1 Introduction to Indexing
1.1 What is a MySQL index
Official definition: an index is a data structure that helps MySQL efficiently obtain data
From the above definition, we can analyze that the index is essentially a data structure. Its function is to help us obtain data efficiently. Before we formally introduce the index, let’s first understand the basic data structure.
2 Index data structure
2.1 Hash index
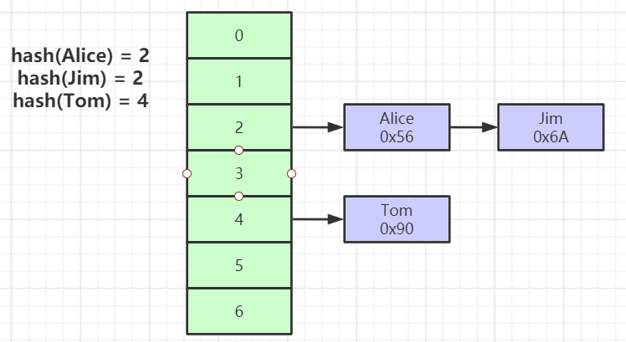
Hash index is a relatively common index. It calculates the hash value corresponding to the record, and then stores it in the corresponding location according to the calculation result. When querying, the location is quickly found according to the hash value. His single record query is very efficient and has a time complexity of 1. However, Hash index is not the most commonly used type of database index, especially our commonly used Mysql Innodb engine does not support hash index.
The hash index is fast in the equivalent query, but has the following two problems
- Range queries are not supported
- Hash conflict, when the hash values of two records are the same, a hash conflict occurs, which needs to be stored in a linked list later
2.2 Binary tree
2.2.1 Classic binary tree
1. A node can only have two child nodes
2. The value of the left child node is smaller than the value of the parent node, and the value of the right child node is greater than the value of the parent node. Binary search is used, which is faster
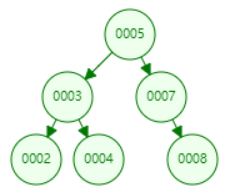
An extreme example of a classic binary tree is a linked list, and the node data is getting bigger and bigger. In this case, binary tree search performance will be reduced
2.2.2 Balanced Binary Tree
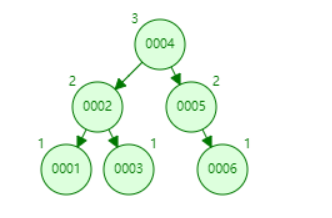
A balanced binary tree is also called an AVL tree . It can be an empty tree, or a binary sorted tree with the following properties :
- The absolute value of the difference between the heights of its left subtree and right subtree (balance factor) does not exceed 1
- Its left subtree and right subtree are both balanced binary trees.
The numbers 1-6 are illustrated in a balanced binary tree as follows:
2.3 B-tree
B-tree is a multi-fork tree, also known as a balanced multi-way search tree, which can have multiple forks and has the following characteristics
(1) Sorting method: all node keywords are arranged in ascending order, and follow the principle of small on the left and large on the right;
