Benford's law:
Also known as Benford's law, it shows that in a bunch of data derived from real life, the probability of occurrence of numbers with 1 as the first digit is about 30% of the total number, which is close to three times the expected value of 1/9 intuitively. In general terms, the larger the number, the lower the probability of the first few digits appearing. It can be used to check various data for falsification.
Benford's law states that in the b-base system, the probability of a number beginning with n is 1.
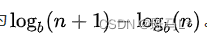
Benford's law is not only applicable to single-digit numbers, but also multi-digit numbers.
Probability of occurrence of the first digit in decimal (%, one digit after the decimal point):

BENFORD’S LAW:

Code
The data of the three financial tables needs to be found by yourself, and the data processing process has been omitted here.
import pandas as pd
import time
#
# #第三部分
# balance=pd.read_excel('E:/工作/201216本福特法则/balance.xlsx')#读取资产负债表数据
# cashflow=pd.read_excel('E:/工作/201216本福特法则/cashflow.xlsx')#读取现金流量表数据
# income=pd.read_excel('E:/工作/201216本福特法则/income.xlsx')#读取利润表数据
#
#
# # 本福特法则计算函数
# time_start = time.time()
# def benfordslaw_calculation(merge_set):
# merge_set = merge_set.fillna(0) # 填充nan数据
# CODE = merge_set.COMPCODE
# COMP_NAME = merge_set.COMPNAME
# merge_set = merge_set.drop(['COMPCODE','COMPNAME'], axis=1)
# merge_set = merge_set.astype(str)
# # 初始化变量的统计结果
# num_counts = [[0 for i in range(9)] for i in range(len(merge_set.iloc[:,1]))]
# total_counts = [0 for i in range(len(merge_set.iloc[:, 1]))]
#
# digit = 0
# # 使用循环统计1-9中数字出现的次数
# for i in range(len(merge_set.iloc[:, 1])):
# print("counting object: " + str(i))
# for j in range(len(merge_set.iloc[i, :])):
# if merge_set.iloc[i, j][0] != '0':
# total_counts[i] = total_counts[i] + 1
# if merge_set.iloc[i, j][digit] == '1':
# num_counts[i][0] = num_counts[i][0] + 1
# elif merge_set.iloc[i, j][digit] == '2':
# num_counts[i][1] = num_counts[i][1] + 1
# elif merge_set.iloc[i, j][digit] == '3':
# num_counts[i][2] = num_counts[i][2] + 1
# elif merge_set.iloc[i, j][digit] == '4':
# num_counts[i][3] = num_counts[i][3] + 1
# elif merge_set.iloc[i, j][digit] == '5':
# num_counts[i][4] = num_counts[i][4] + 1
# elif merge_set.iloc[i, j][digit] == '6':
# num_counts[i][5] = num_counts[i][5] + 1
# elif merge_set.iloc[i, j][digit] == '7':
# num_counts[i][6] = num_counts[i][6] + 1
# elif merge_set.iloc[i, j][digit] == '8':
# num_counts[i][7] = num_counts[i][7] + 1
# elif merge_set.iloc[i, j][digit] == '9':
# num_counts[i][8] = num_counts[i][8] + 1
# else:
# continue
#
# # 计算每个数字出现的频率
# for i in range(len(num_counts)):
# if sum(num_counts[i]) != 0:
# p_counts = devide_list(num_counts[i], sum(num_counts[i]))
# for j in range(9):
# num_counts[i][j] = p_counts[j]
#
# counts_diff = [[0 for i in range(9)] for i in range(len(merge_set.iloc[:, 1]))]
# # 本福特法则理论值
# benfords_dis = [30.1, 17.6, 12.5, 9.7, 7.9, 6.7, 5.8, 5.1, 4.6]
# # 计算实际统计结果跟理论值的差异
# for i in range(len(num_counts)):
# for j in range(9):
# counts_diff[i][j] = num_counts[i][j] - benfords_dis[j] / 100
#
# diff_quadratic_sum = [0 for i in range(len(merge_set.iloc[:, 1]))]
# # 计算每个数字的统计频率跟理论值的误差平方和
# for i in range(len(counts_diff)):
# for j in range(9):
# diff_quadratic_sum[i] = diff_quadratic_sum[i] + (counts_diff[i][j] * counts_diff[i][j])
