Article Directory
Mapping Tool MetaObject
The so-called mapping means that the columns in the result set are filled to the JAVA Bean properties. This requires the use of reflection, and the attributes of Bean are various, including ordinary attributes, objects, collections, and Maps. In order to operate Bean properties more conveniently, MyBatis provides the MetaObject tool class, which is used to map fields in tables in the database to properties of Java objects.It provides some methods to get, set, and judge the properties of Java objects。
basic skills
Its specific functions are as follows:
-
Search attribute: do not ignore capitalization, support camel case, support sub-attributes such as: "blog.comment.user_name"
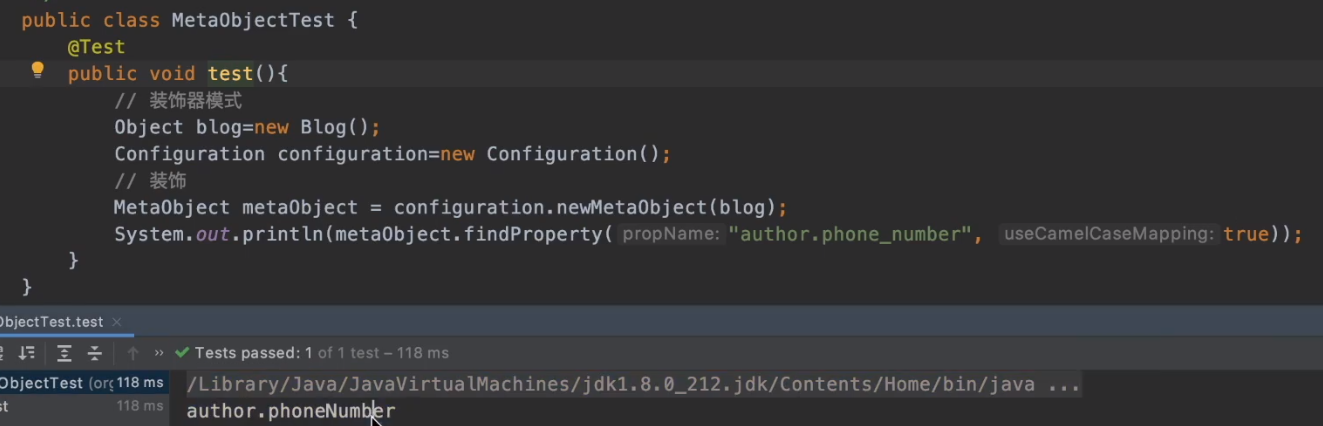
-
get attribute
- Based on
.getting the sub-property "user.name" - Get list value "users[1].id" based on index
- Get the map value "user[name]" based on the key
- Based on
-
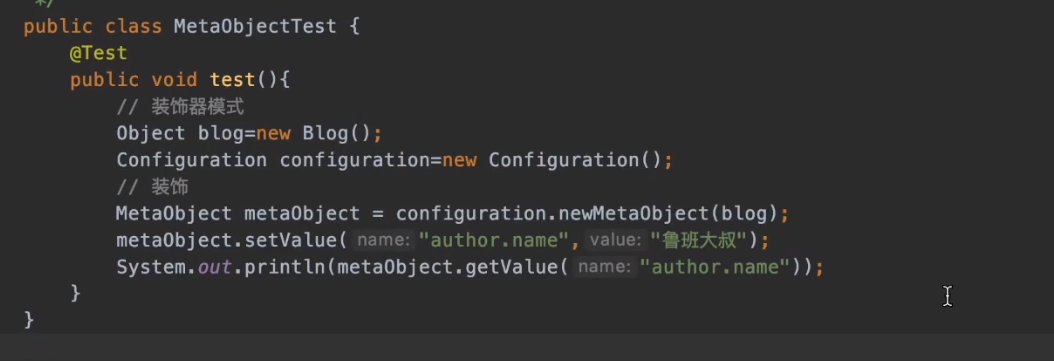
Set properties:
- Settable sub-property value
- Support automatic creation of sub-properties (must have a null parameter constructor, and cannot be a collection)
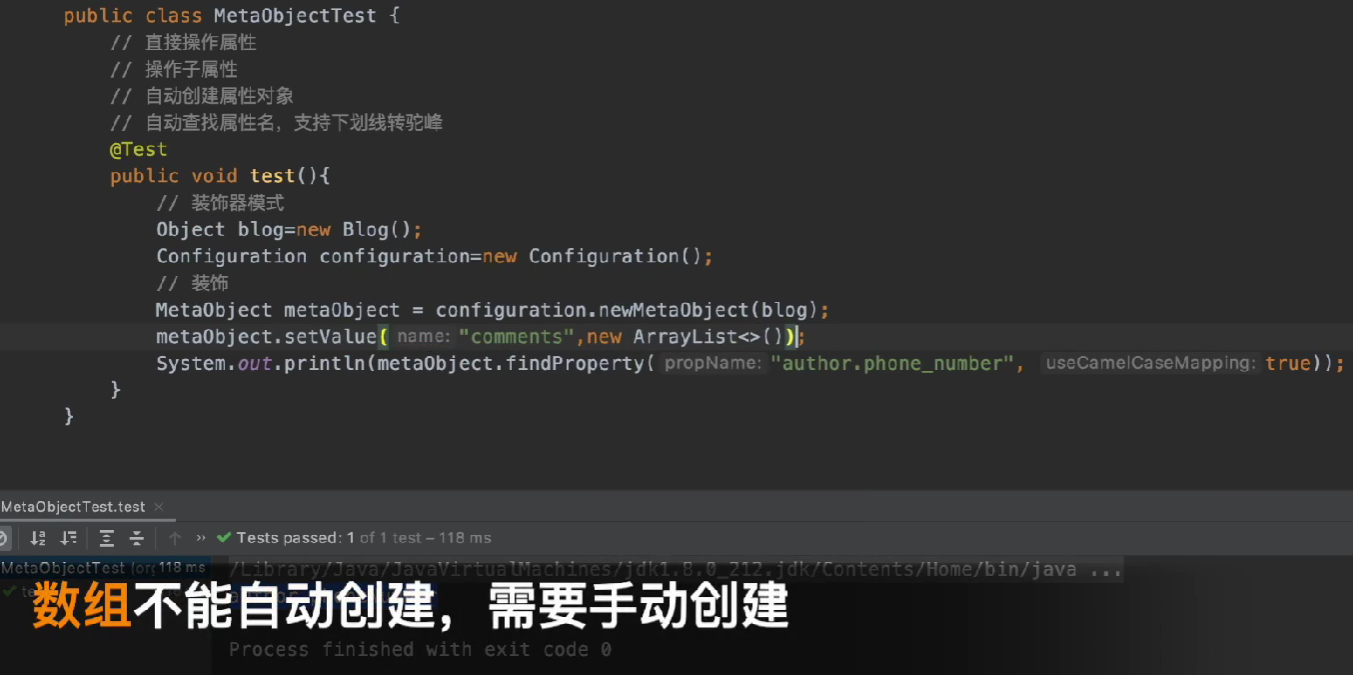
The main methods are:
- getGetter(String name): getter method to get the property
- getSetter(String name): Get the setter method of the property
- getGetterType(String name): Get the type of attribute
- hasGetter(String name): Determine whether there is a getter method
- hasSetter(String name): Determine whether there is a setter method
- getValue(String name): Get the value of the attribute
- setValue(String name, Object value): Set the value of the property
- findProperty(String name, boolean useCamelCaseMapping): When looking for properties, you can specify whether to use camel case naming (the return type is String)
public class User {
private int id;
private String name;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
}
MetaObject metaObject = MetaObject.forObject(user);
