Contents of this article
- One, Redis data structure
- 2. Why is the Redis single-threaded model so fast?
- 3. RDB and AOF of Persistence
- Four, master-slave replication and failover
- 5. High availability and Sentinel
- Six, distributed cache and Redis Cluster
- Seven, cache breakdown (cache penetration), cache avalanche
- Eight, Redis hot key
- Nine, Bloom filter
- Ten, Redis memory management mechanism
One, Redis data structure
(1) String
scenes to be used:
1. Cache: In classic usage scenarios, put commonly used information, strings, pictures or videos in redis, redis as the caching layer, and mysql as the persistence layer to reduce the read and write pressure of mysql.
2. Counter: Redis is a single-threaded model, one command is executed before the next one is executed, and the data can be sent to other data sources in one step.
3.session: common scheme spring session + redis realizes session sharing,
(2) Hash
scenes to be used:
1. Cache: It is intuitive, saves space compared to string, and maintains cache information, such as user information, video information, etc.
(3) List linked list
scenes to be used:
1.timeline: For example, the timeline of Weibo, someone publishes Weibo, and uses lpush to join the timeline to display new list information
(4) Set collection
scenes to be used:
1. Tag (tag), add tags to users, or users add tags to messages, so that people with the same tag or similar tags can recommend things or people to follow.
2. Like, or click, favorite, etc., can be put in the set to achieve
(5) Zset ordered set
scenes to be used:
1. Ranking: an orderly collection of classic usage scenarios. For example, websites such as novel videos need to rank the novel videos uploaded by users. The list can be ranked according to the number of users' attention, update time, and word count.
2. Why is the Redis single-threaded model so fast?
(1) Based on memory operation
Redis stores all the data that needs to be stored in memory. The memory-based random access speed is about 100,000 times that of disks. Even SSDs are out of reach. This is an important physical basis for Redis to operate quickly.
(2) C language implementation
The execution efficiency of C language programs under the same logic is much higher than that of other languages. There is a unique relationship between the C language and the current mainstream operating systems. Despite the difficulty of development, the execution speed is quite fast.
(3) Simple data structure
Another advantage of the memory database is that the memory-based data structure is simpler than the hard disk-based data structure, and the operation of the data is simpler. Therefore, Redis can do a lot of things with little internal complexity. Redis also occupies less memory space.
(4) I/O multiplexing model
A single thread manages multiple I/O streams at the same time by recording and tracking the status of each Sock (I/O stream). There are three implementation modes: select, poll, and epoll.
1. Each time the select poll is called in a loop, the descriptor and file need to be copied to the kernel space; epoll only needs to be copied once;
2. After each return of select, it needs to traverse all the description files to find the ready, and the time is complicated The degree is O(n), while epoll requires O(1);
3. The improvement of poll over select is to use a linked list to save fd, and the number of enabled monitors is far greater than 1024
(5) Single-threaded model
Avoid resource-consuming operations such as multi-threaded startup, destruction, context switching, locking, and unlocking. Single thread is simple, not only can avoid the resource-consuming operation of context switching, but also can avoid deadlock. Greatly improve CPU utilization. If it is a multi-core server, you can use multiple CPUs by starting multiple Redis instances.
3. RDB and AOF of Persistence
Redis is a memory-based database. Once the power is cut off or restarted, the data in Redis will no longer exist. Redis provides two persistence methods, RDB and AOF. When the Redis instance restarts, the persisted data (file) can be used to restore the memory data set.
(1) RDB
This persistence method is to generate a snapshot file of the data in the current Redis memory and save it to the hard disk, which is simple and rude. RDB is also the persistence mode enabled by Redis by default.
1, trigger persistence
save
before been abandoned save command to achieve RDB persistent data, would have been blocked when the save command persistence, persistence until completion. The larger the amount of data, the longer the blocking time caused by the persistence process.
bgsave
can now use the bgsave command instead of save. bg is the background. When using the bgsave method of RDB persistence, the Redis worker process will fork a child process, which is specifically responsible for the time-consuming RDB persistence, and the worker process will continue to work, and the blocking time only occurs in the short fork phase .