#
# # 封装本福特法则计算结果
# benford = pd.DataFrame(num_counts, index=CODE, columns=['1', '2', '3', '4', '5', '6', '7', '8', '9'])
# benford['diff_quadratic_sum'] = diff_quadratic_sum
# benford['total_counts'] = total_counts
# benford['COMP_NAME'] = list(COMP_NAME)
# benford = benford.sort_values(by=['diff_quadratic_sum'])
#
# return benford
#
#
# # 计算频率的函数
# def devide_list(input_list, y):
# def f(x):
# return x / y
#
# return list(map(f, input_list))
#
#
# # 主函数入口
# if __name__ == "__main__":
# # 调用函数计算财务数据的本福特法则统计结果
# # 合并统计资产负债表、现金流量表、利润表的财务数据
# merge_set = pd.merge(balance, cashflow, how='inner', on = ['COMPCODE'])
# merge_set = pd.merge(merge_set, income, how='inner', on = ['COMPCODE'])
# merge_set = merge_set.drop_duplicates(subset=['COMPCODE'], keep='first')
# # 计算合并数据的本福特法则统计数字
# benford_total = benfordslaw_calculation(merge_set)
# output_dir = "E:/工作/201216本福特法则/benford_total.csv"
# benford_total.to_csv(output_dir, index = True, sep = ',',encoding = "utf-8-sig")#输出到本地
# # 计算资产负债表的本福特法则统计数字
# benford_balance = benfordslaw_calculation(balance)
# output_dir = "E:/工作/201216本福特法则/benford_balance.csv"
# benford_balance.to_csv(output_dir, index=True, sep=',',encoding = "utf-8-sig") # 输出到本地
# # 计算现金流量表的本福特法则统计数字
# benford_cashflow = benfordslaw_calculation(cashflow)
# output_dir = "E:/工作/201216本福特法则/benford_cashflow.csv"
# benford_cashflow.to_csv(output_dir, index=True, sep=',',encoding = "utf-8-sig") # 输出到本地
# # 计算利润表的本福特法则统计数字
# benford_income = benfordslaw_calculation(income)
# output_dir = "E:/工作/201216本福特法则/benford_income.csv"
# benford_income.to_csv(output_dir, index=True, sep=',',encoding = "utf-8-sig") # 输出到本地
# # 计算以上所有计算花费的时间
# time_end = time.time()
# time_used = (time_end - time_start) / 60
# print("time_used: " + str(time_used)) # 输出耗时
# 使用本福特法则的统计结果,对各公司的财务状况进行评分
import numpy as np
import csv
# 读取csv文件
def read_csv(input_dir):
csvFile = open(input_dir, "r",encoding='utf-8-sig')
reader = csv.reader(csvFile) # 返回的是迭代类型
data = []
for item in reader:
# print(item)
data.append(item)
csvFile.close()
return data
# 计算分位数
def quantile(data_list, seq_num=4):
quantile_list = []
for i in range(seq_num + 1):
percentage = (i / seq_num) * 100
quantile_list.append(np.percentile(data_list, percentage))
return quantile_list
# 读取三张报表合并数字的本福特统计结果跟理论结果的误差平方和
input_dir = "E:/工作/201216本福特法则/benford_total.csv"
benford_total = read_csv(input_dir)
benford_total = pd.DataFrame(benford_total[1:], columns=benford_total[0])
benford_total = benford_total.loc[:, ["COMP_NAME", "total_counts", "diff_quadratic_sum"]]
benford_total_boundarys = quantile(benford_total["diff_quadratic_sum"].astype(float), 11)
benford_total_boundarys = benford_total_boundarys[1:11]
# 读取资产负债表数字的本福特统计结果跟理论结果的误差平方和
input_dir = "E:/工作/201216本福特法则/benford_balance.csv"
benford_balance = read_csv(input_dir)
benford_balance = pd.DataFrame(benford_balance[1:], columns=benford_balance[0])
benford_balance = benford_balance.loc[:, ["COMP_NAME", "diff_quadratic_sum"]]
benford_balance_boundarys = quantile(benford_balance["diff_quadratic_sum"].astype(float), 11)
benford_balance_boundarys = benford_balance_boundarys[1:11]
# 读取现金流量表数字的本福特统计结果跟理论结果的误差平方和
input_dir = "E:/工作/201216本福特法则/benford_cashflow.csv"
benford_cashflow = read_csv(input_dir)
benford_cashflow = pd.DataFrame(benford_cashflow[1:], columns=benford_cashflow[0])
