Introductory Guide to Deep Learning in 2023 (10) - CUDA Programming Basics
In the previous article, we took a quick look at the programming of SIMD and GPGPU. However, the lines are too thick, and you will definitely feel dizzy if you encounter problems when developing a large model.
So we still need to go deep into CUDA to explore.
Get CUDA device information
Before using CUDA devices, first we have to find out whether CUDA is supported, there are several devices. This can be done bycudaGetDeviceCount
int deviceCount;
cudaError_t cudaError;
cudaError = cudaGetDeviceCount(&deviceCount);
if (cudaError == cudaSuccess) {
cout << "There are " << deviceCount << " cuda devices." << endl;
}
After obtaining how many devices are supported, we can traverse the devices to use the cudaGetDeviceProperties function to view device information.
for (int i = 0; i < deviceCount; i++)
{
cudaError = cudaGetDeviceProperties(&props, i);
if (cudaError == cudaSuccess) {
cout << "Device Name: " << props.name << endl;
cout << "Compute Capability version: " << props.major << "." << props.minor << endl;
}
}
Here's what I get on my computer:
There are 1 cuda devices.
Device Name: NVIDIA GeForce RTX 3060
Compute Capability version: 8.6
struct cudaDeviceProp {
char name[256];
cudaUUID_t uuid;
size_t totalGlobalMem;
size_t sharedMemPerBlock;
int regsPerBlock;
int warpSize;
size_t memPitch;
int maxThreadsPerBlock;
int maxThreadsDim[3];
int maxGridSize[3];
int clockRate;
size_t totalConstMem;
int major;
int minor;
size_t textureAlignment;
size_t texturePitchAlignment;
int deviceOverlap;
int multiProcessorCount;
int kernelExecTimeoutEnabled;
int integrated;
int canMapHostMemory;
int computeMode;
int maxTexture1D;
int maxTexture1DMipmap;
int maxTexture1DLinear;
int maxTexture2D[2];
int maxTexture2DMipmap[2];
int maxTexture2DLinear[3];
int maxTexture2DGather[2];
int maxTexture3D[3];
int maxTexture3DAlt[3];
int maxTextureCubemap;
int maxTexture1DLayered[2];
int maxTexture2DLayered[3];
int maxTextureCubemapLayered[2];
int maxSurface1D;
int maxSurface2D[2];
int maxSurface3D[3];
int maxSurface1DLayered[2];
int maxSurface2DLayered[3];
int maxSurfaceCubemap;
int maxSurfaceCubemapLayered[2];
size_t surfaceAlignment;
int concurrentKernels;
int ECCEnabled;
int pciBusID;
int pciDeviceID;
int pciDomainID;
int tccDriver;
int asyncEngineCount;
int unifiedAddressing;
int memoryClockRate;
int memoryBusWidth;
int l2CacheSize;
int persistingL2CacheMaxSize;
int maxThreadsPerMultiProcessor;
int streamPrioritiesSupported;
int globalL1CacheSupported;
int localL1CacheSupported;
size_t sharedMemPerMultiprocessor;
int regsPerMultiprocessor;
int managedMemory;
int isMultiGpuBoard;
int multiGpuBoardGroupID;
int singleToDoublePrecisionPerfRatio;
int pageableMemoryAccess;
int concurrentManagedAccess;
int computePreemptionSupported;
int canUseHostPointerForRegisteredMem;
int cooperativeLaunch;
int cooperativeMultiDeviceLaunch;
int pageableMemoryAccessUsesHostPageTables;
int directManagedMemAccessFromHost;
int accessPolicyMaxWindowSize;
}
Let us introduce a few of the important ones:
- totalGlobalMem is the total amount of global memory available on the device, in bytes.
- sharedMemPerBlock is the maximum amount of shared memory available to a thread block, in bytes.
- regsPerBlock is the maximum number of 32-bit registers available to a thread block.
- warpSize is the size of the warp in threads.
- memPitch is the maximum pitch, in bytes, allowed by memory copy functions involving memory regions allocated via cudaMallocPitch().
- maxThreadsPerBlock is the maximum number of threads per block.
- maxThreadsDim[3] contains the maximum size of each dimension of a block.
- maxGridSize[3] contains the maximum size of each dimension of a grid.
- clockRate is the clock frequency in kilohertz.
- totalConstMem is the total amount of constant memory available on the device, in bytes.
- major, minor are the major and minor revision numbers that define the computing capabilities of the device.
- multiProcessorCount is the number of multiprocessors on the device.
- memoryClockRate is the peak memory clock rate in kilohertz.
- memoryBusWidth is the memory bus width in bits.
