Article Directory

1. Index overview
1.1 Index overview
MySQL's official definition of index is: Index (Index) is a data structure that helps MySQL obtain data efficiently.
The nature of the index : the index is a data structure. You can simply understand it as a "sorted fast search data structure" that satisfies a specific search algorithm. These data structures point to data in a certain way, so that advanced search algorithms can be implemented on top of these data structures .
1.2 Advantages
(1) Similar to the bibliographic index built by a university library, it can improve the efficiency of data retrieval and reduce the IO cost of the database . This is also the main reason for creating an index.
(2) By creating a unique index, the uniqueness of each row of data in the database table can be guaranteed .
(3) In terms of realizing the referential integrity of data, it can speed up the connection between tables . In other words, the query speed can be improved when the dependent child table and the parent table are jointly queried.
(4) When using grouping and sorting clauses for data query, it can significantly reduce the time of grouping and sorting in the query , and reduce the CPU consumption.
1.3 Disadvantages
Adding indexes also has many disadvantages, mainly in the following aspects:
(1) It takes time to create and maintain indexes , and as the amount of data increases, the time spent will also increase.
(2) The index needs to occupy disk space . In addition to the data space occupied by the data table, each index also occupies a certain amount of physical space and is stored on the disk . If there are a large number of indexes, the index file may be faster than the data file. Maximum file size.
(3) Although the index greatly improves the query speed, it will reduce the speed of updating the table . When adding, deleting and modifying the data in the table, the index should also be maintained dynamically, which reduces the speed of data maintenance.
Therefore, when choosing an index, it is necessary to comprehensively consider the advantages and disadvantages of the index.
hint:
Indexes can improve query speed, but will affect the speed of inserting records. In this case, the best way is to delete the index in the table first, then insert the data, and then create the index after the insertion is complete.
1.6 Common index concepts
According to the physical implementation of the index, the index can be divided into two types: clustered (clustered) and non-clustered (non-clustered) index.
We also refer to non-clustered indexes as secondary indexes or auxiliary indexes.
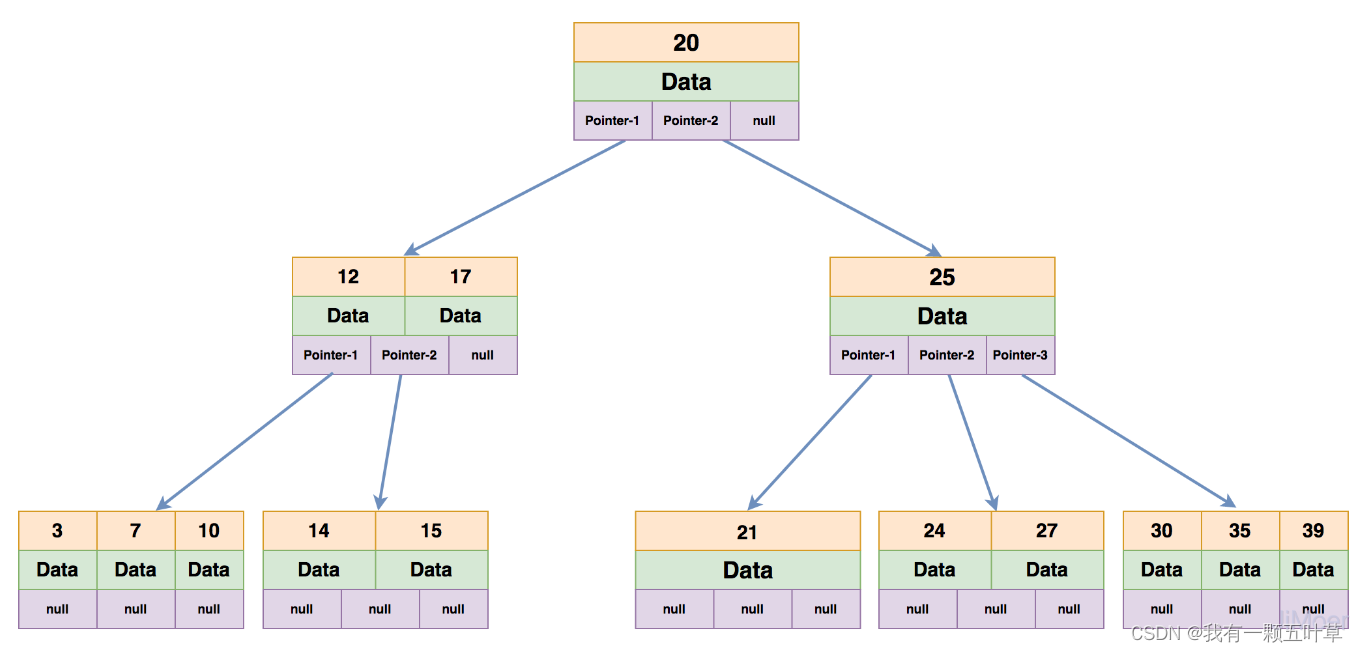
1.6.1 Clustered Index
Features :
- Use the size of the record primary key value to sort records and pages, which includes three meanings:
- The records in the page are arranged in a one-way linked list in order of the size of the primary key.
- Each page storing user records is also arranged in a doubly linked list according to the order of the primary key size of the user records in the page.
- The pages storing the directory entry records are divided into different levels, and the pages in the same level are also arranged in a doubly linked list according to the order of the primary key size of the directory entry records in the page.
-
- The leaf nodes of the B+ tree store complete user records. The so-called complete user record means that the values of all columns (including hidden columns) are stored in this record.
Advantages :
- Data access is faster , because the clustered index stores the index and data in the same B+ tree, so getting data from the clustered index is faster than the non-clustered index (the non-clustered index needs to return the table)
- The clustered index is very fast for the sort lookup and range lookup of the primary key
- According to the order of the clustered index , when the query displays a certain range of data, since the data is closely connected, the database does not need to extract data from multiple data blocks, so **saves a lot of io** operations.
Disadvantages :
- The insertion speed depends heavily on the insertion order . Inserting in the order of the primary key is the fastest way, otherwise page splits will occur, seriously affecting performance. Therefore, for InnoDB tables, we generally define an auto-incrementing ID column as the primary key
- Updating a primary key is expensive because the row being updated will be moved. Therefore, for InnoDB tables, we generally define the primary key as non-updatable
Restrictions :
1.6.2 Secondary index (auxiliary index, non-clustered index)
- Secondary index access requires two index lookups (back to the table) , the first time to find the primary key value, and the second time to find the row data based on the primary key value


