foreword
References:
Gao Sheng's blog
"CUDA C programming authoritative guide"
and CUDA official document
CUDA programming: basics and practice Fan Zheyong
All the codes of the article are available on my GitHub, and will be updated slowly in the future
Articles and explanatory videos are simultaneously updated to the public "AI Knowledge Story", station B: go out to eat three bowls of rice
1: atomic function
The function of atomic operation is called atomic function for short.
In CUDA, the atomic operation of a thread can complete a set of "read-modify-write" operations on a certain data (in global memory or shared memory) without being affected by any operations of other threads.
The set of operations can also be said to be inseparable.
2: Atomic functions and reduction calculations
For the reduction calculation, refer to the introduction in the previous chapter (Chapter 9).
For the reduction calculation in the previous chapters, the kernel function did not do all the calculations, that is, it did not execute all the calculations on the GPU, but just changed a longer array d_x into a shorter array d_y, each of which The element is the sum of several elements in the former. After calling the kernel function, the shorter array is copied to the host, where the rest of the summation is done .
There are two ways to get the final result in the GPU,
one is to use another kernel function to further reduce the shorter array to get the final result (a value);
the second is to use the atomic function at the end of the previous kernel function Reduction, get the final result directly.
This article discusses the second method
//第9章归约核 函数的最后几行
//if 语句块的作用是将每一个线程块中归约的结果从共享内存 s_y[0] 复制到全
//局内 存d_y[bid]。为了将不同线程块的部分和s_y[0]累加起来,存放到一个全局
//内存地址
if (tid == 0)
{
d_y[bid] = s_y[0];
}
//使用原子函数
if (tid == 0)
{
//第一个参数是待累加变量的地址address,第二个 参数是累加的值val
//该函数的作用是将地址address中的旧值old读出,计算old + val, 然后将计算的值存入地址address。
//这些操作在一次原子事务(atomic transaction)中完成,不会被别的线程中的原子操作所干扰。
atomicAdd(&d_y[0], s_y[0]);
}
The atomic function performs a **"read-modify-write" atomic operation** on the data pointed to by its first parameter. The first parameter can point to global memory or to shared memory. For all participating threads, the "read-modify-write" atomic operation is performed one by one thread in turn, but there is no clear order. Also, atomic functions have no synchronization capabilities.
prototype of an atomic function
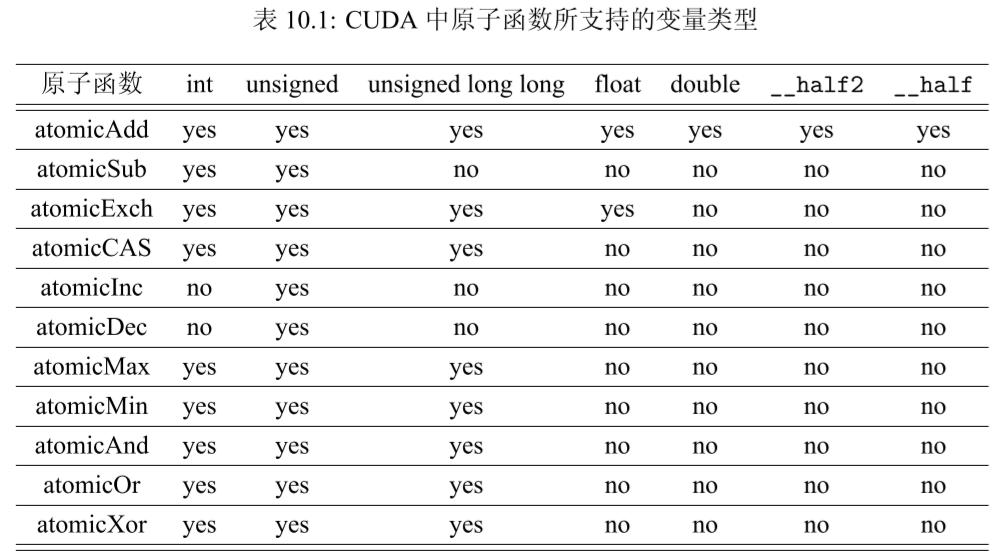
1. 加法:T atomicAdd(T *address, T val); 功能:new = old + val。
2. 减法:T atomicSub(T *address, T val); 功能:new = old - val。
3. 交换:T atomicExch(T *address, T val); 功能:new = val。
4. 最小值:T atomicMin(T *address, T val); 功能:new = (old < val) ? old : val。
5. 最大值:T atomicMax(T *address, T val);
功能:new = (old > val) ? old : val。
6. 自增:T atomicInc(T *address, T val); 功能:new = (old >= val) ? 0 : (old + 1)。
7. 自减:T atomicDec(T *address, T val); 功能:new = ((old == 0) || (old > val)) ? val : (old - 1)。
