Author: Lu Yunqiang, mainly engaged in the development of Java, Python and Golang. Love learning and using new technologies; have a very strong code cleanliness; like refactoring code, good at analyzing and solving problems. Link to the original text .
Our company has been using KubeSphere since June 2022, and it has been almost a year so far. We will briefly record the accumulated experience in this process for your reference.
background
The company currently has a scale of nearly 3,000 people, and its main business is the development of software and hardware related to automobiles. Among them, about 800 people specialize in software development, of which Java development accounts for about 70%, and the rest are C/C++ embedded and C# Development of desktop programs.
In the Java development part, about 80% are Java EE development. Since the company's business is mainly to provide software and hardware products and consulting services to external customers, in the early days the company and departments paid more attention to how to sell products to more customers. , Obtain more orders and pay back as soon as possible, and did not pay too much attention to the software development process, so the software development part was not particularly standardized in the early days. Software development mainly adopts agile development or waterfall model based on projects , while software deployment and operation and maintenance still adopt purely manual methods.
With the expansion of the company's scale and the increase of software product lines, the above methods gradually exposed some problems:
- There is a lot of repetitive work. When the software is iterated rapidly, frequent manual compilation and deployment are required, which is time-consuming, and this process lacks log records, and subsequent audits cannot be tracked;
- Lack of review function, the operation of the test environment and production environment requires an approval process, which could not be connected through email and enterprise WeChat before;
- Lack of access functions. With the expansion of the team, the quality of personnel is uneven, and the software development process and code style need to be forcibly solidified;
- Lack of monitoring functions, subsequent monitoring schemes adopted by different teams and projects are not uniform, which is not conducive to the accumulation of knowledge;
- There are too many customized functions for different customers (logo, font, IP address, business logic, etc.), and the manual packaging method is inefficient and easy to miss and make mistakes.
In an increasingly competitive market environment, companies need to prioritize limited human resources for business iterative development , and it becomes increasingly urgent to solve the above problems.
Selection instructions
Based on the aforementioned reasons, the department plans to use an open source system on the Internet to solve the above pain points as much as possible. The following considerations should be taken when selecting technology:
- Use as few systems as possible, preferably one system that can solve all the aforementioned problems, and avoid the cost of maintenance and integration of multiple systems;
- Adopt the open source version to avoid manual development within the company and save manpower;
- The installation process is simple, does not require complicated operations, and can support offline installation;
- The documentation is rich, the community is active, and there are many users, so it is easier to find answers to problems;
- Supporting containerized deployment, more and more companies and departments are related to autonomous driving and cloud simulation, which puts forward higher requirements for computing power and resources.
We first adopted Jenkins , which can basically solve 90% of our problems, but there are still the following problems that affect the user experience:
- The support for cloud native is not very good, which is not conducive to the department's subsequent business use related to cloud simulation;
- The UI interface is simple and the interaction method is not friendly (project build log output, etc.);
- For projects, the authority allocation and isolation of resources is too simple and does not meet the fine-grained distinction requirements for multi-project and multi-department use.
After searching on the Internet, I found that there are many similar tools. After preliminary comparison and screening, I prefer KubeSphere and Zadig. Their basic functions are similar. Further comparison is as follows:
| KubeSphere | Zadig | |
|---|---|---|
| Cloud native support | high | generally |
| UI aesthetics | high | generally |
| GitHub Star | 12.4k | 2k |
| Community activity | high | generally |
After comparison, KubeSphere is more in line with our needs, especially the UI interface of KubeSphere is very beautiful, so KubeSphere was finally selected as the continuous integration and containerization management system within the department!
