With feelings and dry goods, WeChat search [Desolate Ancient Legend] to pay attention to this different programmer.
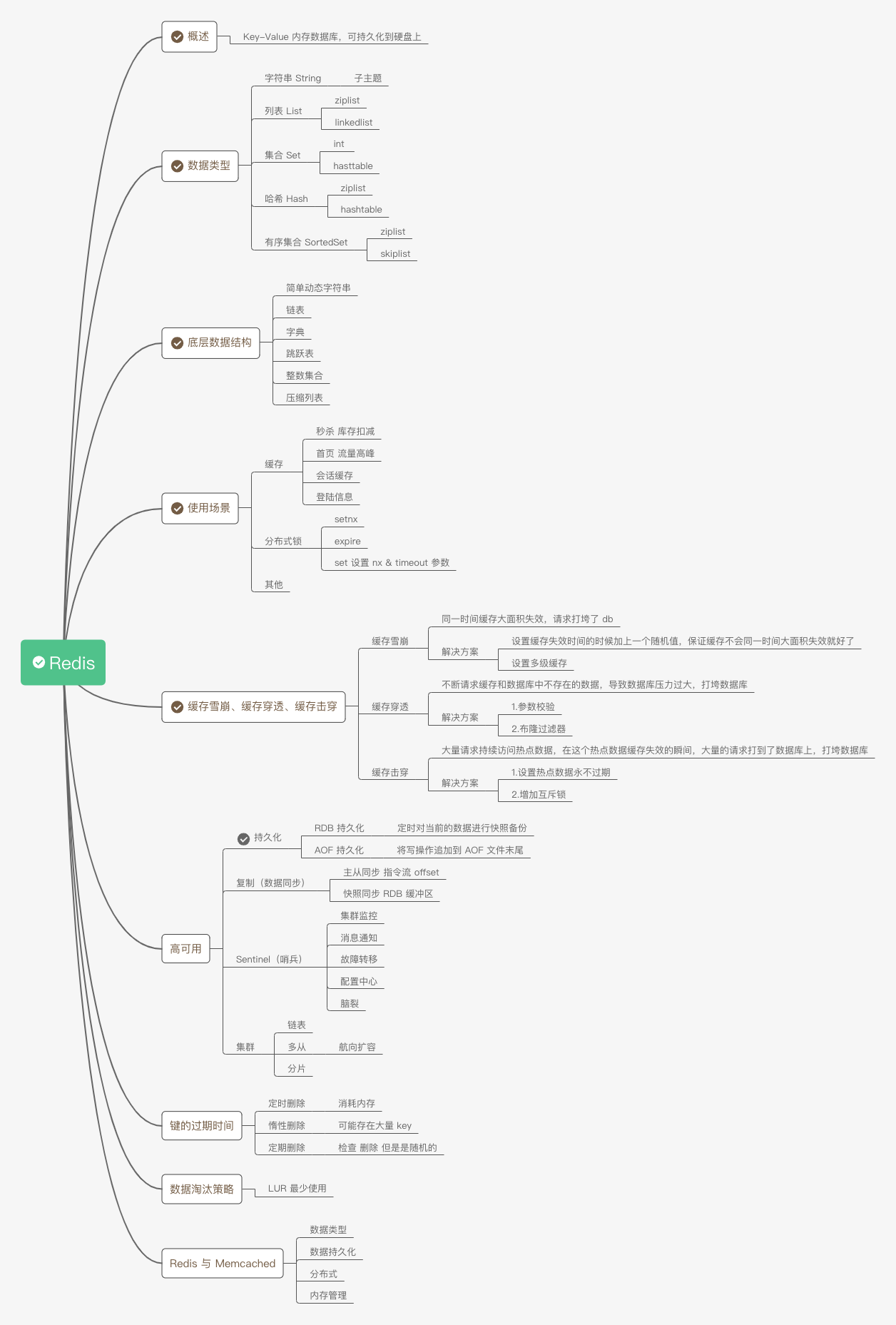
overview
Redis is a key-value in-memory database that can be persisted to disk. The key type can only be a string, but the value type can be a string, list, hash table, set, or ordered set.
type of data
There are five data types in Redis, namely: string, list, hash table, set, and ordered set.