(2) Number of child nodes: The number of child nodes of non-leaf nodes (root nodes and branch nodes) > 1, and the number of child nodes <= M, and M > = 2, except for empty trees (Note: M order means that a tree node has the most How many search paths are there, M=M path, when M=2 is a binary tree, M=3 is a 3-fork);
(3) Number of keywords: the number of keywords in a branch node is greater than or equal to ceil(m/2)-1 and less than or equal to M-1 (Note: ceil() is a function rounded towards positive infinity, such as ceil(1.1 ) results in 2);
(4) All leaf nodes are on the same layer. In addition to pointers to keywords and keyword records, leaf nodes also have pointers to their child nodes, but their pointer addresses are all null, corresponding to the spaces in the last layer of nodes in the figure below. son;
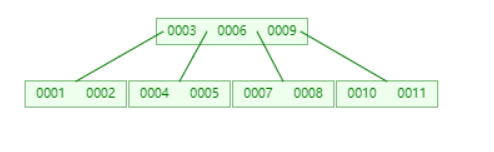
The B-tree storage structure in MySQL is as follows:
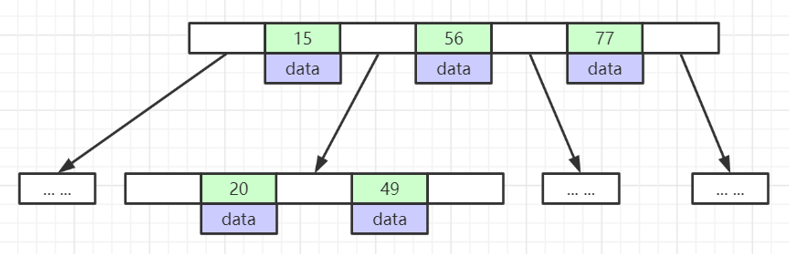
2.4 B+ tree
B+ tree is another improvement on the basis of B tree. It mainly improves two aspects, one is the stability of the query, and the other is more friendly in data sorting. The underlying data structure of MySQL index is B+ tree
(1) The non-leaf nodes of the B+ tree do not save specific data, but only save the index of keywords , and all data will eventually be saved to the leaf nodes. Because all data must be obtained from the leaf nodes, the number of data queries each time is the same, so that the query speed of the B+ tree will be relatively stable, and in the search process of the B tree, different keywords search The number of times is likely to be different (some data may be in the root node, and some data may be in the lowest leaf node), so at the application level of the database, the B+ tree is more suitable.
(2) The keywords of the B+ tree leaf nodes are arranged in order from small to large, and the data at the end of the left will save the pointer to the data at the beginning of the right node. Because the leaf nodes are arranged in an orderly manner, the B+ tree has better support for sorting data.
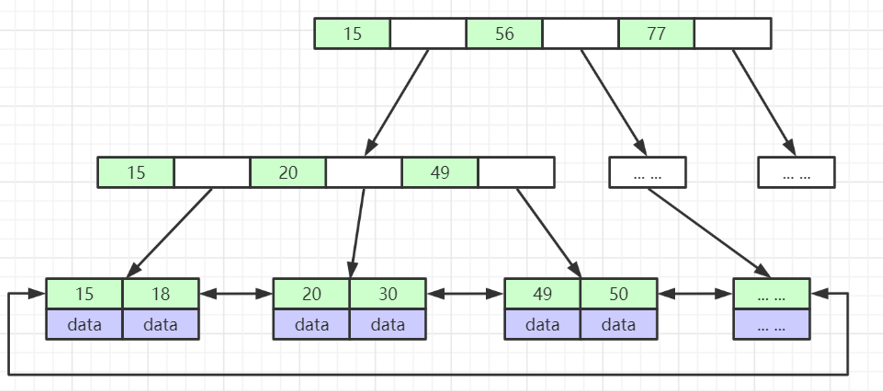
2.5 B* tree
The B-tree is a variant of the B+ tree. It is based on the B+ tree and connects the index layers with pointers (the B+ tree just connects the data layers with pointers), making the search for values faster