// 获取 getter 方法
Method idGetter = metaObject.getGetter("id");
// 获取 setter 方法
Method nameSetter = metaObject.getSetter("name");
// 获取 name 属性的值
String name = (String) metaObject.getValue("name");
// 设置 id 属性的值
metaObject.setValue("id", 1);
underlying structure
In order to achieve the above functions, MetaObject has successively relied on BeanWrapper, MetaClass, and Reflector. These four objects are related as follows:
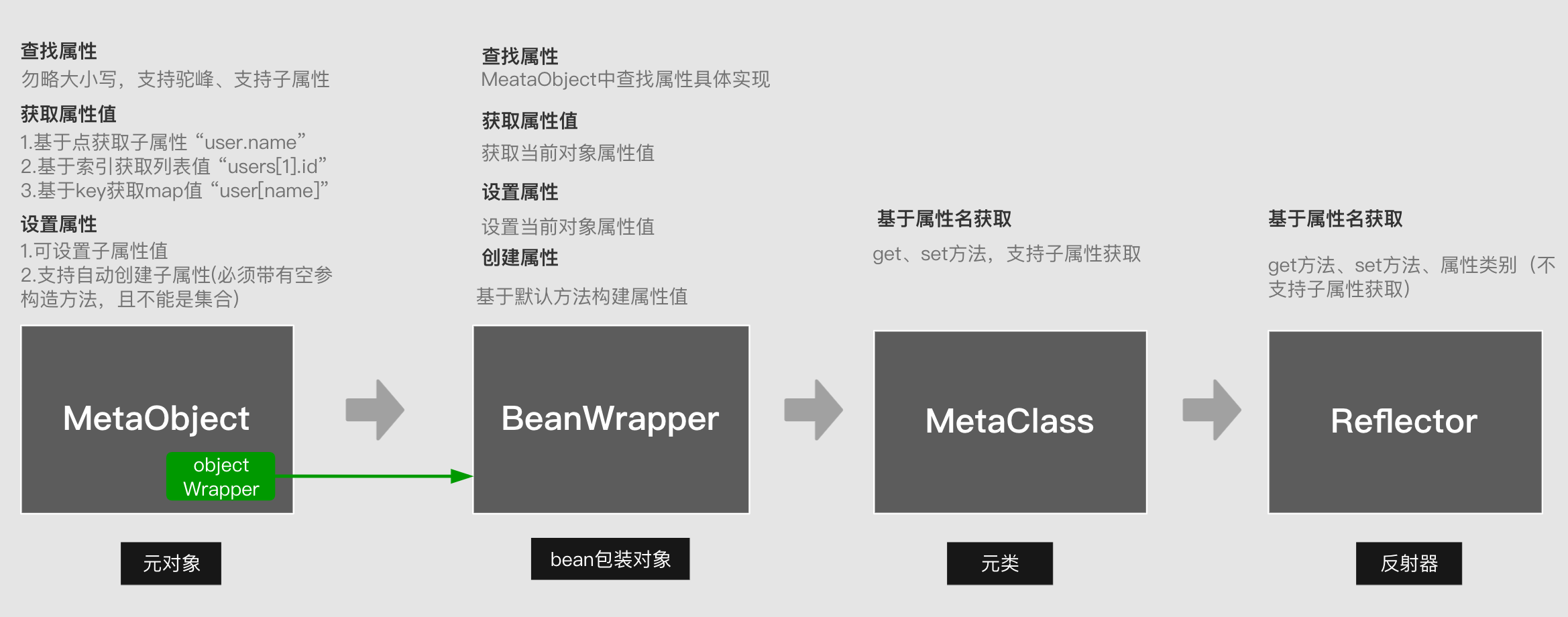
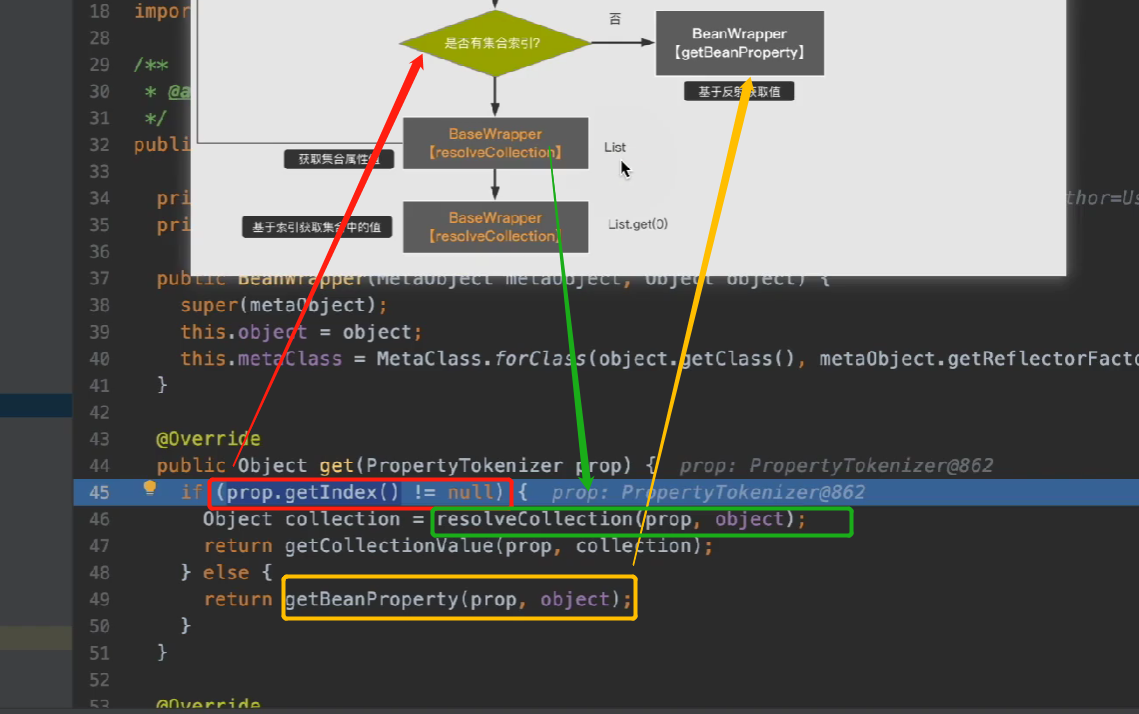
- BeanWrapper: The function is similar to MeataObject, the difference isBeanWrapper can only operate on a single current object property, cannot manipulate sub-properties.
- So when Metaobject looks for the attribute of an attribute, it will search the attribute progressively, and then look for the attribute of the attribute. This process is searched through BeanWrapper, and Metaobject is used to parse the expression
- The bottom layer of BeanWrapper must be based on reflection, here we use MetaClass
- MetaClass: The reflection function of the class is supported, and the attributes of the entire class can be obtained, including the attributes of the attributes. The underlying layer is based on Reflector.
- Reflector: The reflection function of the class is supported, and only supports the attributes of the current class.
The process of obtaining attribute values
The object structure is as follows:
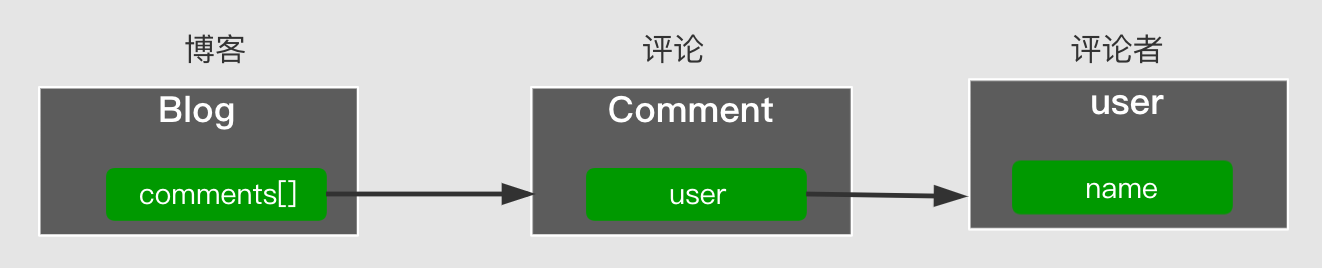
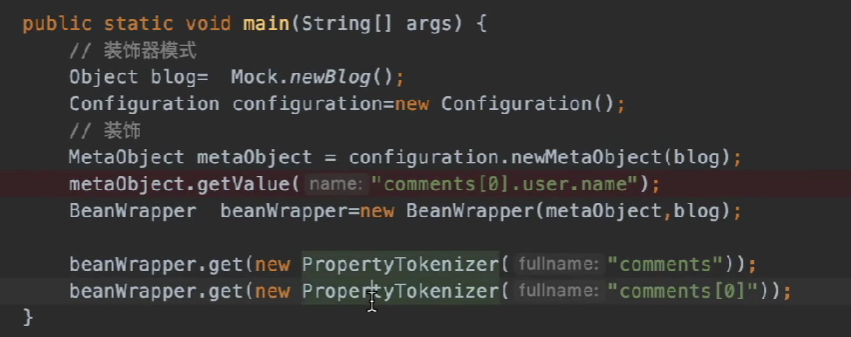
Get the name of the first commenter of the blog, the get expression is:
"comments[0].user.name"
The MetaObjbt analysis and acquisition process is as follows:
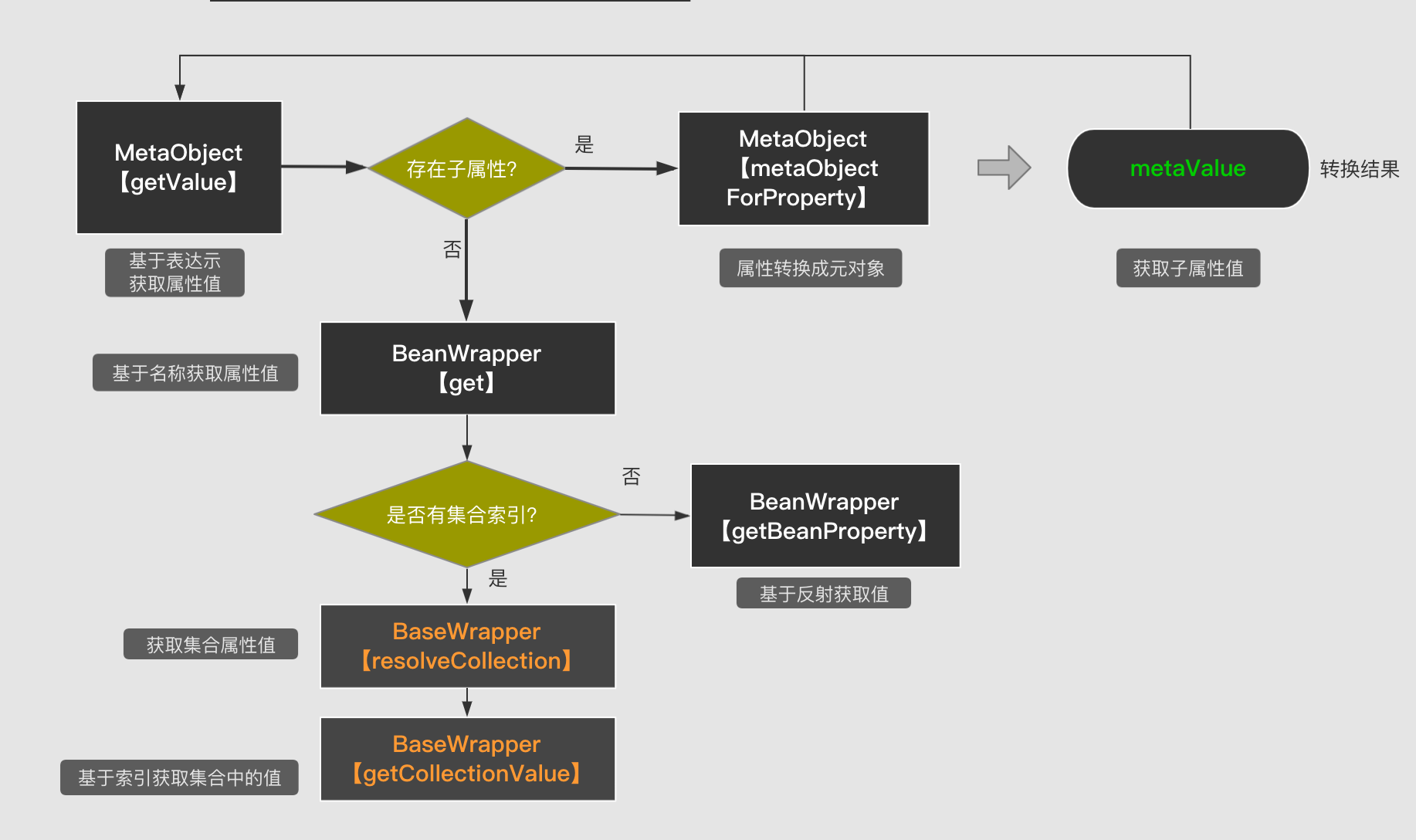
We can see from this process that MetaObject will use recursion to parse the expression layer by layer, and will not hand over the real acquisition work to BeanWrapper until there is no sub-attribute, and the bottom layer of BeanWrapper will get the attribute value based on reflection.