There are 8 encodings (underlying implementations) of Redis, namely: integers of type long, simple dynamic strings encoded by embstr, simple dynamic strings, dictionaries, double-ended linked lists, compressed lists, integer sets, jump lists, and dictionaries.
string

The encoding of a string object can be int, raw or embstr.
If a string object stores an integer value, and this integer value can be represented by the long type, then the string object will store the integer value in the ptr attribute of the string object structure (convert void* to long), and Sets the encoding of a string object to int.
If the string object holds a string value, and the length of the string value is greater than 39 bytes, then the string object will use a simple dynamic string (SDS) to save the string value, and encode the object Set to raw.
If the string object stores a string value, and the length of the string value is less than or equal to 39 bytes, then the string object will use embstr encoding to store the string value.
> set hello world
OK
> get hello
"world"
> del hello
(integer) 1
> get hello
(nil)
the list
[External link picture transfer failed, the source site may have an anti-theft link mechanism, it is recommended to save the picture and upload it directly (img-xhOv3PHP-1603168774635)(https://raw.githubusercontent.com/haxianhe/pic/master/image/20200513150726 .png)]
The encoding of the list object can be ziplist or linkedlist.
The ziplist-encoded list object uses a compressed list as the underlying implementation, and each compressed list node holds a list element.
The list object encoded by linkedlist uses a double-ended linked list as the underlying implementation. Each double-ended linked list node stores a string object, and each string object stores a list element.
> rpush list-key item
(integer) 1
> rpush list-key item2
(integer) 2
> rpush list-key item
(integer) 3
> lrange list-key 0 -1
1) "item"
2) "item2"
3) "item"
> lindex list-key 1
"item2"
> lpop list-key
"item"
> lrange list-key 0 -1
1) "item2"
2) "item"
gather
[External link picture transfer failed, the source site may have an anti-theft link mechanism, it is recommended to save the picture and upload it directly (img-YecB5kUU-1603168774637)(https://raw.githubusercontent.com/haxianhe/pic/master/image/20200513161259 .png)]
The encoding of collection objects can be intset or hashtable.
intset-encoded collection objects use integer collections as the underlying implementation.
The hashtable-encoded collection object uses a dictionary as the underlying implementation. Each key of the dictionary is a string object, and each string object contains a collection element, while the values of the dictionary are all set to NULL.
> sadd set-key item
(integer) 1
> sadd set-key item2
(integer) 1
> sadd set-key item3
(integer) 1
> sadd set-key item
(integer) 0
> smembers set-key
1) "item"
2) "item2"
3) "item3"
> sismember set-key item4
(integer) 0
> sismember set-key item
(integer) 1
> srem set-key item2
(integer) 1
> srem set-key item2
(integer) 0
> smembers set-key
1) "item"
2) "item3"
hash

The encoding of the hash object can be ziplist or hashtable.
The hash object encoded by ziplist uses a compressed list as the underlying implementation. Whenever there is a new key-value pair to be added to the hash object, the program will first push the compressed list node that holds the key to the end of the compressed list, and then Push the compressed list node that holds the value to the end of the compressed list.
The hash object encoded by hashtable uses a dictionary as the underlying implementation, and each key-value pair in the hash object is stored in a dictionary key-value pair.