Summarize
After analyzing the above data structures, MySQL uses a B+ tree to store indexes. On the comprehensive level, this query efficiency is the best. Oracle uses B* tree
3 Index classification
MySQL indexes mainly include the following types
- primary key index
- unique index
- normal index
- composite index
- full text index
3.1 Primary key index
The primary key index is a special index. Generally, a primary key is set for the table when the table is created, and MySQL will add an index to the primary key by default. The primary key index leaf node stores a row of data in the data table . When the table does not create a primary key index, InnDB will automatically create a ROWID field for building a clustered index. The rules are as follows:
- Define the primary key PRIMARY KEY on the table, and InnoDB uses the primary key index as the clustered index.
- If the table does not define a primary key, InnoDB will choose the first unique index column that is not NULL as the clustered index.
- If neither of the above two is available, InnoDB will use a 6-byte long integer implicit field ROWID field to build a clustered index. The ROWID field is automatically incremented when new rows are inserted.
How to create:
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT ,
`name` varchar(255) NOT NULL ,
PRIMARY KEY (`id`)
);
Why does MySQL use an implicit field ROWID to build a clustered index by default without specifying a primary key when creating a table? We will mention this later
3.2 Unique Index
Similar to the previous ordinary index, the difference is that the value of the index column must be unique, but null values are allowed. If it is a composite index, the combination of column values must be unique.
Creation method
CREATE UNIQUE INDEX indexName ON user(column)
或者
ALTER TABLE table_name ADD UNIQUE indexName ON (column)
3.3 Common Index
MySQL basic index, no restrictions
How to create:
CREATE INDEX index_name ON user(column)
或者
ALTER TABLE user ADD INDEX index_name ON (column)
3.4 Composite Index
Composite index, as the name suggests, adds indexes to multiple fields of MySQL at the same time, and must follow the leftmost matching principle when using it
How to create:
CREATE INDEX index_name ON user(column1,column2) -- 给 column1 和 column2 加上索引
3.5 Full-text indexing
The full-text index is mainly used to find keywords in the text, not directly compared with the index value. It is similar to our common search engines (such as elasticsearch, solr, etc.) in function. The performance of MySQL full-text index is average, so it is generally not used, just for understanding
How to create:
CREATE FULLTEXT INDEX index_column ON user(column)
或者
ALTER TABLE user ADD FULLTEXT index_column(column)
4 Index Design
4.1 Samsung Index
The Samsung index is a specification when we design the MySQL index, and the index design that conforms to the Samsung index is usually a better design
One star: the index rows related to the query in the index are contiguous, or at least close enough together
Two stars: the order of the data columns in the index is the same as the sort order in the lookup
Samsung: The columns in the index contain all the columns needed in the query. The index contains the data columns required by the query, and no longer performs full table lookup and table return operations
Let me give you an example to introduce what the Samsung index looks like
Now there is a table with the following structure
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL,
`age` int(10) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;
one star
We now index age
create index idx_age on user (age);
Inquire
select * from user where age in (10,20,35,43)
This statement does not necessarily match one star, because age is a range, and the data may be scattered
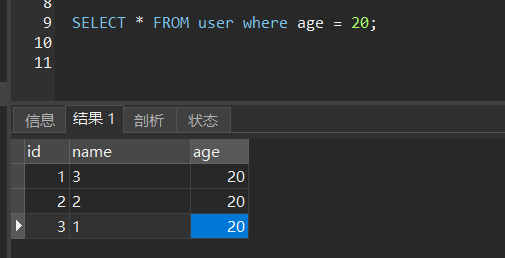
select * from user where age = 20;
This statement is in line with one star, because the index is sorted by age from small to large, so the data with age = 20 must be together
two stars
select * from user where age = 20 order by name;
