Distributed System Consensus Mechanism: Consensus Algorithm Design Ideas
This time, I will summarize the consensus algorithm I have learned from a macro perspective. The goal of the consensus algorithm is to keep most of the nodes in the distributed system consistent with data.
Consensus algorithms in the blockchain, such as pow and pos, belong to this scope, but they are only applied in the blockchain field. The consensus algorithm introduced below is widely used in distributed systems, and of course it is definitely applicable In the blockchain, and finally I summed up their design ideas, in fact, there are certain routines.
Paxos algorithm
The first is the paxos algorithm, which has been tested in a large number of engineering practices. It is used in many Google projects and the big data component zookeeper. It is very complicated to implement, but the basic idea is not difficult to understand.
node role
Paxos nodes have three roles, namely:
The first type is the proposer , responsible for proposing proposals, that is, the data to be synchronized.
The second type of approvers , the proposal proposed by the proposer must be approved by more than half of the approvers.
The third type of learner . Does not participate in the proposal, only responsible for receiving confirmed proposals, generally used to improve the ability of the cluster to provide external read services.
Algorithm process
The specific process of the algorithm mainly has three stages:
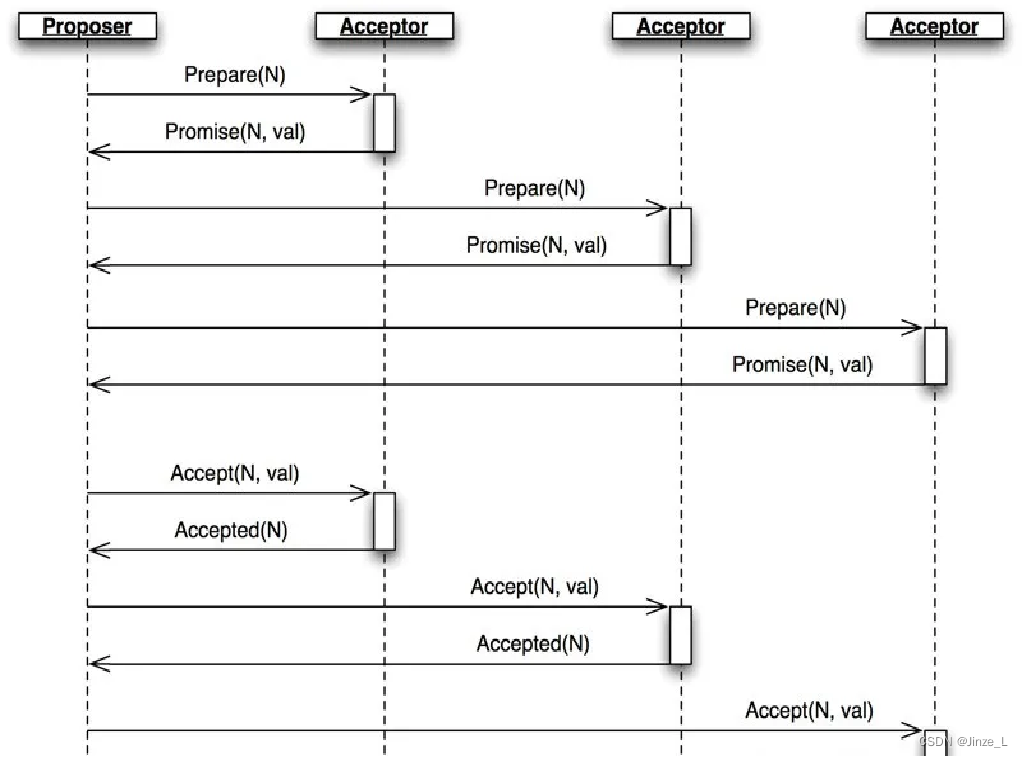
the first is the Prepare stage , the proposer selects a proposal number N, and sends a Prepare request of this number to the approvers. After receiving the request, the approver judges whether N is greater than the number of the Prepare request that has been responded locally, and if so, feeds back the number to the proposer, and will not approve proposals with a number smaller than N.
Then there is the Accept phase . If the proposer receives responses from more than half of the approvers, it sends an Accept request for the [N,val] proposal to the approver, where val is the value of the proposal. The approver then accepts the corresponding value and returns a response to the proposer.
By this time, both approvers and proposers have reached consensus.