> hset hash-key sub-key1 value1
(integer) 1
> hset hash-key sub-key2 value2
(integer) 1
> hset hash-key sub-key1 value1
(integer) 0
> hgetall hash-key
1) "sub-key1"
2) "value1"
3) "sub-key2"
4) "value2"
> hdel hash-key sub-key2
(integer) 1
> hdel hash-key sub-key2
(integer) 0
> hget hash-key sub-key1
"value1"
> hgetall hash-key
1) "sub-key1"
2) "value1"
ordered set
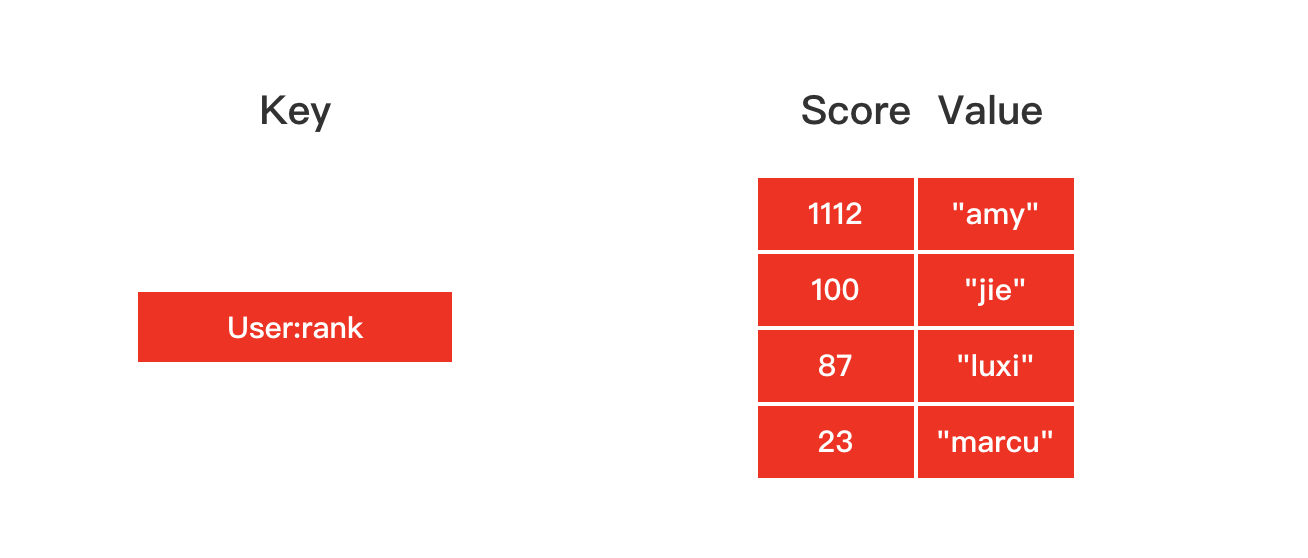
The encoding of an ordered collection object can be ziplist or skiplist.
The ordered collection object encoded by ziplist uses a compressed list as the underlying implementation. Each collection element is saved by two compressed list nodes next to each other. The first node saves the members of the element, and the second node saves the score of the element.
The ordered collection object encoded by skiplist uses the zset structure as the underlying implementation, and a zset structure simultaneously contains a dictionary and a skip list.
> zadd zset-key 728 member1
(integer) 1
> zadd zset-key 982 member0
(integer) 1
> zadd zset-key 982 member0
(integer) 0
> zrange zset-key 0 -1 withscores
1) "member1"
2) "728"
3) "member0"
4) "982"
> zrangebyscore zset-key 0 800 withscores
1) "member1"
2) "728"
> zrem zset-key member1
(integer) 1
> zrem zset-key member1
(integer) 0
> zrange zset-key 0 -1 withscores
1) "member0"
2) "982"
underlying data structure
simple dynamic string
struct sdshdr {
// 记录 buf 数组中已使用字节的数量
// 等于 SDS 所保存字符串的长度
int len;
// 记录 buf 数组中未使用字节的数量
int free;
// 字节数组,用于保存字符串
char buf[];
};
Figure 2-1 shows an example SDS:
- The value of the free attribute is 0, which means that this SDS has not allocated any unused space.
- The value of the len attribute is 5, which means that this SDS saves a five-byte character string.
- The buf attribute is an array of char type. The first five bytes of the array store five characters 'R', 'e', 'd', 'i', and 's' respectively, while the last byte stores Null character '\0'.
