1.1 Consensus mechanism
1.1.1 Core Definition
The consensus mechanism on the blockchain mainly solves the problem of who constructs the block and how to maintain the unity of the blockchain
1.1.2 Classification of Consensus Mechanisms
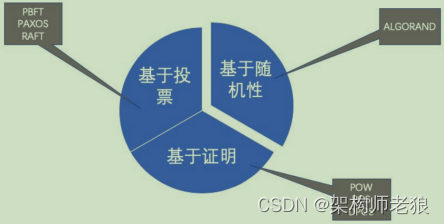
1.1.3 Consensus Algorithm
1.1.3.1 POW (Proof of Work)
Representative item: BTC
Since different nodes accept different data, in order to ensure data consistency, each block data can only be recorded by one node. BTC confirms the bookkeeping nodes through "Proof of Work" (PoW). If each node wants to generate a new block and write it into the blockchain, it must solve the PoW problem of the Bitcoin network. The key elements are the workload proof function, block information and difficulty value. The proof-of-work function is the calculation method of this question, the block determines the input data of this question, and the difficulty value determines the amount of calculation required for this question. It can be simply understood that the achievement is the process of taking different nonce values as input, trying to perform SHA256 hash operation, and finding a hash value that satisfies a given number of leading 0s. The more leading 0s are required, the greater the difficulty.
The steps for Bitcoin nodes to solve the proof-of-work problem are roughly summarized as follows:
- Generate a coinage transaction, and form a transaction list with all other transactions to be packaged into the block, and generate a Merkle root hash through the Merkle tree algorithm;
- Assemble the Merkle root hash and other related fields into a block header, and use the 80-byte data of the block header as the input of the workload proof;
- Constantly change the random number in the block header, that is, the value of nonce, and perform double SHA256 operations on each changed block header (that is, SHA256 (SHA256 (Block_Header))), and compare the result value with the target value of the current network In contrast, if it is less than the target value, the problem is solved successfully and the proof of work is completed.
1.1.3.2 POS (proof of equity)
Representative project: At present, the consensus mechanism of Ethereum is iterating in the direction of POS
Because the PoW method needs to consume a lot of computing power, everyone is caught in computing power competition, which leads to security risks in the concentration of computing power in the top mines. At the same time, the mining process has no practical value, so the POS mechanism appears.
At present, the PoS mechanism still has problems to be solved and is still under development. At present, the more common method is the method adopted by the first Peercoin.
In the PoW+PoS hybrid consensus represented by Peercoin,
under the proof-of-stake PoS mode adopted, there is a term called coin age, each coin generates 1 coin age per day, and the difficulty is related to the transaction input in the hash calculation. Coin age is inversely proportional. At the same time, the coin age is cleared after the block is produced. However, it is still necessary for the nodes participating in block production to perform a certain amount of hash value calculation, that is, to produce blocks in a manner similar to the workload, but the probability that each node finds a legal block through calculation is related to the rights and interests held by the node. That is, producers are selected according to their rights and interests, and an incentive method based on rights and interests is adopted. It only solves the problem of massive energy consumption and waste caused by the POW mechanism to a certain extent.
New PoS consensus represented by Ethereum Casper
- Validators stake a percentage of the ether they own as a security deposit.
- Then, it starts validating every candidate block (blocks submitted by validators who paid a deposit) at every block height. That is, when they find a block that they believe can be added to the chain, they will verify it by placing a bet.
- Through the betting of multiple validators, the only winning block will be selected for each height.
- If the block is added to the chain, then validators will get a reward proportional to their stake.
- However, if a validator acts in a malicious way, trying to do "nothing at stake" (like betting multiple times, betting repeatedly), they will be punished immediately.
1.1.3.3 DPOS (Delegated Proof of Stake)
Representative project: EOS
For cryptocurrencies with a PoS mechanism, each node can create a block. DPoS is a trusted account (super account) elected by the community to create blocks. The DPoS mechanism is similar to a joint-stock company. Ordinary shareholders cannot enter the board of directors, and must vote for representatives (trustees) to make decisions on their behalf.