Finally, it enters the Learn stage . This stage does not belong to the process of selecting proposals. The proposer will synchronize the approved proposals to all learners.
Eventually, most nodes will reach a consensus.
Obviously, this algorithm is not suitable for distributed systems with Byzantine nodes, but only for ordinary distributed systems.
Raft algorithm
Although the principle of Paxos is relatively easy to understand, its engineering implementation is very complicated, so the Raft algorithm appears, which is a simplified implementation of the Paxos algorithm. The basic idea is similar.
node role
Similarly, a node has three roles:
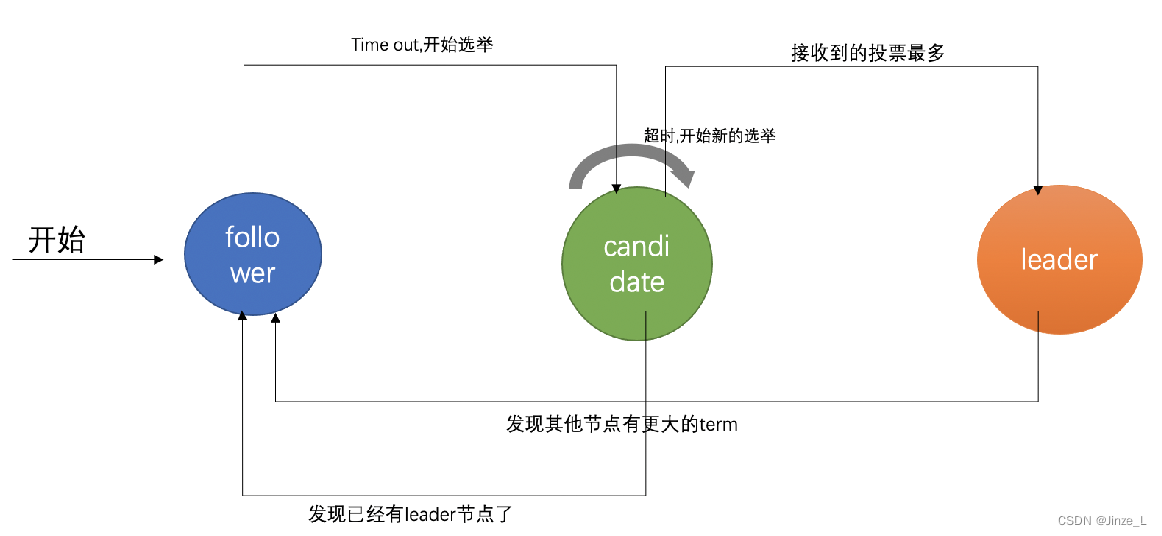
first, it is a follower, which is the initial state of the cluster. When a node joins, it is a follower by default, that is, a slave node.
Then there is the candidate candidate, which is the title of the voter during the election. This is an intermediate role. For example, if followerA votes for followerB, the role of followerB is candidate.
Finally, the leader master node is used to receive user requests and perform data synchronization.
core mechanism
The RAFT algorithm is divided into two phases: Leader election and log replication .
First look at how the leader is selected.
leader election
At the beginning of the algorithm, all nodes are Followers, each node will have a timer, and the timer will be reset when receiving a message from the Leader. If the timer expires, it means that no message from the Leader has been received within a period of time, then the Leader is considered to be absent, and the node will be transformed into a Candidate, ready to compete for the Leader.
After becoming a candidate, the node will send a request for voting to other nodes. After receiving the request, other nodes will judge whether to vote for him and return the result. A Candidate can become a Leader if it receives more than half of the votes. After becoming a Candidate, it will periodically send a heartbeat message to notify other nodes of the new Leader information during the term of office, which is used to reset the timers of other nodes and prevent other nodes from becoming Candidates.
log replication
After the leader is elected, it is necessary to start synchronizing data.
