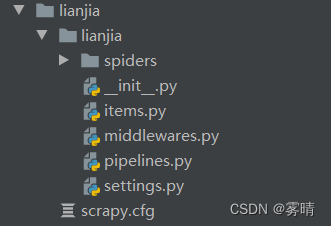
uses the command scrapy startproject myfrist (your_project_name to create a project
) 
. There will be a simple note for scrapy, it’s a note
| name | effect |
|---|---|
| scrapy.cfg | The configuration information of the project mainly provides a basic configuration information for the Scrapy command line tool. (The configuration information related to the real crawler is in the settings.py file) |
| items.py | Set the data storage template for structured data, such as: Django's Model |
| pipelines | Data processing behavior, such as: general structured data persistence |
| settings.py | Configuration files, such as: recursive layers, concurrency, delayed download, etc. |
| spiders | Crawler directory, such as: create files, write crawler rules |
| The next step is to create a crawler, use the command: scrapy genspider crawler name crawler address | |
| After using this command, a crawler file will appear in the spiders directory | |
 |
|
| At this point, our project is created, and the next step is to write the data persistence model. |
1.3 Data Persistence Model
It is the items.py file
class LianjiaItem(scrapy.Item):
# define the fields for your item here like:
name = scrapy.Field()
url = scrapy.Field()
addres1 = scrapy.Field()
addres2 = scrapy.Field()
area = scrapy.Field()
cx = scrapy.Field()
rz = scrapy.Field()
zq = scrapy.Field()
kf = scrapy.Field()
zj=scrapy.Field()
After the model is written, the following is to create a crawler
1.3 Writing a crawler
Note: For some reasons, I modified some xpath statements in the following code, so direct copying and use cannot run, but the logic is absolutely correct and does not affect learning. If you really need code that can be run directly, you can PM me
class ZfSpider(scrapy.Spider):
name = 'zf'
allowed_domains = ['bj.lianjia.com']
start_urls = ['https://bj.lianjia.com/zufang/']
def parse(self, response):
#构造分页Url
url1='https://bj.lianjia.com/zufang/pg'
url2='/#contentList'