8. 比较-交换(Compare And Swap):T atomicCAS(T *address, T compare, T val); 功能:new = (old == compare) ? val : old。
9. 按位与:T atomicAnd(T *address, T val); 功能:new = old & val。
10. 按位或:T atomicOr(T *address, T val); 功能:new = old | val。
11. 按位异或:T atomicXor(T *address, T val);
功能:new = old ^ val。
Atomic functions – reduction calculations
#include<stdint.h>
#include<cuda.h>
#include "cuda_runtime.h"
#include "device_launch_parameters.h"
#include <stdio.h>
#include <math.h>
#include <stdio.h>
#define CHECK(call) \
do \
{
\
const cudaError_t error_code = call; \
if (error_code != cudaSuccess) \
{
\
printf("CUDA Error:\n"); \
printf(" File: %s\n", __FILE__); \
printf(" Line: %d\n", __LINE__); \
printf(" Error code: %d\n", error_code); \
printf(" Error text: %s\n", \
cudaGetErrorString(error_code)); \
exit(1); \
} \
} while (0)
#ifdef USE_DP
typedef double real;
#else
typedef float real;
#endif
const int NUM_REPEATS = 100;
const int N = 100000000;
const int M = sizeof(real) * N;
const int BLOCK_SIZE = 128;
void timing(const real* d_x);
int main(void)
{
real* h_x = (real*)malloc(M);
for (int n = 0; n < N; ++n)
{
h_x[n] = 1.23;
}
real* d_x;
CHECK(cudaMalloc(&d_x, M));
CHECK(cudaMemcpy(d_x, h_x, M, cudaMemcpyHostToDevice));
printf("\nusing atomicAdd:\n");
timing(d_x);
free(h_x);
CHECK(cudaFree(d_x));
return 0;
}
void __global__ reduce(const real* d_x, real* d_y, const int N)
{
const int tid = threadIdx.x;
const int bid = blockIdx.x;
const int n = bid * blockDim.x + tid;
extern __shared__ real s_y[];
s_y[tid] = (n < N) ? d_x[n] : 0.0;
__syncthreads();
for (int offset = blockDim.x >> 1; offset > 0; offset >>= 1)
{
if (tid < offset)
{
s_y[tid] += s_y[tid + offset];
}
__syncthreads();
}
if (tid == 0)
{
atomicAdd(d_y, s_y[0]);
}
}
real reduce(const real* d_x)
{
const int grid_size = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
const int smem = sizeof(real) * BLOCK_SIZE;
real h_y[1] = {
0 };
real* d_y;
CHECK(cudaMalloc(&d_y, sizeof(real)));
CHECK(cudaMemcpy(d_y, h_y, sizeof(real), cudaMemcpyHostToDevice));
reduce << <grid_size, BLOCK_SIZE, smem >> > (d_x, d_y, N);
CHECK(cudaMemcpy(h_y, d_y, sizeof(real), cudaMemcpyDeviceToHost));
CHECK(cudaFree(d_y));
return h_y[0];
}
void timing(const real* d_x)
{
real sum = 0;
for (int repeat = 0; repeat < NUM_REPEATS; ++repeat)
{
cudaEvent_t start, stop;
CHECK(cudaEventCreate(&start));
CHECK(cudaEventCreate(&stop));
CHECK(cudaEventRecord(start));
cudaEventQuery(start);
sum = reduce(d_x);
CHECK(cudaEventRecord(stop));
CHECK(cudaEventSynchronize(stop));
float elapsed_time;
CHECK(cudaEventElapsedTime(&elapsed_time, start, stop));
printf("Time = %g ms.\n", elapsed_time);
CHECK(cudaEventDestroy(start));
CHECK(cudaEventDestroy(stop));
}
printf("sum = %f.\n", sum);
}
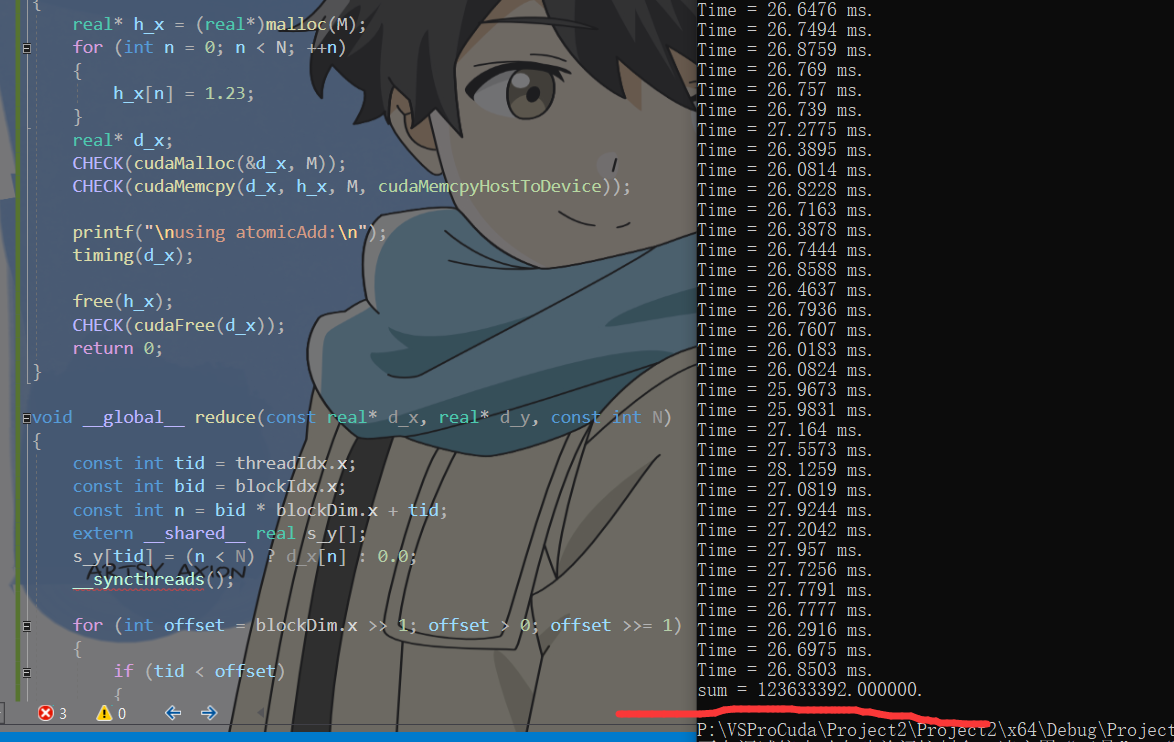
Compared with the ninth article using shared memory 29ms, there is a slight performance improvement