If the collection index is involved, first obtain the collection, and then obtain the value in the collection based on the index. This part of the work is handed over to BaseWrapper.
Method description in the process:
-
MetaObject.getValue(): To get the value of the attribute, first parse it into a PropertyTokenizer based on the attribute name "comments[0].user.name", and judge whether it is a sub-attribute value based on the "." in the attribute. If so, call getValue() recursively to obtain the sub-attribute object. Then recursively call getValue() to get the properties under the sub-properties. until the last name attribute.
-
MetaObject.setValue(): The process is similar to getValue(), the difference is that if the sub-property does not exist, it will try to create the sub-property.
Let's combine the source code:
We can see that the parsing of expressions in MetaObject actually relies on a property tokenizer called PropertyTokenizer.
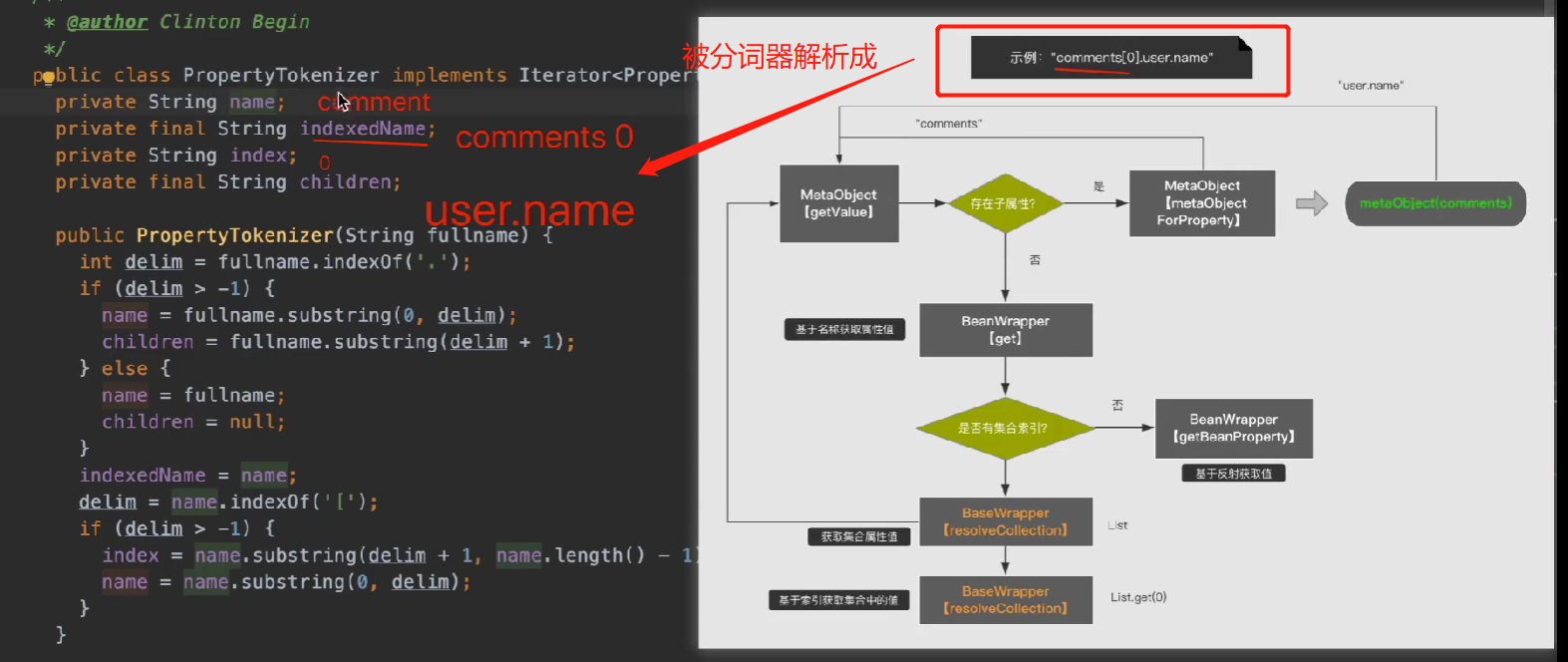
Then this tokenizer has a next method, which generates a tokenizer according to children, so as to achieve the effect of layer-by-layer parsing.

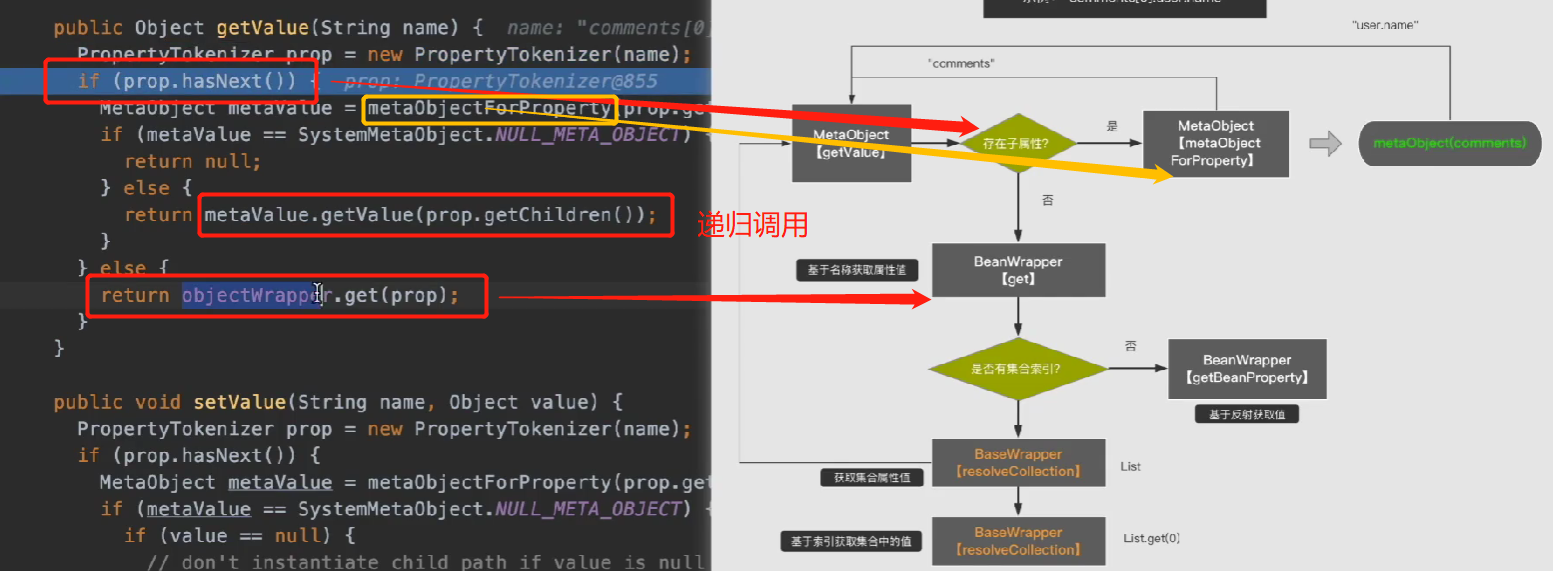
The collection uses the get method of BeanWrapper here:
ResultMap result set mapping
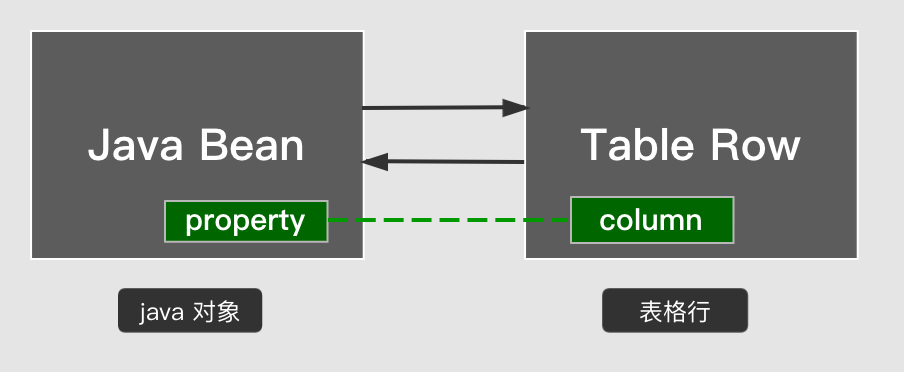
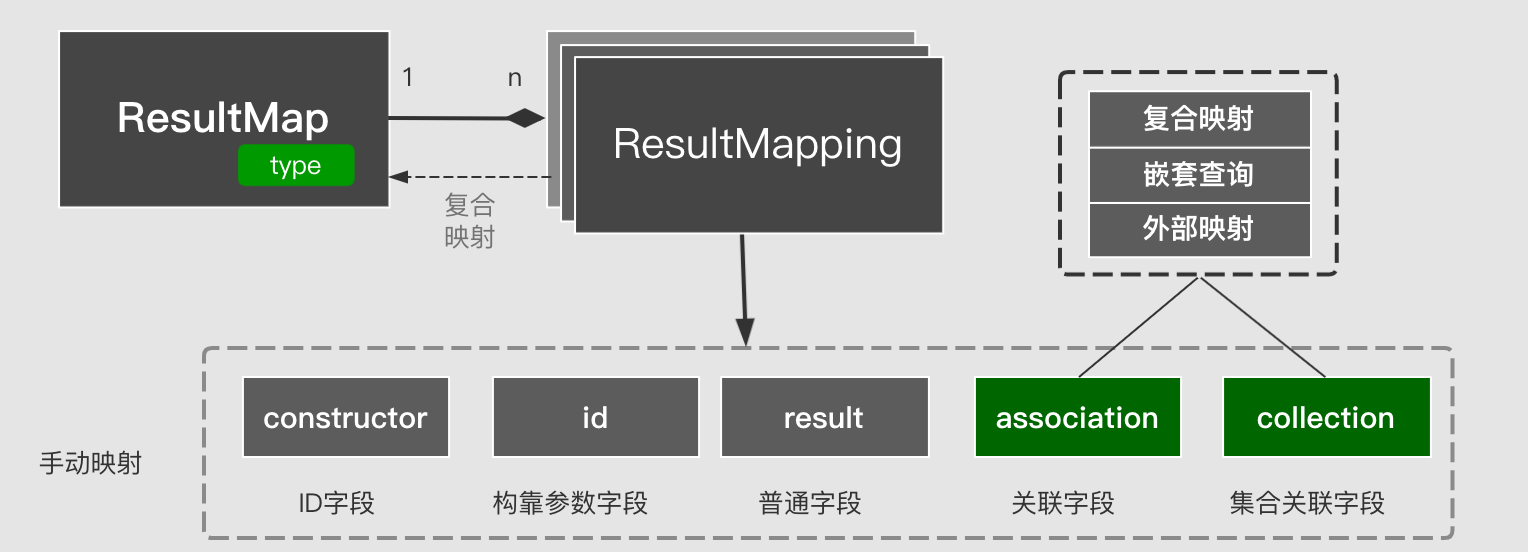
Mapping refers to the correspondence between the returned ResultSet columns and Java Bean properties. The mapping description is carried out through ResultMapping, and it is packaged into a whole with ResultMap.
