Big data visualization - Douban movie data visualization analysis based on Python
This project aims to build a Python-based big data visualization system through comprehensive analysis and visual display of Douban movie data. By collecting, cleaning, and analyzing Douban movie data through data crawling, we provide a comprehensive movie information platform, providing users with tools to gain an in-depth understanding of movie industry trends, film evaluations, and actor performance. The key steps of the project include data collection, data cleaning, data analysis and visual display. First, we use crawler technology to obtain rich movie data from the Douban movie website, including basic movie information, ratings, comments, etc., and store them in the Mysql database. Then, through data cleaning and preprocessing, the quality and consistency of the data are ensured to improve the accuracy of subsequent analysis. The data analysis stage mainly includes in-depth research on the distribution of movie ratings, the number distribution of different types of movies, ratings, and the influence of actors. Based on Echarts for visual display, with the help of data analysis libraries (such as Pandas, NumPy) and visualization libraries (such as Matplotlib, Seaborn) in Python, we can clearly display the characteristics and trends of movie data in the form of charts. Finally, we present the analysis results in an interactive visual interface, and users can use the system's customized query and filtering functions to dig deeper into the movie information they are interested in. This project not only provides a comprehensive data reference platform for film lovers, but also provides film industry practitioners with tools to gain insight into industry trends.
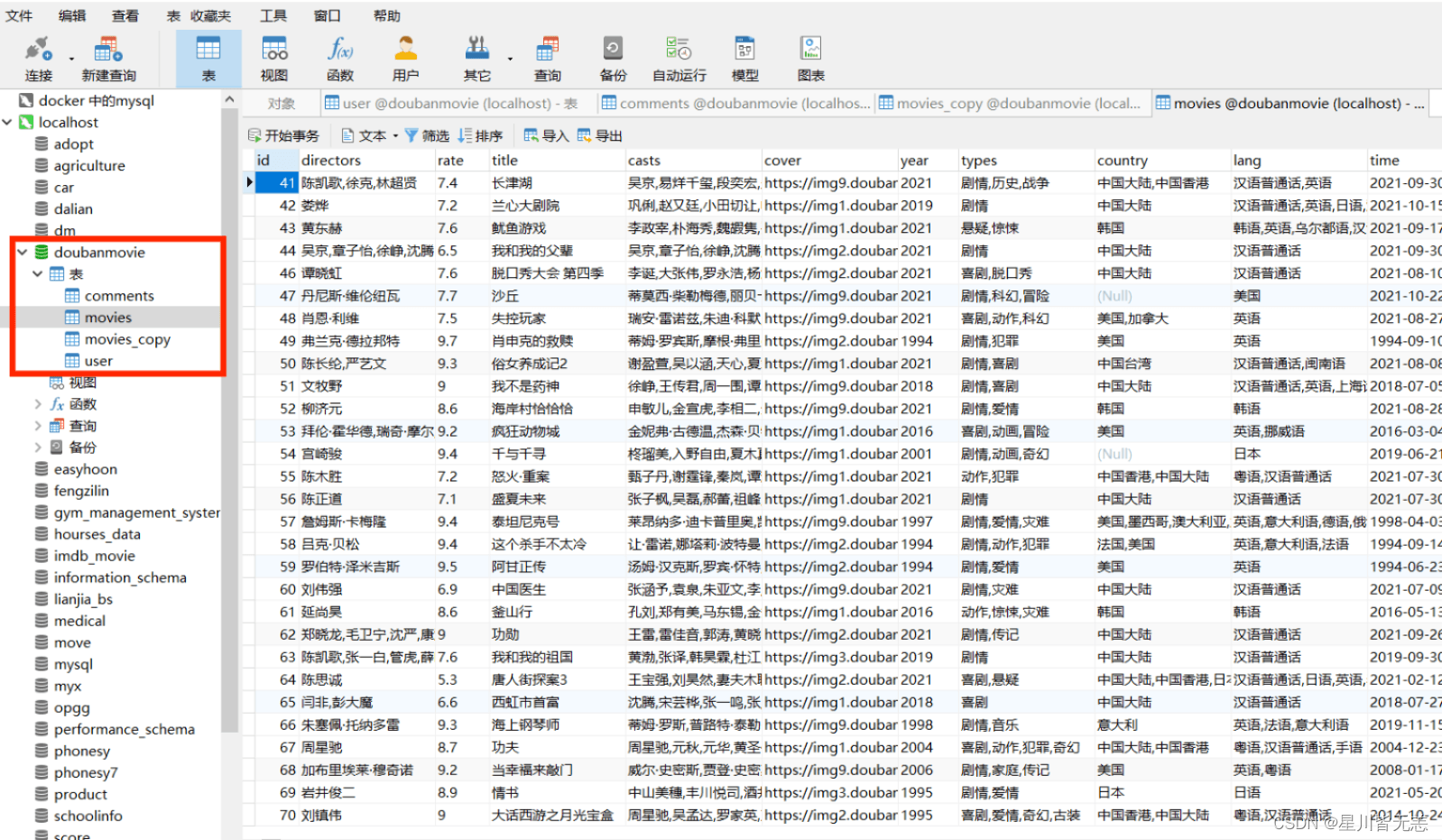
The last field information we crawled: movie name, rating, cover image, detail url, release time, director, type, production country, language, film length, movie introduction, star ratio, how many people have rated it, trailer, top five Comments, five detailed pictures
for i,moveInfomation in enumerate(moveisInfomation):
try:
resultData = {
}
# 详情
resultData['detailLink'] = detailUrls[i]
# 导演(数组)
resultData['directors'] = ','.join(moveInfomation['directors'])
# 评分
resultData['rate'] = moveInfomation['rate']
# 影片名
resultData['title'] = moveInfomation['title']
# 主演(数组)
resultData['casts'] = ','.join(moveInfomation['casts'])
# 封面
resultData['cover'] = moveInfomation['cover']
# =================进入详情页====================
detailMovieRes = requests.get(detailUrls[i], headers=headers)
soup = BeautifulSoup(detailMovieRes.text, 'lxml')
# 上映年份
resultData['year'] = re.findall(r'[(](.*?)[)]',soup.find('span', class_='year').get_text())[0]
types = soup.find_all('span',property='v:genre')
for i,span in enumerate(types):
types[i] = span.get_text()
# 影片类型(数组)
resultData['types'] = ','.join(types)
country = soup.find_all('span',class_='pl')[4].next_sibling.strip().split(sep='/')
for i,c in enumerate(country):
country[i] = c.strip()
# 制作国家(数组)
resultData['country'] = ','.join(country)
lang = soup.find_all('span', class_='pl')[5].next_sibling.strip().split(sep='/')
for i, l in enumerate(lang):
lang[i] = l.strip()
# 影片语言(数组)
resultData['lang'] = ','.join(lang)
upTimes = soup.find_all('span',property='v:initialReleaseDate')
upTimesStr = ''
for i in upTimes:
upTimesStr = upTimesStr + i.get_text()
upTime = re.findall(r'\d*-\d*-\d*',upTimesStr)[0]
# 上映时间
resultData['time'] = upTime
if soup.find('span',property='v:runtime'):
# 时间长度
resultData['moveiTime'] = re.findall(r'\d+',soup.find('span',property='v:runtime').get_text())[0]
else:
# 时间长度
resultData['moveiTime'] = random.randint(39,61)
# 评论个数
resultData['comment_len'] = soup.find('span',property='v:votes').get_text()
starts = []
startAll = soup.find_all('span',class_='rating_per')
for i in startAll:
starts.append(i.get_text())
# 星星比例(数组)
resultData['starts'] = ','.join(starts)
# 影片简介
resultData['summary'] = soup.find('span',property='v:summary').get_text().strip()
# 五条热评
comments_info = soup.find_all('span', class_='comment-info')
comments = [{
} for x in range(5)]
for i, comment in enumerate(comments_info):
comments[i]['user'] = comment.contents[1].get_text()
comments[i]['start'] = re.findall('(\d*)', comment.contents[5].attrs['class'][0])[7]
comments[i]['time'] = comment.contents[7].attrs['title']
contents = soup.find_all('span', class_='short')
for i in range(5):
comments[i]['content'] = contents[i].get_text()
resultData['comments'] = json.dumps(comments)
# 五张详情图
imgList = []
lis = soup.select('.related-pic-bd img')
for i in lis:
imgList.append(i['src'])
resultData['imgList'] = ','.join(imgList)
Save the results to a CSV file and SQL database and update the page count record when complete.
Extract actor and director movie quantity information from Douban movie data for subsequent analysis and visual display.
def getAllActorMovieNum():
allData = homeData.getAllData()
ActorMovieNum = {
}
for i in allData:
for j in i[1]:
if ActorMovieNum.get(j,-1) == -1:
ActorMovieNum[j] = 1
else:
ActorMovieNum[j] = ActorMovieNum[j] + 1
ActorMovieNum = sorted(ActorMovieNum.items(), key=lambda x: x[1])[-20:]
x = []
y = []
for i in ActorMovieNum:
x.append(i[0])
y.append(i[1])
return x,y
Define the function getAllDirectorMovieNum() that counts the number of movies directed by a director:
def getAllDirectorMovieNum():
allData = homeData.getAllData()
ActorMovieNum = {
}
for i in allData:
for j in i[4]:
if ActorMovieNum.get(j,-1) == -1:
ActorMovieNum[j] = 1
else:
ActorMovieNum[j] = ActorMovieNum[j] + 1
ActorMovieNum = sorted(ActorMovieNum.items(), key=lambda x: x[1])[-20:]
x = []
y = []
for i in ActorMovieNum:
x.append(i[0])
y.append(i[1])
return x,y
allData = homeData.getAllData(): Call the functionhomeDatain the modulegetAllDatato get all the movie data and save it inallDatavariables.ActorMovieNum = {}:Creates an empty dictionaryActorMovieNumthat stores a mapping of directors to the number of films they have directed.for i in allData:: Traverse all movie data, whichirepresents the information of each movie.for j in i[4]:: In each movie's information, usei[4]the access director's information, and then iterate through each director.if ActorMovieNum.get(j, -1) == -1:: CheckActorMovieNumwhether the director's record already exists in the dictionary. If it does not exist, add the director as a key to the dictionary and initialize the corresponding value to 1.else:: If a record of the director already exists in the dictionary, add 1 to the corresponding value, indicating that the director has directed another movie.ActorMovieNum = sorted(ActorMovieNum.items(), key=lambda x: x[1])[-20:]: Sort the directors and the number of movies they directed in the dictionary in descending order according to the number of movies, and then take the first 20 items after sorting. The basis for sorting iskey=lambda x: x[1], that is, sorting according to the values in the dictionary.x = []andy = []: Create two empty lists to store the director name and the corresponding number of directed movies.for i in ActorMovieNum:: Traverse the top 20 sorted directors and the number of films they directed.x.append(i[0])andy.append(i[1]): Add the director's name and the number of films he directed to the listsxand respectivelyy.return x, y: Returns two lists storing the name of the director and the number of films directed.
homeDataImport the function from the module named getAllDataand then use pandasthe library to create a DataFrame df. getAllDataThe return value of the function is passed to DataFramethe constructor, specifying the column names of the data frame.
from . import homeData: This line of code.importshomeDatathe module from the current directory (meaning the current directory).import pandas as ps: This line of code importspandasthe library and uses itpsas an alias. Generally speaking,pandasthe alias ispd, but that is used hereps.df = ps.DataFrame(homeData.getAllData(), columns=[...]): This line of code creates a data framedfandhomeData.getAllData()fills it with the return value of . The column namescolumnsare specified by the parameters, and the order of the columns corresponds to the order in the list. Column names include:- 'id': movie ID
- 'directors': director
- 'rate': rating
- 'title': title
- 'casts': actors
- 'cover': cover
- 'year': year of release
- 'types': types
- 'country': country of production
- 'lang': language
- 'time': duration
- 'moveiTime': movie duration
- 'comment_len': comment length
- 'starts': star rating
- 'summary': summary
- 'comments': comments
- 'imgList': image list
- 'movieUrl': movie link
- 'detailLink': detailed link
This creates a data frame containing specific column names, with the data homeData.getAllData()returned from the function.