This statement fits one star, but not two stars, because the order of the data columns is sorted by age. If it is now sorted by name, the index order may be different from the order by sorting result. The result is as follows:
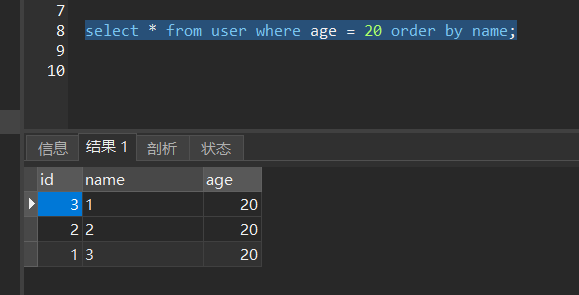
select * from user where age = 20 order by age
This query statement is in line with one-star and two-star
Samsung
select * from user where age = 20
This statement does not conform to Samsung, because there are only id and age in the index column, no name
select age from user where age = 20
This statement is in line with Samsung, because only age is queried, age exists in the index, and there is no need to return the table
4.2 Return form
The above Samsung index mentioned a return form, so what is the return form?
To put it simply, the columns required in the query statement are not included in the index, and they need to be queried again according to the primary key id to obtain them. Returning to the table is equivalent to one more query, and we should try to avoid returning to the table when querying again.
Because ordinary indexes only contain the values of the corresponding columns and primary keys, such as the age index, the data contained in the age index includes age and id. If you need a name at this time, you need to find the corresponding id through the age index first, and then find the name on the primary key index, which contains the values of all records in a row. Here is the answer to the above question, why MySQL must have a primary key index, because the primary key index child node contains all the data
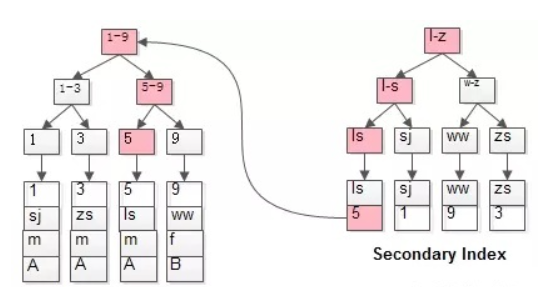
4.3 Index coverage
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) NOT NULL,
`age` int(1) DEFAULT NULL,
`sex` varchar(2) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `idx_name_age` (`name`,`age`)
) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8mb4;
select name,age from user where name = "张三"
-- 这条语句就使用了索引覆盖,因为 name 和 age 再 idx_name_age 索引中都有,不需要回表查询
select name,age,sex from user where name = "张三"
-- 如果加上了 sex,那么就需要回表查询了,因为索引中不存在 sex 字段
5 Index Optimization
5.1 Slow query
5.1.1 Introduction
The slow query log is a log record provided by MySQL to record all slow SQL statements. We can define what kind of SQL is slow SQL by setting the time threshold of slow query long_query_time. Through the slow query log, we can find out the SQL that needs to be optimized. The next step is to optimize the SQL
5.1.2 Slow query configuration
Step 1: We can use the show variables like 'slow_query_log' statement to check whether the slow query is enabled, the default is OFF
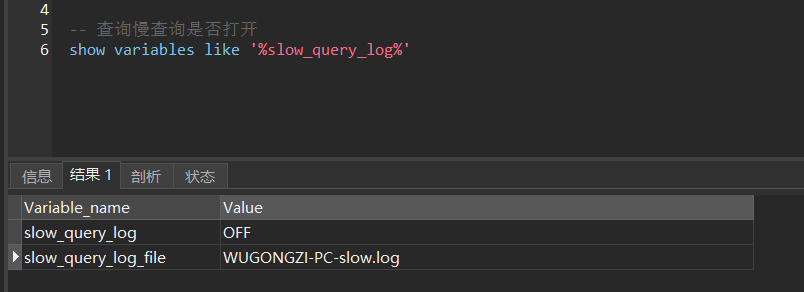
slow_query_log_file is the location where the slow query log is stored. If it is a window, it is usually in the Data directory of your installation folder
Step 2: Open slow query
set global slow_query_log = 1;
Step 3: Set the slow query threshold
What kind of query is called slow query? 1s, 5s or 10s, MySQL does not know this, so we need to set the long_query_time parameter through configuration
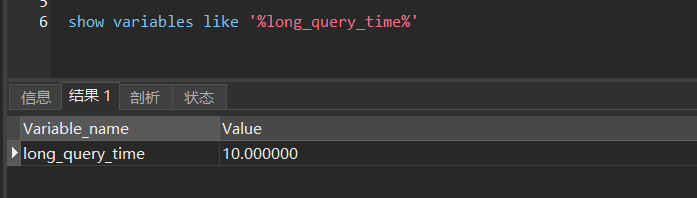
Check the slow query time by command show variables like '%long_query_time%', the default is 10 s
If you need to modify it, you can set global long_query_time = 5set it by command
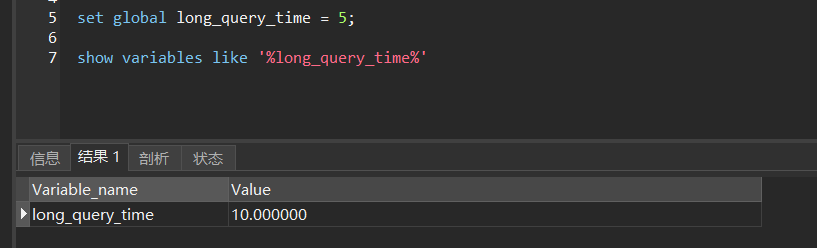
**Note:** After set global long_query_time = 5setting the slow query time here, I checked again and found that the slow query time is still 10s. Could it be that the setting has not taken effect?
After using this command to modify, you need to reconnect or open a new session to see the modified configuration
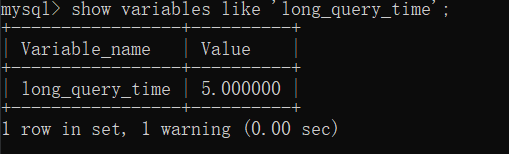
Or show global variables like '%long_query_time%'check with the command
5.1.3 Slow query log analysis
We have just set the slow query threshold to 5s, now we execute a sql statement like this
select sleep(6);
The execution time of this statement is 6s. We can find that some data has been added by opening the slow query log
# Time: 2022-10-02T09:16:23.194396Z
# User@Host: root[root] @ localhost [::1] Id: 6
# Query_time: 6.011569 Lock_time: 0.000000 Rows_sent: 1 Rows_examined: 0
SET timestamp=1664675770;
