Article Directory
1 Summary
In this paper, DeepLab system for semantic segmentation, the three major contributions: ① using the "empty convolution" instead of the traditional general convolution; ② made empty space pyramid pooled (ASPP) effectively solve the problem of multi-scale image; ③ using conditional random field (CRF) after processing of FIG characterized solve the positioning image boundary, the problem of inaccurate segmentation. DeepLab system combines DCNN achieve the best results when the PASCAL VOC-2012 semantic segmentation task, the other three sets of data: PASCAL-Context, PASCAL-Person-Part, Cityspaces also have a good performance.
2 Highlights
2.1 hollow convolution
In DCNN, due to the need to improve the convolution kernel of receptive fields in order to get richer image semantic information and semantic links each convolution sliding window, it usually needs to be repeated image convolution pool and get a smaller feature Fig. But the pool of carrying out the process, some of the details of the image may be out of the pool, but in order to increase the convolution of the receptive field while reducing the parameters, they must be pooled operation; To compensate for the loss caused by pooling information , characterized by a pool of FIG front fused with FIG characteristics obtained after upsampling FCN, U-net-peer network to recover some of the lost information. The authors think of a best of both worlds is to use something called a hollow convolution to replace the ordinary convolution, can obtain more receptive field with the same parameters, each sliding window can integrate more image information or semantic context information . FIG follows:
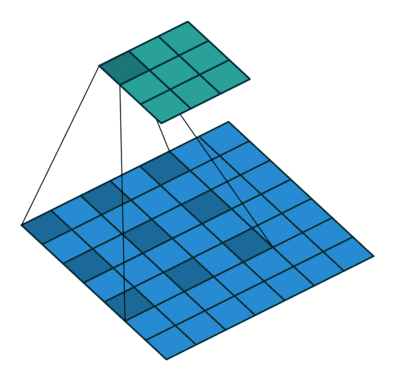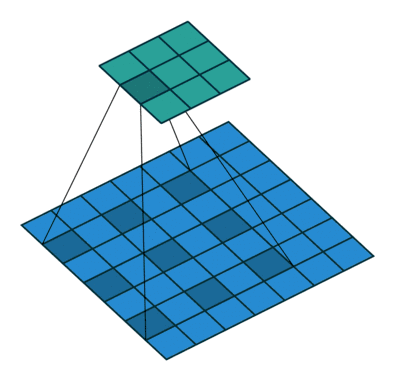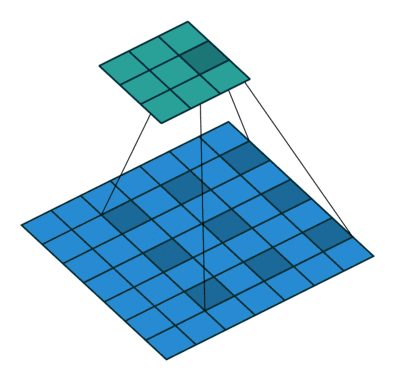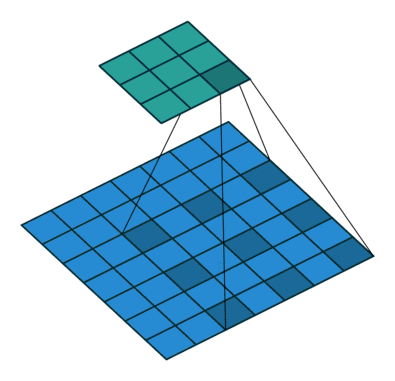
Visible moving below the above figure with numbers filled convolution kernel is a 3x3, but not all filled convolution kernel, but the spacing is filled, then a 3x3 fully populated with respect to the filling can be obtained more spaced Jia receptive field, and wherein the convoluted FIG smaller, there is no need of the cell layer, that is to say the same parameters, the cavity can be greater convolution receptive field. Better hollow convolution can refer to the following detailed description of this blog:
Empty convolution of understanding
Downsampling below shows the same parameters on + + convolution and sampling effects FIG hollow convolution comparison:
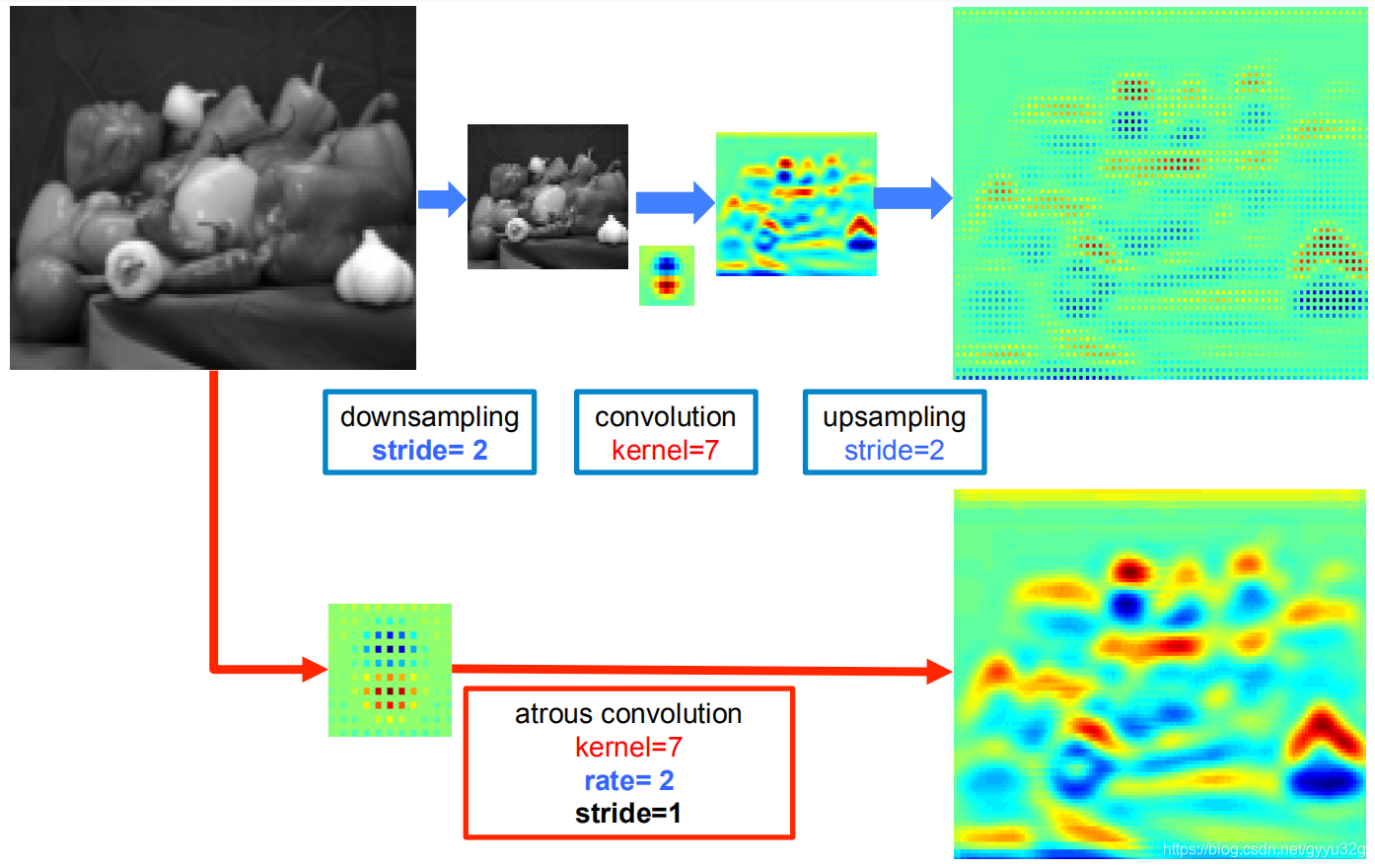
can be visually observed through heat FIG convolution + + downsampling the upsampled produced is sparse, directly by FIG hollow convolution heat generated relatively more dense, indicating that after the hollow profile generated convolutional more details in FIG.