So far, the department has experienced 手工操作-> Jenkins-> KubeSpherethese three stages, and the main usage points of each stage are as follows:
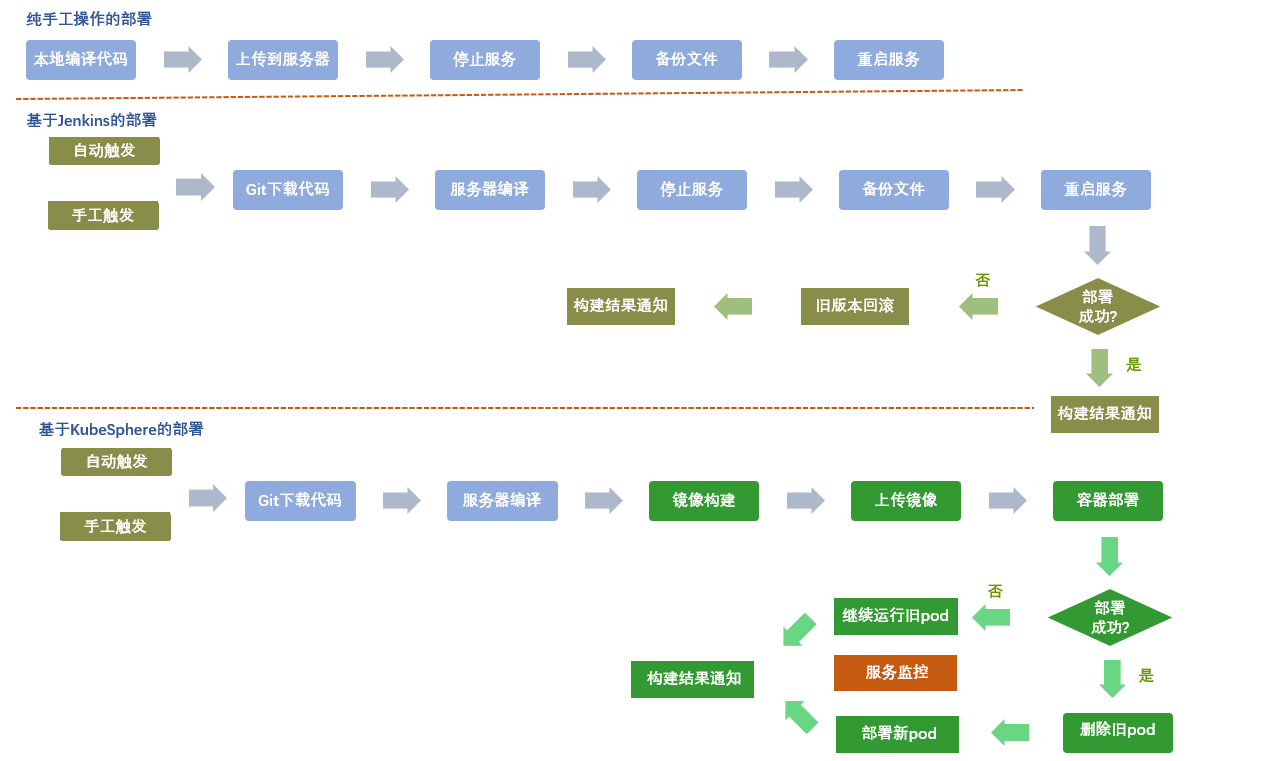
practice process
The overall deployment architecture of KubeSphere within the company is shown in the figure below. As the topmost application, it directly interacts with users, providing active/scheduled trigger builds, application monitoring and other functions. Users do not need to care about the underlying Jenkins, Kubernetes and other dependent components , only need to interact with Gitlab and KubeSphere.
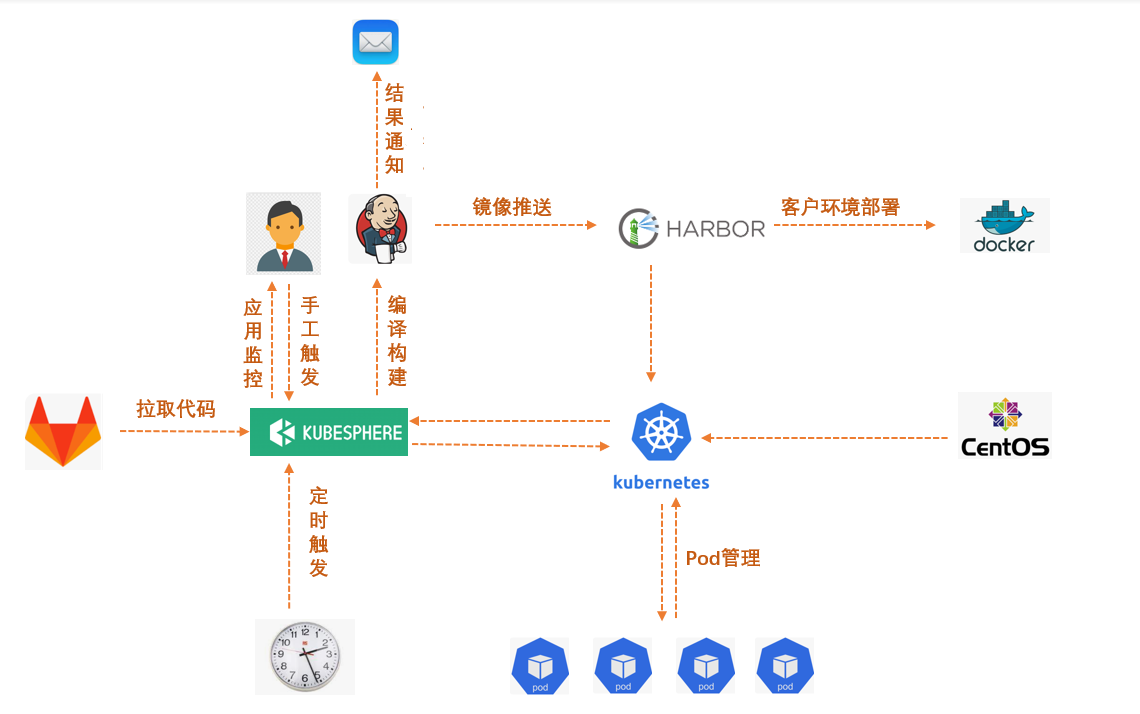
continuous integration
initial implementation
In the initial trial stage, only 4 sets of environments were planned: dev(development environment), sit(debug environment), test(test environment), prod(production environment).