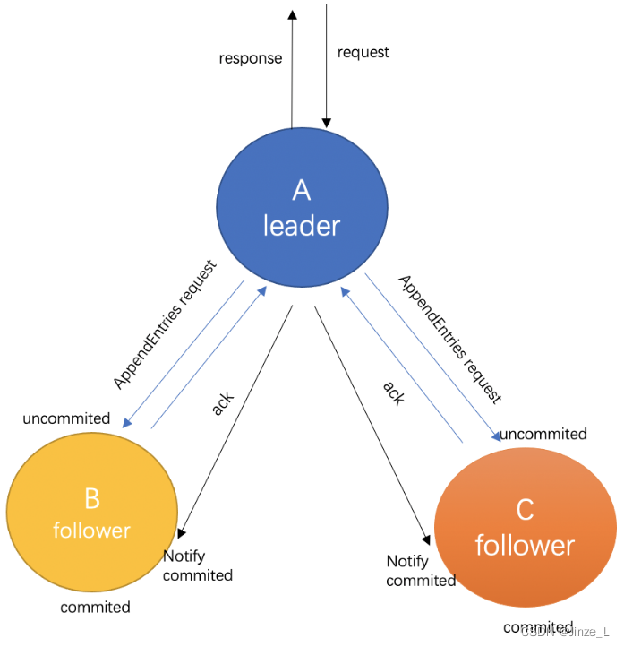
When the leader receives the client's request, it will package the request into a log package and send it to other nodes. This process is called log replication. Other nodes respond ACK to the master node after receiving the data.
The leader waits for more than half of the nodes in the cluster to respond, and then replies to the client that the data has been received. At this point, enter the state where the data has been submitted.
Finally, the Leader node informs other nodes that the data status has been submitted, and other nodes start to commit their own data. At this time, the cluster reaches the consistency between the master node and the slave node.
Both the raft algorithm and the paxos algorithm introduced just now assume that there is no Byzantine general problem, and only consider problems such as node downtime, network partition, and unreliable messages. The following algorithms take into account the situation of nodes doing evil. The most classic and practical is pbft. I have introduced the implementation details of this algorithm many times before, but this time I will interpret it from another angle.
PBFT
First of all, it is also divided into different store node roles, namely:
master node, responsible for packaging transactions into blocks, and each round of consensus process can only have one master node.
Replica nodes are responsible for consensus voting, and there are multiple replica nodes in each round of consensus.
Process:
The client sends a request to the master node.
The master node broadcasts the request to other nodes, and the node executes the three-stage consensus process of the PBFT algorithm.
After the three-stage process, return the message to the client.
After the client receives the same message from f+1 nodes, it means that the consensus has been completed correctly.
The consensus algorithm based on voting is basically a routine: determine a leader to make a proposal, and other nodes are responsible for voting. According to the voting results to determine whether the proposal is passed. When the master node puts forward a proposal, the voting and collection of votes of other nodes are completed by each node independently. This is because of the existence of Byzantine nodes, nodes only believe in the voting information they have obtained, and each node determines based on the information it collects. Whether the proposal has reached consensus.
Therefore, four stages are designed:
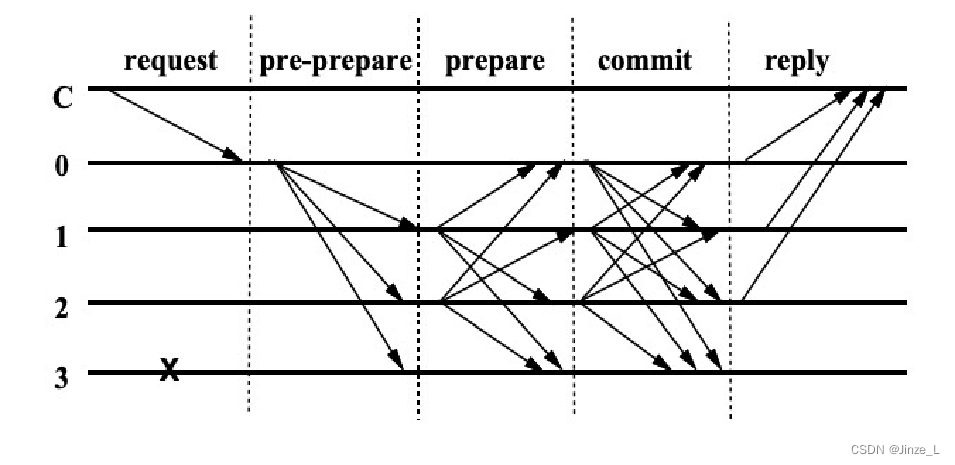
first, the pre-prepare stage is that the master node sends a proposal to the replica node, and the replica node receives the proposal and verifies it, but does not know the status of other nodes.