2.2 empty space pyramid pooled (ASPP)
多尺度问题也是语义分割中一个重要的问题,多尺度问题可以理解为在一张图片中近处有一个人和远处一辆车,直接通过CNN提取特征获得的是全局特征,而单纯地截取车辆部分放大至与原图相同的尺寸并且在其基础上提取特征,这就是一个局部特征。多尺度就是在保证全局特征的基础上要保证局部特征的不丢失,特征图上既有全局特征又有局部特征。本文提出ASPP来解决多尺度问题。其基本思路是:针对一张图片,同时使用多个不同空洞率的空洞卷积核,将得到的所有结果进行融合。如下图。
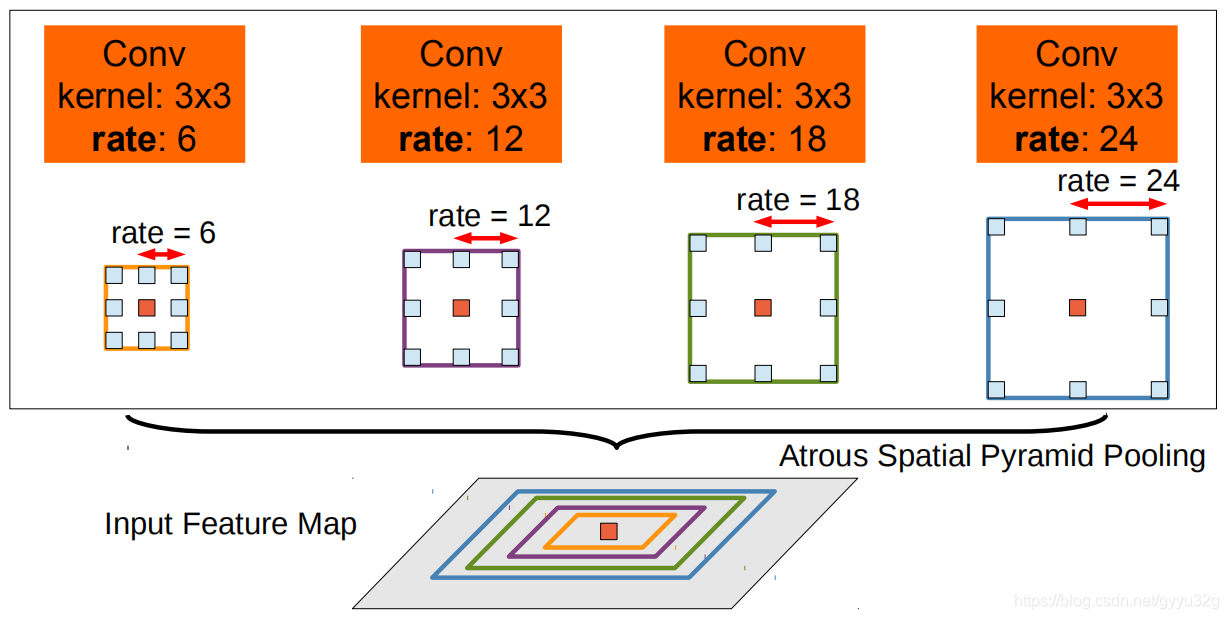
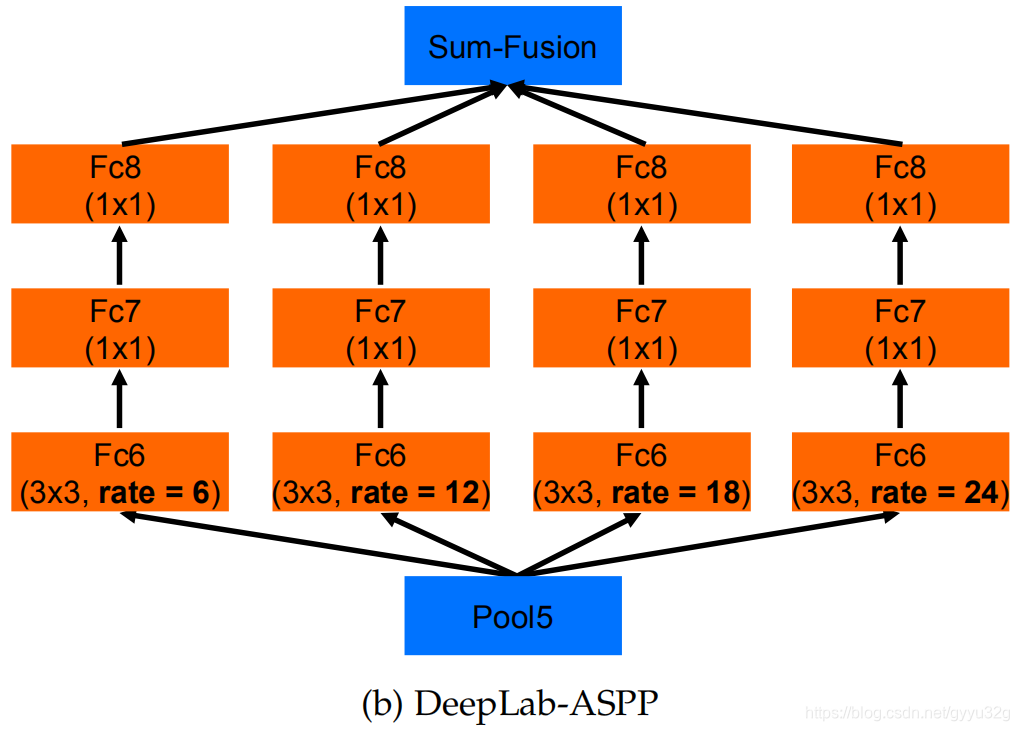