- memoryPoolsSupported is 1 if the device supports the use of cudaMallocAsync and cudaMemPool family APIs, otherwise 0
- gpuDirectRDMASupported is 1 if the device supports the GPUDirect RDMA API, otherwise 0
- gpuDirectRDMAFlushWritesOptions is a bitmask interpreted according to the cudaFlushGPUDirectRDMAWritesOptions enumeration
- gpuDirectRDMAWritesOrdering see cudaGPUDirectRDMAWritesOrdering enumeration value
- memoryPoolSupportedHandleTypes is a bitmask of handle types supported with mempool-based IPC
- deferredMappingCudaArraySupported is 1 if the device supports deferred mapped CUDA arrays and CUDA mipmapped arrays
- ipcEventSupported is 1 if the device supports IPC events, otherwise 0
- unifiedFunctionPointers is 1 if the device supports unified pointers, 0 otherwise
With more information, let's print some output:
for (int i = 0; i < deviceCount; i++)
{
cudaError = cudaGetDeviceProperties(&props, i);
if (cudaError == cudaSuccess) {
cout << "Device Name: " << props.name << endl;
cout << "Compute Capability version: " << props.major << "." << props.minor << endl;
cout << "设备上可用的全局内存总量:(G字节)" << props.totalGlobalMem / 1024 / 1024 / 1024 << endl;
cout << "时钟频率(以MHz为单位):" << props.clockRate / 1000 << endl;
cout << "设备上多处理器的数量:" << props.multiProcessorCount << endl;
cout << "每个块的最大线程数:" << props.maxThreadsPerBlock <<endl;
cout << "内存总线宽度(位)" << props.memoryBusWidth << endl;
cout << "一个块的每个维度的最大尺寸:" << props.maxThreadsDim[0] << ","<< props.maxThreadsDim[1] << "," << props.maxThreadsDim[2] << endl;
cout << "一个网格的每个维度的最大尺寸:" << props.maxGridSize[0] << "," << props.maxGridSize[1] << "," << props.maxGridSize[2] <<endl;
}
}
The result of running on my 3060 graphics card:
Device Name: NVIDIA GeForce RTX 3060
Compute Capability version: 8.6
设备上可用的全局内存总量:(G字节)11
时钟频率(以MHz为单位):1777
设备上多处理器的数量:28
每个块的最大线程数:1024
内存总线宽度(位)192
一个块的每个维度的最大尺寸:1024,1024,64
一个网格的每个维度的最大尺寸:2147483647,65535,65535
Thread Blocks and Thread Grids
In CUDA, thread block (block) and thread grid (grid) are two very important concepts, which are used to describe the thread organization method when GPU executes parallel tasks. A thread block is composed of several threads (thread), which can be executed in parallel on the same GPU multiprocessor (multiprocessor). The thread grid is composed of several thread blocks, which can be executed in parallel on the entire GPU device. Each thread block and thread grid has a unique index used to identify and control threads in CUDA C/C++ GPU kernel functions.
In CUDA, the dim3 structure is used to represent the dimensions of thread blocks and thread grids. For example, dim3(2,2) represents a 2D thread grid with 2x2=4 thread blocks; dim3(2,2,2) represents a 3D thread block with 2x2x2=8 threads. When starting the GPU kernel function, you can use the <<< >>> syntax to specify the size of the thread grid and thread block, for example:
dim3 dimGrid(2, 2);
dim3 dimBlock(2, 2, 2);
myKernel<<<dimGrid, dimBlock>>>(...);
Here dimGrid and dimBlock are used to specify the size of the thread grid and thread block, and then call the myKernel function and pass the necessary parameters. When executing GPU kernel functions, CUDA will start corresponding threads according to the specified thread grid and thread block size, and allocate and cooperate with them, so as to complete the parallel execution of tasks. The organization and size of thread blocks and thread grids can be adjusted and optimized according to specific application scenarios and hardware environments to achieve optimal performance and efficiency.
Let's take a look at how to use the thread grid and thread block in the kernel function.
__global__ void testKernel(int val) {
printf("[%d, %d]:\t\tValue is:%d\n", blockIdx.y * gridDim.x + blockIdx.x,
threadIdx.z * blockDim.x * blockDim.y + threadIdx.y * blockDim.x +
threadIdx.x,
val);
}
There are a few points above that we need to explain:
__global__: It does not indicate that this is a global function, but that this is a GPU kernel function.- blockIdx: is a built-in variable that indicates the index of the block where the current thread is located. It is a structure type, which contains three member variables, which respectively represent the index values of the current block in the three dimensions of x, y, and z.
- threadIdx: It is also a built-in variable, indicating the index of the current thread in the block. It is also a structure type, which contains three member variables, which respectively represent the index values of the current thread in the three dimensions of x, y, and z.
- blockDim: It is also a built-in variable, indicating the dimension of each block (block), including three dimensions of x, y, and z.
