Can you briefly talk about the classification of indexes?

For example, from the perspective of basic usage:
- Primary key index: InnoDB primary key is the default index. Data columns are not allowed to be repeated or NULL. A table can only have one primary key.
- Unique index: Duplication of data columns is not allowed, NULL values are allowed, and a table allows multiple columns to create unique indexes.
- Ordinary index: Basic index type, no uniqueness restrictions, NULL values allowed.
- Combined index: Multiple column values form an index for combined search, which is more efficient than index merging
Why does using an index speed up queries?
The traditional query method traverses the table in order. No matter how many pieces of data are queried, MySQL needs to traverse the table data from beginning to end.
After we add the index, MySQL generally generates an index file through the BTREE algorithm. When querying the database, we find the index file to traverse, search in the relatively small index data, and then map it to the corresponding data, which can greatly improve the efficiency of the search.
What are the points to note when creating an index?
Although indexes are a powerful tool for SQL performance optimization, index maintenance also requires costs, so when creating indexes, you should also pay attention to:
- Indexes should be built on fields where queries are frequently used
Create an index on the (on) field used for where judgment, order sorting and join.
- The number of indexes should be appropriate
Indexes take up space and need to be maintained when updated.
- Do not create indexes for fields with low distinction, such as gender.
For fields with too low dispersion, the number of scanned rows will be limited.
- Frequently updated values should not be used as primary keys or indexes
Maintaining index files requires costs; it will also lead to page splits and increased IO times.
- Combining indexes put values with high hashability (high discriminability) at the front
In order to satisfy the leftmost prefix matching principle
- Create a composite index instead of modifying a single column index.
A composite index replaces multiple single-column indexes (for single-column indexes, MySQL can basically only use one index, so it is more suitable to use a composite index when multiple condition queries are often used)
- For fields that are too long, use prefix indexes. When the field value is relatively long, indexing will consume a lot of space and the search will be very slow. We can create an index by intercepting the previous part of the field, which is called a prefix index.
- It is not recommended to use unordered values (such as ID cards, UUID) as indexes
When the primary key is uncertain, it will cause frequent splitting of leaf nodes and fragmentation of disk storage.
Under what circumstances will the index fail?
- The query condition contains or, which may cause index failure
- If the field type is a string, the where must be enclosed in quotes, otherwise the index will be invalid due to implicit type conversion.
- like wildcards may cause index failure.
- In the joint index, the condition column in the query is not the first column in the joint index, and the index becomes invalid.
- When using MySQL's built-in function on an index column, the index becomes invalid.
- For operations on indexed columns (such as +, -, *, /), the index becomes invalid.
- When using (!= or < >, not in) on an index field, it may cause index failure.
- Using is null or is not null on index fields may cause index failure.
- The encoding formats of fields associated with left join queries or right join queries are different, which may cause index failure.
- The MySQL optimizer estimates that using a full table scan is faster than using an index, so the index is not used.
What scenarios are indexes not suitable for?
- Tables with relatively small amounts of data are not suitable for indexing
- Fields that are updated frequently are not suitable for indexing
- Fields with low discreteness are not suitable for indexing (such as gender)
Is it better to build more indexes?
of course not.
- Indexes take up disk space
- Although indexes will improve query efficiency, they will reduce the efficiency of updating tables . For example, every time a table is added, deleted, or modified, MySQL must not only save the data, but also save or update the corresponding index file.
Why use B+ tree instead of ordinary binary tree?
You can look at this problem from several dimensions, including whether the query is fast enough, whether the efficiency is stable, how much data is stored, and how many times the disk is searched.
Why not use ordinary binary trees?
Ordinary binary trees are degenerated. If it degenerates into a linked list, it is equivalent to a full table scan. Compared with binary search trees, balanced binary trees have more stable search efficiency and faster overall search speed.
Why not balance a binary tree?
When reading data, it is read from disk to memory. If a data structure like a tree is used as an index, each time you search for data, you need to read a node from the disk, which is a disk block, but a balanced binary tree only stores one key value and data per node. If it is a B+ tree , more node data can be stored, and the height of the tree will also be reduced, so the number of disk reads will be reduced, and the query efficiency will be faster.
Why use B+ tree instead of B tree?
Compared with B-tree, B+ has the following advantages:
- It is a variant of B Tree. It can solve all the problems that B Tree can solve.
Two major problems solved by B Tree: each node stores more keywords; more paths
- Stronger ability to scan databases and tables
If we want to perform a full table scan on the table, we only need to traverse the leaf nodes, and there is no need to traverse the entire B+Tree to get all the data.
- B+Tree has stronger disk read and write capabilities than B Tree, and has fewer IO times.
The root node and branch nodes do not save data areas, so a node can save more keywords, load more keywords from the disk at one time, and require fewer IO times.
- Better sorting ability
Because there is a pointer to the next data area on the leaf node, the data forms a linked list.
- Efficiency is more stable
B+Tree always gets data from leaf nodes, so the number of IOs is stable.