In addition to the active trigger command, Redis also provides the automatic trigger RDB persistence command bgsave, which indicates that the RDB persistence will be triggered when the number of Redis memory data modification reaches changes times within seconds. For example, bgsave 7200 10 means that RDB persistence will be triggered automatically when the data is changed 10 times within 2 hours.
(Note that the changes count does not include query statements. Of course, the key to be operated must exist, otherwise it will not be counted)
2. Data snapshot storage
First, the working directory defaults to the current Redis directory, then the persistent RDB data snapshot will be stored in This directory can be modified through the dir ./ parameter. The default name of the generated data storage snapshot is dump.rdb, which can be modified through the dbfilename dump.rdb parameter. Mr. RDB persistence saves a temporary snapshot. After the data persistence is completed, this temporary snapshot will replace the original snapshot to prevent problems in the persistence process.
RDB storage snapshots use the LZF algorithm compression function by default, and the compressed file size will be greatly reduced. Compressed files are not perfect. RDB snapshots will also consume CPU when compressed. The larger the amount of data, the more CPU resources will be consumed, but the official website still strongly recommends us to start this feature.
When RDB persists, there may be problems such as permission problems and insufficient storage space. Redis turns on the stop-writes-on-bgsave-error yes parameter by default, which means that when an error occurs, Redis will stop writing data to the snapshot file.
When Redis saves/restores data, it is not a single-minded save/restore. The RDB snapshot file is checked by default, and the performance will be affected (about 10%), so you can disable it to get the maximum performance. (Recommended)
(Two) AOF
This kind of persistence method is to record the operation log by saving the write command. When the data is restored, the recorded write command is re-executed to achieve data recovery.
1. Principle of AOF
By default, AOF is turned off. You can enable AOF persistence by modifying appendonly no to appendonly yes. The output bandwidth of the memory is much larger than the bandwidth of the disk input. If the memory writes a large amount of data to the disk instantaneously, IO congestion will inevitably occur, and the performance of the single-threaded Redis will also be greatly reduced. Therefore, all write commands are not directly written into the AOF file, but the write commands are first stored in the AOF Buffer, and finally synchronized to the AOF file.
The generated AOF file name, the default is appendonly.aof, you can modify the appendfilename "appendonly.aof" parameter to change the generated AOF file name.
From the buffer to the disk, Redis provides three synchronization methods:
always: after the write command is appended to the AOF cache, call the system fsync function to synchronize the data in the buffer to the disk, and finally return
everysec: the write command is appended to the AOF cache After that, call the system write function, after the write function is executed, and then return, it will trigger the system to synchronize the data in the buffer to the disk.
No: After the write command is appended to the AOF cache, call the system write function, and then return. Synchronization is the responsibility of the system.
Everysec is not only the default method, but also the recommended method.
2. AOF rewrite mechanism
AOF persistent file stores Redis write commands, which is much larger than just data storage files. In the AOF rewrite mechanism, the database is traversed first, and if the database is empty, the database is skipped. For a non-empty database, all keys are traversed, if the key expires, the key is skipped, and if the key has an expiration time, the expiration time of the key is set.
The AOF rewrite mechanism is not triggered randomly. The default is to trigger the rewrite mechanism when the size of the current written AOF file has increased by 100% compared to the file size after the last rewrite. For example, the file size after the last rewrite is 1G, after a period of time, the volume of the AOF file has increased by 1G, then the growth rate is 100%, which will trigger the AOF rewrite. The trigger threshold of file growth rate can be adjusted by setting auto-aof-rewrite-percentage 100.
If there are few AOF files, it is not enough to affect the performance too much, so there is no need to rewrite the AOF files. The minimum threshold of AOF file rewriting can be set by auto-aof-rewrite-min-size 64mb.
The aof-load-truncated yes parameter indicates that when Redis restores data, the last command may be incomplete, and it means to ignore the last incomplete command when it is turned on.
