Hole (expansion) convolution --------Dilated Convolution
Atrous convolutions , also known as dilated convolutions, were proposed at ICLR 2016. Its main function
在不增加参数和模型复杂度的条件下,可以指数倍的扩大视觉感受野(每一个输出是由诗句感受野大小的输入决定的)的大小。is to reduce image resolution and lose information in the problem of image semantic segmentation. accumulate ideas. By adding holes to expand the receptive field, a hyperparameter called "dilate rate" is introduced to the convolutional layer, which defines the distance between values when the convolution kernel processes data.
Hole convolution is an operation on the convolution kernel, and has a larger receptive field when the number of parameters remains the same.
Hole convolution was born in the field of image segmentation. The image is input into the network and extracted by CNN, and then the receptive field is increased while reducing the image scale through pooling.
Since image segmentation is a pixel-wise prediction output, it is also necessary to restore the reduced image to its original size through upsampling. Upsampling is usually done by deconv (transposed convolution). Therefore, image segmentation FCN has two key steps:
- The pooling operation increases the receptive field
- The upsampling operation enlarges the image size.
Disadvantage:
Although the size is restored after the upsampling operation, many details are still lost by the pooling operation.
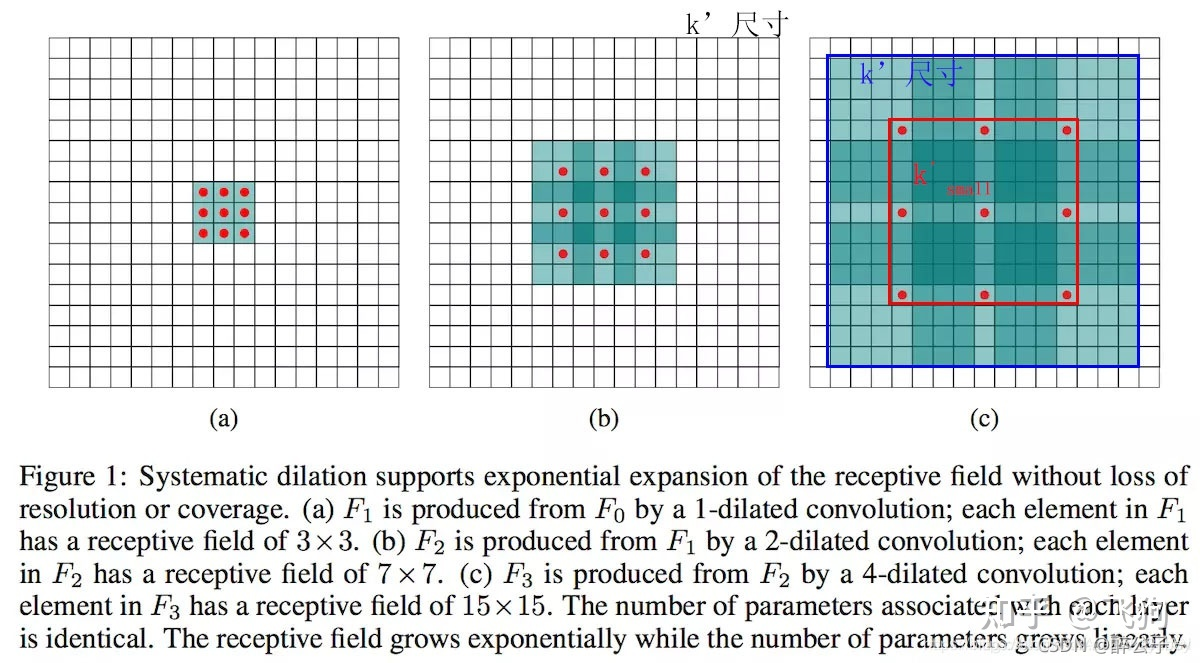 As can be seen from the above figure, dilated convolution is to expand the size of the convolution kernel on the basis of the original kernel (a new convolution kernel is generated), eg: 3 ∗ 3
As can be seen from the above figure, dilated convolution is to expand the size of the convolution kernel on the basis of the original kernel (a new convolution kernel is generated), eg: 3 ∗ 3
— — — > 5 ∗ 5 3 * 3 —— —> 5*53∗3———>5∗5
But he didn't get more parameters, but just selected the value of a specific area according to a certain rule, and the receptive field became larger.

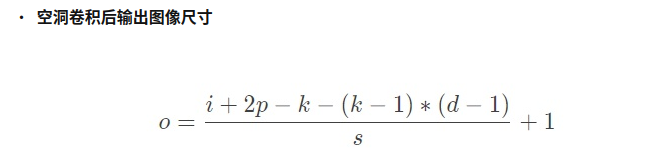 o : output feature map
o : output feature map
ℹ : input map size
p : padding
k : kernel size
d : expansion coefficient
s : step size
Advantages:
In the case of constant parameters, a larger field of view can be obtained, and a larger target can be extracted;
Groupable convolution
Group convolution first appeared in AlexNet. Due to the limited hardware resources at that time, the convolution operations could not all be processed on the same GPU when training AlexNet. Therefore, the author assigned feature maps to multiple GPUs for processing separately. Finally, the The results of multiple GPUs are fused.
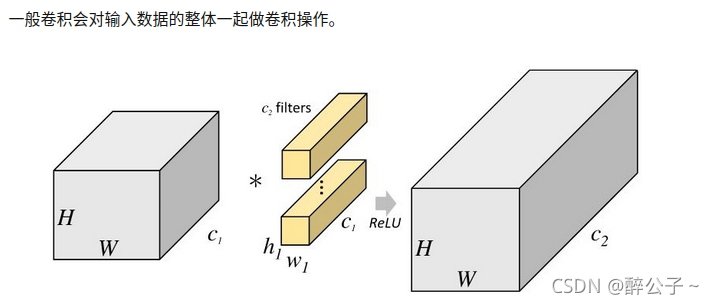
General convolution calculation:
Input 256 feature maps, output 256 feature maps
input : 256
kernel: 3*3
output:256
Parameter quantity: 256 * 3 * 3 * 256
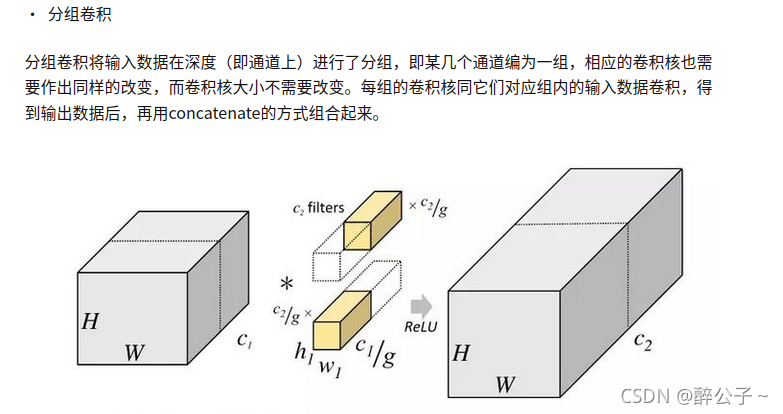
Group convolution calculation:
Divide 256 channels into 8 groups, each with 32 feature maps
input : 32
kernel: 3*3
group: 8
output:32
Parameter amount: 8 * 32 * 3 * 3 * 32
advantage:
- better structured learning;
- overcome overfitting;
- reduce parameters;
Hope this article is useful to you!
Thank you for your likes and comments!