from . import homeData
import pandas as ps
df = ps.DataFrame(homeData.getAllData(),columns=[
'id',
'directors',
'rate',
'title',
'casts',
'cover',
'year',
'types',
'country',
'lang',
'time',
'moveiTime',
'comment_len',
'starts',
'summary',
'comments',
'imgList',
'movieUrl',
'detailLink'
])
Extract the address data from the 'country' column in the DataFrame. The address data in the data frame is extracted, and the number of occurrences of each address is counted. It first checks each element in the 'country' column and, if the element is a list, adds each element in the list to a new list (address). Then, it creates a dictionary (addressDic) with addresses as keys and occurrences as values, and finally returns a list of addresses and the corresponding list of occurrences.
def getAddressData():
# 获取名为 'country' 的列的值
addresses = df['country'].values
# 创建一个空列表来存储地址
address = []
# 遍历 'country' 列的每个元素
for i in addresses:
# 如果元素是列表类型
if isinstance(i, list):
# 遍历列表中的每个元素并添加到 address 列表中
for j in i:
address.append(j)
else:
# 如果元素不是列表类型,直接将其添加到 address 列表中
address.append(i)
# 创建一个空字典来存储地址及其出现次数
addressDic = {
}
# 遍历地址列表中的每个元素
for i in address:
# 如果地址字典中不存在该地址,则将其添加并设置出现次数为1
if addressDic.get(i, -1) == -1:
addressDic[i] = 1
else:
# 如果地址字典中已存在该地址,则将其出现次数加1
addressDic[i] = addressDic[i] + 1
# 返回地址列表和对应的出现次数列表
return list(addressDic.keys()), list(addressDic.values())
Extract the language data from the 'lang' column of the data frame and count the number of occurrences of each language. Finally, the language list and the corresponding occurrence count list are returned.
def getLangData():
# 获取名为 'lang' 的列的值
langs = df['lang'].values
# 创建一个空列表来存储语言数据
languages = []
# 遍历 'lang' 列的每个元素
for i in langs:
# 如果元素是列表类型
if isinstance(i, list):
# 遍历列表中的每个元素并添加到 languages 列表中
for j in i:
languages.append(j)
else:
# 如果元素不是列表类型,直接将其添加到 languages 列表中
languages.append(i)
# 创建一个空字典来存储语言及其出现次数
langsDic = {
}
# 遍历语言列表中的每个元素
for i in languages:
# 如果语言字典中不存在该语言,则将其添加并设置出现次数为1
if langsDic.get(i, -1) == -1:
langsDic[i] = 1
else:
# 如果语言字典中已存在该语言,则将其出现次数加1
langsDic[i] = langsDic[i] + 1
# 返回语言列表和对应的出现次数列表
return list(langsDic.keys()), list(langsDic.values())
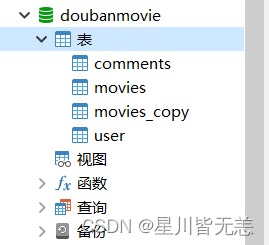
Create four tables in the database:
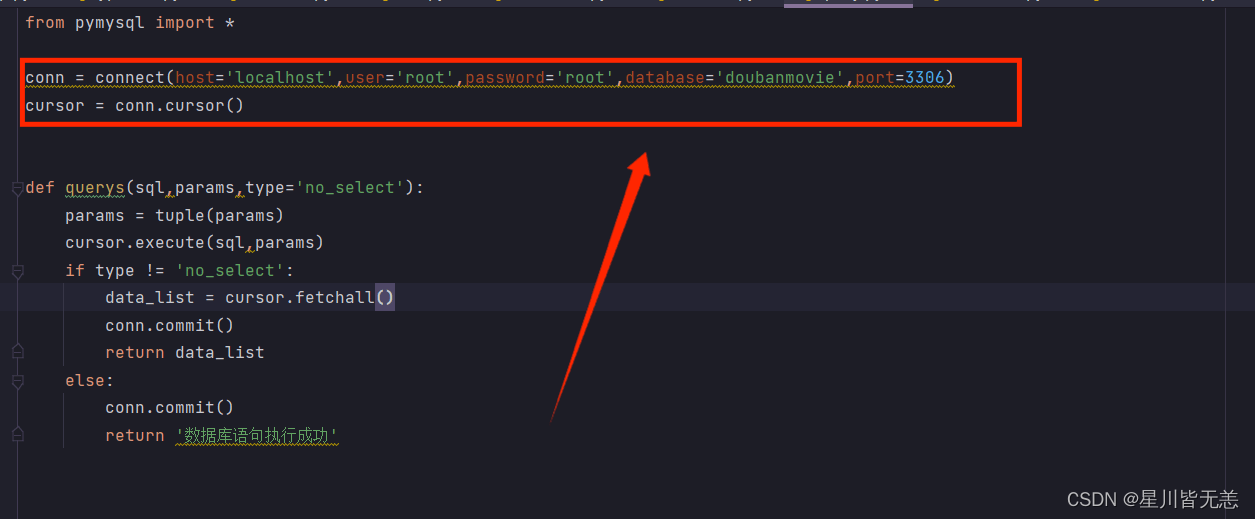
modify it to your own database host name and account password:
start the project:
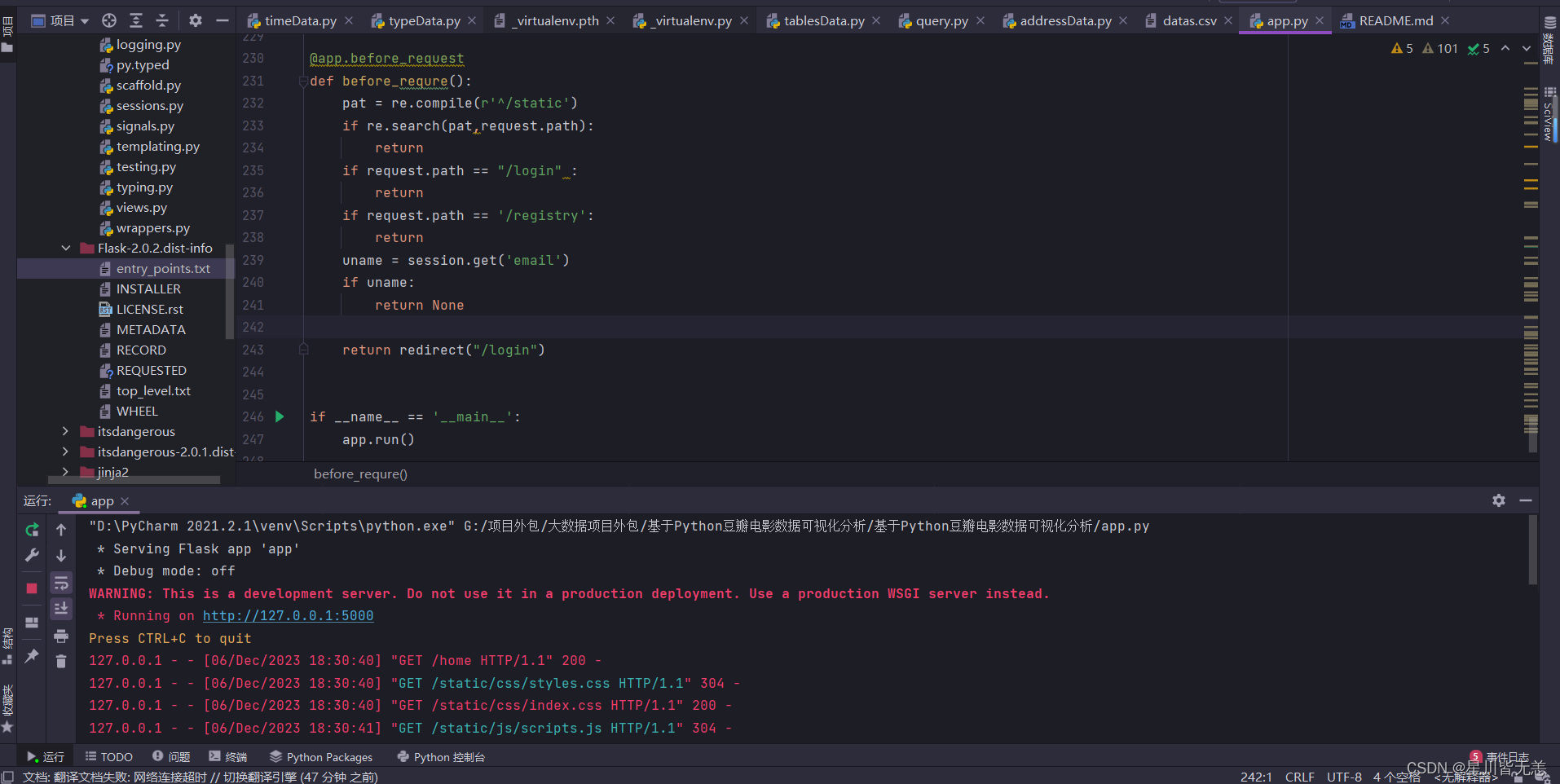
Service port: 5000 http://127.0.0.1:5000
User registration http://127.0.0.1:5000/registry