for i in range(1,100):
url=url1+str(i)+url2
#丢到下一层去
yield scrapy.Request(url=url,callback=self.one_data_list,meta={})
def one_data_list(self,response):
data_list = response.xpath('//*[@id="content"]/div[1]/div[1]/div')
for i in data_list:
url='https://bj.lianjia.com'+i.xpath('./div/p[1]/a/@href').get()
name=i.xpath('./div/p[1]/a/text()').get()
addres1=i.xpath('./div/p[1]/a/text()').get()
addres2=i.xpath('./div/p[1]/a[3]/text()').get()
meta={
'url':url,
'name':name,
'addres1':addres1,
'addres2':addres2
}
yield scrapy.Request(url=url,callback=self.data_donw,meta=meta)
def data_donw(self,response):
lianjIetm=LianjiaItem()
lianjIetm['url']=response.meta['url']
lianjIetm['name']=response.meta['name']
lianjIetm['addres1']=response.meta['addres1']
lianjIetm['addres2'] = response.meta['addres2']
#取出数据
lianjIetm['area']=response.xpath('//*[@id="info"]/ul[1]/li[1]/text()').get()
lianjIetm['cx']=response.xpath('//*[@id="info"]/ul[1]/li[3]/text()').get()
lianjIetm['rz']=response.xpath('//*[@id="info"]/ul[1]/li[4]/text()').get()
lianjIetm['zq']=response.xpath('//*[@id="info"]/ul[2]/li[2]/text()').get()
lianjIetm['kf']=response.xpath('//*[@id="info"]/ul[2]/li[5]/text()').get()
lianjIetm['zj'] = response.xpath('//*[@id="aside"]/div[0]/span/text()').get()
#推到下载器去
yield lianjIetm
At this point, we have finished writing the crawler to try the effect
Start the crawler command: scrapy crawl crawler name
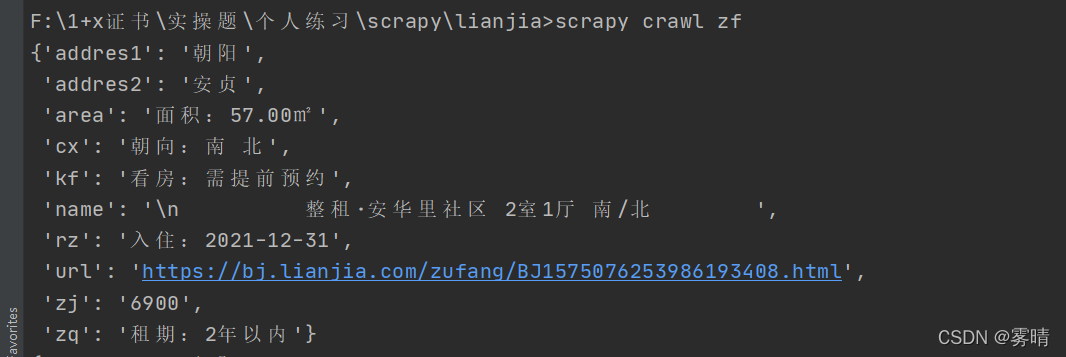
No problem, let’s write the pipeline below. The project pipeline is used to store data persistently in human terms. We need to store the data in the mysql database. Of course, before that, we need to create the database and table structure in mysql. Just like our model class, the train collector is pseudo-original .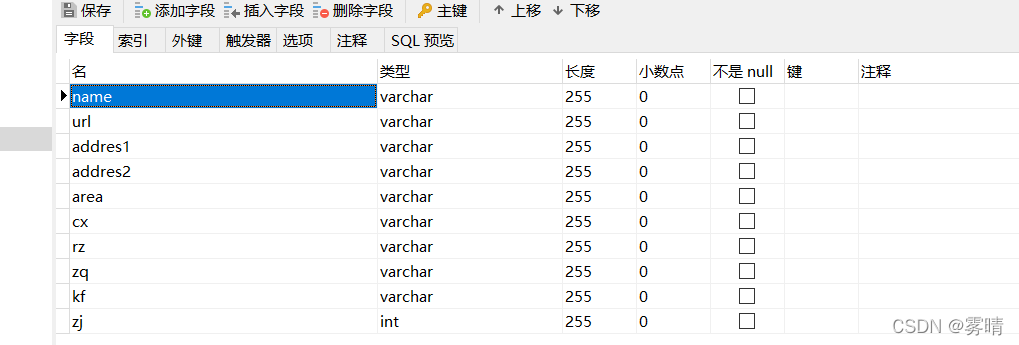
1.4 Writing the project pipeline
That is the pipelines.py file.
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
# useful for handling different item types with a single interface
import pymysql