[External link picture transfer failed, the source site may have an anti-theft link mechanism, it is recommended to save the picture and upload it directly (img-ax80qTIF-1603168774641)(https://raw.githubusercontent.com/haxianhe/pic/master/image/20200506153334 .png)]
linked list
Each linked list node is represented by an adlist.h/listNode structure:
typedef struct listNode {
// 前置节点
struct listNode *prev;
// 后置节点
struct listNode *next;
// 节点的值
void *value;
} listNode;
Multiple listNodes can form a double-ended linked list through prev and next pointers, as shown in Figure 3-1.

The characteristics of Redis' linked list implementation can be summarized as follows:
- Double-ended: Linked list nodes have prev and next pointers, and the complexity of obtaining a node's pre-node and post-node is O(1).
- Acyclic: The prev pointer of the head node and the next pointer of the tail node both point to NULL, and the access to the linked list ends at NULL.
- With head pointer and tail pointer: Through the head pointer and tail pointer of the list structure, the complexity of the program to obtain the head node and tail node of the linked list is O(1).
- With linked list length counter: The program uses the len attribute of the list structure to count the linked list nodes held by the list, and the complexity of the program to obtain the number of nodes in the linked list is O(1).
- Polymorphism: Linked list nodes use void* pointers to store node values, and can set type-specific functions for node values through the dup, free, and match attributes of the list structure, so linked lists can be used to store various types of values.
dictionary
dicttht is a hash table structure that uses the zipper method to resolve hash collisions.
/* This is our hash table structure. Every dictionary has two of this as we
* implement incremental rehashing, for the old to the new table. */
typedef struct dictht {
dictEntry **table;
unsigned long size;
unsigned long sizemask;
unsigned long used;
} dictht;
typedef struct dictEntry {
void *key;
union {
void *val;
uint64_t u64;
int64_t s64;
double d;
} v;
struct dictEntry *next;
} dictEntry;
The dictionary dict of Redis contains two hash tables dicttht, which is for the convenience of rehash operation. When expanding, rehash the key-value pairs on one of the dictts to the other dicttht, release the space and exchange the roles of the two dictthts after completion.
typedef struct dict {
dictType *type;
void *privdata;
dictht ht[2];
long rehashidx; /* rehashing not in progress if rehashidx == -1 */
unsigned long iterators; /* number of iterators currently running */
} dict;
The rehash operation is not completed at one time, but in a gradual manner, which is to avoid excessive burden on the server by performing too many rehash operations at one time.
Progressive rehash is done by recording the rehashidx of the dict, which starts at 0 and increments each rehash. For example, in a rehash, you need to rehash dict[0] to dict[1], this time you will rehash the key-value pairs of table[rehashidx] on dict[0] to dict[1], and the table [rehashidx] points to null and makes rehashidx++.
During rehash, a progressive rehash is performed each time an add, delete, lookup, or update operation is performed on the dictionary.
The use of progressive rehash will cause the data in the dictionary to be scattered on two dictthts, so the lookup operation on the dictionary also needs to be performed in the corresponding dicttht.
/* Performs N steps of incremental rehashing. Returns 1 if there are still
* keys to move from the old to the new hash table, otherwise 0 is returned.