manual mapping
mapping settings


A ResultMap contains multiple ResultMappings to represent a specific JAVA attribute-to-column mapping, and its main values are as follows:

ResultMapping has various manifestations as follows:
- constructor: construction parameter field
- id: ID field
- result: common structure set field
- association: 1 to 1 association field (when associating an object)
- Collection: 1-to-many collection association field
Let's talk about the constructor here:
The constructor element in resultMap is used to call the constructor of the class during the result set mapping process.
When MyBatis builds the result object, it will instantiate the target class through the default constructor by default, and then assign it a value through the setter method.
However, sometimes our class does not have a default constructor, or we need to set some default values through the constructor. At this time, the constructor element is very useful.
We can configure the constructor in resultMap to specify the construction method of the target class, and MyBatis will call this construction method when constructing the result object.
The constructor configuration syntax is as follows:<constructor> <idArgumnet index="0" javaType="int"/> <arg index="1" javaType="String"/> </constructor>
- idArgumnet: Specifies the parameter used for id in the constructor.
- arg: specifies the normal parameters in the constructor.
- index: Specifies the position of the parameter in the constructor parameter list.
- javaType: The java type of the specified parameter.
Then when MyBatis constructs the result object, it will find a matching construction method, call the construction method and instantiate the object through the id parameter specified by idArgumnet and each parameter specified by arg.
For example, we have a user class User:
public class User { private int id; private String name; public User(int id, String name) { this.id = id; this.name = name; } }Our resultMap can be configured as:
<resultMap id="userMap" type="User"> <constructor> <idArg index="0" javaType="int"/> <arg index="1" javaType="String"/> </constructor> </resultMap>Then when MyBatis processes the result set and maps it to a User object, it will find the User(int, String) construction method and call it
User(1, "Tom")to instantiate the User object.
And if the constructor is not configured, MyBatis will call the no-argument constructionUser()to instantiate by default, and then assign values to the id and name through the setter method. The code is as follows:User user = new User(); user.setId(1); user.setName("Tom");It can be seen that using constructor has certain performance advantages, and can avoid the situation of no-argument construction method.
Therefore, the constructor element provides a richer choice for the result object construction process of resultMap. We can choose to use the default construction + setter method or construction method to instantiate the result object according to our needs. This once again reflects the power of MyBatis flexibility.
automatic mapping
Automatic mapping can be used when the current column name and attribute name are the same
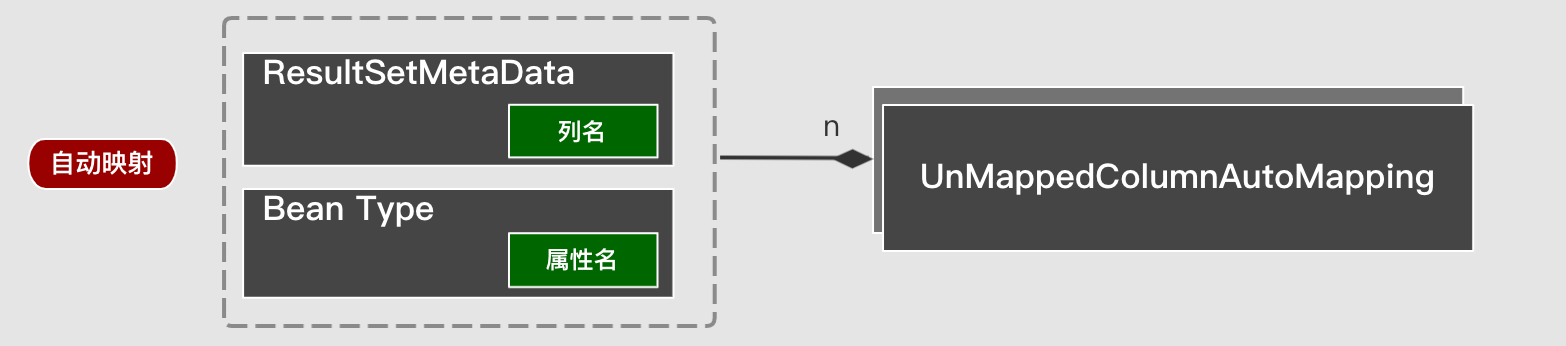
Automatic mapping conditions
- Column names and attribute names exist at the same time ( do not omit capitalization, camel case-underscore )
- The current column has no mapping set manually
- Property class exists TypeHandler
- Enable autoMapping (enabled by default)
Automatic mapping can only be established in the three cases on the left, once complex mapping is involved:

nested subqueries
Let's first talk about the origin of nested subqueries:
the association element handles the "has a" type of relationship. For example, in our example, a blog has a user. Association result mappings work in much the same way as other types of mappings. You need to specify the target property name and the javaType of the property (MyBatis can infer it by itself in many cases). You can also set the JDBC type if necessary, and you can also set the type handler if you want to override the process of getting the result value.
The difference with associations is that you need to tell MyBatis how to load the associations. MyBatis has two different ways to load associations (of course Collection can also be used):
嵌套 Select 查询: Load the desired complex type by executing another SQL mapping statement.
It's that simple. We have two select queries: one to load the blog (Blog) and another to load the author (Author), and the blog's result map describes that its author property should be loaded using the selectAuthor statement.
All other properties will be loaded automatically as long as their column names match the property names.
This approach, while simple, does not perform well on large datasets or large tables. This problem is known as the "N+1 query problem". In a nutshell, the N+1 query problem looks like this:
- You execute a single SQL statement to get a list of results (that is, "+1").
- For each record returned by the list, you execute a select query to load the details (that is, "N") for each record.
This problem can cause hundreds or thousands of SQL statements to be executed. Sometimes, we don't want such consequences.
The good news is that MyBatis can lazy load such queries, so it can spread the overhead of running a large number of statements at the same time. However, if you immediately iterate over the list to fetch nested data after loading the list of records, all lazy loading queries will be triggered and performance can become very poor.
嵌套结果映射: Use nested result maps to handle repeated subsets of join results.
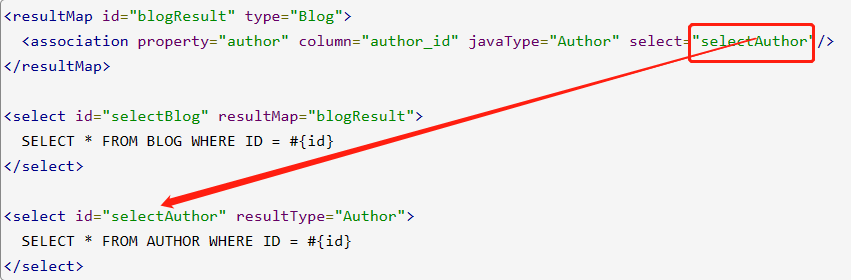
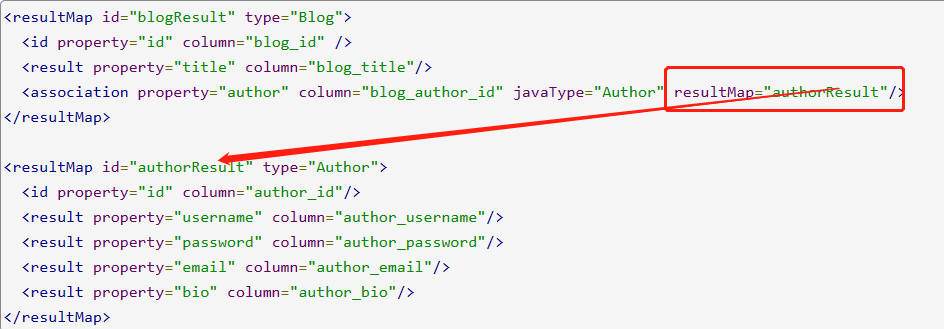
But in many cases, the object structure is displayed at the tree level. That is, objects contain objects. Sub-object properties can be obtained via a subquery.