(3) Comparison of RDB and AOF
After the RDB starts to compress, it generates a smaller and more compact binary file that occupies a small space. RDB not only has faster data recovery capabilities, but also can directly copy RDB files to other Redis instances for data recovery, which has a good disaster recovery experience. RDB is suitable for scenarios of timed replication, full replication, and fast recovery. Due to the long time for RDB file generation and data storage delay, it is not suitable for near real-time persistence scenarios.
AOF writes files continuously and near real-time (second level) by means of additional commands. Moreover, to a certain extent, AOF continuously rewrites persistent files and continuously optimizes. Especially in terms of data integrity, it is much better than RDB. For example, using the default data synchronization strategy, Redis may only lose one second of writing time when a major event such as a server power failure occurs, or it occurs in the Redis process itself. Wrong but the operating system is still running normally and loses a write time. Therefore, AOF is more suitable for scenarios where data real-time and data integrity requirements are relatively high. Compared with RDB, the disadvantage of AOF is that the file is relatively large, and because all write commands are executed when recovering data, data recovery is slower, especially in the case of high load on the application system that is depended on, and it takes a long time. Data recovery is intolerable to the back-end system.
But AOF and RDB persistence can be enabled at the same time without problems. If AOF is enabled at startup, redis will load AOF, which is a file with better durability guarantee. And in the newer version also supports mixed mode.
RDB-AOF Hybrid Persistence
Redis supports RDB-AOF hybrid persistence since 4.0. It is turned off by default and can be turned on by aof-use-rdb-preamble yes. After the AOF file is rewritten, an RDB snapshot file that records the existing data will be generated, and an AOF file that records the most recent write command will be generated as a supplement to the RDB snapshot. Such a hybrid persistence model will have the dual advantages of RDB and AOF.
Four, master-slave replication and failover
(1) The significance of data replication
1. Separation of reading and writing, reducing the pressure of reading and writing on a single node;
2. Disaster recovery transfer, when a single machine has a problem, it will take over from the node.
(2) Redis registration and replication principle
First, through the above configuration of master-slave replication, the slave node saves the information of the master node, and then establishes a socket connection. The Redis ping command is a command used by the client to detect whether the server is operating normally or the message is delayed. It is a heartbeat mechanism, where the slave node is the client and the master node is the server. The slave node sends a ping command to the master node, and if the master node is operating normally, it will return to pong, so that it can indicate that the two parties are connected to the network. Then, if the master node turns on the requirepass foobared parameter (foobared can be considered as a security verification password), the master node will verify the permissions of the slave nodes. After the password is correct, data synchronization is performed. Finally, the subsequent data is copied continuously, one after another, and the way to realize this continuous data copy is to copy its operation commands.
(3) Failover
For a single node, there may be a failure (fail), in order to ensure the availability of the service, it is necessary to use other redundant or spare nodes to take over the work of the node, this rescue method is failover (Failover).
For example, a high-availability solution with one master and two slaves, the master node works, and the slave node
serves as a backup: if the master node (master node) fails, then the service is unavailable, and the slave node (slave node) cannot continue to replicate data from the master node. How to achieve failover? The following is a client-based implementation.
1. The client uses the heartbeat mechanism to detect the activity of the master and slave nodes regularly, such as using the ping command;
2. If the master node does not reply within a certain period of time, the master node is considered unavailable at this time;
3. Randomly select from the slave nodes Or choose a node with a better ping-pong network to be promoted to master, such as the 6380 node;
4. The 6380 node and the 6381 node first disconnect the replication relationship slave of no one with 6379;
5. Then use 6380 as the master node and 6381 as the salve The node establishes a replication relationship;
establishes a new master-slave replication
6. After the heartbeat detection 6379 node fails, establish a master-slave replication relationship with the master node as a salve node;
screenshot 2019-02-16 4.10.30.png
7. Failure The transfer is complete. (In fact, after the 6380 is selected as the master node in step 3, the service is available.) The
client can also be made into multiple nodes for high availability. When the Redis master node fails, the client multiple nodes will generate new nodes through elections. The master node. Starting from Redis 2.8 version, Redis Sentinel was newly added to achieve high availability.