*
* Note that a rehashing step consists in moving a bucket (that may have more
* than one key as we use chaining) from the old to the new hash table, however
* since part of the hash table may be composed of empty spaces, it is not
* guaranteed that this function will rehash even a single bucket, since it
* will visit at max N*10 empty buckets in total, otherwise the amount of
* work it does would be unbound and the function may block for a long time. */
int dictRehash(dict *d, int n) {
int empty_visits = n * 10; /* Max number of empty buckets to visit. */
if (!dictIsRehashing(d)) return 0;
while (n-- && d->ht[0].used != 0) {
dictEntry *de, *nextde;
/* Note that rehashidx can't overflow as we are sure there are more
* elements because ht[0].used != 0 */
assert(d->ht[0].size > (unsigned long) d->rehashidx);
while (d->ht[0].table[d->rehashidx] == NULL) {
d->rehashidx++;
if (--empty_visits == 0) return 1;
}
de = d->ht[0].table[d->rehashidx];
/* Move all the keys in this bucket from the old to the new hash HT */
while (de) {
uint64_t h;
nextde = de->next;
/* Get the index in the new hash table */
h = dictHashKey(d, de->key) & d->ht[1].sizemask;
de->next = d->ht[1].table[h];
d->ht[1].table[h] = de;
d->ht[0].used--;
d->ht[1].used++;
de = nextde;
}
d->ht[0].table[d->rehashidx] = NULL;
d->rehashidx++;
}
/* Check if we already rehashed the whole table... */
if (d->ht[0].used == 0) {
zfree(d->ht[0].table);
d->ht[0] = d->ht[1];
_dictReset(&d->ht[1]);
d->rehashidx = -1;
return 0;
}
/* More to rehash... */
return 1;
}
jump table
It is one of the underlying implementations of sorted collections.
The jump table is implemented based on a multi-pointer ordered linked list, which can be regarded as multiple ordered linked lists.
[External link picture transfer failed, the source site may have an anti-theft link mechanism, it is recommended to save the picture and upload it directly (img-kflaiIwR-1603168774642)(https://raw.githubusercontent.com/haxianhe/pic/master/image/20200506154158 .png)]
When searching, start searching from the upper layer pointer, find the corresponding interval, and then go to the next layer to search. The figure below demonstrates the process of finding 22.
[External link picture transfer failed, the source site may have an anti-theft link mechanism, it is recommended to save the picture and upload it directly (img-ucObpoFV-1603168774643)(https://raw.githubusercontent.com/haxianhe/pic/master/image/20200506154222 .png)]
Compared with balanced trees such as red-black trees, jump tables have the following advantages:
- The insertion speed is very fast, because no operations such as rotation are required to maintain balance;
- easier to implement;
- Support for lock-free operations.
set of integers
Integer set (intset) is an abstract data structure used by Redis to store integer values. It can store integer values of type int16_t, int32_t or int64_t, and guarantees that there will be no duplicate elements in the set.
Each intset.h/intset structure represents a set of integers:
typedef struct intset {
// 编码方式
uint32_t encoding;
// 集合包含的元素数量
uint32_t length;
// 保存元素的数组
int8_t contents[];
} intset;
Figure 6-1 shows an example set of integers:
- The value of the encoding attribute is INTSET_ENC_INT16, which means that the underlying implementation of the integer set is an array of type int16_t, and the set stores all integer values of type int16_t.
- The value of the length attribute is 5, indicating that the integer collection contains five elements.
- The contents array holds the five elements in the collection in ascending order.
Since each collection element is an integer value of type int16_t, the size of the contents array is equal to sizeof(int16_t) * 5 = 16 * 5 = 80 bits.
[External link picture transfer failed, the source site may have an anti-theft link mechanism, it is recommended to save the picture and upload it directly (img-I3RXVvul-1603168774644)(https://raw.githubusercontent.com/haxianhe/pic/master/image/20200506154613 .png)]
compressed list
The compressed list is developed by Redis to save memory. It is a sequential data structure composed of a series of specially coded contiguous memory blocks.
A compressed list can contain any number of nodes (entries), and each node can hold a byte array or an integer value.
Figure 7-1 shows the various components of the compression list, and Table 7-1 records the type, length, and purpose of each component.
[External link picture transfer failed, the source site may have an anti-theft link mechanism, it is recommended to save the picture and upload it directly (img-SiOPfejX-1603168774644)(https://raw.githubusercontent.com/haxianhe/pic/master/image/20200506154718 .png)]
Figure 7-2 shows an example of a compressed list:
- The value of the list zlbytes attribute is 0x50 (80 in decimal), indicating that the total length of the compressed list is 80 bytes.
- The value of the zltail attribute of the list is 0x3c (decimal 60), which means that if we have a pointer p pointing to the start address of the compressed list, then we can calculate the address of the tail node entry3 by adding the offset 60 to the pointer p .