1.1.3.4 PBFT (Practical Byzantine Fault Tolerant Algorithm)
The design idea of PBFT has been used for reference in many consensus mechanisms, and has also been adopted by many alliance chains.
In addition to supporting fault-tolerant faulty nodes, it also supports fault-tolerant malicious nodes. Suppose the number of cluster nodes is N, and the problematic nodes are f. The maximum number of fault-tolerant nodes for the pbft algorithm is (n-1)/3. Among the problematic nodes, they can be both faulty nodes and malicious nodes, or only faulty nodes or malicious nodes.
Assume that the faulty node and the malicious node are different nodes. Then there will be f problematic nodes and f faulty nodes. When a node is found to be a problematic node, it will be excluded from the cluster, leaving f faulty nodes. According to the principle that decimals obey the majority, the normal nodes in the cluster only need to compare If f nodes have one more node, that is, f+1 nodes, the number of correct nodes will be more than the number of faulty nodes, and then the cluster can reach a consensus. Therefore, the sum of the number of nodes of all types is f+1 correct nodes, f fault nodes and f problem nodes, that is, 3f+1=n
The basic process of the pbft algorithm mainly has the following four steps:
- The client sends a request to the master node
- The master node broadcasts the request to other nodes, and the nodes execute the three-stage consensus process of the pbft algorithm.
- After the node completes the three-stage process, it returns a message to the client.
- After the client receives the same message from f+1 nodes, it means that the consensus has been completed correctly.
Why does it mean that the consensus has been completed correctly after receiving the same message from f+1 nodes? From the derivation in the previous section, we can see that no matter in the best case or the worst case, if the client receives the same message from f+1 nodes, it means that enough correct nodes have reached a consensus and processed It's over.
1.1.3.5 RAFT
Fabric: The raft algorithm has been implemented.
Unlike PBFT, RAFT does not support malicious nodes, so it is more used in private chains. The raft algorithm contains three roles, namely: follower (follower), candidate (candidate) and leader (leader). A node in the cluster can only be in one of these three states at a certain moment, and these three roles can be converted to each other as time and conditions change.
The raft algorithm mainly has two processes: one process is leader election, and the other process is log replication. The log replication process will be divided into two stages: recording logs and submitting data. The maximum fault-tolerant node supported by the raft algorithm is (N-1)/2, where N is the total number of nodes in the cluster.
In Raft, each node will be in one of the following three states:
- follower: All nodes start in the follower state. If no leader message is received, it will become a candidate state
- candidate: It will "pull votes" to other nodes, and if it gets most of the votes, it will become the leader. This process is called Leader Election (Leader Election)
- leader: All modifications to the system will go through the leader first. Each modification will write a log (log entry).
The process after the leader receives the modification request is as follows. This process is called log replication (Log Replication): - Copy logs to all follower nodes (replicate entry)
- Submit logs when most nodes respond
- Notify all follower nodes that the log has been submitted
- All followers also submit logs
- The whole system is in a consistent state
Raft algorithm animation: https://link.zhihu.com/?target=http%3A//thesecretlivesofdata.com/raft/
1.1.4 Comparison of Consensus Algorithms
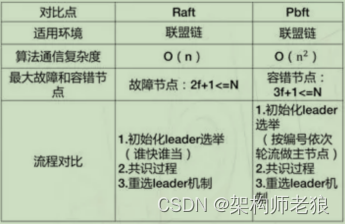
1.1.4.1 PBFT VS RAFT
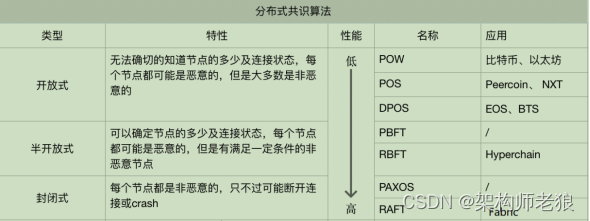
1.1.4.2 Comparison of Mainstream Algorithms
1.1.4.3 Comparison between ZAB protocol and Raft protocol
ZAB implements the sequence of operations through the strong leader model of "everything depends on the leader" and the strict sequential processing and submission of proposals. The master node broadcasts messages based on the TCP protocol, and guarantees the order in which messages are received. came out earlier.