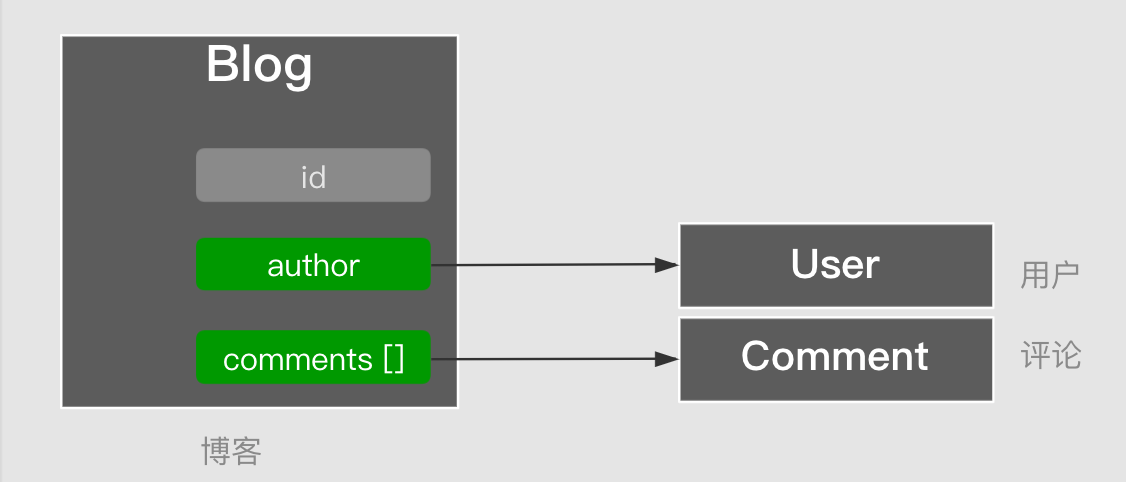
When parsing the attributes in the Blog in sequence, it will parse and populate the common attributes first, and when parsing to a compound object, it will trigger a pair of subqueries.
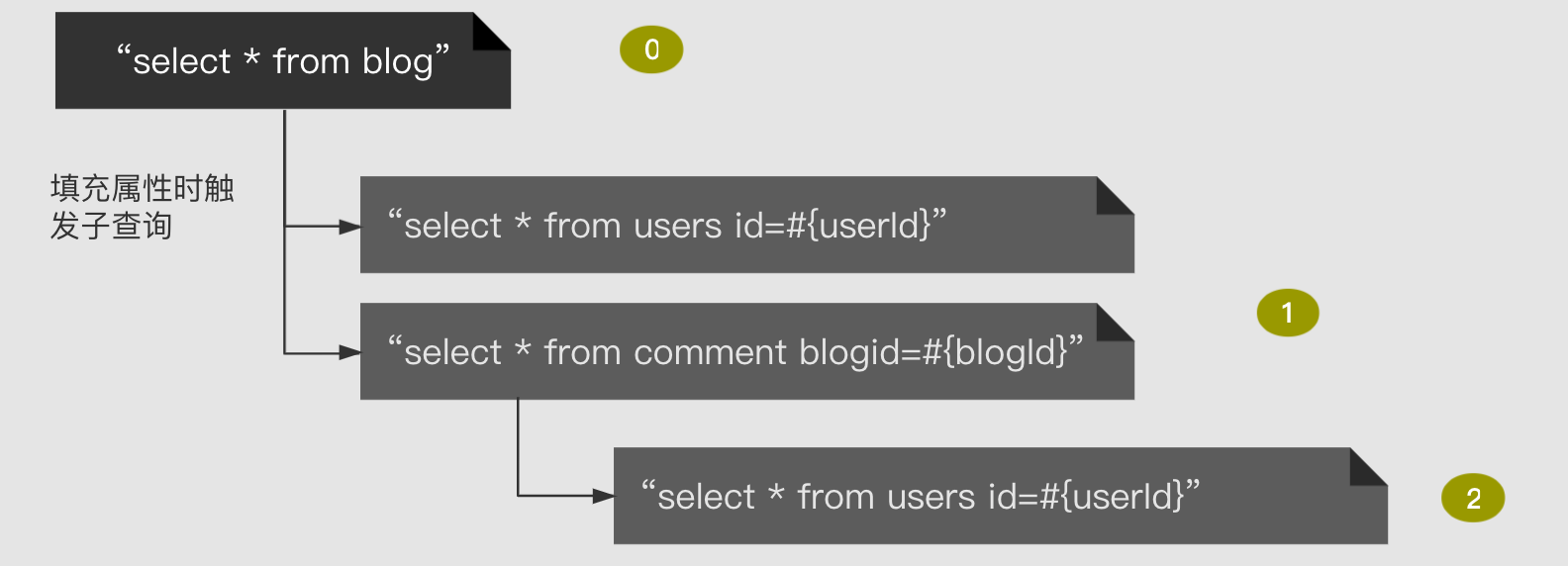
circular dependency
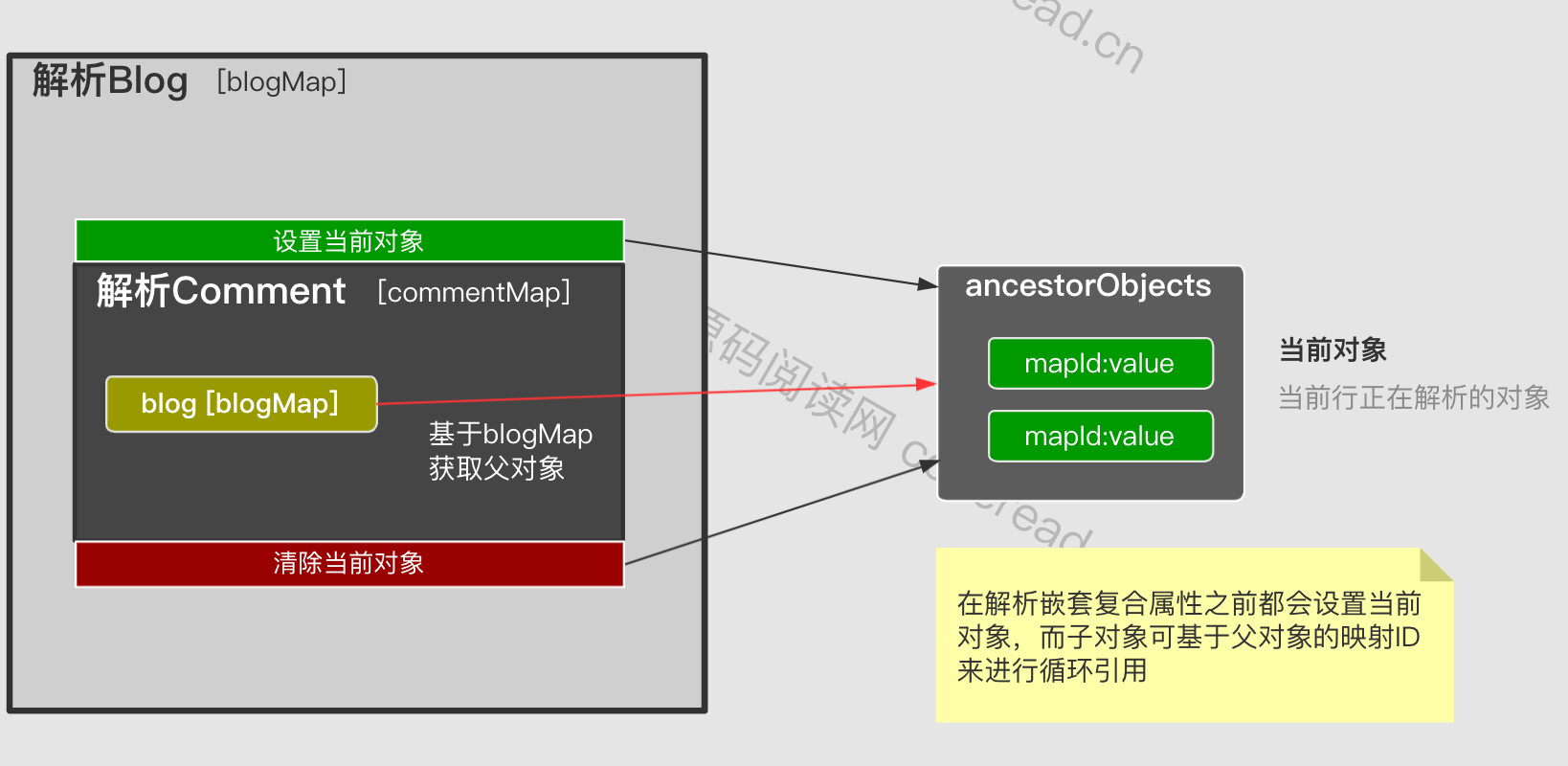
Two objects refer to each other, that is, a circular reference, as shown in the following figure:
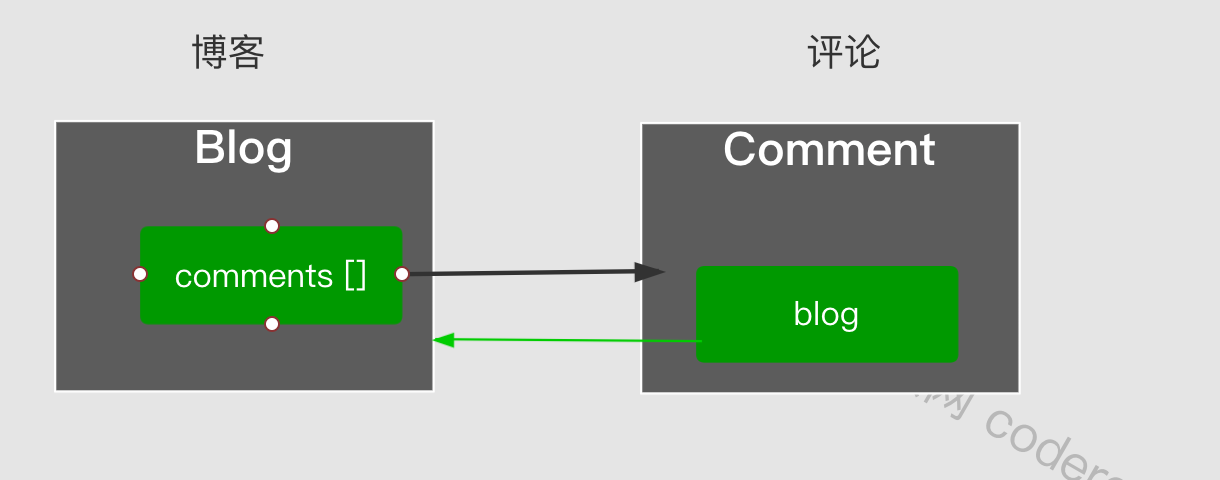
The corresponding ResultMap is as follows:
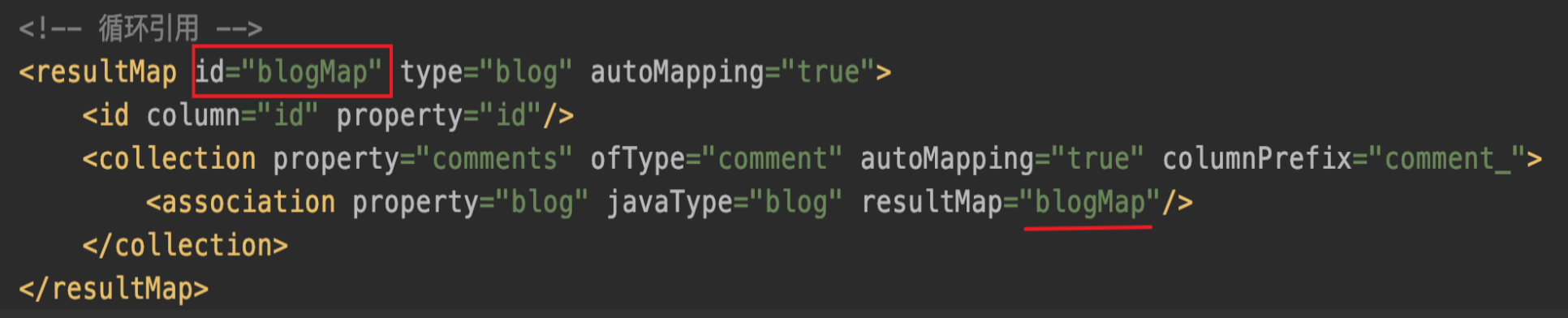
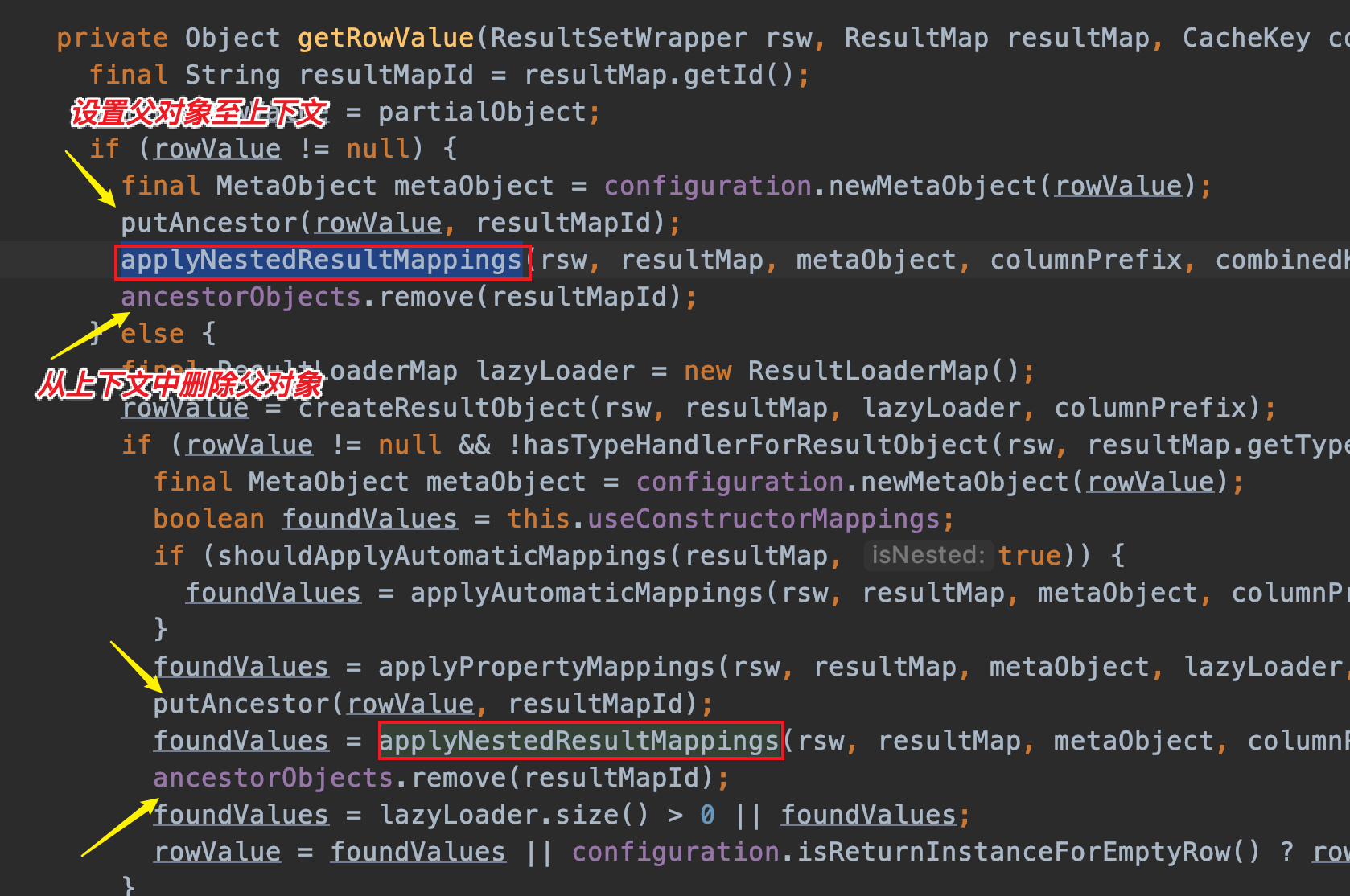
Will this situation lead to an infinite loop of parsing? The answer is no.DefaultResultSetHandler will populate the current parsing object (using resultMapId as Key) in the context before parsing the composite map. If the sub-property mapping references the parent mapping ID, it can be directly obtained without parsing the parent object. The specific process is as follows:
Specific code:
lazy loading
Lazy loading is to improve the concurrency of a large number of nested subqueries when parsing object properties.After setting lazy loading, it will only be loaded when the specified attribute is used, thus dispersing SQL requests。
<resultMap id="blogMap" type="blog" autoMapping="true">
<id column="id" property="id"></id>
<association property="comments" column="id" select="selectCommentsByBlog" fetchType="lazy"/>
</resultMap>
Lazy loading can be set by specifying fetchType="lazy" in the nested subquery. It is not actually loaded until getComments is called. In addition, calls: "equals", "clone", "hashCode", "toString" will trigger all unexecuted lazy loading of the current object. By setting the global parameter aggressiveLazyLoading=true, you can also specify to call any method of the object to trigger all lazy loading.

set override & serialization
After calling the setXXX method to manually set the attribute, the lazy loading of the corresponding attribute will be removed, and the manually set value will not be overwritten.
After the object is serialized and deserialized, lazy loading is no longer supported by default. However, if the configurationFactory class is set in the global parameters, and Java native serialization is used, lazy loading can be performed normally. The principle is to serialize the parameters required for lazy loading and the configuration together, and after deserialization, obtain the configuration to build the execution environment through the configurationFactory.
configurationFactory is a class that contains a getConfiguration static method
public static class ConfigurationFactory {
public static Configuration getConfiguration() {
return configuration;
}
}
principle
MyBatis provides two tags, association and collection, to configure lazy loading. Their working principles are as follows:
- When the association or collection tag is configured with fetchType="lazy", MyBatis will return the proxy object of this attribute in the query result. This proxy object contains the data loading logic for the target property.
- When we call the getter method of the proxy object for the first time, the proxy object will execute the query and load the real data by itself, and replace itself with the real data object.
- Then calling the getter method will directly return the real data object.
In this way, lazy loading of attributes is realized, and only when the attribute is really needed will the query be executed to load data.