5. High availability and Sentinel
Redis-Sentinel is a high-availability (HA) solution officially recommended by Redis. When Redis is used as a high-availability solution for Master-slave, if the master goes down, Redis itself (including many of its clients) does not implement automatic processing. Master-slave switch, and Redis-sentinel itself is also an independently running process. It can monitor multiple master-slave clusters and automatically switch after the master is down.
(1) The function of sentinel
1. Monitoring
Sentinel will constantly check whether your master server and slave server are operating normally.
2. Reminder
When there is a problem with a monitored Redis server, Sentinel can send notifications to the administrator or other applications through the API.
3. Automatic failover
When a master server fails to work normally, Sentinel will start an automatic failover operation. It will upgrade one of the slave servers of the failed master server to the new master server, and let the other slave servers of the failed master server Copy the new master server instead; when the client tries to connect to the failed master server, the cluster will also return the address of the new master server to the client, so that the cluster can use the new master server to replace the failed server.
Six, distributed cache and Redis Cluster
Redis first used the master-slave mode as a cluster. If the master is down, you need to manually configure the slave to turn to the master. Later, for high availability, the sentry mode is proposed. In this mode, there is a sentry to monitor the master and the slave. If the master is down, the slave can be automatically turned on. Turned to master, but it also has a problem, that is, it cannot be dynamically expanded; therefore, the cluster mode was proposed in 3.x.
Redis-Cluster adopts a centerless structure, each node saves data and the state of the entire cluster, and each node is connected to all other nodes.
Seven, cache breakdown (cache penetration), cache avalanche
(1) Cache breakdown (cache penetration)
Cache is a distributed, high-concurrency scenario. In order to protect the back-end database and reduce the pressure on the database, a memory-based data access mechanism is introduced to speed up the reading and writing of data, thereby increasing the system load ability.
Cache breakdown (cache penetration) is to access data that does not exist in the cache, and then directly access the database.
Cache breakdown and cache penetration are classified
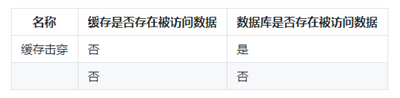
in more detail: In the case of cache penetration, if neither the cache nor the database has data that needs to be accessed, then there is no data when accessing the cache, and it will return empty directly to avoid repeated access to the database. Cause unnecessary pressure on the back-end database.
Solution
1. Cache empty values: If you access a data that does not exist for the first time, then cache the data whose key and value are empty values, and the next time there is a corresponding key access, the cache will directly return the empty value, usually To set the expiration time of the key, update the expiration time when it is accessed again;
2. Bloom filter: Similar to a hash set, judge whether the key is in this set. The implementation mechanism lies in the bit position. A key corresponds to a bit position and an identifier is stored. If the key has a corresponding bit position and the identifier bit indicates that it exists, it means that there is corresponding data. For example, use Redis's Bitmap implementation.
(Two) cache avalanche
A large number of cache breakdowns means that a large number of requests are placed on the database. The lighter ones will cause the database to respond very slowly, and the more serious ones will cause the database to go down. For example, the data in the cache is periodically refreshed collectively, the server is restarted, and so on.
Solution
1. Reduce the cache refresh frequency;
2. Part of the cache refresh, refresh data in groups according to certain rules;
3. Set the key to never expire, if you need to refresh the data, refresh regularly;
4. Sharded cache, in distributed Under the cache, the data that needs to be cached is hashed and distributed to multiple nodes, and the hot data is evenly distributed to multiple nodes as far as possible.
Eight, Redis hot key
Within a certain period of time, frequently accessed keys are called hotspot keys. For example, breaking news, hot search news that is common on Weibo, causing tens of millions of people to browse within a short period of time; online shopping mall promotion activities, the sudden price reduction of products that consumers pay more attention to, causing thousands of consumers to click, buy. Hot keys will cause traffic to be too concentrated, and the pressure on the cache server will rise suddenly. If the load capacity of the physical machine is exceeded, the cache will be unavailable, which may cause cache breakdown and cache avalanche.