Concept : Back to the table We can only determine the primary key value of the record we want to find based on the B+ tree sorted by the size of the c2 column , so if we want to find the complete user record based on the value of the c2 column, we still need to go to the clustered index Check again, this process is called back to the table. That is, querying a complete user record based on the value of column c2 needs to use 2 B+ trees!
Question : Why do we need a table return operation? Isn't it OK to put the complete user record directly in the leaf node?
answer :

Summary : The difference between a clustered index and a non-clustered index:
- The leaf nodes of the clustered index store our data records , and the leaf nodes of the non-clustered index store the data location (primary key) . Nonclustered indexes do not affect the physical storage order of data tables.
- A table can only have one clustered index , because there can only be one way of sorting and storing, but there can be multiple non-clustered indexes , that is, multiple index directories provide data retrieval.
- When using a clustered index, the data query efficiency is high, but if the data is inserted, deleted, updated, etc., the efficiency will be lower than that of the non-clustered index.
1.6.3 Joint Index
We can also use the size of multiple columns as the sorting rule at the same time, that is, create indexes for multiple columns at the same time. For example, we want the B+ tree to be sorted according to the size of the c2 and c3 columns. This contains two meanings :
- First sort each record and page according to column c2.
- When the c2 column of the records is the same, the c3 column is used for sorting.
The schematic diagram of the index established for the c2 and c3 columns is as follows:
Note that the B+ tree built with the size of the c2 and c3 columns as the sorting rule is called a joint index , which is essentially a secondary index. Its meaning is different from the expression of building indexes for columns c2 and c3 respectively. The differences are as follows:
- Building a joint index will only create a B+ tree as shown in the figure above.
- Creating indexes for columns c2 and c3 respectively will create two B+ trees with the size of columns c2 and c3 as the sorting rules.
1.8 The principle of MyISAM index
The following figure is the schematic diagram of MyISAM index

If we create a secondary index on Col2, the structure of this index is shown in the following figure:

1.9 Comparison between MyISAM and InnoDB
The index methods of MyISAM are all "non-clustered", which is different from InnoDB which contains a clustered index.
Summarize the difference between indexes in the two engines :
① In the InnoDB storage engine, we only need to search the clustered index once according to the primary key value to find the corresponding record, but in MyISAM, we need to perform a return table operation, which means that the index established in MyISAM is equivalent to all Both are secondary indexes.
② InnoDB's data file itself is an index file, while the MyISAM index file and data file are separated, and the index file only saves the address of the data record.
③ InnoDB's non-clustered index data domain stores the value of the corresponding record primary key, while the MyISAM index records the address. In other words, all non-clustered indexes of InnoDB refer to the primary key as the data field.
④ MyISAM's table return operation is very fast, because it directly fetches data from the file with the address offset. In contrast, InnoDB searches for records in the clustered index after obtaining the primary key. Although it is not slow, but It is still not as good as directly using the address to access.
⑤ InnoDB requires that the table must have a primary key (MyISAM may not). If not explicitly specified, the MySQL system will automatically select a column that can be non-null and uniquely identify the data record as the primary key. If there is no such column, MySQL automatically generates an implicit field for the InnoDB table as the primary key. The length of this field is 6 bytes, and the type is a long integer.