User login
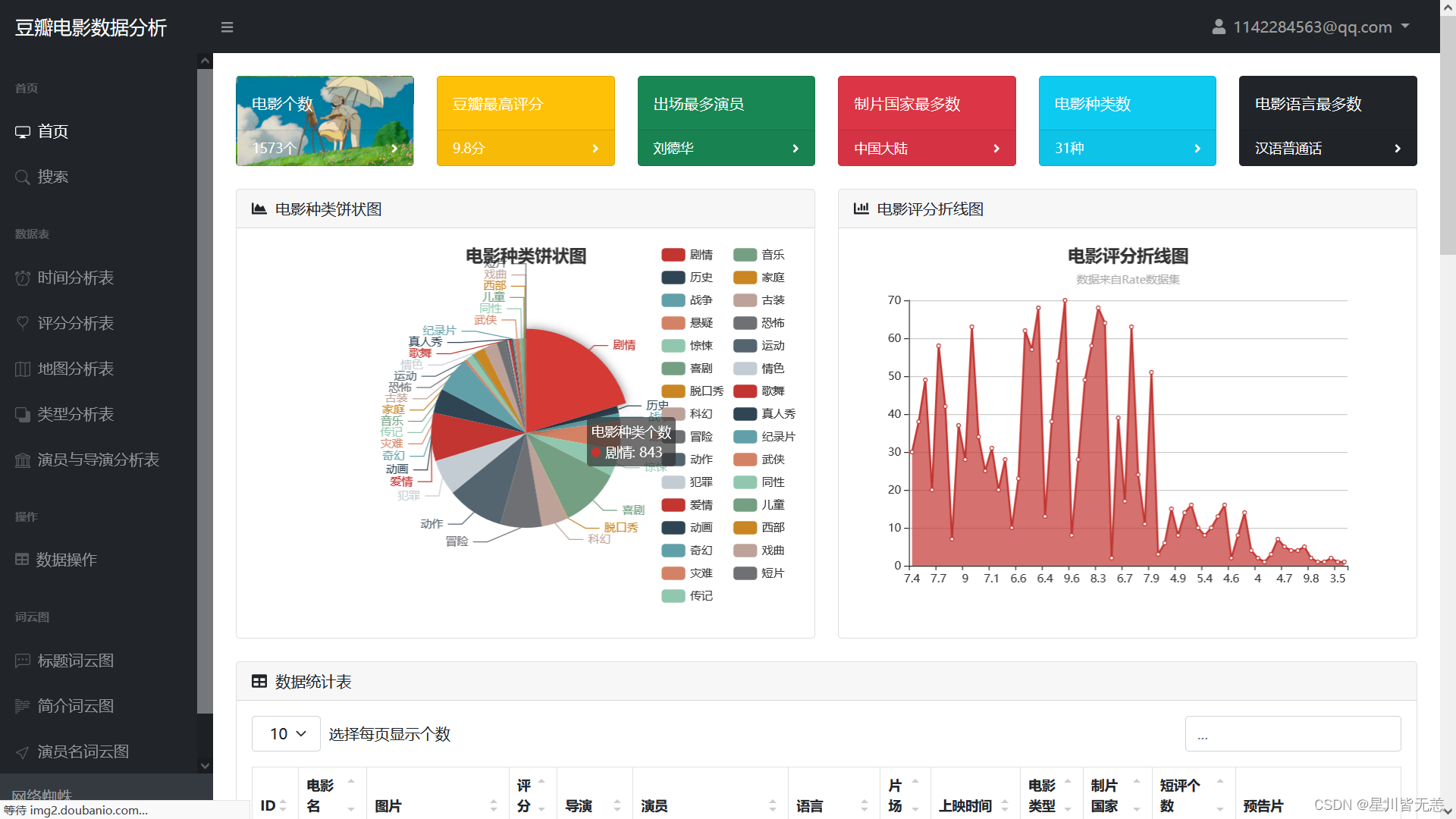
Home page display:
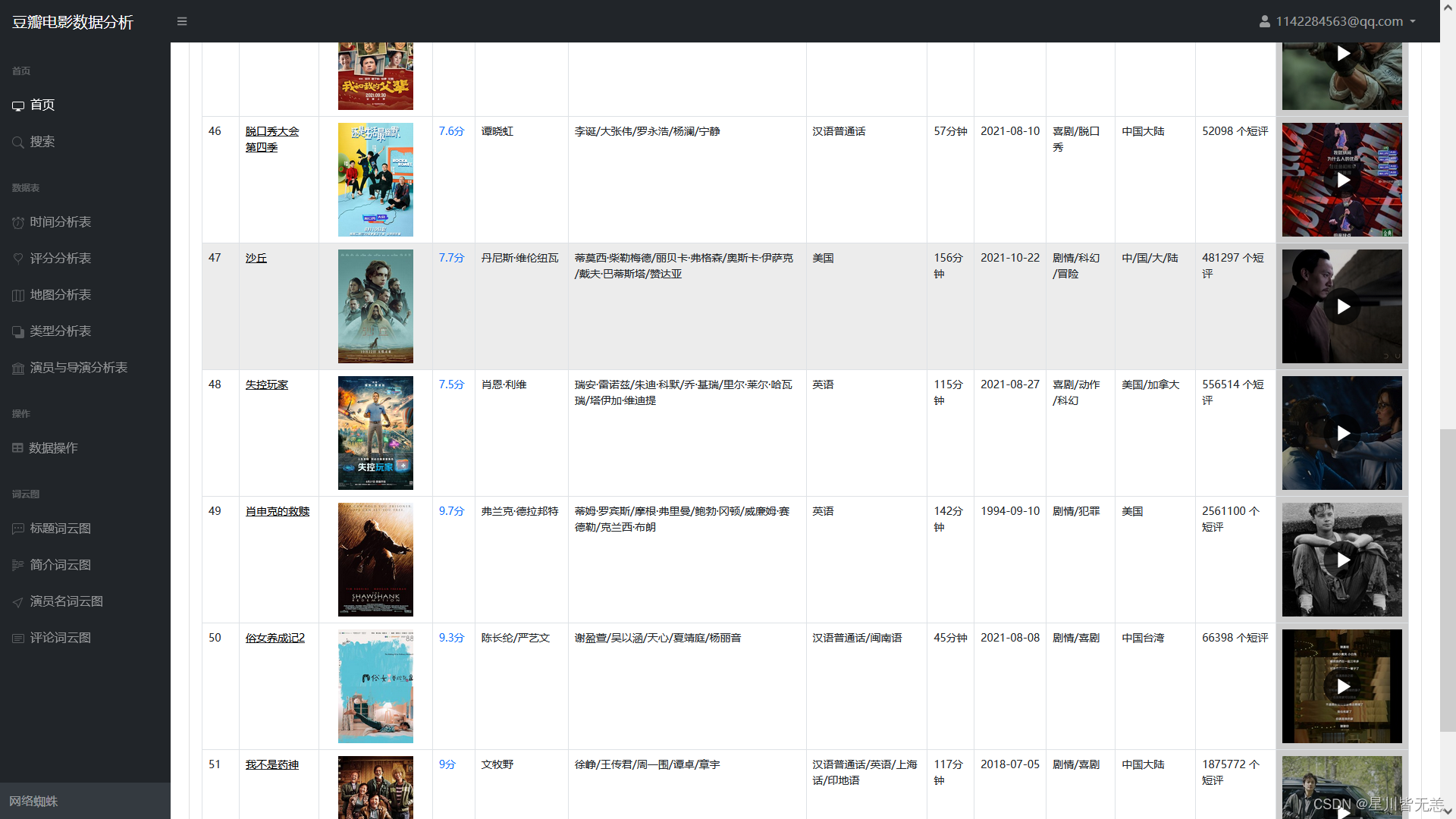
There is also movie data, including movie title, rating, studio, trailer and other data.
View movie trailer
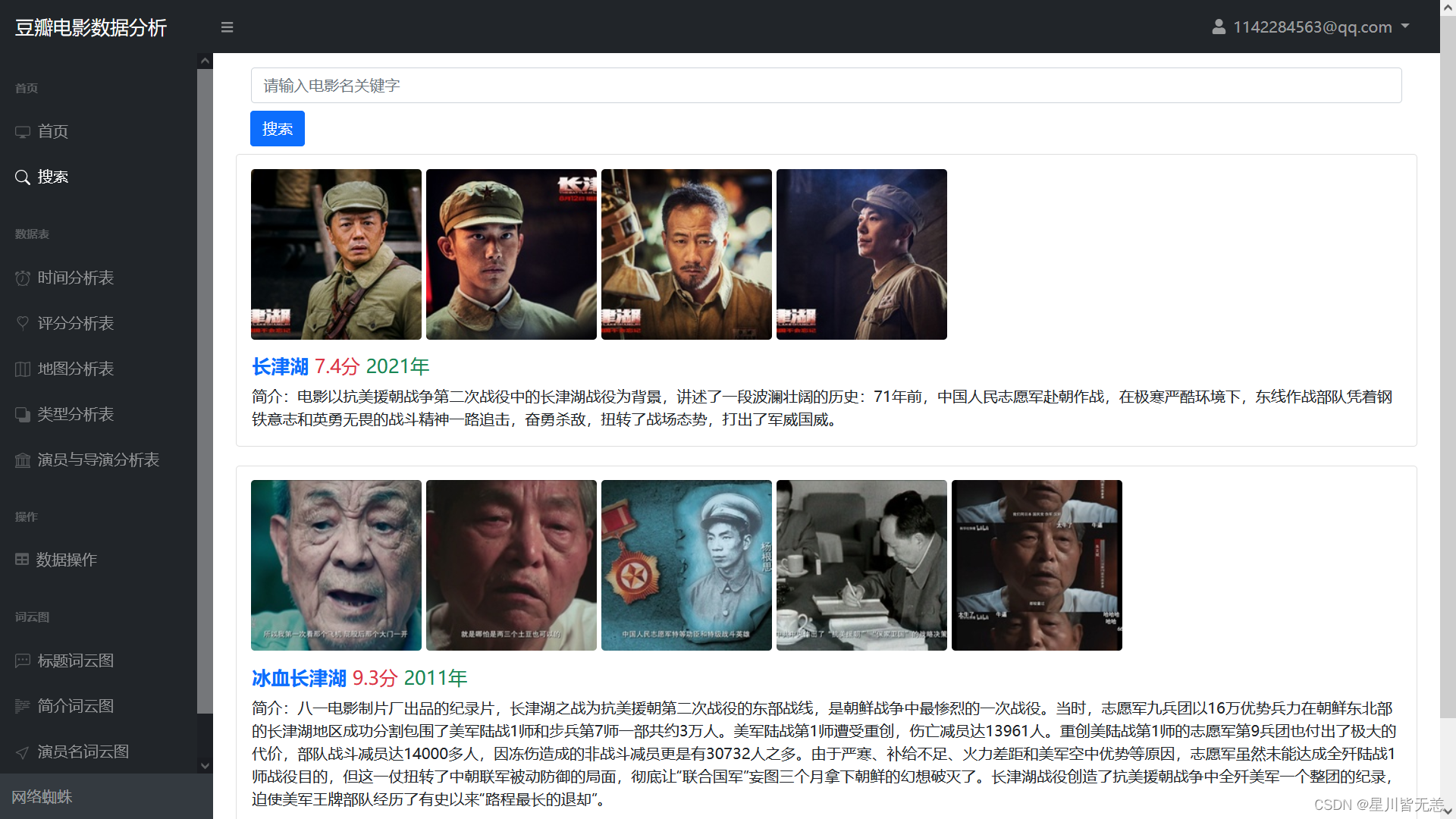
Movie search
Film Production Analysis
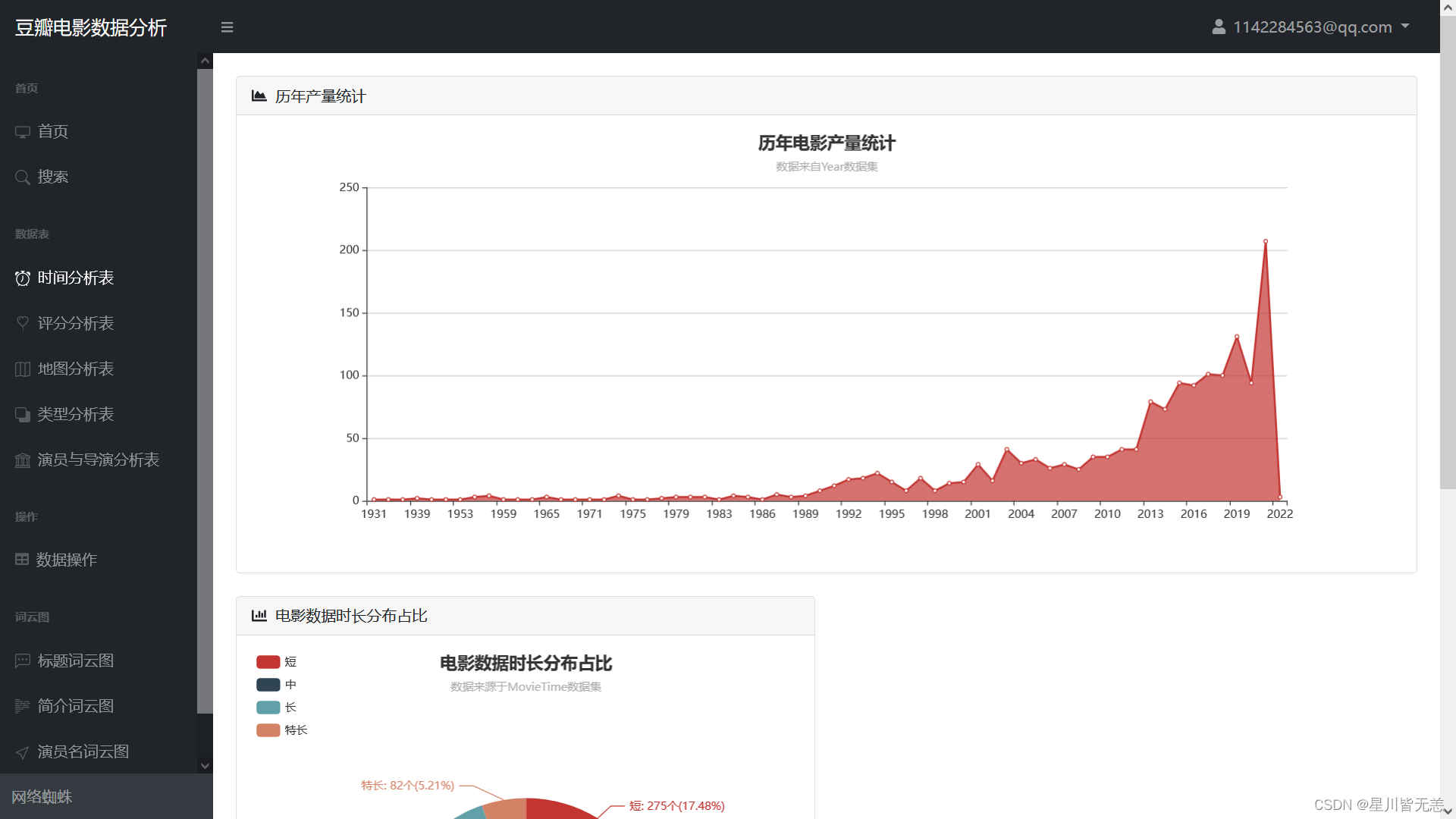
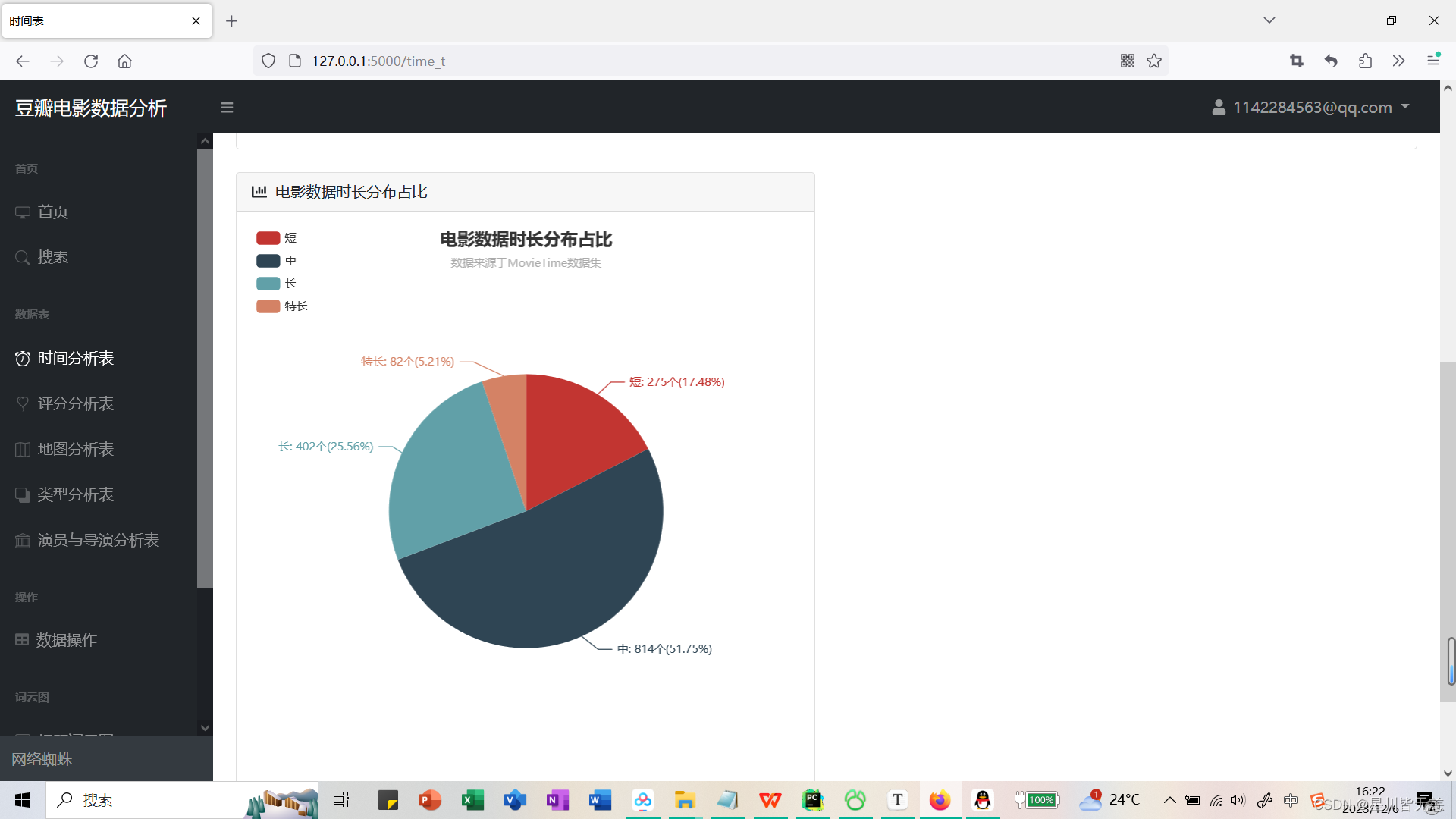
Movie data duration distribution proportion
Movie rating statistical analysis
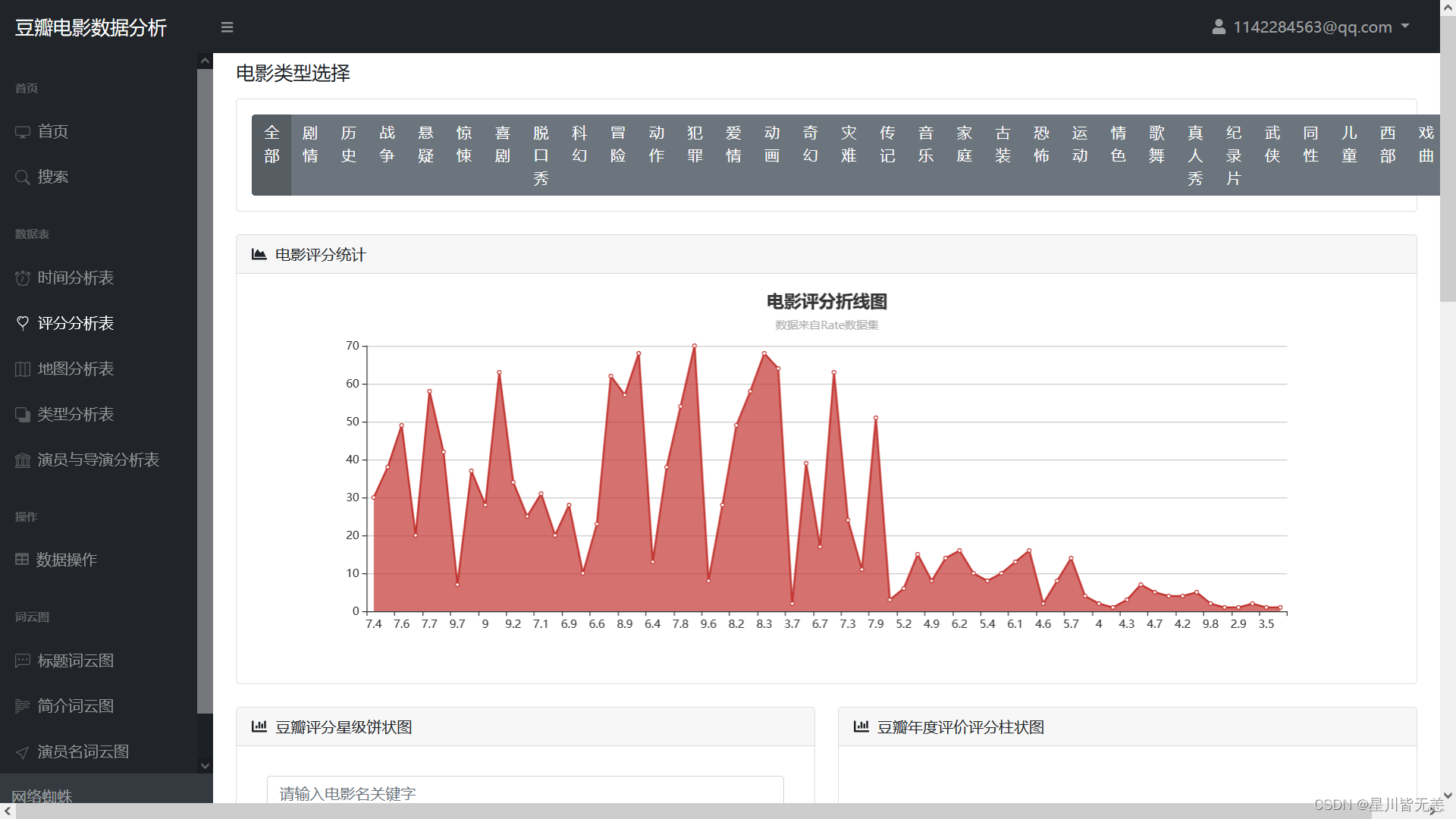
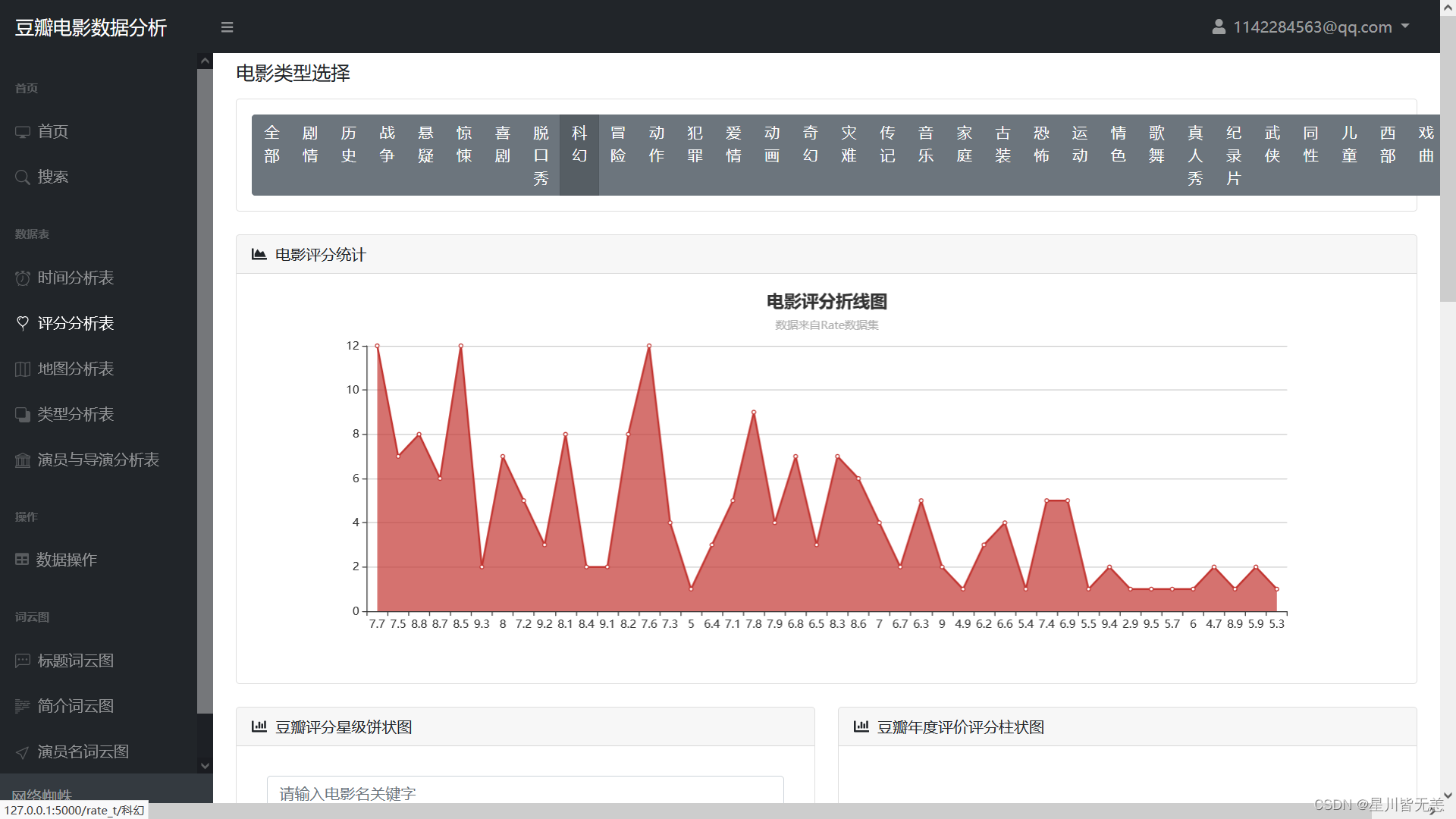
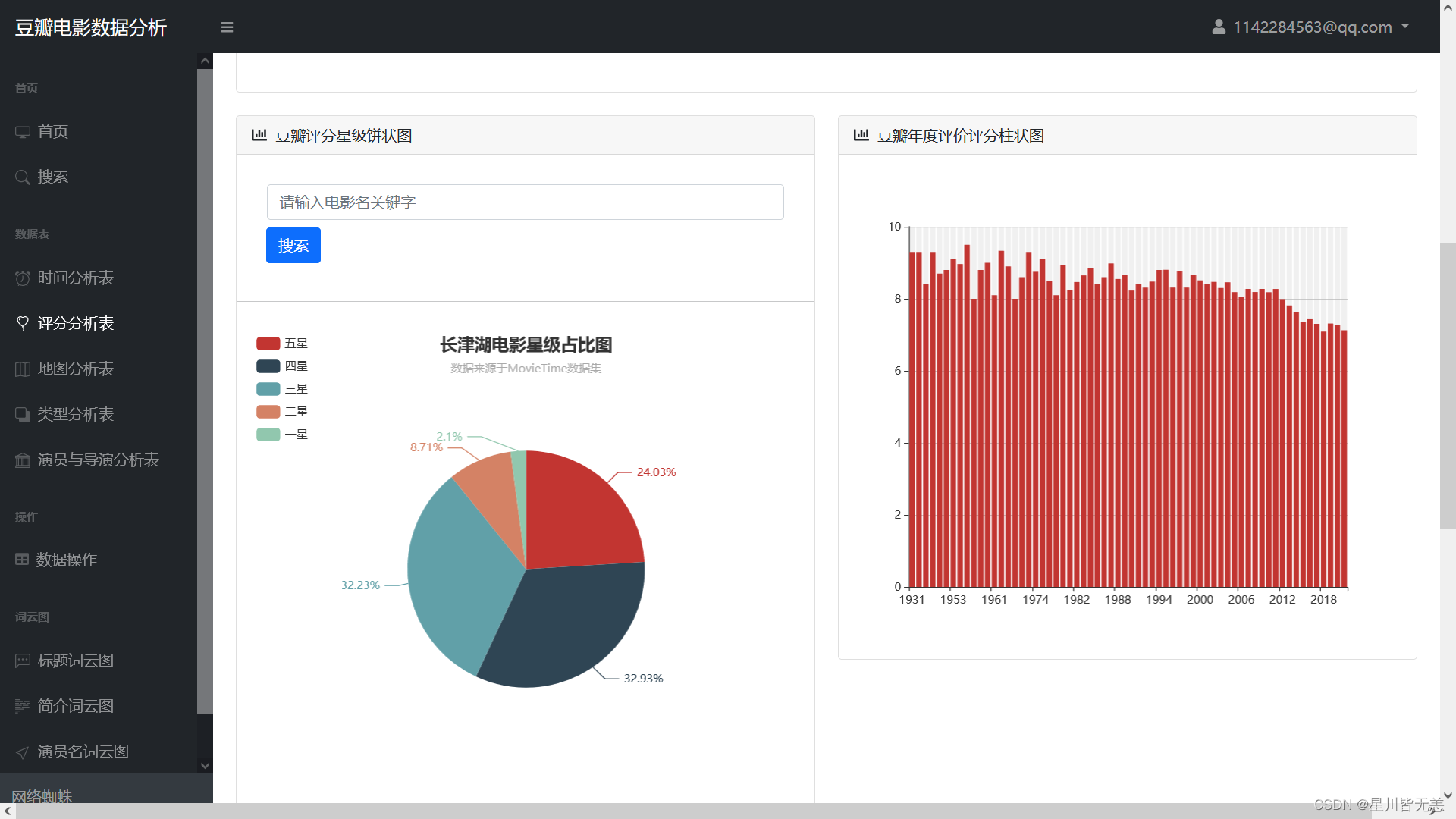