In CUDA, each kernel function (kernel function) is assigned to execute in one or more blocks (block), and each block contains several threads (thread), which can be executed in parallel on the GPU. By accessing the member variable of blockIdx, you can determine where the block where the current thread is located, so as to perform specific calculations in the kernel function. For example, blockIdx.x can be used to indicate the index value on the x-axis of the block where the current thread is located. In CUDA programming, it is usually necessary to use blockIdx and threadIdx to determine the unique identifier of each thread in the parallel execution of the entire GPU, so as to allocate and cooperate with tasks.
Then pass dimGrid and dimBlock to testKernel.
// Kernel configuration, where a two-dimensional grid and
// three-dimensional blocks are configured.
dim3 dimGrid(2, 2);
dim3 dimBlock(2, 2, 2);
testKernel << <dimGrid, dimBlock >> > (10);
Save the following file as kernel.cu, then compile it through the nvcc command, and finally run the generated executable file.
// System includes
#include <stdio.h>
#include <assert.h>
#include <iostream>
// CUDA runtime
#include <cuda_runtime.h>
using namespace std;
__global__ void testKernel(int val) {
printf("[%d, %d]:\t\tValue is:%d\n", blockIdx.y * gridDim.x + blockIdx.x,
threadIdx.z * blockDim.x * blockDim.y + threadIdx.y * blockDim.x +
threadIdx.x,
val);
}
int main(int argc, char** argv) {
int devID;
cudaDeviceProp props;
int deviceCount;
cudaError_t cudaError;
cudaError = cudaGetDeviceCount(&deviceCount);
if (cudaError == cudaSuccess) {
cout << "There are " << deviceCount << " cuda devices." << endl;
}
for (int i = 0; i < deviceCount; i++)
{
cudaError = cudaGetDeviceProperties(&props, i);
if (cudaError == cudaSuccess) {
cout << "Device Name: " << props.name << endl;
cout << "Compute Capability version: " << props.major << "." << props.minor << endl;
cout << "设备上可用的全局内存总量:(G字节)" << props.totalGlobalMem / 1024 / 1024 / 1024 << endl;
cout << "时钟频率(以MHz为单位):" << props.clockRate / 1000 << endl;
cout << "设备上多处理器的数量:" << props.multiProcessorCount << endl;
cout << "每个块的最大线程数:" << props.maxThreadsPerBlock <<endl;
cout << "内存总线宽度(位)" << props.memoryBusWidth << endl;
cout << "一个块的每个维度的最大尺寸:" << props.maxThreadsDim[0] << ","<< props.maxThreadsDim[1] << "," << props.maxThreadsDim[2] << endl;
cout << "一个网格的每个维度的最大尺寸:" << props.maxGridSize[0] << "," << props.maxGridSize[1] << "," << props.maxGridSize[2] <<endl;
}
}
// Kernel configuration, where a two-dimensional grid and
// three-dimensional blocks are configured.
dim3 dimGrid(2, 2);
dim3 dimBlock(2, 2, 2);
testKernel << <dimGrid, dimBlock >> > (10);
cudaDeviceSynchronize();
return EXIT_SUCCESS;
}
Regardless of the previous output, we only look at the results of the next 32 threads:
[1, 0]: Value is:10
[1, 1]: Value is:10
[1, 2]: Value is:10
[1, 3]: Value is:10
[1, 4]: Value is:10
[1, 5]: Value is:10
[1, 6]: Value is:10
[1, 7]: Value is:10
[0, 0]: Value is:10
[0, 1]: Value is:10
[0, 2]: Value is:10
[0, 3]: Value is:10
[0, 4]: Value is:10
[0, 5]: Value is:10
[0, 6]: Value is:10
[0, 7]: Value is:10
[3, 0]: Value is:10
[3, 1]: Value is:10
[3, 2]: Value is:10
[3, 3]: Value is:10
[3, 4]: Value is:10
[3, 5]: Value is:10
[3, 6]: Value is:10
[3, 7]: Value is:10
[2, 0]: Value is:10
[2, 1]: Value is:10
[2, 2]: Value is:10
[2, 3]: Value is:10
[2, 4]: Value is:10
[2, 5]: Value is:10
[2, 6]: Value is:10
[2, 7]: Value is:10
The front indicates a thread block, and the back indicates a thread.
If you are doing GPU programming for the first time, it is easy to get confused. Let me explain this calculation method. In fact, it is an algorithm to simulate a multidimensional array with a one-dimensional array.
blockIdx.y * gridDim.x + blockIdx.x represents the unique identifier of the thread block where the current thread is located in the two-dimensional thread grid. Among them, gridDim.x indicates the number of thread blocks in the thread grid in the x direction, blockIdx.x indicates the index value of the current thread block in the x direction, and blockIdx.y indicates the index value of the current thread block in the y direction.
threadIdx.z * blockDim.x * blockDim.y indicates the offset of the current thread in the z direction, that is, the space occupied by all previous threads. Then, threadIdx.y * blockDim.x represents the offset of the current thread in the y direction, that is, the offset of the current thread on the z plane. Finally, threadIdx.x indicates the offset of the current thread in the x direction, that is, the offset of the current thread on a certain row of the z plane.