输入的特征图,分别采用空洞率为:6,12,18,24的空洞卷积核,而空洞率越大就越能体现全局特征,空洞率越小就能够保证局部的细节特征,最终进行融合能够同时获得全局特征和局部特征。如下图为DeepLab-ASPP使用多尺度空洞卷积核的部分结构图。
2.3 条件随机场(CRF)
使用CRF进行图像的后处理能够使得图像的边界更加明显,其效果如下图。
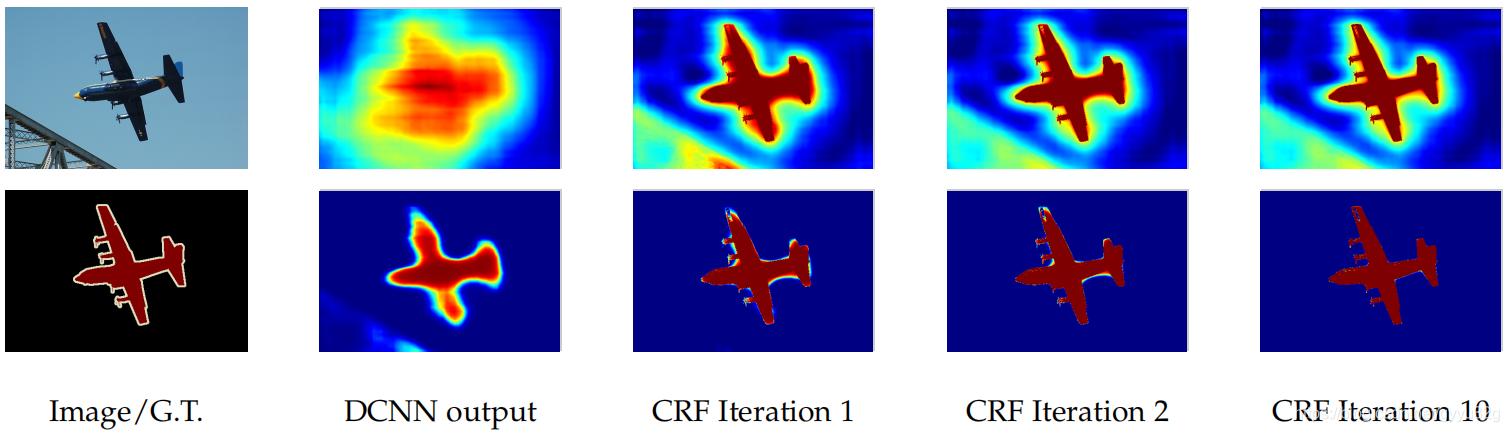
直接经过DCNN输出的特征图跟分割的label效果相比还是有一定的区别的,但是经过CRF进行后处理以后跟label更加接近。有关CRF的更详细信息可以参考这两篇博客(数学韵味很强,而且用于NLP的较多):
条件随机场(CRF)的理解
条件随机场是如何应用于图像分割?