1.10 The cost of indexing
The index is a good thing, but it cannot be built randomly, it will consume space and time:
- space cost
Every time an index is created, a B+ tree must be built for it. Each node of each B+ tree is a data page. A page will occupy 16KB of storage space by default. A large B+ tree consists of many data pages. Composition, that is a large piece of storage space.
- time cost
Every time the data in the table is added, deleted, or changed , it is necessary to modify each B+ tree index. And we have said that the nodes at each level of the B+ tree are sorted according to the value of the index column from small to large to form a doubly linked list . Whether it is the records in the leaf nodes or the records in the inner nodes (that is, whether it is a user record or a directory entry record), a one-way linked list is formed according to the order of the index column values from small to large. The addition, deletion, and modification operations may damage the ordering of nodes and records, so the storage engine needs additional time to perform operations such as record shifting, page splitting, and page recycling to maintain the ordering of nodes and records. If we build many indexes, the B+ tree corresponding to each index needs to perform related maintenance operations, which will slow down the performance.
The more indexes are built on a table, the more storage space will be occupied, and the performance will be worse when adding, deleting, and modifying. In order to create good and few indexes, we have to learn the conditions under which these indexes work.
2. Index creation and design principles
2.1 Declaration and use of index
2.1.1 Classification of Indexes
MySQL indexes include ordinary indexes, unique indexes, full-text indexes, single-column indexes, multi-column indexes, and spatial indexes.
- In terms of functional logic , there are mainly four types of indexes, namely ordinary indexes, unique indexes, primary key indexes, and full-text indexes.
- According to the physical implementation , the index can be divided into two types: clustered index and non-clustered index.
- According to the number of functional fields , it is divided into single-column index and joint index.
- normal index

- unique index

- primary key index

- single column index

- Multicolumn (composite, union) indexes

- full text index


- Supplement: Spatial Index

Summary : Different storage engines support different index types.
InnoDB: supports B-tree, Full-text and other indexes, but does not support Hash indexes;
MyISAM: supports B-tree, Full-text and other indexes, but does not support Hash indexes;
Memory : supports B-tree, Hash and other indexes, does not support Full-text indexes;
NDB: supports Hash indexes, does not support B-tree, Full-text and other indexes;
Archive: does not support B-tree, Hash, Full-text and other indexes ;
2.1.2 Create an index