Knowing this, we try to change each thread block from 8 threads to 12:
dim3 dimGrid(2, 2);
dim3 dimBlock(2, 2, 3);
testKernel << <dimGrid, dimBlock >> > (12);
The result of the operation is as follows:
[0, 0]: Value is:12
[0, 1]: Value is:12
[0, 2]: Value is:12
[0, 3]: Value is:12
[0, 4]: Value is:12
[0, 5]: Value is:12
[0, 6]: Value is:12
[0, 7]: Value is:12
[0, 8]: Value is:12
[0, 9]: Value is:12
[0, 10]: Value is:12
[0, 11]: Value is:12
[1, 0]: Value is:12
[1, 1]: Value is:12
[1, 2]: Value is:12
[1, 3]: Value is:12
[1, 4]: Value is:12
[1, 5]: Value is:12
[1, 6]: Value is:12
[1, 7]: Value is:12
[1, 8]: Value is:12
[1, 9]: Value is:12
[1, 10]: Value is:12
[1, 11]: Value is:12
[3, 0]: Value is:12
[3, 1]: Value is:12
[3, 2]: Value is:12
[3, 3]: Value is:12
[3, 4]: Value is:12
[3, 5]: Value is:12
[3, 6]: Value is:12
[3, 7]: Value is:12
[3, 8]: Value is:12
[3, 9]: Value is:12
[3, 10]: Value is:12
[3, 11]: Value is:12
[2, 0]: Value is:12
[2, 1]: Value is:12
[2, 2]: Value is:12
[2, 3]: Value is:12
[2, 4]: Value is:12
[2, 5]: Value is:12
[2, 6]: Value is:12
[2, 7]: Value is:12
[2, 8]: Value is:12
[2, 9]: Value is:12
[2, 10]: Value is:12
[2, 11]: Value is:12
Next, we officially start the journey of true concurrency, and calculate sine in the above 48 threads at the same time.
For calculations in the GPU, the original math library on our CPU is no longer useful. We need to use the GPU’s own. In CUDA we use __sinf:
__global__ void testKernel(float val) {
printf("[%d, %d]:\t\tValue is:%f\n", blockIdx.y * gridDim.x + blockIdx.x,
threadIdx.z * blockDim.x * blockDim.y + threadIdx.y * blockDim.x +
threadIdx.x,
__sinf(val* threadIdx.z * blockDim.x * blockDim.y + threadIdx.y * blockDim.x +
threadIdx.x));
}
In the main function, just change one:
dim3 dimGrid(2, 2);
dim3 dimBlock(2, 2, 3);
testKernel << <dimGrid, dimBlock >> > (0.5);
The result of the operation is as follows:
[0, 0]: Value is:0.000000
[0, 1]: Value is:0.841471
[0, 2]: Value is:0.909297
[0, 3]: Value is:0.141120
[0, 4]: Value is:0.909297
[0, 5]: Value is:0.141120
[0, 6]: Value is:-0.756802
[0, 7]: Value is:-0.958924
[0, 8]: Value is:-0.756802
[0, 9]: Value is:-0.958924
[0, 10]: Value is:-0.279416
[0, 11]: Value is:0.656986
[1, 0]: Value is:0.000000
[1, 1]: Value is:0.841471
[1, 2]: Value is:0.909297
[1, 3]: Value is:0.141120
[1, 4]: Value is:0.909297
[1, 5]: Value is:0.141120
[1, 6]: Value is:-0.756802
[1, 7]: Value is:-0.958924
[1, 8]: Value is:-0.756802
[1, 9]: Value is:-0.958924
[1, 10]: Value is:-0.279416
[1, 11]: Value is:0.656986
[3, 0]: Value is:0.000000
[3, 1]: Value is:0.841471
[3, 2]: Value is:0.909297
[3, 3]: Value is:0.141120
[3, 4]: Value is:0.909297
[3, 5]: Value is:0.141120
[3, 6]: Value is:-0.756802
[3, 7]: Value is:-0.958924
[3, 8]: Value is:-0.756802
[3, 9]: Value is:-0.958924
[3, 10]: Value is:-0.279416
[3, 11]: Value is:0.656986
[2, 0]: Value is:0.000000
[2, 1]: Value is:0.841471
[2, 2]: Value is:0.909297
[2, 3]: Value is:0.141120
[2, 4]: Value is:0.909297
[2, 5]: Value is:0.141120
[2, 6]: Value is:-0.756802
[2, 7]: Value is:-0.958924
[2, 8]: Value is:-0.756802
[2, 9]: Value is:-0.958924
[2, 10]: Value is:-0.279416
[2, 11]: Value is:0.656986
Data exchange between memory and video memory
Above we passed an immediate number to the GPU kernel function. We are far away from officially being able to use GPU for CUDA programming, and we are short of allocating GPU memory and copying between video memory and memory.