- The value of the list zllen attribute is 0x3 (decimal 3), indicating that the compressed list contains three nodes.
[External link picture transfer failed, the source site may have an anti-theft link mechanism, it is recommended to save the picture and upload it directly (img-zalMscrT-1603168774645)(https://raw.githubusercontent.com/haxianhe/pic/master/image/20200506154848 .png)]
scenes to be used
cache
Put the hotspot data in the memory, set the maximum usage of the memory and the elimination strategy to ensure the hit rate of the cache.
Lightning deduction inventory
Home page traffic peak
session cache
Redis can be used to uniformly store session information of multiple application servers.
When the application server no longer stores the user's session information, it no longer has state, and a user can request any application server, which makes it easier to achieve high availability and scalability.
login information
Redis can be used to cache user login information.
distributed lock
In a distributed scenario, locks in a stand-alone environment cannot be used to synchronize processes on multiple nodes.
You can use the SETNX command that comes with Redis to implement distributed locks. First use setnx to compete for the lock, and then use expire to add an expiration time to the lock to prevent the lock from being forgotten to be released.
What happens if the process unexpectedly crashes or needs to be restarted for maintenance before executing expire after setnx?
You can set nx and timeout parameters for set, and combine setnx and expire into one command.
other
Set can implement operations such as intersection and union, so as to realize functions such as mutual friends.
ZSet can realize orderly operations, so as to realize functions such as leaderboards.
Cache avalanche, cache penetration, cache breakdown
cache avalanche
At the same time, the cache fails in a large area, and the request destroys the DB
solution:
- Add a random value when setting the cache time perspective to ensure that the cache will not fail in large areas at the same time
- Set up multi-level caching
cache penetration
Constantly requesting data that does not exist in the cache and database, resulting in excessive pressure on the database and breaking the database
solution:
- Parameter check
- bloom filter
cache breakdown
A large number of requests continue to access hot data. At the moment when the hot data cache fails, a large number of requests hit the database, breaking the database
solution;
- Set hotspot data to never expire
- add mutex
high availability
Persistence
Redis is an in-memory database. In order to ensure that the data will not be lost after a power failure, the data in the memory needs to be persisted to the hard disk.
The RDB persistence performs point-in-time snapshots of your dataset at specified intervals.
The AOF persistence logs every write operation received by the server, that will be played again at server startup, reconstructing the original dataset. Commands are logged using the same format as the Redis protocol itself, in an append-only fashion. Redis is able to rewrite the log in the background when it gets too big.
RDB persistence
working principle
Redis calls fork() to generate a child process. The child process writes data to a temporary file. When the child process finishes writing the new RDB file, it replaces the old RDB file.
advantage
- RDB is a very compact single-file point-in-time representation of your Redis data. RDB files are perfect for backups. For instance you may want to archive your RDB files every hour for the latest 24 hours, and to save an RDB snapshot every day for 30 days. This allows you to easily restore different versions of the data set in case of disasters.
- RDB is very good for disaster recovery, being a single compact file that can be transferred to far data centers, or onto Amazon S3 (possibly encrypted).
- RDB maximizes Redis performances since the only work the Redis parent process needs to do in order to persist is forking a child that will do all the rest. The parent instance will never perform disk I/O or alike.
- RDB allows faster restarts with big datasets compared to AOF.
RDB persistence is very suitable for backup.
shortcoming
- RDB is NOT good if you need to minimize the chance of data loss in case Redis stops working (for example after a power outage). You can configure different save points where an RDB is produced (for instance after at least five minutes and 100 writes against the data set, but you can have multiple save points). However you’ll usually create an RDB snapshot every five minutes or more, so in case of Redis stopping working without a correct shutdown for any reason you should be prepared to lose the latest minutes of data.
- RDB needs to fork() often in order to persist on disk using a child process. Fork() can be time consuming if the dataset is big, and may result in Redis to stop serving clients for some millisecond or even for one second if the dataset is very big and the CPU performance not great. AOF also needs to fork() but you can tune how often you want to rewrite your logs without any trade-off on durability.