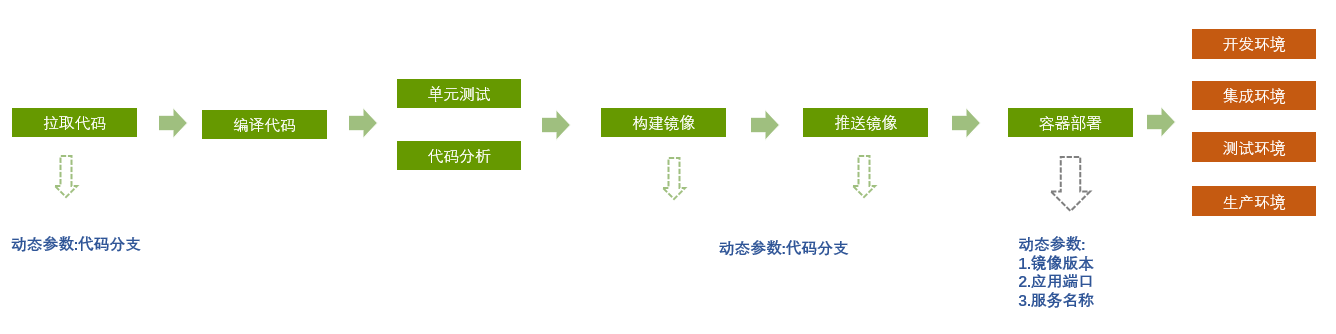
For the sake of simplifying use and maintenance, it is planned to maintain only one pipeline for each engineering module, and realize customized packaging and deployment by selecting different environment parameters during construction.
KubeSphere and Kubernetes are currently installed in the form of a stand-alone version in the department, so the distinction between different environments is mainly achieved by assigning different ports. The specific implementation needs to be able to dynamically obtain the corresponding ports in the yaml files of Jenkins and Kubernetes Parameters and project names, the reference implementation code is as follows:
Dynamically allocate relevant ports according to the selected environment in
Groovythescriptswitch(PRODUCT_PHASE) { case "sit": env.NODE_PORT = 13003 env.DUBBO_PORT = 13903 break case "test": env.NODE_PORT = 14003 env.DUBBO_PORT = 14903 break case "prod": env.NODE_PORT = 15003 env.DUBBO_PORT = 15903 break }scriptread parameters inprint env.DUBBO_IPshellread parameters indocker build -f kubesphere/Dockerfile \ -t idp-data:$BUILD_TAG \ --build-arg PROJECT_VERSION=$PROJECT_VERSION \ --build-arg NODE_PORT=$NODE_PORT \ --build-arg DUBBO_PORT=$DUBBO_PORT \ --build-arg PRODUCT_PHASE=$PRODUCT_PHASE .yamlread parameters from filespec: ports: - name: http port: $NODE_PORT protocol: TCP targetPort: $NODE_PORT nodePort: $NODE_PORT - name: dubbo port: $DUBBO_PORT protocol: TCP targetPort: $DUBBO_PORT nodePort: $DUBBO_PORT selector: app: lucumt-data-$PRODUCT_PHASE sessionAffinity: None type: NodePort
The operation effect is similar to the following figure:

For details, see KubeSphere usage experience .