Similar to malloc, CUDA uses cudaMalloc to allocate GPU memory, and its prototype is:
cudaError_t cudaMalloc(void **devPtr, size_t size);
Parameter explanation:
- devPtr: Returns a pointer to the allocated device memory.
- size: The size of the memory to be allocated, in bytes.
return value:
- cudaSuccess: Allocation succeeded.
- cudaErrorInvalidValue: size is zero or devPtr is NULL.
- cudaErrorMemoryAllocation: Memory allocation failed.
For general usage, remember to release it with cudaFree when you run out:
float* devPtr;
cudaMalloc(&devPtr, size * sizeof(float));
...
cudaFree(devPtr);
After the memory is allocated, it is copied from the memory to the video memory. Also similar to memcpy, done through cudaMemcpy.
cudaError_t cudaMemcpy(void* dst, const void* src, size_t count, cudaMemcpyKind kind);
Parameter explanation:
- dst: pointer to destination memory.
- src: pointer to source memory.
- count: The memory size to be copied, in bytes.
- kind: the type of copy, which can be:
- cudaMemcpyHostToHost
- cudaMemcpyHostToDevice
- cudaMemcpyDeviceToHost
- cudaMemcpyDeviceToDevice
return value:
- cudaSuccess: The copy was successful.
- cudaErrorInvalidValue: count or dst or src is NULL.
- cudaErrorMemoryAllocation: Memory allocation failed.
Let's write an example of calculating the square root with CUDA:
const int n = 1024;
size_t size = n * sizeof(float);
float* h_in = (float*)malloc(size);
float* h_out = (float*)malloc(size);
float* d_in, * d_out;
// Initialize input array
for (int i = 0; i < n; ++i) {
h_in[i] = (float)i;
}
// Allocate device memory
cudaMalloc(&d_in, size);
cudaMalloc(&d_out, size);
// Copy input data to device
cudaMemcpy(d_in, h_in, size, cudaMemcpyHostToDevice);
// Launch kernel
int threadsPerBlock = 256;
int blocksPerGrid = (n + threadsPerBlock - 1) / threadsPerBlock;
sqrtKernel << <blocksPerGrid, threadsPerBlock >> > (d_in, d_out, n);
// Copy output data to host
cudaMemcpy(h_out, d_out, size, cudaMemcpyDeviceToHost);
// Verify results
for (int i = 0; i < n; ++i) {
if (fabsf(h_out[i] - sqrtf(h_in[i])) > 1e-5) {
printf("Error: h_out[%d] = %f, sqrtf(h_in[%d]) = %f\n", i, h_out[i], i, sqrtf(h_in[i]));
}
}
printf("Success!\n");
// Free memory
free(h_in);
free(h_out);
cudaFree(d_in);
cudaFree(d_out);
Everyone pays attention to the number of thread blocks and the number of threads. We do not use multi-dimensional here, but use two integers to calculate:
int threadsPerBlock = 256;
int blocksPerGrid = (n + threadsPerBlock - 1) / threadsPerBlock;
sqrtKernel << <blocksPerGrid, threadsPerBlock >> > (d_in, d_out, n);
We use 4 blocks with 256 threads per block.
At this point, there is no need to calculate y and z, only the x dimension can be calculated:
int i = blockIdx.x * blockDim.x + threadIdx.x;
But note that blockIdx and threadIdx are still three-dimensional, and the y and z dimensions are still valid, but they become 0.
Our kernel function is written like this:
__global__ void sqrtKernel(float* in, float* out, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
out[i] = sqrtf(in[i]);
printf("[%d, %d]:\t\tValue is:%f\n", blockIdx.y * gridDim.x + blockIdx.x,
threadIdx.z * blockDim.x * blockDim.y + threadIdx.y * blockDim.x +
threadIdx.x, out[i]);
}
}
Of course, because the y and z of block and thread are both 0, it is no different from just writing x:
__global__ void sqrtKernel(float* in, float* out, int n) {
int i = blockIdx.x * blockDim.x + threadIdx.x;
if (i < n) {
out[i] = sqrtf(in[i]);
printf("[%d, %d]:\t\tValue is:%f\n", blockIdx.x, threadIdx.x, out[i]);
}
}
Use packaged library
In addition to the CUDA runtime, NVidia also provides many specialized libraries for the main application scenarios.
For example, for matrix operations, there is the cuBLAS library. Some libraries are installed along with the CUDA toolkit, such as cuBLAS, cuFFT. There are also some libraries that need to be specially downloaded and installed, such as the cudnn library.
Let me emphasize here that the so-called library is not a module to be called in the kernel function, but a fully encapsulated function that needs to be implemented in the kernel function. So when using the package library, nvcc is not needed, just refer to a library.
Let's look at an example of computing matrix multiplication using the cuBLAS library.