benford_cashflow = benford_cashflow.loc[:, ["COMP_NAME", "diff_quadratic_sum"]]
benford_cashflow_boundarys = quantile(benford_cashflow["diff_quadratic_sum"].astype(float), 11)
benford_cashflow_boundarys = benford_cashflow_boundarys[1:11]
# 读取利润表数字的本福特统计结果跟理论结果的误差平方和
input_dir = "E:/工作/201216本福特法则/benford_income.csv"
benford_income = read_csv(input_dir)
benford_income = pd.DataFrame(benford_income[1:], columns=benford_income[0])
benford_income = benford_income.loc[:, ["COMP_NAME", "diff_quadratic_sum"]]
benford_income_boundarys = quantile(benford_income["diff_quadratic_sum"].astype(float), 11)
benford_income_boundarys = benford_income_boundarys[1:11]
# 将上述四列数据,合并到一个数据集
merge_set = pd.merge(benford_total, benford_balance, how='inner', on=['COMP_NAME'])
merge_set = pd.merge(merge_set, benford_cashflow, how='inner', on=['COMP_NAME'])
merge_set = pd.merge(merge_set, benford_income, how='inner', on=['COMP_NAME'])
merge_set.columns = ["COMP_NAME", "counts", "total", "balance", "cash_flow", "income"]
# 设置运算结果为浮点数,以便于保留小数位得分
merge_set.counts = merge_set.counts.astype(float)
merge_set.total = merge_set.total.astype(float)
merge_set.balance = merge_set.balance.astype(float)
merge_set.cash_flow = merge_set.cash_flow.astype(float)
merge_set.income = merge_set.income.astype(float)
score_list = []
for i in range(len(merge_set.COMP_NAME)):
print("counting object: " + str(i))
weight_score_list = []
# 赋权重
for j in range(2, 6):
if merge_set.iloc[i, j] < benford_total_boundarys[0]:
weight_score_list.append(0)
elif merge_set.iloc[i, j] >= benford_total_boundarys[0] and merge_set.iloc[i, j] < benford_total_boundarys[1]:
weight_score_list.append(1 * 1.1)
elif merge_set.iloc[i, j] >= benford_total_boundarys[1] and merge_set.iloc[i, j] < benford_total_boundarys[2]:
weight_score_list.append(2 * 1.2)
elif merge_set.iloc[i, j] >= benford_total_boundarys[2] and merge_set.iloc[i, j] < benford_total_boundarys[3]:
weight_score_list.append(3 * 1.3)
elif merge_set.iloc[i, j] >= benford_total_boundarys[3] and merge_set.iloc[i, j] < benford_total_boundarys[4]:
weight_score_list.append(4 * 1.4)
elif merge_set.iloc[i, j] >= benford_total_boundarys[4] and merge_set.iloc[i, j] < benford_total_boundarys[5]:
weight_score_list.append(5 * 1.5)
elif merge_set.iloc[i, j] >= benford_total_boundarys[5] and merge_set.iloc[i, j] < benford_total_boundarys[6]:
weight_score_list.append(6 * 1.6)
elif merge_set.iloc[i, j] >= benford_total_boundarys[6] and merge_set.iloc[i, j] < benford_total_boundarys[7]:
weight_score_list.append(7 * 1.7)
elif merge_set.iloc[i, j] >= benford_total_boundarys[7] and merge_set.iloc[i, j] < benford_total_boundarys[8]:
weight_score_list.append(8 * 1.8)
elif merge_set.iloc[i, j] >= benford_total_boundarys[8] and merge_set.iloc[i, j] < benford_total_boundarys[9]:
weight_score_list.append(9 * 1.9)
else:
weight_score_list.append(10 * 2)
comprehensive_score = (20 - sum(weight_score_list) / 4) / 2 # 计算本福特得分
# 如果一家公司的数字太少,直接得-1分
if merge_set.counts[i] < 50:
comprehensive_score = -1
score_list.append(comprehensive_score)
merge_set["score"] = score_list
merge_set = merge_set.sort_values(by="score", axis=0, ascending=False)
# 输出每家公司的最终本福特评分结果
output_dir = "E:/工作/201216本福特法则/benfordslaw_comprehensive_score.csv"
merge_set.to_csv(output_dir, index=False, sep=',',encoding = "utf-8-sig")