Environment expansion
The 4 sets of environments built based on the above methods were used smoothly at the beginning, but with the advancement of the project and the increase of developers, there are multiple functional modules that need to be developed and tested in parallel, resulting in insufficient use of the original 4 sets of environments. After some exploration, the function of dynamically configuring multiple sets of environments in KubeSphere combined with NacosJSON has been realized. By modifying the configuration files in Nacos, it can be easily expanded from 4 sets to 16 sets or even more.
Combined with the actual situation of the project and to avoid subsequent modifications to the KubeSphere pipeline, in order to achieve flexible configuration of multiple environments , the following two rules have been formulated:
- The port information is stored in the configuration file, and KubeSphere goes to the pipeline to read the relevant configuration when building
- When you need to expand the environment or modify the port, you don't need to modify the pipeline in KubeSphere, you only need to modify the corresponding port configuration file
Since Nacos is used as the configuration center and service management platform in the project, it is decided to use Nacos as the port configuration center. The implementation process is as follows:
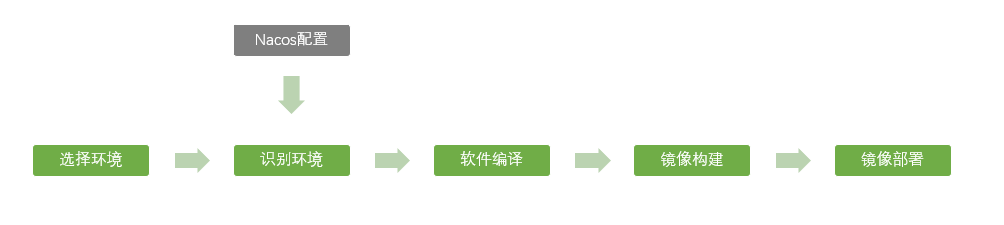
Based on the above process, the following problems are faced in the specific implementation:
- Use
Groovythe code to obtain theNacosspecific portJSONconfiguration and analyze it dynamically; - Use
Groovythe code to dynamically obtainNacosthe corresponding in according to the input input parametersnamespace; - Due to the increase of environments, it is impossible to prepare a
YAMLfile . At this time,YAMLthe file needs to be read and updated dynamically.
Since does not support parsing of , by Jenkinsdefault , the Pipeline Utility Steps plug-in needs to be pre-installed in , which provides reading and modifying operations for common file formats such as , , , and so on.JSONYAMLJenkinsJSONYAMLCSVPROPERTIES
JSONThe file design is as follows. Record the environment and port information through env, server, dubbo and other attributes, and record the specific project name through project. Since the keys in the configuration file are fixed, it will be more convenient for subsequentGroovyanalysis Just update thisJSONfile .{ "portConfig":[ { "project":"lucumt-system", "ports":[ { "env":"dev-1", "server":12001, "dubbo":12002 }, { "env":"dev-2", "server":12201, "dubbo":12202 } ] }, { "project":"lucumt-idp", "ports":[ { "env":"dev-1", "server":13001, "dubbo":13002 }, { "env":"dev-2", "server":13201, "dubbo":13202 } ] } ] }In Nacos Open Api, it is known that the request
namespaceto is/nacos/v1/console/namespaces, the request to query the configuration file is/nacos/v1/cs/configs, and the reading codeGroovybased on is as follows:response = sh(script: "curl -X GET 'http://xxx.xxx.xxx.xxx:8848/nacos/v1/console/namespaces'", returnStdout: true) jsonData = readJSON text: response namespaces = jsonData.data for(nm in namespaces){ if(BUILD_TYPE==nm.namespaceShowName){ NACOS_NAMESPACE = nm.namespace } } response = sh(script: "curl -X GET 'http://xxx.xxx.xxx.xxx:8848/nacos/v1/cs/configs?dataId=idp-custom-config.json&group=idp-custom-config&tenant=0f894ca6-4231-43dd-b9f3-960c02ad20fa'", returnStdout: true) jsonData = readJSON text: response configs = jsonData.portConfig for(config in configs){ project = config.project if(project!=PROJECT_NAME){ continue } ports = config.ports for(port in ports){ if(port.env!=BUILD_TYPE){ continue } env.NODE_PORT = port.server } }dynamic update
yamlfileyamlFile = 'src/main/resources/bootstrap-dev.yml' yamlData = readYaml file: yamlFile yamlData.spring.cloud.nacos.discovery.group = BUILD_TYPE yamlData.spring.cloud.nacos.discovery.namespace = NACOS_NAMESPACE yamlData.spring.cloud.nacos.config.namespace = NACOS_NAMESPACE sh "rm $yamlFile" writeYaml file: yamlFile, data: yamlData
For details, see Creating Multiple Development and Testing Environments Using Nacos and KubeSphere .
extensions
The review function is added when the project is built,
testandprodthe environment must be reviewed by relevant people before the subsequent construction process can be carried out to avoid damaging the stability of the relevant version.