2.1.2.1 Create an index when creating a table

CREATE TABLE dept(
-- 主键自动创建索引
dept_id INT PRIMARY KEY AUTO_INCREMENT,
dept_name VARCHAR(20)
);
CREATE TABLE emp(
emp_id INT PRIMARY KEY AUTO_INCREMENT,
-- 自动创建唯一性索引
emp_name VARCHAR(20) UNIQUE,
dept_id INT,
-- 自动创建外键索引
CONSTRAINT emp_dept_id_fk FOREIGN KEY(dept_id) REFERENCES dept(dept_id)
);
However, if you create an index when explicitly creating a table, the basic syntax is as follows:
CREATE TABLE table_name [col_name data_type]
[UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY] [index_name] (col_name [length]) [ASC |
DESC]
- UNIQUE , FULLTEXT and SPATIAL are optional parameters, representing unique index, full-text index and spatial index respectively;
- INDEX and KEY are synonyms, both have the same function, and are used to specify the creation of an index;
- index_name specifies the name of the index, which is an optional parameter. If not specified, MySQL defaults to col_name as the index name;
- col_name is the field column that needs to be indexed, and this column must be selected from multiple columns defined in the data table;
- length is an optional parameter, indicating the length of the index, and only string type fields can specify the index length;
- ASC or DESC specifies ascending or descending order of index value storage.
- Create an ordinary index
Create an ordinary index on the year_publication field in the book table. The SQL statement is as follows:
CREATE TABLE book(
book_id INT ,
book_name VARCHAR(100),
authors VARCHAR(100),
info VARCHAR(100) ,
comment VARCHAR(100),
year_publication YEAR,
-- 声明索引
INDEX index_bname(book_name)
);
- Create a unique index
CREATE TABLE test1(
id INT NOT NULL,
name varchar(30) NOT NULL,
-- 声明唯一索引
UNIQUE INDEX uk_index_name(name)
);
After the statement is executed, use SHOW CREATE TABLE to view the table structure:
SHOW INDEX FROM test1 \G
- After the primary key index
is set as the primary key, the database will automatically create an index. InnoDB is a clustered index. The syntax is:
- Build indexes along with the table:
CREATE TABLE student (
id INT(10) UNSIGNED AUTO_INCREMENT ,
student_no VARCHAR(200),
student_name VARCHAR(200),
PRIMARY KEY(id)
);
- Drop the primary key index:
ALTER TABLE student drop PRIMARY KEY ;
- Modify the primary key index: you must first delete (drop) the original index, and then create (add) the index
- Create a single-column index
CREATE TABLE test2(
id INT NOT NULL,
name CHAR(50) NULL,
INDEX single_idx_name(name(20))
);
After the statement is executed, use SHOW CREATE TABLE to view the table structure:
SHOW INDEX FROM test2 \G
- Example of creating a joint index
: create a table test3, and create a combined index on the id, name, and age fields in the table. The SQL statement is as follows:
CREATE TABLE test3(
id INT(11) NOT NULL,
name CHAR(30) NOT NULL,
age INT(11) NOT NULL,
info VARCHAR(255),
INDEX multi_idx(id,name,age)
);
Note : When querying, follow the leftmost prefix principle, otherwise the index cannot be named.
Example 1 of creating a full-text index : create a table test4, and create a full-text index on the info field in the table. The SQL statement is as follows:
CREATE TABLE test4(
id INT NOT NULL,
name CHAR(30) NOT NULL,
age INT NOT NULL,
info VARCHAR(255),
FULLTEXT INDEX futxt_idx_info(info)
) ENGINE=MyISAM;
In MySQL5.7 and later versions, it is not necessary to specify the last ENGINE, because InnoDB supports full-text indexing in this version.
Example 2:
CREATE TABLE articles (
id INT UNSIGNED AUTO_INCREMENT PRIMARY KEY,
title VARCHAR (200),
body TEXT,
FULLTEXT index (title, body)
) ENGINE = INNODB ;
Example 3:
CREATE TABLE `papers` (
`id` int(10) unsigned NOT NULL AUTO_INCREMENT,
`title` varchar(200) DEFAULT NULL,
`content` text,
PRIMARY KEY (`id`),
FULLTEXT KEY `title` (`title`,`content`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8;
Queries different from the like method:
SELECT * FROM papers WHERE content LIKE ‘%查询字符串%’;
The full-text index is queried in match+against mode:
SELECT * FROM papers WHERE MATCH(title,content) AGAINST (‘查询字符串’);
important point:
- Before using the full-text index, find out the version support;
- Full-text indexing is N times faster than like + %, but there may be precision issues;
- If a large amount of data needs to be indexed full-text, it is recommended to add data first, and then create an index.
- Creating a spatial index
When creating a spatial index, it is required that the field of the spatial type must be non- null .
Example: To create a table test5 and create a spatial index on the field whose spatial type is GEOMETRY, the SQL statement is as follows:
CREATE TABLE test5(
geo GEOMETRY NOT NULL,
SPATIAL INDEX spa_idx_geo(geo)
) ENGINE=MyISAM;
2.1.2.2 Create an index on an existing table
To create an index on an existing table, use the ALTER TABLE statement or the CREATE INDEX statement.
- Using the ALTER TABLE statement to create an index The basic syntax of the ALTER TABLE statement to create an index is as follows:
ALTER TABLE table_name ADD [UNIQUE | FULLTEXT | SPATIAL] [INDEX | KEY]
[index_name] (col_name[length],... [ASC | DESC])
- Use CREATE INDEX to create an index The CREATE INDEX statement can add an index to an existing table. In MySQL,
CREATE INDEX is mapped to an ALTER TABLE statement. The basic syntax structure is:
CREATE [UNIQUE | FULLTEXT | SPATIAL] INDEX index_name
ON table_name (col_name[length],...) [ASC | DESC]
2.1.3 Delete Index
- Using ALTER TABLE to delete an index The basic syntax format of ALTER TABLE to delete an index is as follows:
ALTER TABLE table_name DROP INDEX index_name;
- Use the DROP INDEX statement to delete an index DROP INDEX The basic syntax format for deleting an index is as follows:
DROP INDEX index_name ON table_name;
Tip: When dropping a column in a table, if the column being dropped is part of an index, that column is also dropped from the index. If
all the columns that make up the index are dropped, the entire index will be dropped.