Solution
1. Separation of reading and writing
By decentralizing the writing and reading of data to each node, the purpose of data consistency of each node is achieved through data replication. In the case of less writes, the master node writes data, and in the case of high read request pressure, multiple slave nodes are configured, and the data is synchronized horizontally (topology). Combine Redis Sentinel (or other high-availability technologies) to achieve high availability of cache nodes.
2. The Alibaba Cloud Database Redis version solution
is mainly divided into two forms of hot key processing: writing and reading. During the data writing process, when the SLB receives the data key1 and writes it to a Redis through a certain Proxy, Complete the data writing. If the back-end hotspot module calculates that key1 becomes a hotspot key, the Proxy will cache the hotspot. When the client accesses key1 next time, it does not need to go through Redis. Finally, because Proxy can be expanded horizontally, it can arbitrarily enhance the ability to access hotspot data.
3. The hot key does not expire
If the key exists, don't set the key expiration time. If the data corresponding to the key is unavailable (such as deleted), delete the key from the cache. From the request point of view, if the corresponding key is found in the cache, it indicates that the key and its value are the data the user needs. If the corresponding key does not exist in the cache, it indicates that there is no corresponding data, and a null value is returned. For example, a celebrity article is posted on Weibo, and the number of visits directly rises in a short period of time. If the key does not expire, the request will always hit the cache. Only when the article is deleted, the corresponding key is deleted from the cache. If there is still a request for access at this time, and there is no data in the cache, a null value is directly returned, indicating that the article has been deleted. Of course, you can also update the value corresponding to the key and return the value you want to express.
Nine, Bloom filter
Bloom filter is a magical data structure that can be used to determine whether an element is in a set. A very commonly used function is to remove duplication. Bloom filter is essentially a bit array, which means that each element of the array only occupies 1 bit. Each element can only be 0 or 1.
In addition to a bit array, the Bloom filter also has K hash functions. When an element is added to the Bloom filter, the following operations will be performed:
1. Use K hash functions to perform K calculations on the element value to obtain K hash values.
2. According to the obtained hash value, set the value of the corresponding subscript to 1 in the bit array.
3. When it is necessary to judge whether a value is in the Bloom filter, the element is hashed again, and after the value is obtained, it is judged whether each element in the bit array is 1. If the value is 1, then the value is In the Bloom filter, if there is a value other than 1, it means that the element is not in the Bloom filter.
- The Bloom filter says that an element is present and may be misjudged.
- The Bloom filter says that an element is not there, so it must not be there.
Ten, Redis memory management mechanism
(1) Maximum memory limit
Redis uses the maxmemory parameter to limit the maximum available memory. The default value is 0, which means unlimited.
1. Used in caching scenarios. When the maxmemory memory limit is exceeded, delete strategies such as LRU are used to release space.
2. Prevent the memory used from exceeding the physical memory of the server. Because Redis uses the server's memory as much as possible by default, there may be insufficient server memory, causing the Redis process to be killed.
(2) Memory recovery strategy
(1) Delete the expired key object
Lazy deletion and timing task deletion mechanisms are used to realize memory recovery of expired keys.
Lazy deletion means that when the client operates a key with a timeout attribute, it checks whether the key expiration time has passed, and then executes the delete operation synchronously or asynchronously and returns that the key has expired. This can save CPU cost considerations, and there is no need to maintain a separate expiration time linked list to handle the deletion of expired keys.
Redis maintains a scheduled task internally, which runs 10 times per second by default (controlled by configuration). The logic for deleting expired keys in a timed task uses an adaptive algorithm, which reclaims keys according to the expiration ratio of the keys and using two rate modes: fast or slow.
(2) Memory overflow control strategy
When the memory reaches maxmemory, the memory overflow control strategy is triggered to force the deletion of the selected key-value object.
Each time Redis executes a command, if the maxmemory parameter is set, it will try to reclaim memory. When Redis has been working in the state of memory overflow (used_memory>maxmemory) and a non-noeviction strategy is set, it will frequently trigger the operation of reclaiming memory, which affects the performance of the Redis server.