There are four main functions used by the cuBLAS library to calculate matrix multiplication:
- cublasCreate: create cublas handle
- cublasDestroy: Release the cublas handle
- cublasSetVector: Copy data between CPU and GPU memory
- cublasSgemm: matrix multiplication operation
cublasStatus_t cublasSetVector(int n, int elemSize, const void *x, int incx, void *y, int incy)
in:
- n is the number of elements to copy
- elemSize is the size of each element in bytes
- x is the starting address of the data in the host-side (CPU) memory
- incx is the span between adjacent elements in x
- y is the data start address in the GPU device memory
- incy is the span between adjacent elements in y
cublasStatus_t cublasSgemm(cublasHandle_t handle,
cublasOperation_t transa, cublasOperation_t transb,
int m, int n, int k,
const float *alpha, const float *A, int lda,
const float *B, int ldb, const float *beta,
float *C, int ldc)
in:
- handle is the cuBLAS handle;
- transa is the transpose option of A matrix, the value is CUBLAS_OP_N or CUBLAS_OP_T, which means no transpose and transpose respectively;
- transb is the transpose option of B matrix; m, n, k are the dimensions of A, B, and C matrices respectively;
- alpha is a scalar value used to scale the product of the A and B matrices into the C matrix;
- A is the starting address of A matrix;
- lda is the span between adjacent columns in the A matrix;
- B is the starting address of B matrix;
- ldb is the span between adjacent columns in the B matrix;
- beta is a scalar value used to scale the values in the C matrix;
- C is the starting address of the C matrix;
- ldc is the span between adjacent columns in the C matrix.
Let's simplify and write an example, mainly to illustrate the usage of the function:
#include <stdio.h>
#include <cuda_runtime.h>
#include <cublas_v2.h>
int main() {
int m = 1024, n = 1024, k = 1024;
float* h_A = (float*)malloc(m * k * sizeof(float));
float* h_B = (float*)malloc(k * n * sizeof(float));
float* h_C = (float*)malloc(m * n * sizeof(float));
for (int i = 0; i < m * k; ++i) {
h_A[i] = (float)i;
}
for (int i = 0; i < k * n; ++i) {
h_B[i] = (float)i;
}
float* d_A, * d_B, * d_C;
cudaMalloc(&d_A, m * k * sizeof(float));
cudaMalloc(&d_B, k * n * sizeof(float));
cudaMalloc(&d_C, m * n * sizeof(float));
// Copy data from host to device
cublasSetVector(m * k, sizeof(float), h_A, 1, d_A, 1);
cublasSetVector(k * n, sizeof(float), h_B, 1, d_B, 1);
// Initialize cuBLAS
cublasHandle_t handle;
cublasCreate(&handle);
// Do matrix multiplication
const float alpha = 1.0f, beta = 0.0f;
cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, m, n, k,
&alpha, d_A, m, d_B, k, &beta, d_C, m);
// Copy data from device to host
cublasGetVector(m * n, sizeof(float), d_C, 1, h_C, 1);
// Free memory
free(h_A);
free(h_B);
free(h_C);
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// Destroy cuBLAS handle
cublasDestroy(handle);
return 0;
}
Of course, the above is just an example, and there is no error handling, which is wrong.
Let's refer to the official example:
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
/* Includes, cuda */
#include <cublas_v2.h>
#include <cuda_runtime.h>
#include <helper_cuda.h>
/* Matrix size */
#define N (275)
/* Host implementation of a simple version of sgemm */
static void simple_sgemm(int n, float alpha, const float *A, const float *B,
float beta, float *C) {
int i;
int j;
int k;
for (i = 0; i < n; ++i) {
for (j = 0; j < n; ++j) {
float prod = 0;
for (k = 0; k < n; ++k) {
prod += A[k * n + i] * B[j * n + k];
}
C[j * n + i] = alpha * prod + beta * C[j * n + i];
}
}
}
/* Main */
int main(int argc, char **argv) {
cublasStatus_t status;
float *h_A;
float *h_B;
float *h_C;
float *h_C_ref;
float *d_A = 0;
float *d_B = 0;
float *d_C = 0;
float alpha = 1.0f;
float beta = 0.0f;
int n2 = N * N;
int i;
float error_norm;
float ref_norm;
float diff;
cublasHandle_t handle;
/* Initialize CUBLAS */
printf("simpleCUBLAS test running..\n");
status = cublasCreate(&handle);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! CUBLAS initialization error\n");
return EXIT_FAILURE;
}
/* Allocate host memory for the matrices */
h_A = reinterpret_cast<float *>(malloc(n2 * sizeof(h_A[0])));