In the prepare phase, each legal node receives at least 2/3 of the votes, we call a node receiving at least 2/3 of the votes event A , obviously at least 2/3 of the nodes have event A, However, the nodes do not know whether event A has occurred to each other;
so there is a commit phase, each node broadcasts the message that event A has occurred to other nodes, and also collects the broadcasts of other nodes about event A. We collect Event A to at least 2/3 nodes is called event B. At this point, each node knows that event A has occurred in at least 2/3 of the nodes, then most of the nodes have reached a consensus. However, the client doesn't know the result yet.
Finally, in the reply phase, each node returns event B to the client. At this time, the client can judge that the system has reached a consensus as long as it collects the broadcast of event B from at least f+1 nodes. We call the broadcast of event B that collects at least f+1 nodes event C.
Therefore, pbft has set up four stages to ensure the occurrence of these three events .
Hotstuff
According to the introduction just now, the key point in PBFT is that each node does the work of collecting votes independently, which leads to the duplication of the workload of the nodes in the entire algorithm. The reason why PBFT does this is that nodes only trust the voting information they have obtained. If this trust problem can be solved, then these repetitive tasks will be saved. The optimization performed by HotStuff is based on this, by using threshold signatures to ensure that voting results cannot be forged.
threshold signature
The node role is the same as that of PBFT, which is divided into master node and replica node.
Threshold signature A brief introduction: a (k, n) threshold signature scheme refers to a signature group composed of n members, all members share a public key, and each member has its own private key. As long as the signatures of k members are collected and a complete signature is generated, this signature can be verified by the public key.
Here we will not discuss the technical details of the threshold signature in detail, but mainly focus on how the algorithm is applied. In HotStuff, in addition to making proposals, the leader also needs to collect votes from other nodes, and integrate the voting results into a proof that is easy to check legality but cannot be forged. The characteristic of threshold signature is that a signature can be synthesized if and only if there are enough sub-signatures for the same data, and others only need to verify the final signature to ensure that the entire signature construction process is legal. The use of threshold signatures enables all nodes to delegate the work of collecting voting information to the leader, and ensures that the leader cannot cheat. Therefore, the final algorithm complexity of HotStuff is directly reduced by an order of magnitude.
core mechanism
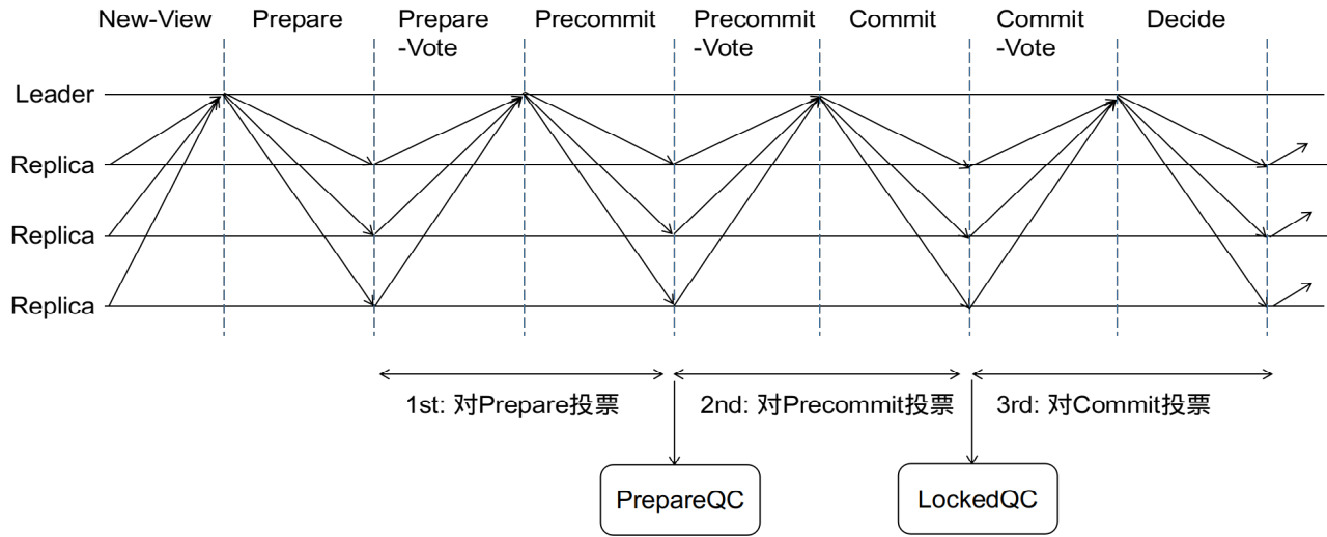
HotStuff mainly integrates the idea of "leader is responsible for collecting voting information for each round" into pbft. There are 2 rounds of all node broadcasts and collection voting + 1 round of client collection voting in pbft. If it is replaced by the leader to collect votes, it will take 3 rounds to ensure the occurrence of these three events.