2.4 实现过程
DeepLab在DCNN中完整的实现过程如下图:
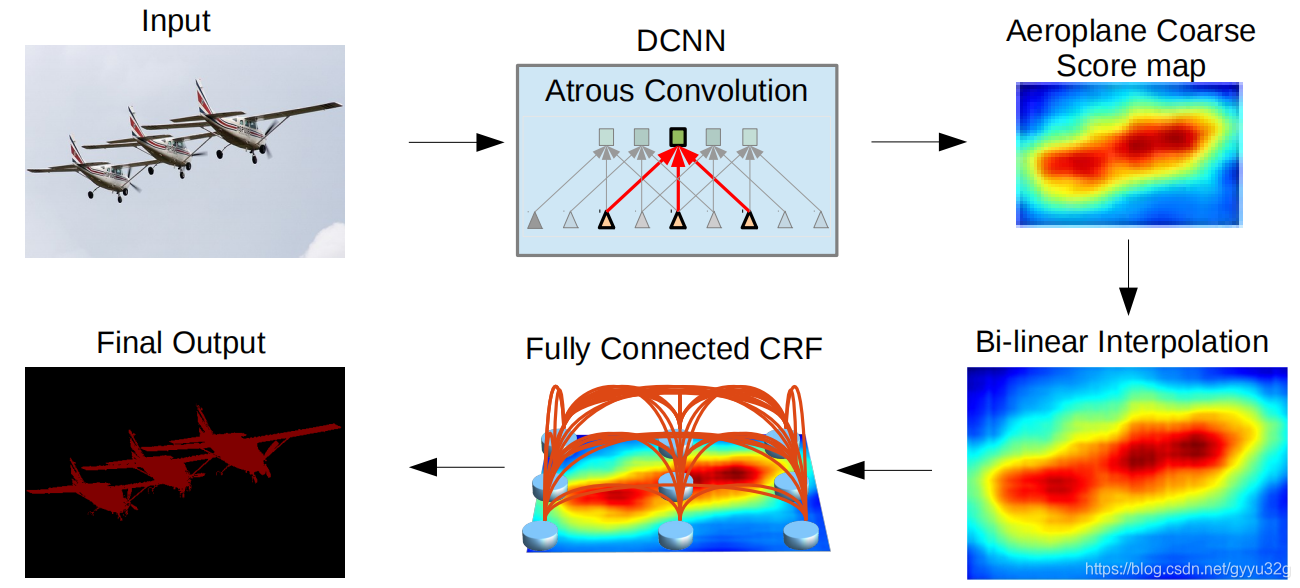
输入图像经过带空洞卷积的DCNN得到一个缩小的特征图,然后经过一个双线性插值法的上采样恢复图像尺寸大小,最后经过CRF进行图像后处理输出结果。
3 部分效果
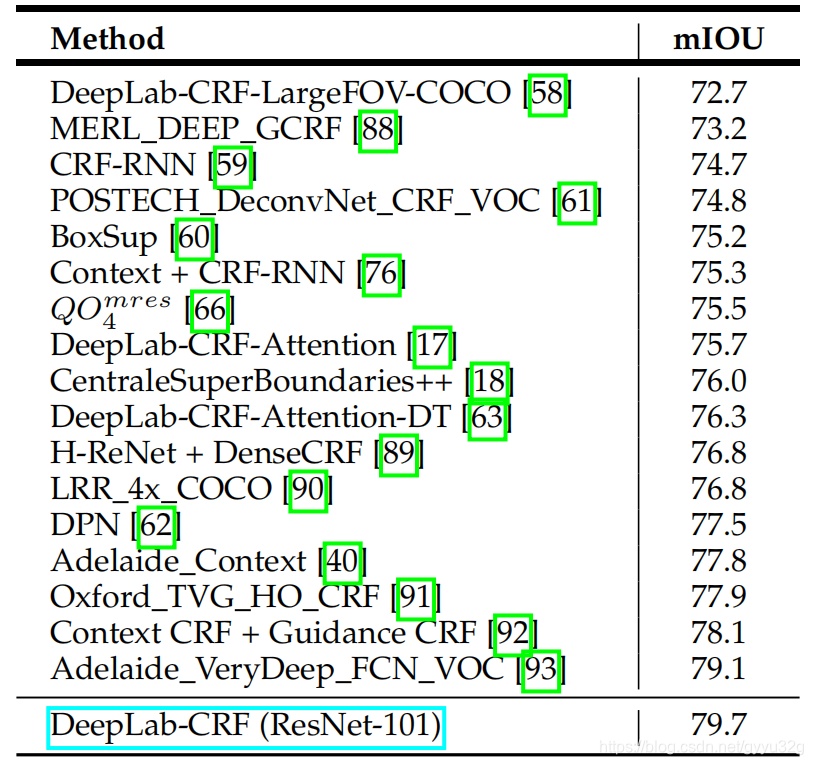
上图不同结构在PASCAL VOC 2012测试集的平均交并比的表现,可以看到ResNet-101结构+DeepLab-CRF系统得到最好的效果。
4 结论
DeepLab proposed system successfully solved the three major problems: ① characteristic graph becomes sparse problems pooled process (convolution using empty); ② multi-scale problems (use ASPP); ③ due to the presence DCNN invariance feature map positioning accuracy problem (after image processing using CRF). FCN DeepLab-CRF with the same technique is a method to be applied to the configuration VGG16, ResNet-101 and the like.
5 References
(. 1) DeepLab: Image Segmentation with Deep Convolutional the Semantic Nets, a Convolution Atrous, Fully Connected CRFs and
(2) void appreciated convolution
(3) multiscale understanding
(4) Conditional Random Fields (CRF) is understood
(5) Condition how random field is applied to image segmentation?