if (h_A == 0) {
fprintf(stderr, "!!!! host memory allocation error (A)\n");
return EXIT_FAILURE;
}
h_B = reinterpret_cast<float *>(malloc(n2 * sizeof(h_B[0])));
if (h_B == 0) {
fprintf(stderr, "!!!! host memory allocation error (B)\n");
return EXIT_FAILURE;
}
h_C = reinterpret_cast<float *>(malloc(n2 * sizeof(h_C[0])));
if (h_C == 0) {
fprintf(stderr, "!!!! host memory allocation error (C)\n");
return EXIT_FAILURE;
}
/* Fill the matrices with test data */
for (i = 0; i < n2; i++) {
h_A[i] = rand() / static_cast<float>(RAND_MAX);
h_B[i] = rand() / static_cast<float>(RAND_MAX);
h_C[i] = rand() / static_cast<float>(RAND_MAX);
}
/* Allocate device memory for the matrices */
if (cudaMalloc(reinterpret_cast<void **>(&d_A), n2 * sizeof(d_A[0])) !=
cudaSuccess) {
fprintf(stderr, "!!!! device memory allocation error (allocate A)\n");
return EXIT_FAILURE;
}
if (cudaMalloc(reinterpret_cast<void **>(&d_B), n2 * sizeof(d_B[0])) !=
cudaSuccess) {
fprintf(stderr, "!!!! device memory allocation error (allocate B)\n");
return EXIT_FAILURE;
}
if (cudaMalloc(reinterpret_cast<void **>(&d_C), n2 * sizeof(d_C[0])) !=
cudaSuccess) {
fprintf(stderr, "!!!! device memory allocation error (allocate C)\n");
return EXIT_FAILURE;
}
/* Initialize the device matrices with the host matrices */
status = cublasSetVector(n2, sizeof(h_A[0]), h_A, 1, d_A, 1);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! device access error (write A)\n");
return EXIT_FAILURE;
}
status = cublasSetVector(n2, sizeof(h_B[0]), h_B, 1, d_B, 1);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! device access error (write B)\n");
return EXIT_FAILURE;
}
status = cublasSetVector(n2, sizeof(h_C[0]), h_C, 1, d_C, 1);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! device access error (write C)\n");
return EXIT_FAILURE;
}
/* Performs operation using plain C code */
simple_sgemm(N, alpha, h_A, h_B, beta, h_C);
h_C_ref = h_C;
/* Performs operation using cublas */
status = cublasSgemm(handle, CUBLAS_OP_N, CUBLAS_OP_N, N, N, N, &alpha, d_A,
N, d_B, N, &beta, d_C, N);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! kernel execution error.\n");
return EXIT_FAILURE;
}
/* Allocate host memory for reading back the result from device memory */
h_C = reinterpret_cast<float *>(malloc(n2 * sizeof(h_C[0])));
if (h_C == 0) {
fprintf(stderr, "!!!! host memory allocation error (C)\n");
return EXIT_FAILURE;
}
/* Read the result back */
status = cublasGetVector(n2, sizeof(h_C[0]), d_C, 1, h_C, 1);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! device access error (read C)\n");
return EXIT_FAILURE;
}
/* Check result against reference */
error_norm = 0;
ref_norm = 0;
for (i = 0; i < n2; ++i) {
diff = h_C_ref[i] - h_C[i];
error_norm += diff * diff;
ref_norm += h_C_ref[i] * h_C_ref[i];
}
error_norm = static_cast<float>(sqrt(static_cast<double>(error_norm)));
ref_norm = static_cast<float>(sqrt(static_cast<double>(ref_norm)));
if (fabs(ref_norm) < 1e-7) {
fprintf(stderr, "!!!! reference norm is 0\n");
return EXIT_FAILURE;
}
/* Memory clean up */
free(h_A);
free(h_B);
free(h_C);
free(h_C_ref);
if (cudaFree(d_A) != cudaSuccess) {
fprintf(stderr, "!!!! memory free error (A)\n");
return EXIT_FAILURE;
}
if (cudaFree(d_B) != cudaSuccess) {
fprintf(stderr, "!!!! memory free error (B)\n");
return EXIT_FAILURE;
}
if (cudaFree(d_C) != cudaSuccess) {
fprintf(stderr, "!!!! memory free error (C)\n");
return EXIT_FAILURE;
}
/* Shutdown */
status = cublasDestroy(handle);
if (status != CUBLAS_STATUS_SUCCESS) {
fprintf(stderr, "!!!! shutdown error (A)\n");
return EXIT_FAILURE;
}
if (error_norm / ref_norm < 1e-6f) {
printf("simpleCUBLAS test passed.\n");
exit(EXIT_SUCCESS);
} else {
printf("simpleCUBLAS test failed.\n");
exit(EXIT_FAILURE);
}
}
some more advanced features
With the above foundation, we can write some code that can run on the GPU.
Before we wrap up, let's look at a couple of slightly more advanced features.
__device__keywords
Earlier we learned about __global__the keywords of the kernel function. Kernel functions can be called by either the CPU or the GPU.
If we want to write functions that can only be run on the GPU, we can use the __device__.