Let's look at an example:
User and account configuration:
<resultMap id="userAccountMap" type="User">
<association property="account" select="selectAccountByUserId" column="id" fetchType="lazy"/>
</resultMap>
<select id="selectUserById" resultMap="userAccountMap">
select * from user where id = #{id}
</select>
<select id="selectAccountByUserId" resultType="Account">
select * from account where user_id = #{id}
</select>
Test code:
User user = mapper.selectUserById(1);
// 第一次调用account属性的getter方法
Account accout = user.getAccount();
- When executed
selectUserById(1), the User object will be queried, and its account property will be filled as a proxy object. - When called for the first
user.getAccount()time, the proxy object willselectAccountByUserIdquery the real Account data and replace itself with the real Account object. - Calling it later
getAccount()will directly return the Account object.
So the question is, what is this proxy object? How does it know which select statement to execute ?
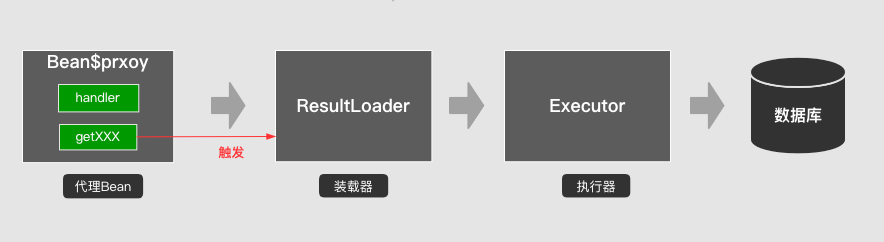
MyBatis uses JDK dynamic proxy and enhances InvocationHandler to achieve lazy loading. When fetchType=lazy, MyBatis will create the following proxy objects:
Proxy.newProxyInstance(
mapperInterface.getClassLoader(),
new Class[] {
mapperInterface },
new LazyLoaderHandler(sqlSession, selectStatement)
)
- LazyLoaderHandler implements the InvocationHandler interface, which knows the actual select statement to be executed.
- When the getter method is called, the invoke method of the InvocationHandler is actually called.
- The invoke method will first determine whether the attribute has been loaded. If not, it will execute the select statement to query the data through SqlSession, and set the result to the source object.
- Then calling the invoke method will directly return the loaded data.
So in summary, the principle of MyBatis lazy loading is:
- A proxy object containing lazy loading logic is generated through the JDK dynamic proxy.
- When the getter method is called for the first time, the select statement is executed through the proxy object to query data.
- Sets the query result to the source object, and returns the result.
- After calling the getter method, the result will be returned directly to achieve lazy loading.
JDK dynamic proxy is the basis of MyBatis lazy loading function. MyBatis realizes lazy loading proxy effect by enhancing InvocationHandler. This is the ingenious implementation of this feature of MyBatis.
Lazy loading allows us to delay the loading of associated attributes until we really need to use it, which greatly improves the efficiency of database interaction and reduces memory consumption. It is one of the important means for MyBatis to optimize database performance.
internal structure
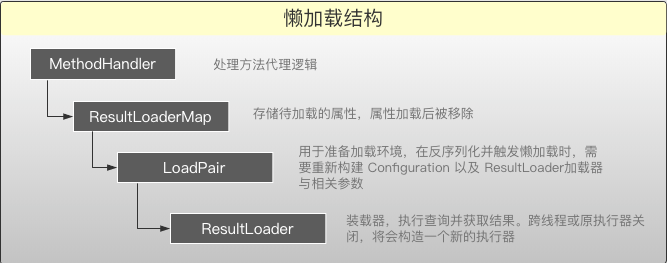
After the proxy, the Bean will contain a MethodHandler, which contains a Map inside to store the lazy loading to be executed, and it will be removed before the lazy loading is executed. LoadPair is used to prepare the execution environment for deserialized beans. ResultLoader is used to perform loading operations. If the original executor is closed before execution, a new one will be created.
If a specific attribute fails to load, it will not be loaded again.
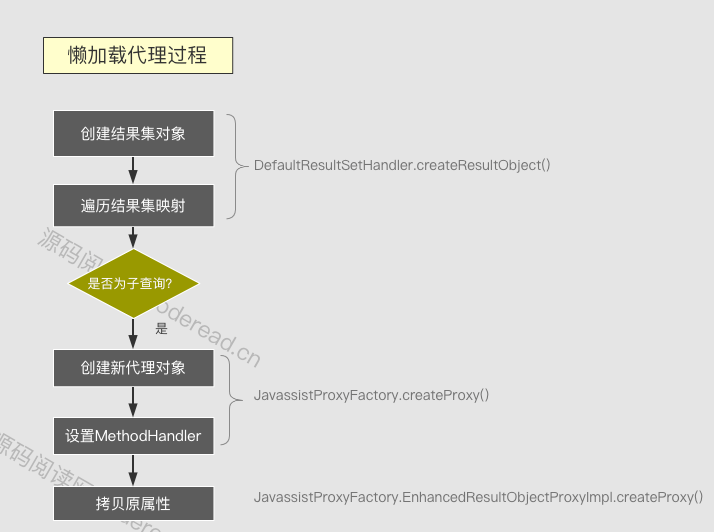
Bean proxy process
The proxy process occurs after the result set is parsed and created (DefaultResultSetHandler.createResultObject). If the corresponding property is set to lazy loading, a proxy object will be created through ProxyFactory, which inherits from the original object, and then all the values of the object are copied to the proxy object. And set the corresponding MethodHandler (the original object is discarded directly)
Union queries and nested maps
Mapping description
Mapping refers to the correspondence between the returned ResultSet columns and Java Bean properties. The mapping description is carried out through ResultMapping, and it is packaged into a whole with ResultMap. Mapping is divided into simple mapping and compound nested mapping.
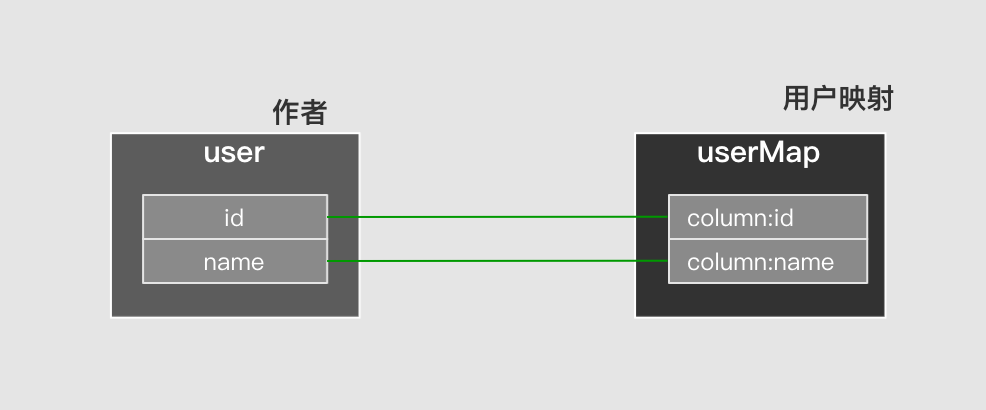
简单映射: That is, the returned result set column has a 1-to-1 relationship with the object attribute. In this case, ResultHandler will traverse the rows in the result set in turn, create an object for each row, and then fill in the mapped attribute of the object in the traversal result set column.
嵌套映射: But most of the time the object structure is a tree-level process. That is, objects contain objects. The corresponding mapping is also this kind of nested structure.
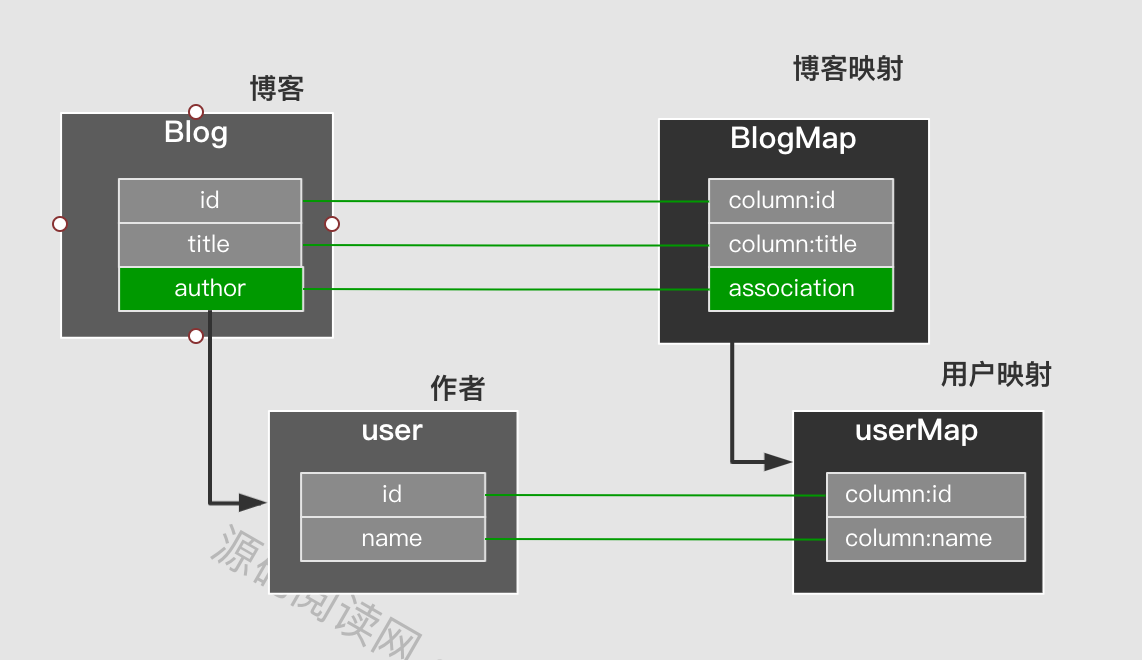
In the configuration mode, you can directly configure sub-mapping, and also introduce external mapping and automatic mapping. There are two types of nested structures:
- one-to-many
- many to many

The official website has very detailed documentation on how to use the mapping. I won't go into details here. Next, analyze the nested mapping result set filling process.
joint query
How to get the result after having the mapping? Ordinary single-table queries cannot obtain the results required by composite mappings, so joint queries must be used. Then split the data columns returned by the joint query into different object attributes. 1-to-1 and 1-to-many are split and created in the same way.