In the first stage, votes from at least 2/3 nodes are collected, that is, event A occurs on the leader node . At this time, the leader node retains the evidence at this point in time and broadcasts it to other nodes. Other nodes are equivalent to the occurrence of event A; but it is not known whether other nodes have received the event A broadcast by the leader; the
second stage, so the node that receives event A will send a message to the leader; the leader will collect these votes, that is, the leader Event B has occurred . Similarly, this event B is broadcast to other nodes. When other nodes receive event B, it is equivalent to event B, but they still do not know whether other nodes have received event B. In the third stage,
follow Same as step 2, the node that received event B will also send a vote to the leader, and the leader collects it. At this time, the leader has event C. Similarly, the event is broadcast to other nodes. After other nodes receive it, they confirm the consensus has been achieved.
Summarizing the design ideas of the above consensus algorithms, they can be divided into a two-phase commit protocol and a three-phase commit protocol .
Phase Two Commitment Protocol
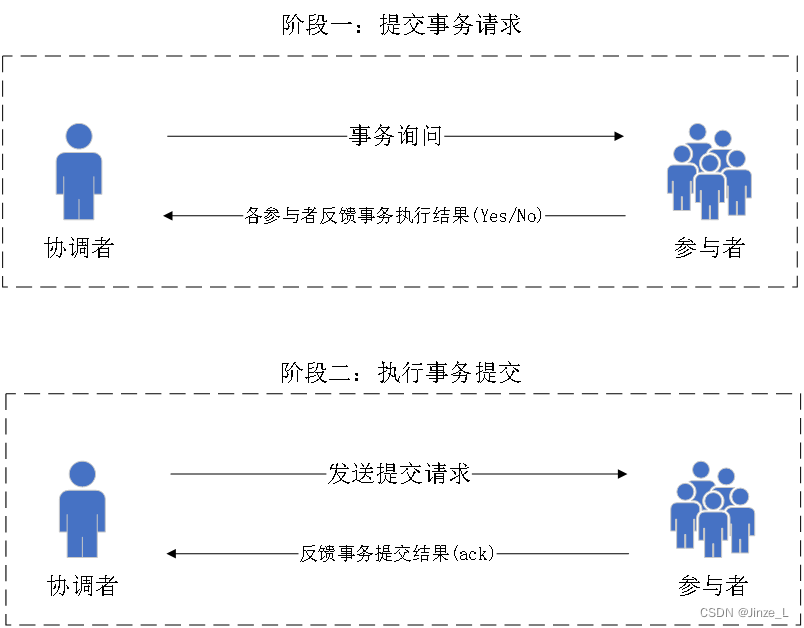
The second phase is mainly adopted: first try, then submit.
Can be divided into two roles: coordinator and participant.
The first phase is to submit the transaction request .
The coordinator sends the transaction content to the participant, asks whether the transaction submission operation can be performed, and waits for a response; the
participant performs the transaction operation and replies to the coordinator, and returns Yes if the execution is successful, otherwise No.
The second phase is to perform a transaction commit .
If the participants all reply Yes, then the coordinator sends a commit request to the participants, otherwise a rollback request is sent.
Participants perform transaction commit or rollback according to the request of the coordinator, and send an Ack message to the coordinator.
After the coordinator receives all Ack messages, it judges whether the result of the distributed system transaction is completed or failed.
Both paxos and raft introduced just now are implemented based on the idea of two-phase commit.
Advantages of the second stage :
- The principle is simple;
- The atomicity of distributed transactions is guaranteed, either all executions succeed or all executions fail.
Disadvantages of the second stage :
- Synchronous blocking: During the submission execution process, each participant is waiting for the response of other participants, and cannot perform other operations.