Functions or variables that use __device__definitions can only be used in device code, not in host-side code. In CUDA programs, the __host__and __device__keywords are usually used to specify where functions or variables are executed on the host side and on the device side. The defined __device__functions or variables can be called by other functions in the device code, or can be processed by functions on the device after the host uses CUDA API to transfer data from the host memory to the device memory.
Inlining of GPU functions
Like CPU functions, functions on the GPU can also be inlined, using __forceinline__the keyword.
Concurrent "?:" ternary operator
In the C language, the "?:" ternary operator can only make one judgment.
Now in the world of GPU, the concurrency capability has become stronger, and multiple judgments can be made.
Let's look at an example:
__device__ __forceinline__ int qcompare(unsigned &val1, unsigned &val2) {
return (val1 > val2) ? 1 : (val1 == val2) ? 0 : -1;
}
PTX assembly
When we learned SIMD instructions in the last article, we basically had to assemble them inline. So is there compilation in CUDA?
The answer is yes, since performance optimization is to be done, then all potential must be tapped.
However, in order to avoid being too related to the architecture, NVidia provides us with an intermediate instruction format PTX (Parallel Thread Execution).
PTX assembly is an intermediate assembly language for CUDA, which is a machine-independent instruction set architecture (ISA) for describing parallel thread execution on GPUs. The PTX assembly can be compiled into the actual machine code for execution of a specific GPU family. Cross-GPU compatibility and performance optimization can be achieved using PTX assembly.
Let's look at a piece of inline assembly:
static __device__ __forceinline__ unsigned int __qsflo(unsigned int word) {
unsigned int ret;
asm volatile("bfind.u32 %0, %1;" : "=r"(ret) : "r"(word));
return ret;
}
The bfind.u32 instruction used in it is used to find the rightmost non-zero bit (that is, the least significant bit) in an unsigned integer and return its bit position. This instruction takes an unsigned integer as an operand input and outputs the bit position of the least significant bit into the destination operand.
"=r" (ret) indicates the output register, and the returned result is stored in ret.
"r" (word) indicates the input register, and the parameter word is used as input.
GPU-specific algorithms
The last point to emphasize is that in many cases, parallelizing the code is not simply transferring from the CPU to the GPU, but it is likely to change the algorithm.
For example, quicksort is a (nlog(n)) algorithm, while bitonic sort is ( nlog 2 ( n ) ) (nlog^2(n))( no g _ _2 (n))algorithm. However, bitonic sort is more suitable for GPU acceleration. So it would be better if we changed the quicksort on the CPU to the bitonic sort algorithm.
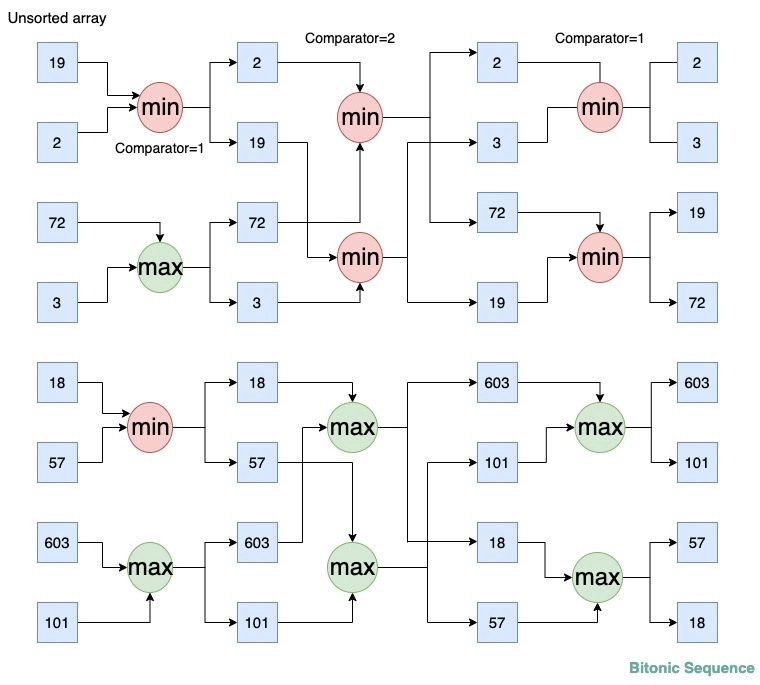
summary
When the Intel CPU was still 8+4 cores and 20 threads, the GTX 1060 graphics card had 1280 CUDA cores, the 3060 had 3584 CUDA cores, the 3090 had 10496 CUDA cores, and the 4090 had 16384 CUDA cores. For example, 1024 threads can be started on each CUDA core.
Therefore, if there are a large number of concurrent tasks, you should not hesitate to write them as kernel functions and run them on the GPU.
GPU programming is not that complicated, and it can be written quickly like a CPU program. But it's not that simple, suitable for GPU may need to use special algorithm instead.
The large model based on a large number of simple Transformers is just suitable for high-concurrency calculations.