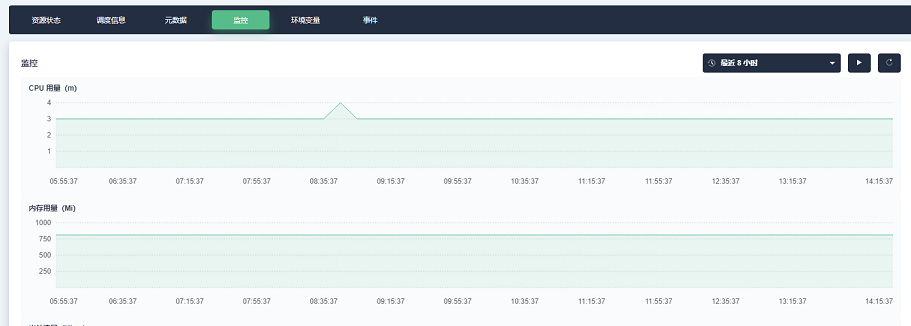
On the container group page of KubeSphere, you can view the CPU and memory consumption of the pod node, which can initially satisfy the troubleshooting of potential performance problems of the code.
Send email notifications to relevant people when the project build is complete.

External department
The software within the department will eventually be sold and delivered to the relevant customers. Due to the requirements of the customer's network being disconnected from the company's network and code confidentiality, it is impossible to use the original Jenkins pipeline for deployment and delivery at the customer's site. Based on this department, a compromise solution is adopted: compile and package through KubeSphere within the company, export the Docker image, copy it to the customer, and then deploy and run it based on the Docker image . For details, please refer to the following link:
- Checkout code from different warehouses according to configuration in Jenkins
- Using shell scripts to automatically deploy microservice programs in the form of docker containers

use assistance
In the process of using it, we have indeed encountered many problems, which are mainly solved through the following three ways:
- Read the official documentation and operate according to the documentation;
- If there is no document on the official website, go to the user forum to see if anyone has encountered similar problems or post directly;
- Seek help through WeChat groups.
According to the department's experience, 90% of the questions can be answered through official documents or user forums.
Effect
Some colleagues are accustomed to the original manual operation or Docker-based deployment, resulting in certain resistance during the promotion process. The department guides relevant colleagues to adapt slowly based on full communication and gradual replacement. After about a year of running-in, everyone has recognized the convenience brought to us by embracing cloud native and KubeSphere. Colleagues who have used it say it is very fragrant!
For our company, there are the following improvements:
- R&D personnel spend almost no time on software deployment and monitoring, saving about 20% of time, and product iteration speed is faster;
- Customized functions are implemented through scripts, which completely eliminates occasional problems caused by manual omissions when delivering software to customers, and improves the quality of software delivery while also improving the recognition of our company;
- The software development and testing process is more standardized. By adding various standard inspection and review processes to
Jenkinsthe assembly line , the standardization of software development is realized, the code quality is higher, and it is more conducive to extended maintenance. At the same time, it also reduces personnel loss due to certain procedures. /The impact of the change on the project; KubeSphereThe combination of cloud-native deployment based onNacoscan allocate multiple sets of environments more quickly, and effectively realize the isolation of开发,测试, and生产environments. In business scenarios related to cloud simulation, it can be more convenientpodto . Forward-looking business R&D is carried out more smoothly.

future plan
Combined with the actual situation of the company and the department, the short-term plan is still to improve the use of CI/CD based on Jenkins to improve the packaging and deployment process. The department is fully web-based, and based on this, it embraces cloud native in the medium and long term.
- Connect to the enterprise WeChat, and notify the relevant people of the construction and operation results at any time, so that the construction results and project monitoring are more real-time;
- Standardize and automate the construction of the department's
Eclipse RCPinternal ;Jenkins - Upgrade the bottom layer
Kubernetesfrom a single machine to a cluster, supportpodmore deployments, and support cloud simulation projects that require a large number ofpodconcurrent ; - All internal
webprojects areKubeSpherebuilt and deployed to improve their use documents and explore new application scenariosKubeSpherein the department's business (such as timing and mandatory inspection notifications for design documents, development documents, bug repairs, etc.).
This article is published by OpenWrite, a multi-post platform for blogging !