from itemadapter import ItemAdapter
class LianjiaPipeline:
'''保存数据'''
def open_spider(self, spider):
self.db = pymysql.connect(host='192.168.172.131', port=3306, user='root', password='12346', charset='utf8',
database='lj')
self.cur = self.db.cursor()
def process_item(self, item, spider):
print(item)
sql="insert into data values(%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)"
self.cur.execute(sql,[item['name'],item['url'],item['addres1'],item['addres2'],item['area'],item['cx'],item['rz'],item['zq'],item['kf'],item['zj']])
self.db.commit()
return item
def close_spider(self,spider):
self.db.close()
After writing here, you will find that there is no data in the database when you start it directly, because it has not been enabled yet, you need to configure it in settings.py, and you can see that there is already data 

when you start the crawler below 
, and the data collection is complete at this point, as follows is data cleaning
data cleaning
I am not a professional who studies big data. I can only say that I am mixed in the big data class and mixed with a big data second-rate competition. As for data cleaning, this is just my own understanding. If there is any mistake, please correct me. 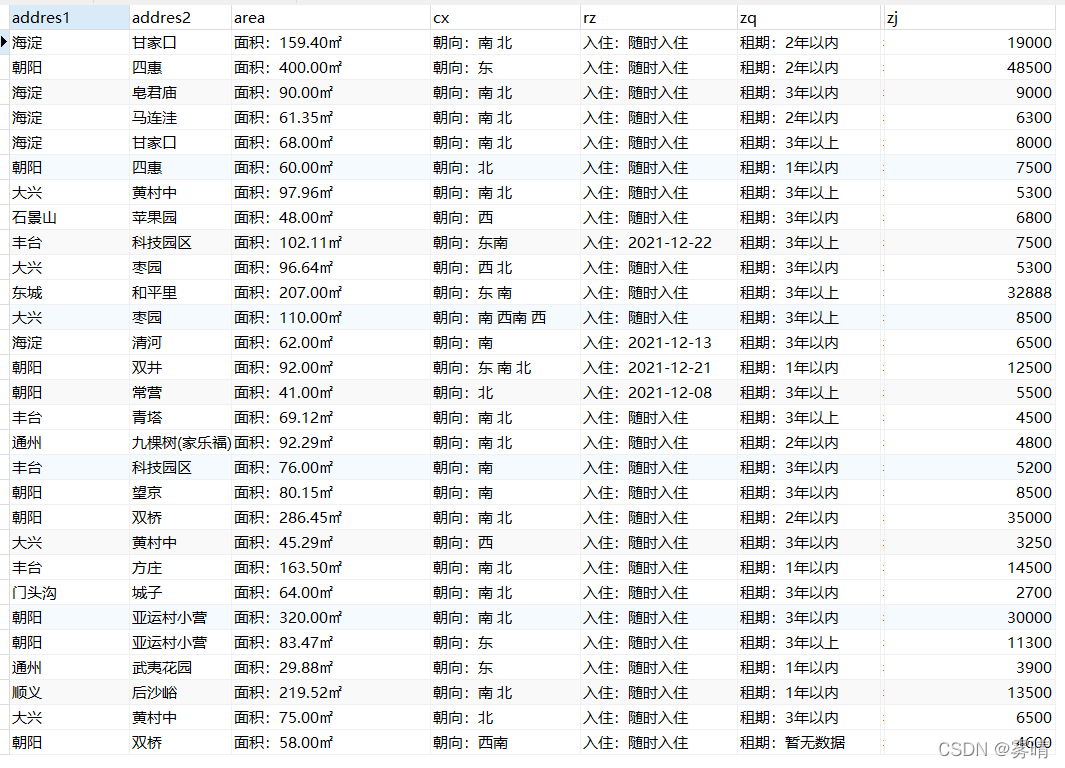
Let me talk about the problem first.
1. The address is not merged
2. The area uses numbers to facilitate sorting
3. There are some missing data in the lease term
Solution
1. Merge addresses
2. Process area data
3. Get rid of missing data
# 合并地址
UPDATE `lj`.`data` SET `addres2` = CONCAT(`addres1`,`addres2`)
# 面积处理
UPDATE `lj`.`data` set `area`=substring(`area`,4)
UPDATE `lj`.`data` set `area`=REPLACE(`area`,'㎡','');
# 处理缺失值
DELETE FROM `lj`.`data` where rz='入住:暂无数据'
The final effect 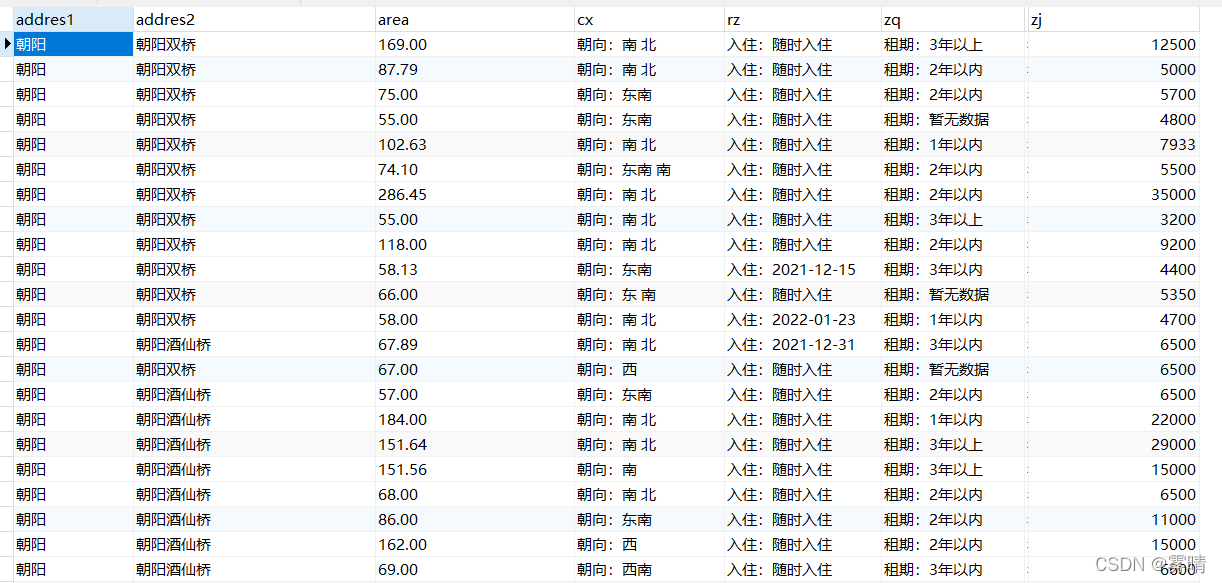
is the data visualization at the end, and it will be improved when it is empty. I have been a little busy recently, and I am still considering whether to use falsk or django