What is the difference between Hash index and B+ tree index?
- B+ trees can perform range queries, but Hash indexes cannot.
- B+ trees support the leftmost principle of joint indexes, but Hash indexes do not.
- B+ tree supports order by sorting, but Hash index does not support it.
- Hash index is more efficient than B+ tree in equivalent query.
- When the B+ tree uses like for fuzzy query, the words after like (such as starting with %) can play an optimization role, and the Hash index cannot perform fuzzy query at all.
What is the difference between clustered index and non-clustered index?
First understand that clustered index is not a new index, but a data storage method . Clustering means that rows of data and adjacent key values are stored compactly together. The two storage engines we are familiar with - MyISAM uses non-clustered indexes and InnoDB uses clustered indexes.
You can say that:
- The data structure of the index is a tree. The index and data of the clustered index are stored in a tree. The leaf nodes of the tree are the data. The index and data of the non-clustered index are not in the same tree.
Do you understand the return form?
In the InnoDB storage engine, using the auxiliary index query, first find the key value of the primary key index through the auxiliary index, and then use the primary key value to find out that there is no data that meets the requirements in the primary key index. It scans one more tree than the query based on the primary key index. Index tree, this process is called table back.
What is the leftmost prefix principle/leftmost matching principle?
Note: The leftmost prefix principle, the leftmost matching principle, and the leftmost prefix matching principle are all the same concept.
Leftmost matching principle : In InnoDB's joint index, when querying, only the previous/left value can be matched before the next one can be matched.
According to the leftmost matching principle, we create a combined index, such as (a1, a2, a3), which is equivalent to creating three indexes (a1), (a1, a2) and (a1, a2, a3).
Why can't we match if we don't search from the far left?
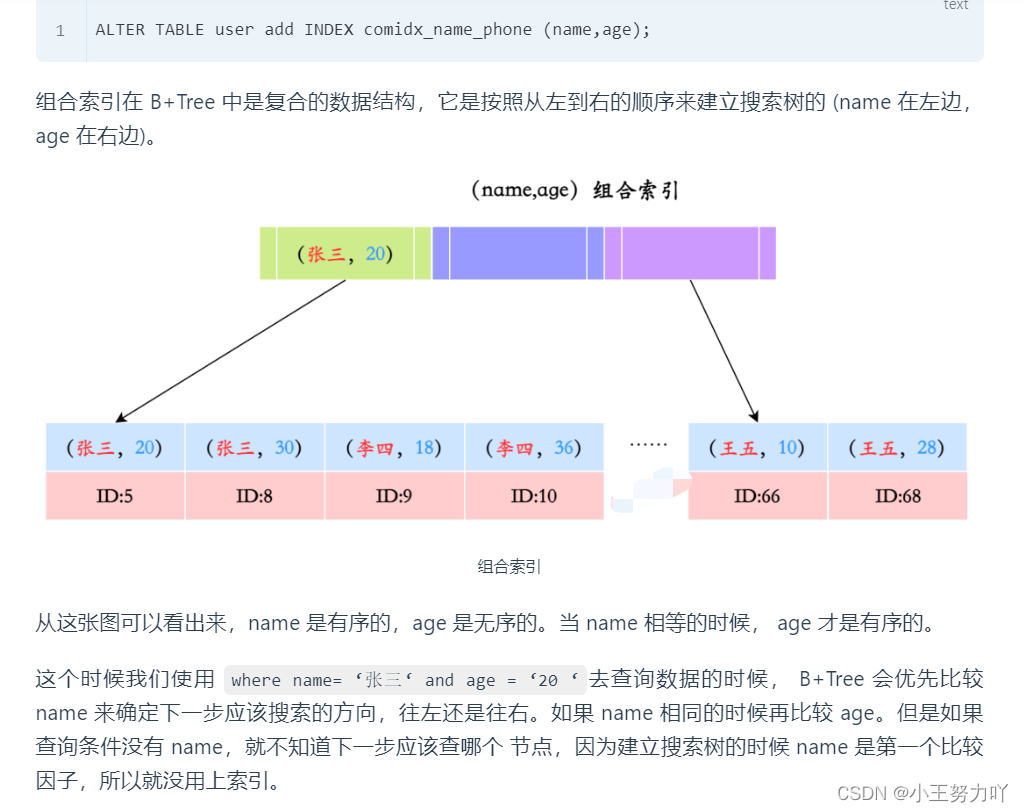
For example, there is a user table, and we create a combined index for name and age.
What is the leftmost prefix principle/leftmost matching principle?
Note: The leftmost prefix principle, the leftmost matching principle, and the leftmost prefix matching principle are all the same concept.
Leftmost matching principle : In InnoDB's joint index, when querying, only the previous/left value can be matched before the next one can be matched.
According to the leftmost matching principle, we create a combined index, such as (a1, a2, a3), which is equivalent to creating three indexes (a1), (a1, a2) and (a1, a2, a3).
Why can't we match if we don't search from the far left?
For example, there is a user table, and we create a combined index for name and age.