Douban Rating Star Pie Chart, Douban Annual Rating Rating Bar Chart
Douban movie rating distribution chart at home and abroad
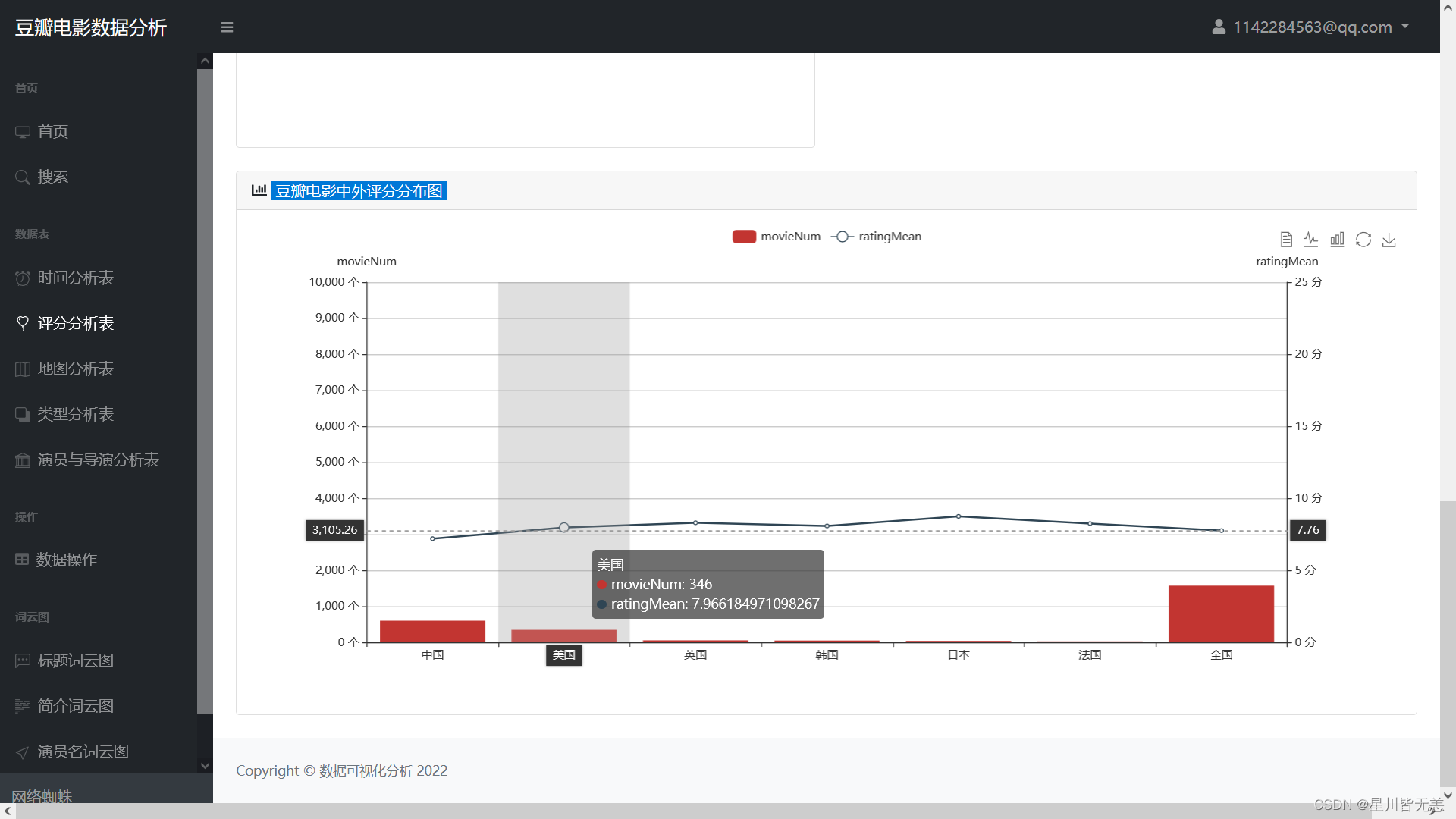
Data view switch
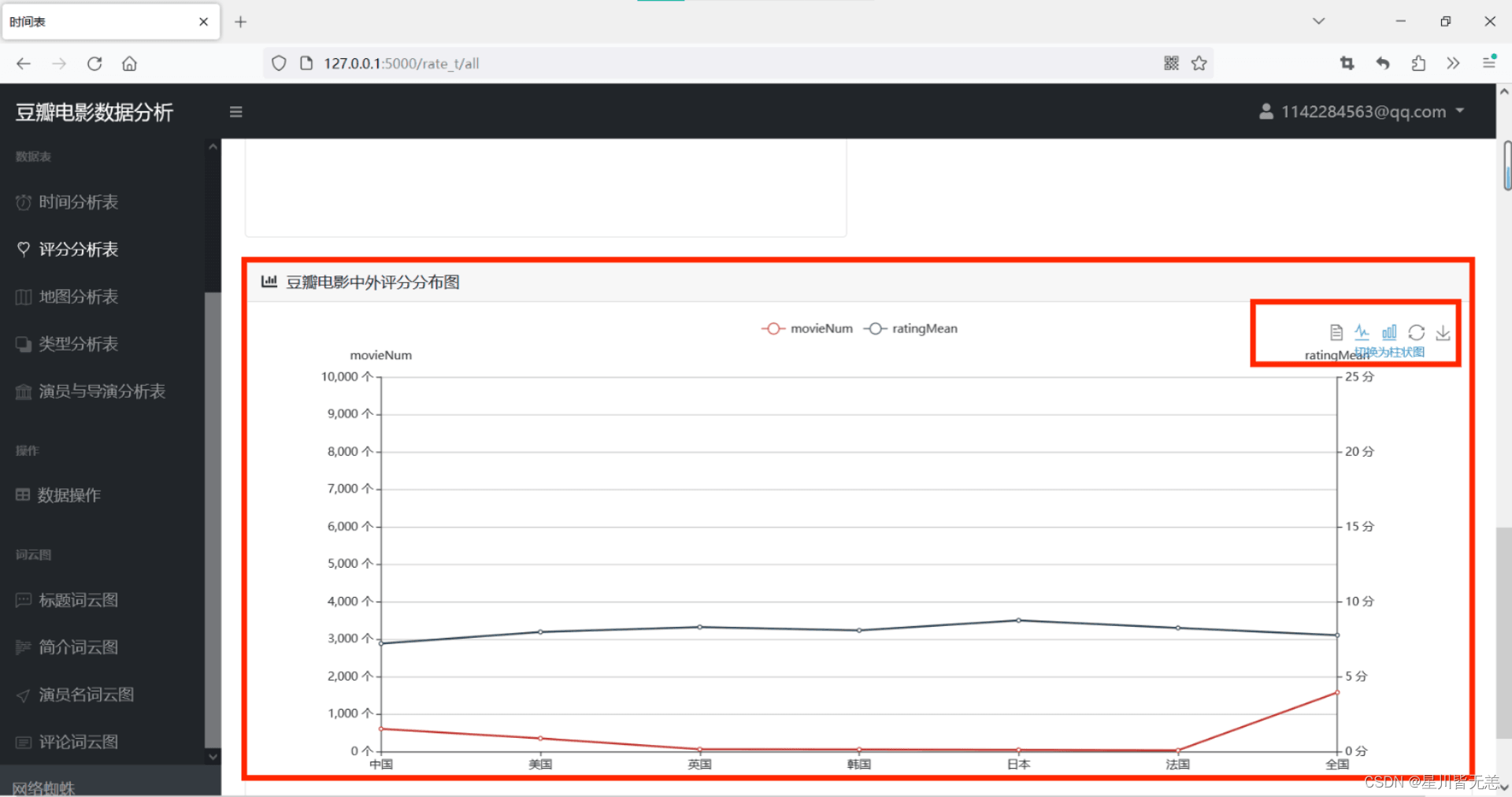
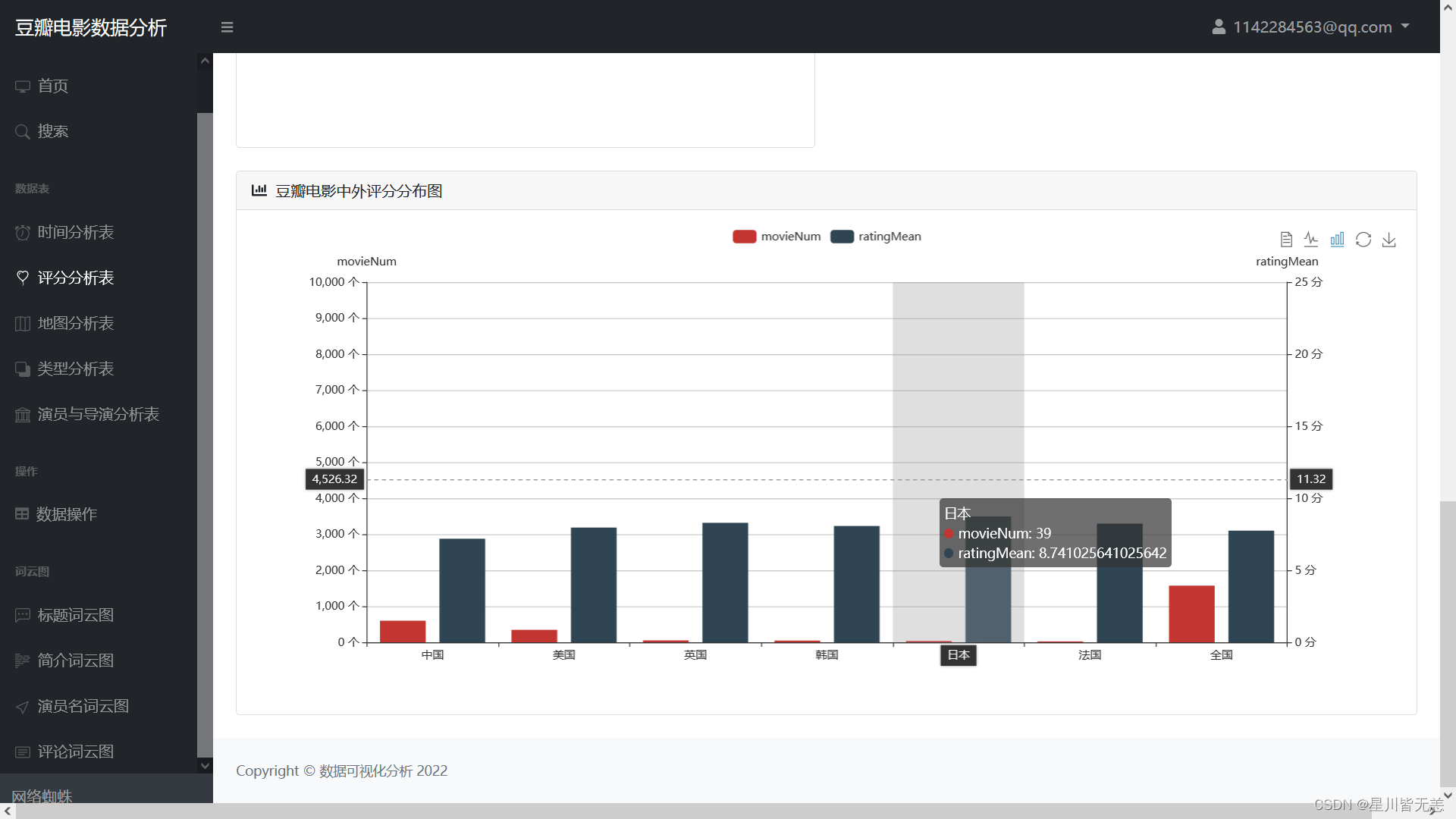
Statistical map of movie shooting locations
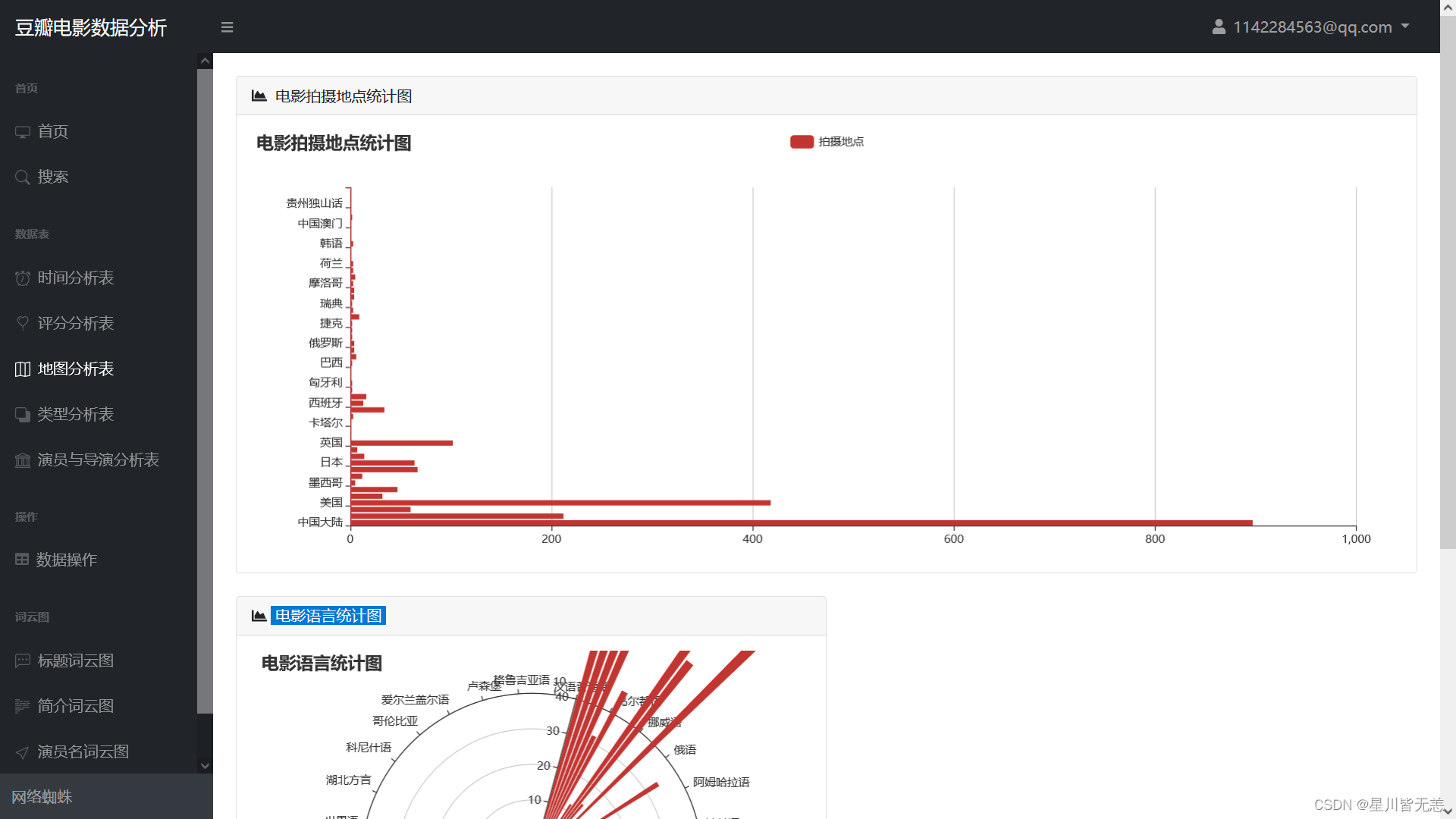
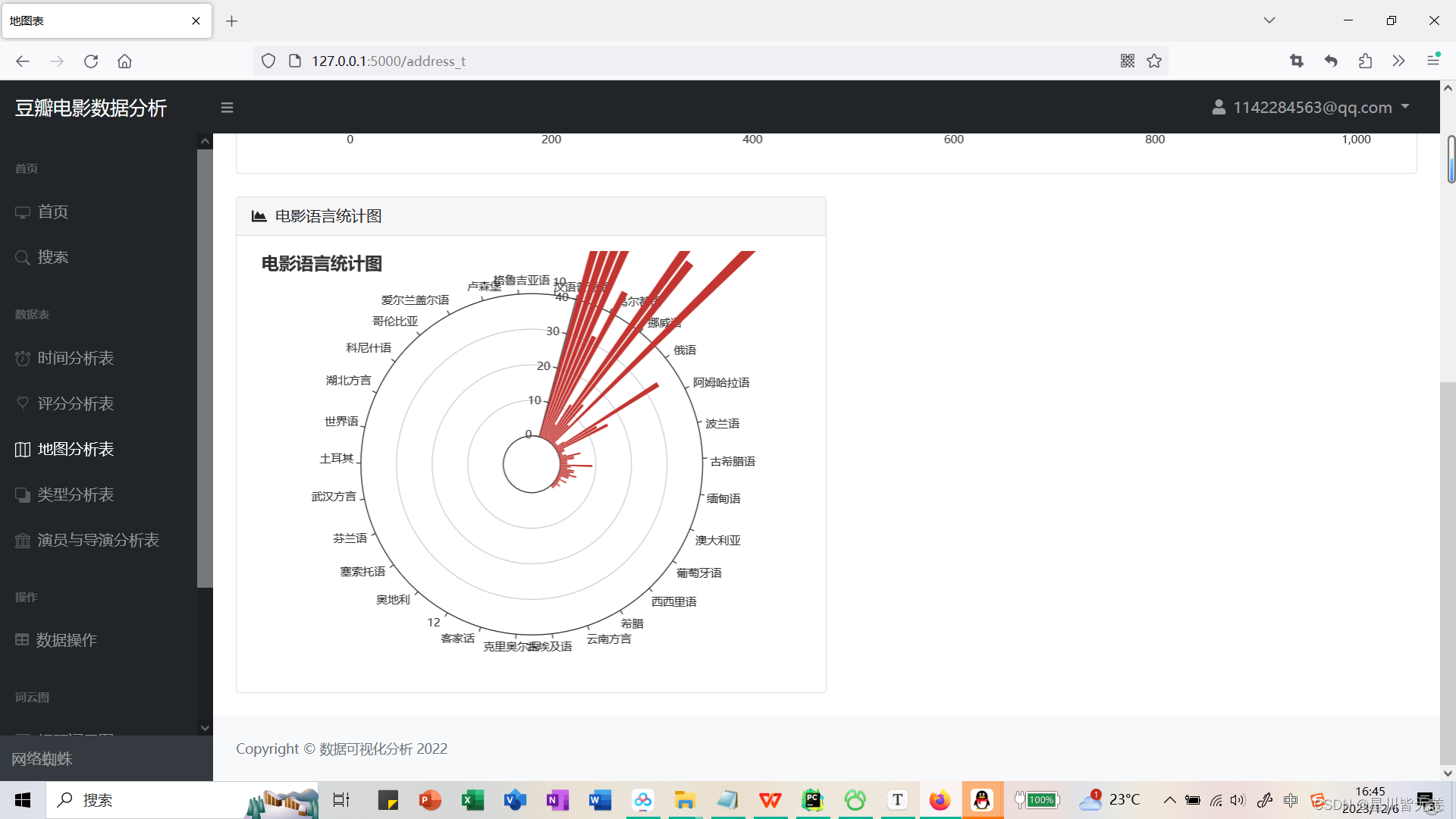
Movie language statistics chart
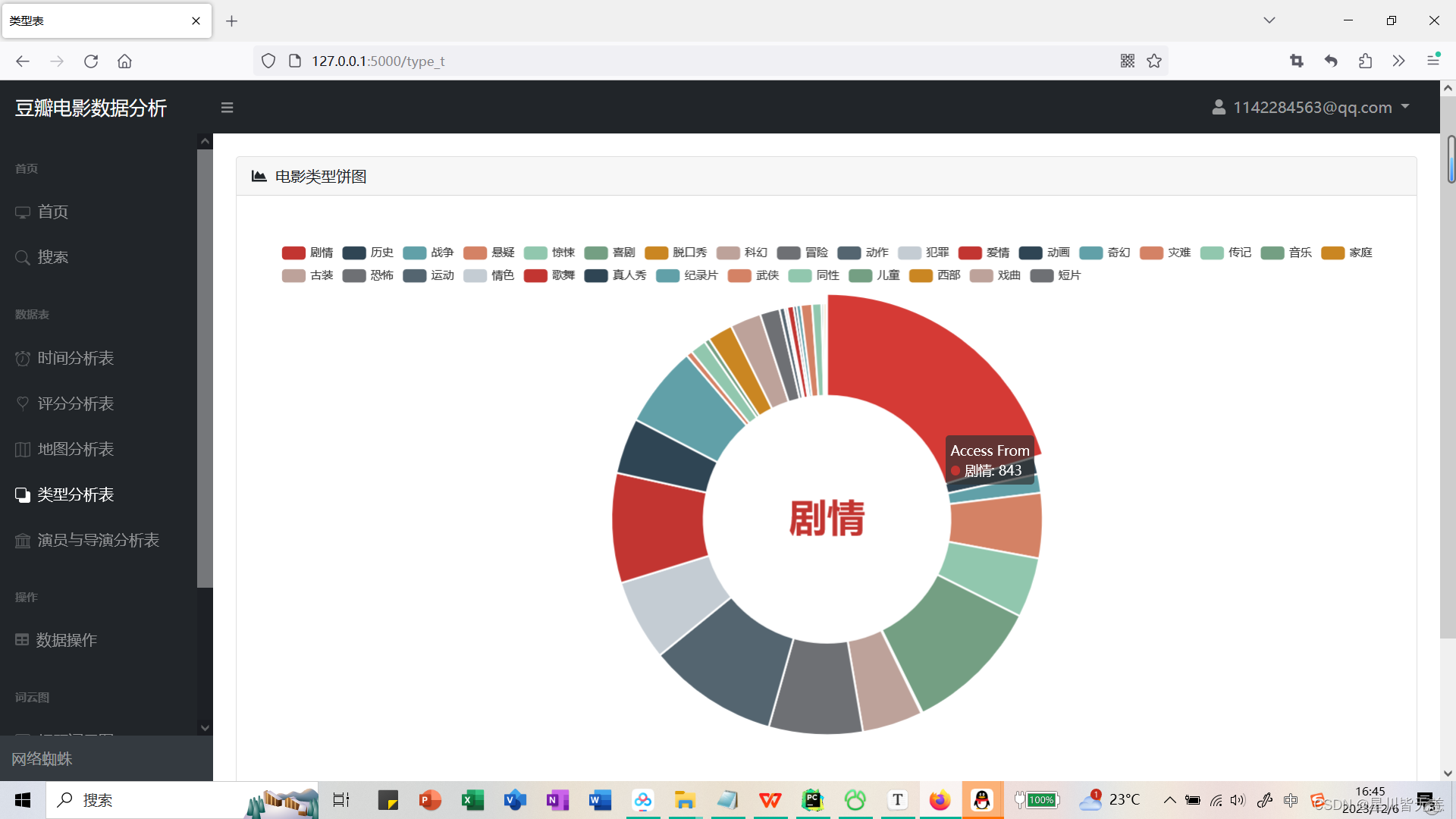
Movie Genre Pie Chart
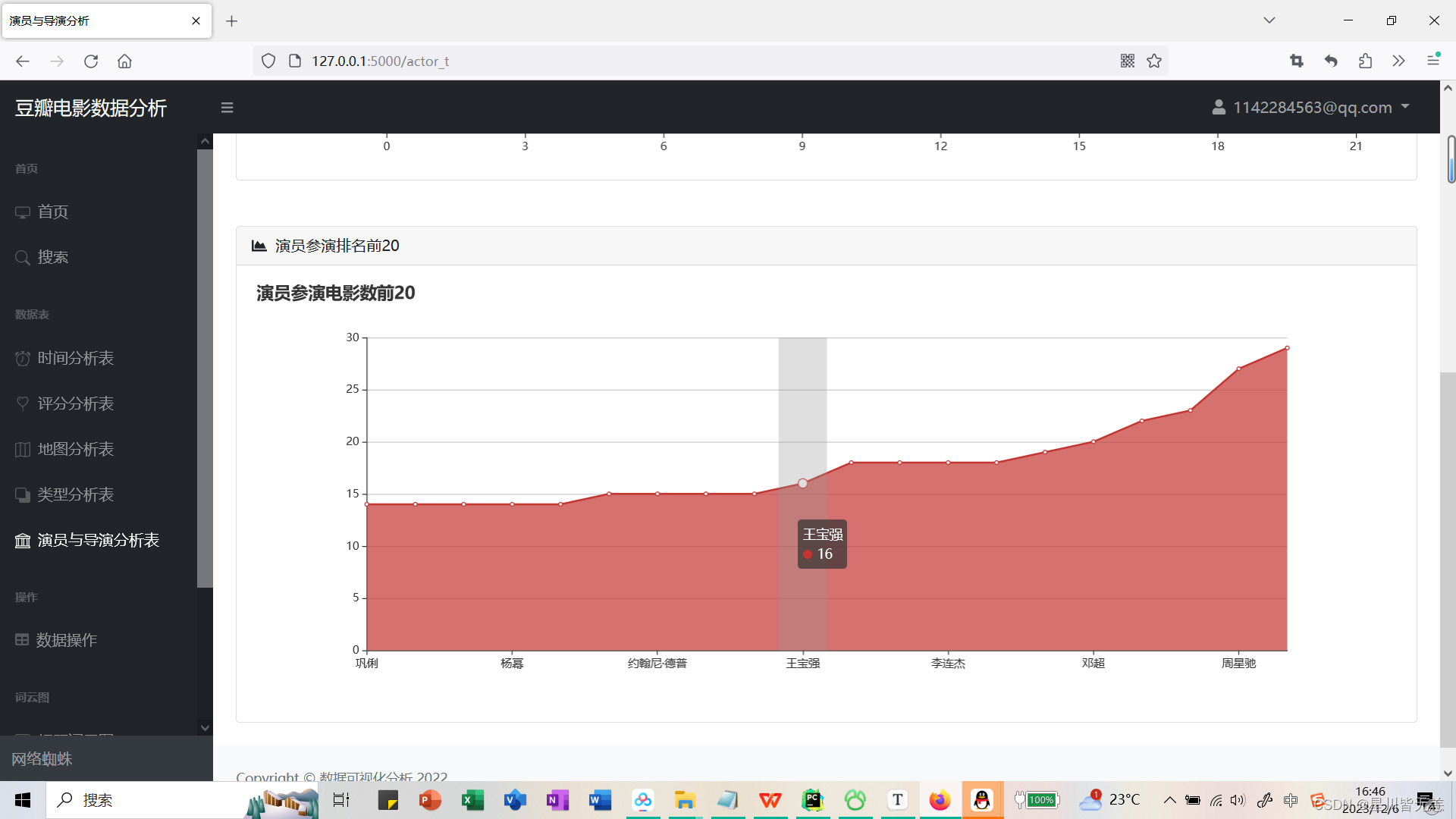
Top 20 directors by number of works

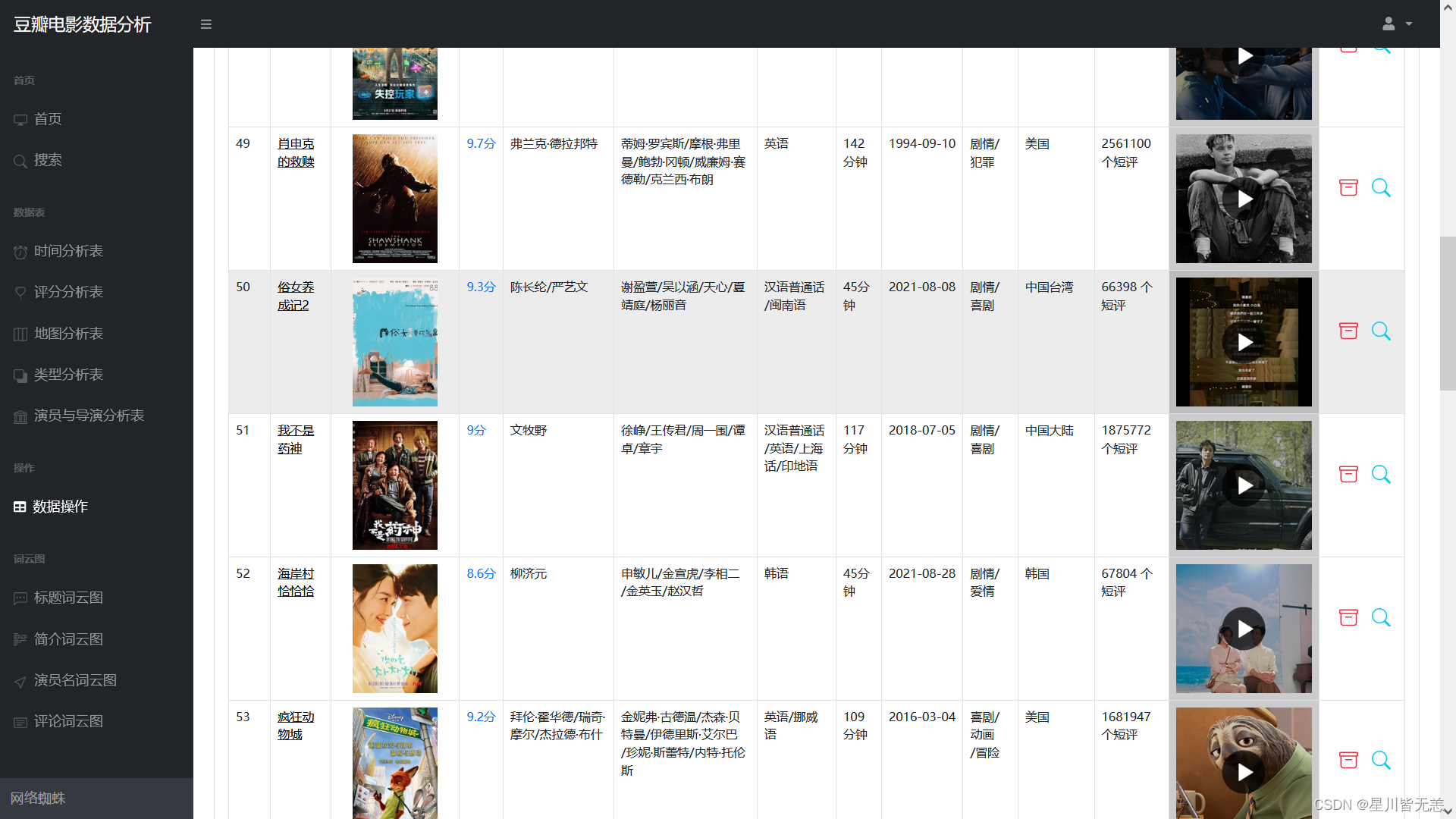
Data table operations
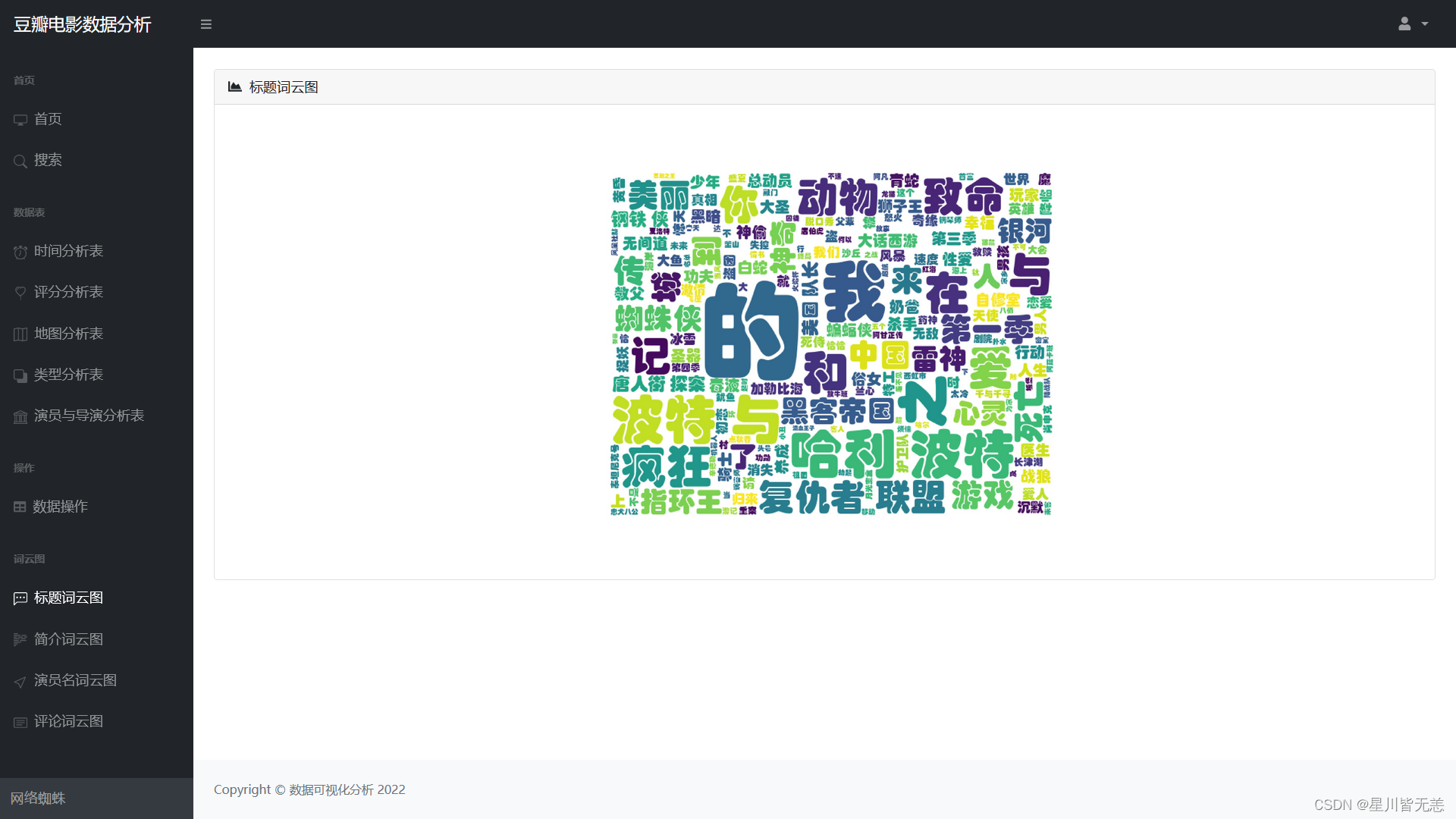