select sleep(6);
Let's analyze what each line represents one by one:
User@Host: the user who executes the SQL and the IP address of the slow query
Query_time: statement execution time
Lock_time: the length of time to acquire the lock
Rows_sent: the number of rows returned by MySQL to the client
Rows_examined: the number of rows scanned by MySQL
timestamp: indicates the timestamp of the slow SQL record
select sleep(6): it is slow query SQL
Let's analyze a real slow query SQL, a SQL statement in the previous test
# Time: 2022-07-27T09:26:44.440318Z
# User@Host: root[root] @ localhost [127.0.0.1] Id: 249
# Query_time: 68.461112 Lock_time: 0.000938 Rows_sent: 877281 Rows_examined: 877303
SET timestamp=1658914004;
SELECT id,prd_line_id,shift_name,shift_id,app_id,weight,upload_time,operator,status,prd_line_name FROM prd_weight
WHERE (upload_time > '2022-07-27 00:00' AND upload_time < '2022-07-27 17:24');
Query_time: total query time 68.461112s
Lock_time:0.000938s
Rows_examined: Scanned row 877281
Rows_sent: 877303 returned
Of course, this is for testing, and such outrageous SQL statements generally do not appear in production
5.1.4 Precautions
- In MySQL, management statements are not recorded in the slow query log by default, such as:
alter table, analyze table, check table, etc. However, it can be set via the following property:
set global log_slow_admin_statements = "ON" - In MySQL, you can also set to record the SQL statements that have not been indexed in the slow log query file (the default is off). It can be set through the following properties:
set global log_queries_not_using_indexes = "ON" - In MySQL, the log output format is supported: FILE (default) and TABLE, which can be used in combination. As follows:
set global log_output = "FILE, TABLE"
This setting will be written in FILE and slow_log table in MySQL library at the same time. However, logging to the system's dedicated log table consumes more system resources than logging to files. Therefore, if you need to enable slow query logging and obtain higher system performance, it is recommended to log to files first.
5.2 Explain execution plan
Through the above slow query log analysis, we can know what slow SQL statements there are. But where these SQLs are slow and how to optimize them, we also need a more detailed analysis plan. Here, MySQL provides us with the Explain keyword, through which we can analyze the detailed execution information of the SQL statement.
5.2.1 Use of Explain
We create a user table in the database for testing
SET NAMES utf8mb4;
SET FOREIGN_KEY_CHECKS = 0;
-- ----------------------------
-- Table structure for user
-- ----------------------------
DROP TABLE IF EXISTS `user`;
CREATE TABLE `user` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`password` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`sex` varchar(2) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`phone` varchar(11) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`dept_id` int(10) NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_name`(`name`) USING BTREE,
INDEX `idx_dept_id`(`dept_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 6 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of user
-- ----------------------------
INSERT INTO `user` VALUES (1, '张三', '123', '男', '12323432', 1);
INSERT INTO `user` VALUES (2, '李四', '456', '男', '178873937', 1);
INSERT INTO `user` VALUES (3, '小花', '123', '女', '1988334554', 2);
INSERT INTO `user` VALUES (4, '小芳', '334', '女', '18765287937', 2);
INSERT INTO `user` VALUES (5, NULL, '122', NULL, NULL, NULL);
DROP TABLE IF EXISTS `dept`;
CREATE TABLE `dept` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`dept_name` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 3 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of dept
-- ----------------------------
INSERT INTO `dept` VALUES (1, '开发部');
INSERT INTO `dept` VALUES (2, '销售部');
explain is also very simple to use, just add the explain keyword in front of the query statement:
EXPLAIN SELECT * FROM user where id = 1;