1 to 1 query mapping
select a.id,
a.title,
b.id as user_id,
b.name as user_name
from blog a
left join users b on a.author_id=b.id
where a.id = 1;
By combining the above statements with query statements, the results in the following table can be obtained. The first two fields in the result correspond to Blog, and the last two fields correspond to User. Then fill in the User as the author attribute to the Blog object.


In the above two examples, each line will generate two objects, a Blog parent object and a User child object.
1 to many query
select a.id,a.title,
c.id as comment_id,
c.body as comment_body
from blog a
left join comment c on a.id=c.blog_id
where a.id = 1;
The above statement can get three results, the first two fields correspond to Blog, and the latter two fields correspond to Comment. Unlike 1-to-1, the three lines point to the same Blog. Because its ID is the same.


In the above results, the same three lines of Blog will create a Blog, and at the same time create three different Comments to form a collection and fill it into the comments object.
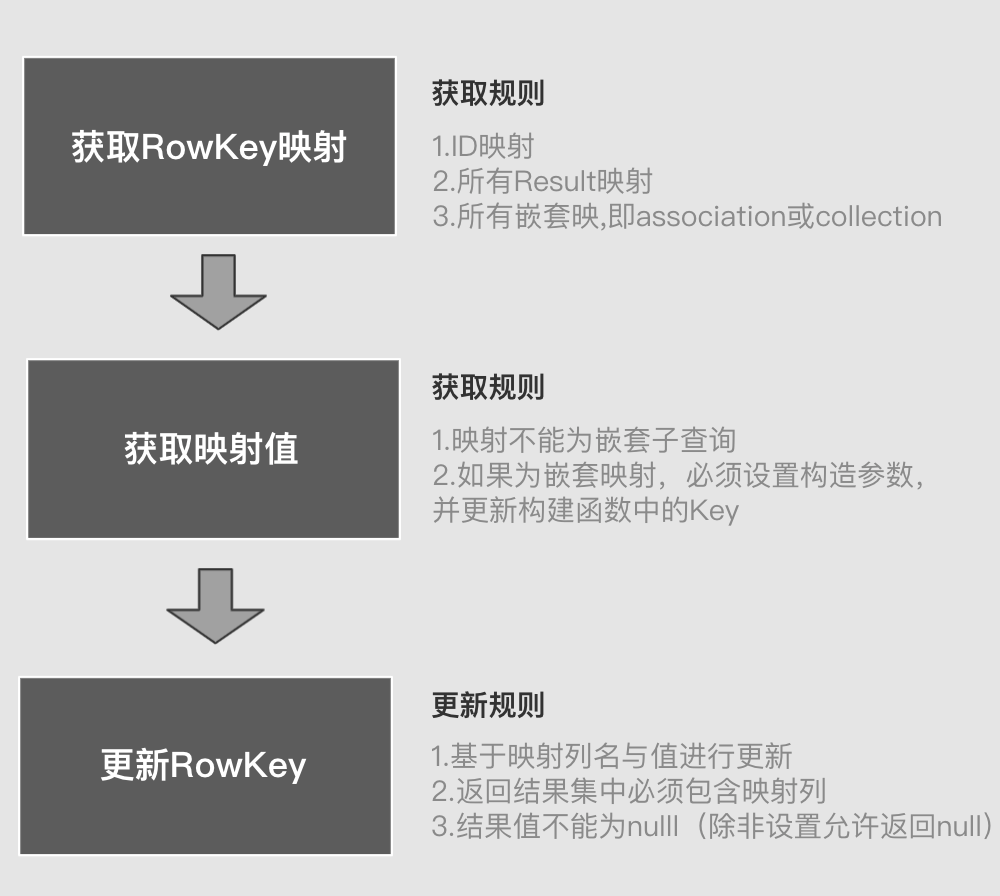
RowKey Creation Mechanism
In the 1-to-many query process, it is based on RowKey to determine whether the two rows of data are the same. RowKey is generally based on . But sometimes it is not specified that other mapping fields will be used to create the RowKey. The specific rules are as follows:
Result set parsing process
Here, the 1-to-many situation is directly used for analysis, because 1-to-1 is a simplified version of 1-to-many. The results of the query are as follows:

The entire analysis process is as follows:
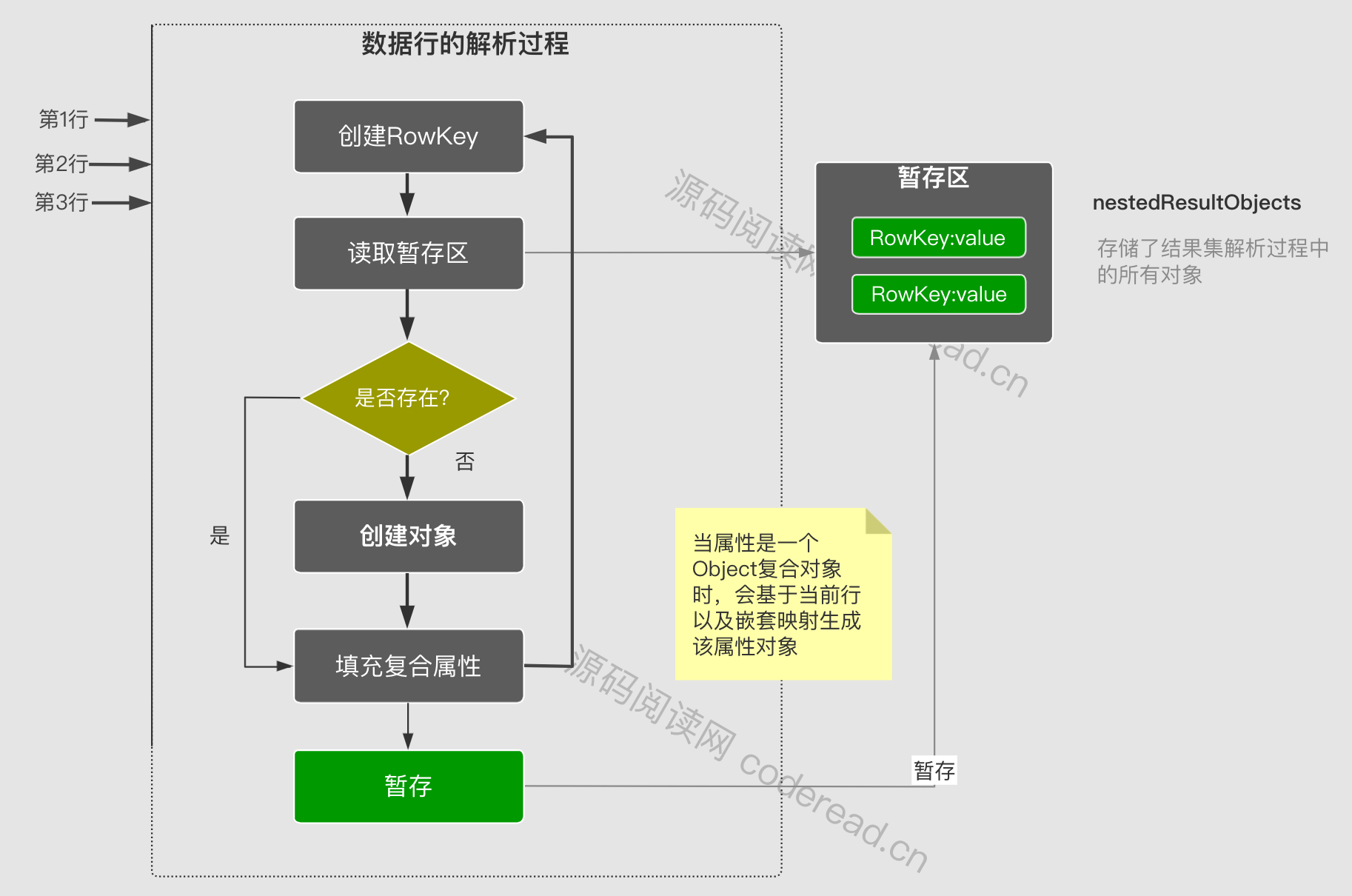
Flow Description:
The parsing of all mapping processes is done in DefaultResultSetHandler. The main method is as follows:
-
handleRowValuesForNestedResultMap(): The nested result set parsing entry, where all rows in the result set will be traversed. And create a RowKey object for each row. Then call getRowValue() to get the parsing result object. Finally saved to ResultHandler.
- Note: Before calling getRowValue, the parsed object will be obtained based on RowKey, and then sent to getRowValue as a partialObject parameter
-
getRowValue(): This method will eventually generate a parsed object based on the current row. Specific responsibilities include, 1. Create objects, 2. Populate common properties and 3. Populate nested properties. When parsing nested properties, getRowValue will be called recursively to get sub-objects. The last step 4. Temporarily store the current parsing object based on the RowKey.
- If the partialObject parameter is not empty, only step 3 will be executed. Because 1 and 2 have already been executed.
-
applyNestedResultMappings(): Parses and populates the nested result set mapping, traverses all nested mappings, and then obtains its nested ResultMap. Then create a RowKey to get the value of the temporary storage area. Then call getRowValue to get the property object. Finally filled to the parent object.
- If the attribute object can be obtained through RowKey, it will still call getRowsValue, because there may still be unresolved attributes under it.