-
In the event of a system failure, data from the last snapshot taken will be lost.
-
RDB uses fork() to generate child processes for data persistence. If the data is relatively large, it may take some time, causing Redis to stop serving for a few milliseconds. If the amount of data is large and the CPU performance is not very good, the time to stop the service may even reach 1 second.
AOF persistence
working principle
Add the write command to the end of the AOF file (Append Only File).
To use AOF persistence, you need to set the synchronization option to ensure that the write command is synchronized to the disk file. This is because writing to a file does not synchronize the content to the disk immediately, but stores it in the buffer first, and then the operating system decides when to synchronize to the disk. There are the following synchronization options:
| options | sync frequency |
|---|---|
| always | Every write command is synchronized |
| everysec | sync every second |
| no | Let the OS decide when to sync |
- The always option will seriously reduce the performance of the server;
- The everysec option is more appropriate, which can ensure that only about one second of data will be lost when the system crashes, and Redis performs synchronization every second with almost no impact on server performance;
- The no option does not improve server performance much, and it also increases the amount of data lost when the system crashes.
As the server write requests increase, the AOF file will become larger and larger. Redis provides a feature to rewrite AOF, which can remove redundant write commands in AOF files.
advantage
- Using AOF Redis is much more durable: you can have different fsync policies: no fsync at all, fsync every second, fsync at every query. With the default policy of fsync every second write performances are still great (fsync is performed using a background thread and the main thread will try hard to perform writes when no fsync is in progress.) but you can only lose one second worth of writes.
- The AOF log is an append only log, so there are no seeks, nor corruption problems if there is a power outage. Even if the log ends with an half-written command for some reason (disk full or other reasons) the redis-check-aof tool is able to fix it easily.
- Redis is able to automatically rewrite the AOF in background when it gets too big. The rewrite is completely safe as while Redis continues appending to the old file, a completely new one is produced with the minimal set of operations needed to create the current data set, and once this second file is ready Redis switches the two and starts appending to the new one.
- AOF contains a log of all the operations one after the other in an easy to understand and parse format. You can even easily export an AOF file. For instance even if you flushed everything for an error using a FLUSHALL command, if no rewrite of the log was performed in the meantime you can still save your data set just stopping the server, removing the latest command, and restarting Redis again.
- Less data lost if data needs to be restored (how much is lost depends on sync strategy)
- When the AOF file is too large, Redis will automatically rewrite it in the background
shortcoming
- AOF files are usually bigger than the equivalent RDB files for the same dataset.
- AOF can be slower than RDB depending on the exact fsync policy. In general with fsync set to every second performance is still very high, and with fsync disabled it should be exactly as fast as RDB even under high load. Still RDB is able to provide more guarantees about the maximum latency even in the case of an huge write load.
- AOF files are larger than RDB files
- AOF persistence is more time-consuming than RDB persistence.
Recommendations
The general indication is that you should use both persistence methods if you want a degree of data safety comparable to what PostgreSQL can provide you.
If you care a lot about your data, but still can live with a few minutes of data loss in case of disasters, you can simply use RDB alone.
There are many users using AOF alone, but we discourage it since to have an RDB snapshot from time to time is a great idea for doing database backups, for faster restarts, and in the event of bugs in the AOF engine.
Note: for all these reasons we’ll likely end up unifying AOF and RDB into a single persistence model in the future (long term plan).
- If you want to ensure the highest data security, use both
- If you can accept the loss of a few minutes of data, you only need to use RDB for persistence
- It is not recommended to use AOF alone for persistence
References
- Bloom Filters by Example
- Redis Bloom filter actual combat "cache breakdown, avalanche effect"
- Use and Precautions of Redis Bloom Filter
- CS-Notes-redis
- JavaFamily-redis
- Redis Persistence
The article is continuously updated, you can search for "Desolate Ancient Legend" on WeChat to read it as soon as possible.