From the figure, we can see that MySQL returns a row of records, let's analyze what each field means
| field | meaning |
|---|---|
| id | The unique identifier of the select statement in a query process |
| select_type | Query type, including four simple, primary, subquery, derived |
| table | Which table is queried |
| partitions | Table partition information |
| type | Access type, analysis performance is mainly through this field |
| possible_keys | Indexes that may be used |
| key | the actual index used |
| key_len | the number of bytes used in the index |
| ref | This column shows the column or constant used for the table lookup value in the index of the key column record |
| rows | MySQL Estimated Scan Rows |
| filtered | After MySQL filtering, the proportion of the number of records that meet the conditions |
| Extra | shows some additional information |
5.2.2 Explain in detail
1、id
id is the unique identifier in the query statement. The larger the value of id, the earlier the SQL statement corresponding to the id will be executed
explain select * from dept where id = (select dept_id from user where id = 1);

From the perspective of the execution plan, the statement select dept_id from user where id = 1 is executed first, because the outer query needs the result of this query statement
2、select_type
Query types, including four
simple: simple query. Query does not contain subquery and union

primary: the outermost select in complex queries

subquery: the subquery included in select (not in the from clause)

derived: The subquery contained in the from clause. MySQL will store the results in a temporary table, also known as a derived table (the English meaning of derived)
3、table
It is easier to understand which table is being queried
4、partitions
Partition information matched during query, the value is NULL for a non-partitioned table, when the query is a partitioned table, partitions displays the partitions hit by the partitioned table.
5、type
type: What type of query is used, which is a very important indicator in SQL optimization. The following performances are in order from good to bad:system > const > eq_ref > ref > ref_or_null > range > index > ALL
-
system is a special case of const, that is, when there is only one record in the table, the type is system
-
const, constant query, id is the primary key, all information can be queried through id

-
eq_ref, in the connection query, all parts of the primary key or unique key index are used by the connection
Note: The id of dept and the id of user are not related here, just to demonstrate the query type

The id of user and the id of dept are both primary keys. In the connection query, both primary keys are used
- ref, do not use a unique index, use a common index or a unique index, may find the value of multiple conditions, idx_name is a common index

- ref_of_null, similar to the ref function, the difference is that the index will additionally search for values containing NULL, the name field is a normal index, and there are data whose name is null in the database