The Raft protocol is that the Raft protocol is all based on the leader, to achieve a consensus of a series of values and the consistency of the logs of each node. The sequence and integrity of messages or data is guaranteed through the continuity of the log. The log in the Raft protocol is not only the carrier of data, but the integrity of the log will also affect the result of leader election (Note: the election factor is not only guaranteed by the integrity of the log, but also other factors such as term of office).
Raft is currently a widely used distributed protocol with strong consistency, decentralization and high availability in engineering. The emphasis here is on engineering, because in the academic theory circle, the most dazzling is the famous Paxos.
Different score:
-
Leader Election:
ZAB adopts the Fast Leader Election of "seeing the best and recommending each other". Nodes compete through PK (capital is the information held) to see which node is more suitable to be a Leader. After the node PK, the ballot information will be broadcast, and finally the node with the most complete data among the majority of nodes will be elected.
Raft uses a custom algorithm of "one vote, first come, first served" (Note: It contains a concept of random waiting time to ensure that the election process can be completed for a few elections at most.), here is a brief introduction: When a node finds that the leader is down, it elects itself as the leader, and then notifies other nodes, and the other nodes vote for the first node that notifies it. (Note: PK will also be involved here. According to the integrity of the data and the term of office, if the node notifying it does not have the data integrity of the current node, the current node will not vote for the node.) From the above
, Raft's leader election requires fewer messages to communicate and faster elections. -
Log replication:
Raft and ZAB are the same, they are based on the leader's log to achieve log consistency, and the log must be continuous and must be submitted in order.
ZAB uses TCP to ensure the order of operations.
The Raft protocol implements log continuity by adding its own checksum to the Log Entry. It is recommended to read the blog post above -
Read operations and consistency:
The design goal of ZAB is the sequentiality of operations. The default implementation in ZooKeeper is final consistency. Read operations can be performed on any node; (Note: There is nothing wrong with saying that ZK is CP in many places, but It does not refer to the strong consistency of reading and writing in ZK, it means that when P occurs, ZK is C, or seeing this is very confusing, read the above blog, and carefully look at the diagram of CAP theory, which is also clear It marks that when P does not occur, AC can coexist)
and the design goal of Raft is strong consistency (that is, linear consistency), so Raft is more flexible (you can configure it yourself), and the Raft system can provide strong consistency Resilience can also provide final consistency, but generally in order to ensure performance, final consistency is also provided by default. -
Write operations:
Raft is the same as ZAB, and write operations must be processed on the leader node. -
Membership changes:
Both Raft and ZAB support membership changes, and ZAB implements it in the form of dynamic configuration. Then when you change the node, there is no need to restart the machine, the cluster is always running, and the service will not be interrupted. -
Design phase:
Compared with ZAB, Raft's design is more concise. For example, Raft does not introduce a member discovery and data synchronization phase similar to ZAB. Instead, when a node initiates an election, it increments the term number. After the election, it broadcasts a heartbeat and directly establishes The leader relationship, and then synchronize the log to each node to achieve the consistency of the data copy.
During the data synchronization phase of the ZAB protocol, the ZAB cluster cannot provide external services.
In fact, ZAB members found that it can be combined with leader election, similar to Raft, after the leader election is over, the leader relationship is directly established instead of introducing a new stage; the data synchronization stage is a redundant The design can be removed, because ZAB does not have to achieve the consistency of the data copy before it can process the write request, and this design has no additional meaning and value. -
Design independence
ZAB and ZooKeeper are strongly coupled, and you cannot use them independently in actual systems; while Raft implementations (such as Hashicorp Raft) can be used independently and are programming-friendly.