- Single-point problem: there is only one coordinator, the coordinator hangs up, and the entire two-phase commit process cannot be executed; more seriously, if there is a problem with the coordinator during phase two, the participants will always be locked in the transaction state and cannot continue Complete the transaction operation.
- Data inconsistency: In phase 2, after the coordinator sends the Commit request, if a network failure occurs, only some participants receive the commit request and execute the commit operation, resulting in data inconsistency.
Three Phase Commit Protocol
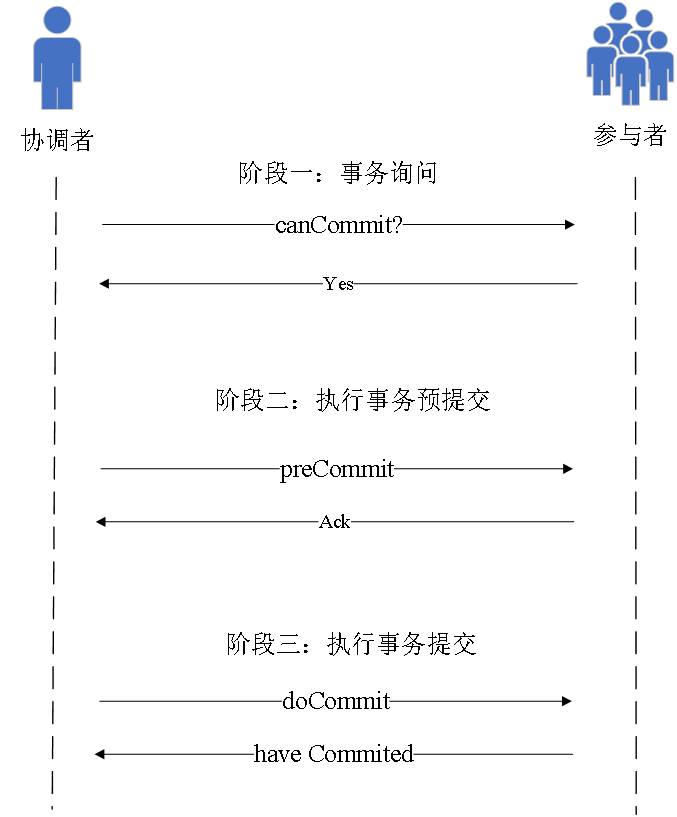
Because there are many problems with the two-phase commit, there is a three-phase commit
The main improvement point is to divide the first phase into two phases, first initiate the transaction query, and then execute the transaction .
At the same time, timeout mechanisms are introduced in the coordinator and participants.
Phase 1 Transaction
inquiry The coordinator sends an inquiry request containing the transaction content to the participant, asking whether the transaction can be executed; the
participant judges and replies yes or no according to its own state;
The second stage executes
transaction pre-commit If the coordinator receives yes from most nodes, it sends a preCommit request, otherwise it issues an abort request;
if the participant receives preCommit, it executes the transaction and returns an Ack. If abort or timeout is received, the transaction is interrupted;
The third stage is to execute
the transaction submission . If the coordinator receives most of the nodes as Ack, it sends a doCommit request;
the participant submits the transaction and returns a response after receiving the doCommit;
after the coordinator receives the response, it judges whether to complete the transaction or interrupt the transaction;
The basic idea of algorithms such as pbft and hotstuf is a three-phase commit protocol. Advantages
of the three stages :
- The scope of synchronous blocking in the second phase is reduced. In the second phase, as long as the participant receives the preCommit request, the transaction will be executed without blocking all the time.
- Solve the single-point problem: two situations will occur in the third stage: 1: There is a problem with the coordinator; 2: There is a network failure between the coordinator and the participant; both will cause the participant to fail to receive the doCommit request, but the participant will not receive the doCommit request after the timeout Transactions will be committed.
Disadvantages of three stages
- There will still be a data partition problem: the participant receives a preCommit request. If a network partition occurs at this time, normal network communication between the coordinator and the participant cannot be carried out. The participant will still commit the transaction after the timeout, and data inconsistency will occur . Of course, this is a common problem of distributed systems. To maintain consistency and availability, partition fault tolerance must be sacrificed. This is the impossible triangle of distributed systems, which is the cap theory. So whether it is a two-phase commit or a three-phase commit, data partitioning is inevitable.