- range, use range query on the index field, common queries are >, <, in, like, etc.
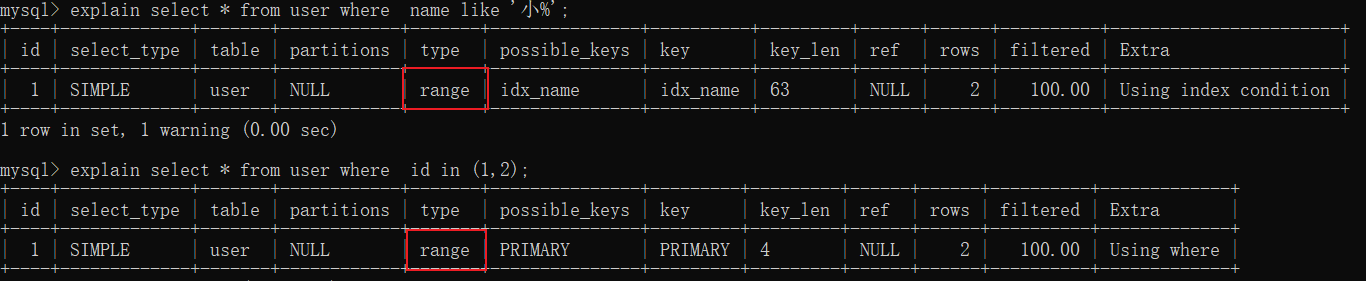
- index, full table scan through index tree

- ALL, full table scan, do not pass the index tree, because this is a select * query

6、possible_keys
MySQL analyzes the indexes that may be used in this query, but may not be used in actual queries

The analysis may use the idx_name index. The index is not used in the actual query, and the full table scan is performed.
7、key
The key actually used in the query

The index idx_name is actually used in the query
8、ken_len
Indicates the length of the index column used in the query

We use this index to analyze, how does key_len come from 63?

When creating the user table, I wonder if you have noticed that the character set of name is utf8
For MySQL version 5.0 and above, each character in the utf8 character set occupies 3 bytes, and varchar(20) occupies 60 bytes. At the same time, because varchar is a variable-length string, an additional byte is required to store the length of the character, a total of two Bytes, in addition, the name field can be a null value, and a null value occupies one byte alone, adding up to a total of 63 bytes
9、ref
When using the index column equivalence matching conditions to execute the query, that is, when the access method is one of const, eq_ref, ref, ref_or_null, unique_subquery, , the column displays the specific information that is equivalent to the index column, such as just a constant or a column.index_subqueryref

10、rows
functions expected to be scanned
11、filtered
filtered This is a percentage value, the percentage of the number of records in the table that meet the conditions. To put it simply, this field indicates the proportion of the number of records that meet the conditions after filtering the data returned by the storage engine.
12、Extra
ExtraIt is used to explain some amount of information, so as to help us understand the query more accurately
5.3 High performance index usage strategy
5.3.1 Do not perform any operations on indexed columns
explain select * from user where left(name,2) = '小芳';

This sql performs a function operation on the name field, causing the index to fail
5.3.2 Leftmost prefix rule
When using a joint index query, the leftmost prefix principle should be followed, which means that the query starts from the leftmost front column of the index and does not skip columns in the index.
Create a goods table with a joint index containing three fields: name, price, and mark
DROP TABLE IF EXISTS `goods`;
CREATE TABLE `goods` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(10) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
`price` int(10) NULL DEFAULT NULL,
`mark` varchar(20) CHARACTER SET utf8 COLLATE utf8_general_ci NULL DEFAULT NULL,
PRIMARY KEY (`id`) USING BTREE,
INDEX `idx_all`(`name`, `price`, `mark`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
-- ----------------------------
-- Records of goods
-- ----------------------------
INSERT INTO `goods` VALUES (1, '手机', 5678, '华为手机');
INSERT INTO `goods` VALUES (2, '电脑', 9888, '苹果电脑');
INSERT INTO `goods` VALUES (3, '衣服', 199, '好看的衣服');
Execute the following query statement:
explain select * from goods where name = '手机' and price = 5678 and mark = '华为手机';

From the figure above, you can see that the type is ref.
Now we don't start the query from the leftmost, just skip the name field
explain select * from goods where price = 5678 and mark = '华为手机';

The type has changed from ref to index. This is because MySQL sorts the fields in the combined index according to the order of the fields in the composite index. If a field in the middle is skipped, it is not necessarily in order.
5.3.3 Try to use covering index
Covering index, the fields that need to be queried are all included in the index column, and there is no need to return to the table for query