Title word cloud chart
Introduction word cloud chart
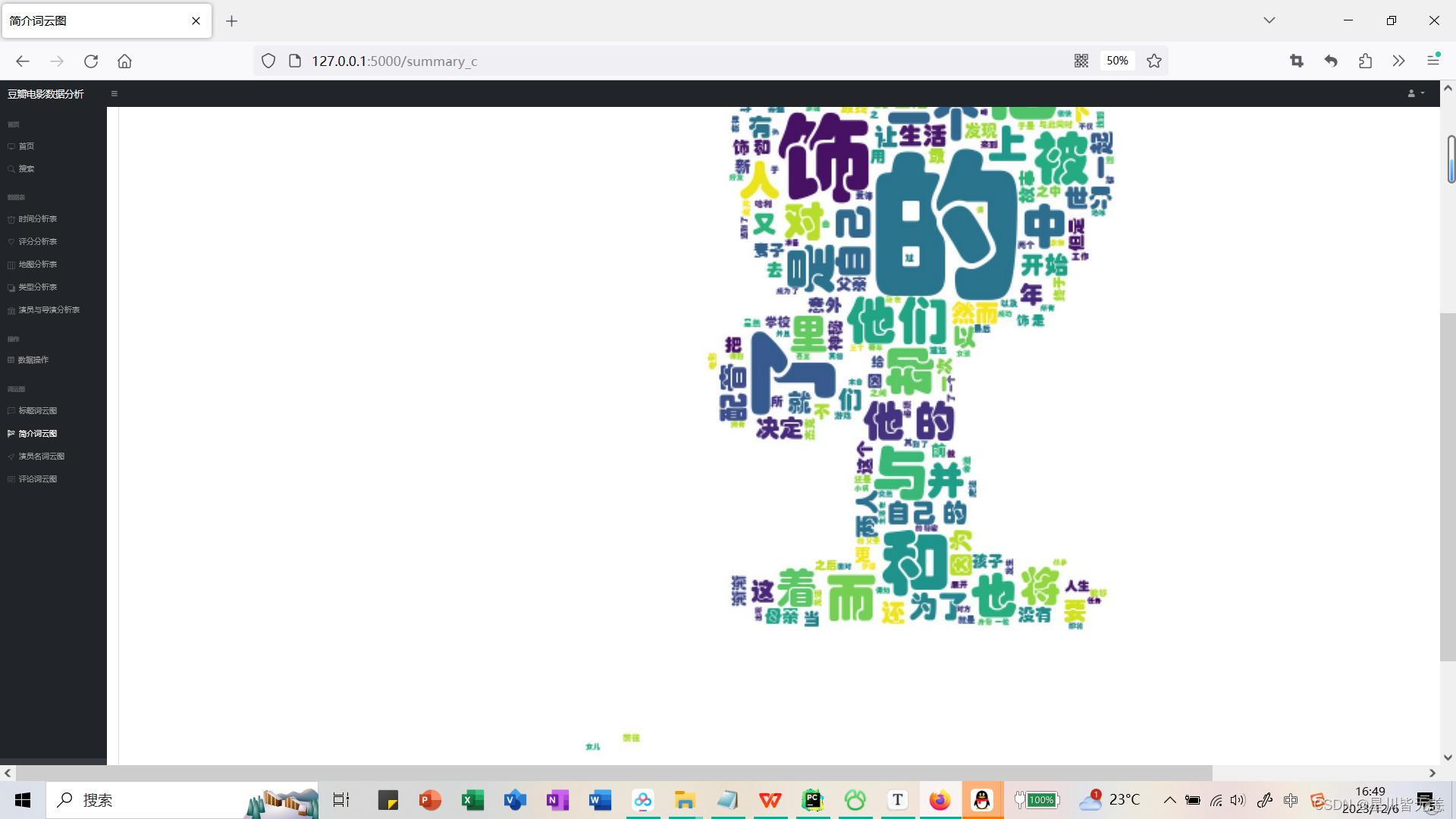
s4XV8qh-1701860368769)
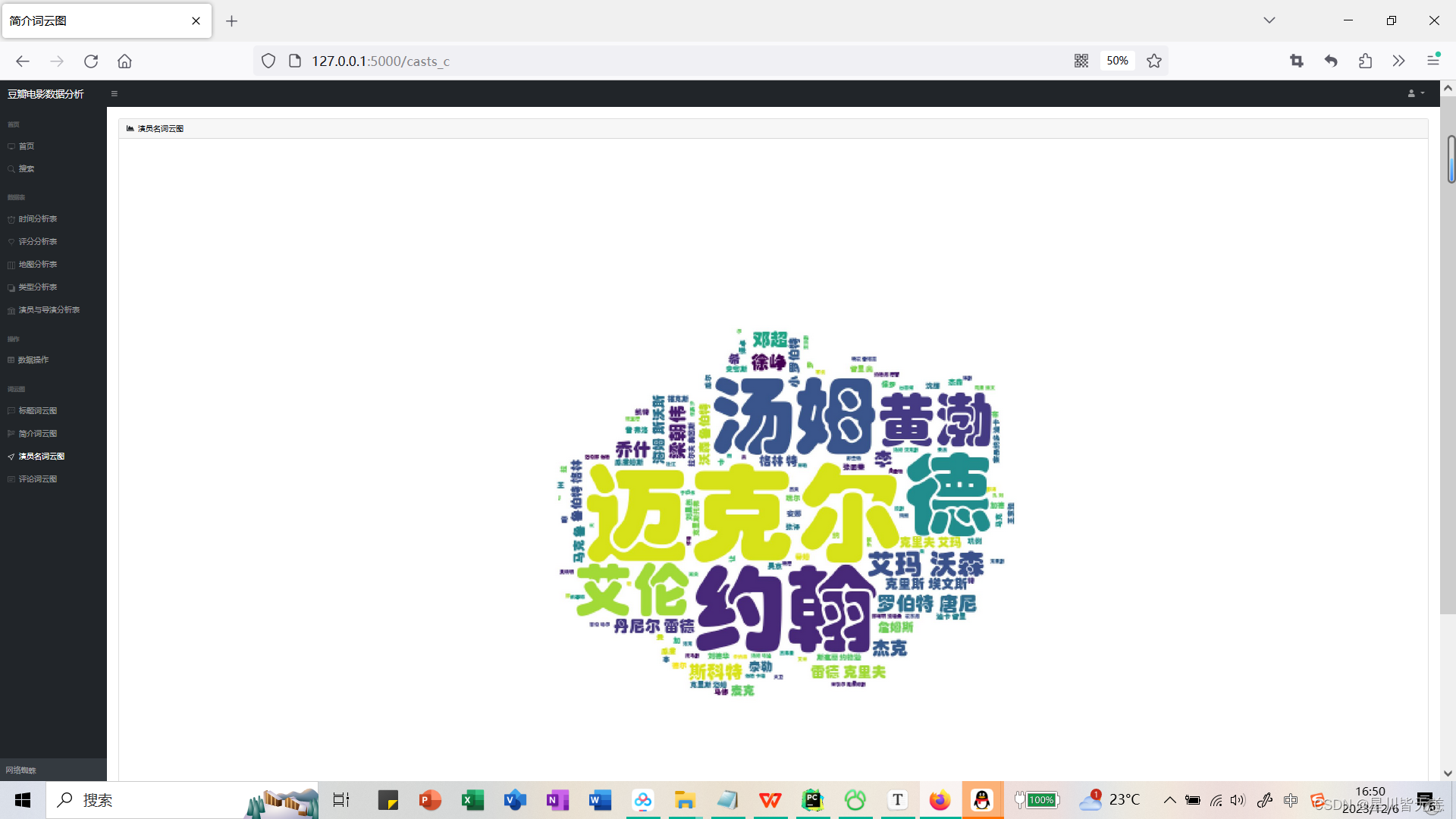
Actor noun cloud chart
Comments word cloud
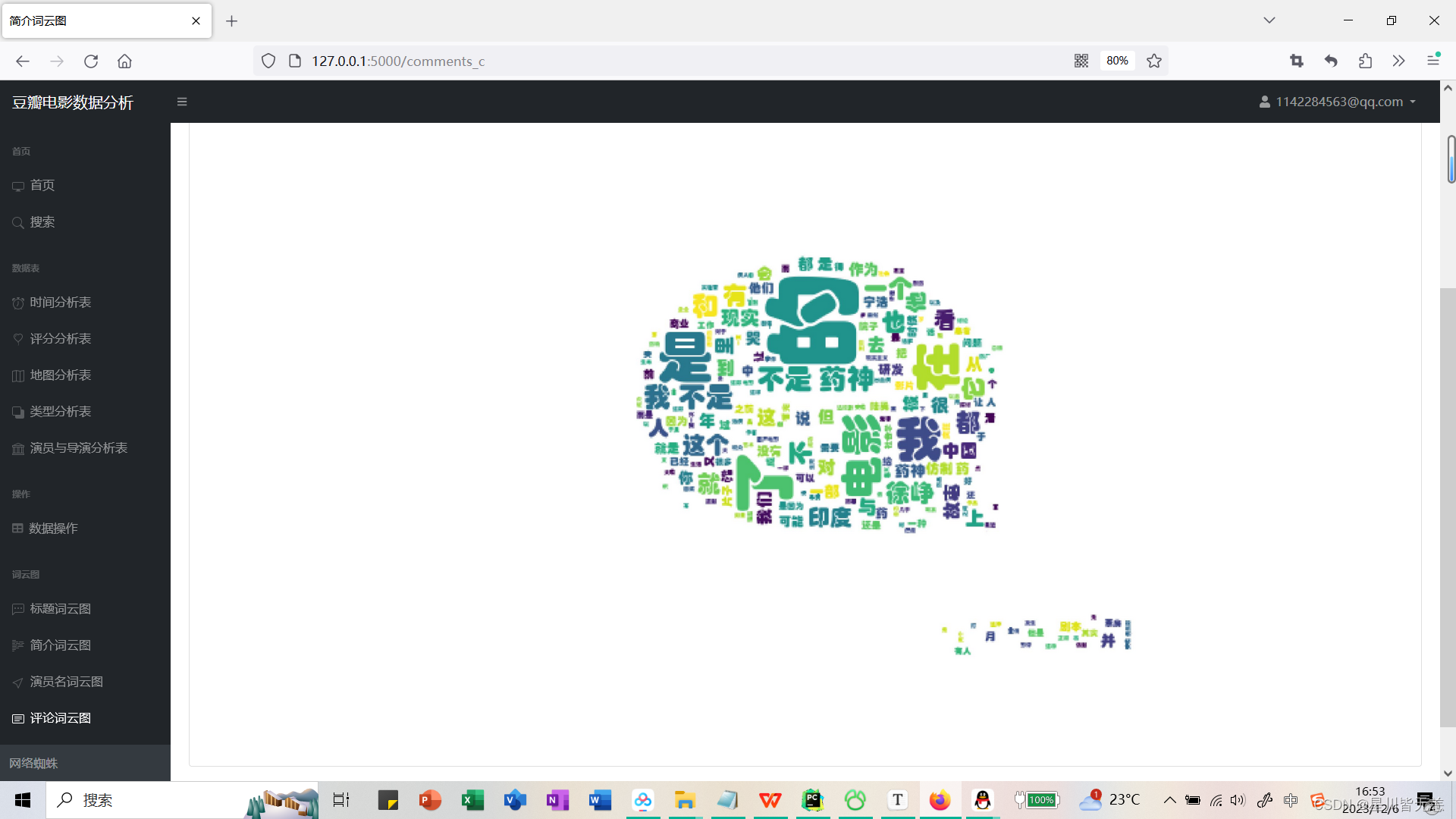
If you need more information/business cooperation/communication and discussion, you can add your personal business card below. Thank you for your like and support!
If I have time and energy, I will share more high-quality content about the field of big data later . If you like it, you can like it, follow it and collect it. Thank you for your like and support!