operating system
1. Communication between processes
- Unnamed pipe pipe: pipe is a half-duplex communication method, data can only flow in one direction, and can only be used between processes with kinship. Process affinity usually refers to the parent-child process relationship.
- Named pipe FIFO: The named pipe is also a half-duplex communication method, but it allows communication between unrelated processes.
- Message Queue MessageQueue: A message queue is a linked list of messages stored in the kernel and identified by a message queue identifier. The message queue overcomes the disadvantages of less signal transmission information, the pipeline can only carry unformatted byte streams, and the buffer size is limited.
- Shared storage SharedMemory: Shared memory is to map a section of memory that can be accessed by other processes. This shared memory is created by one process, but can be accessed by multiple processes. Shared memory is the fastest method of IPC, and it is specifically designed to run inefficiently when other methods of interprocess communication run. It is often used in conjunction with other communication mechanisms, such as semaphores, to achieve synchronization and communication between processes.
- Semaphore Semaphore: A semaphore is a counter that can be used to control access to shared resources by multiple processes. It is often used as a locking mechanism to prevent other processes from accessing shared resources while a process is accessing the resource. Therefore, it is mainly used as a means of synchronization between processes and between different threads in the same process.
- Socket Socket: used for communication between processes between different machines.
- Signal (sinal): A signal is a more complex communication method used to notify the receiving process that an event has occurred.
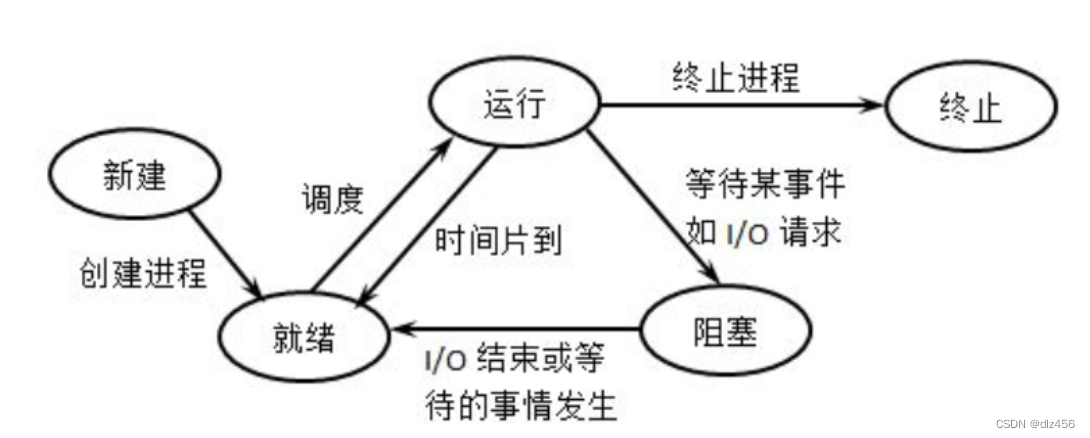
2. What are the states of the process?
Created state, ready state, running state, blocked state, terminated state.
3. Transition between process states
4. What are the page replacement algorithms?
First in, first out, best replacement, least recently used, clock replacement.
-
Optimal Replacement Algorithm (OPT, Optimal)
Algorithm Thought: The page selected for elimination each time will be the page that will never be used in the future, or will not be accessed for the longest time, so as to ensure the lowest page fault rate.
The optimal replacement algorithm can guarantee the lowest page fault rate, but in fact, only during the execution of the process can we know which page will be accessed next. The operating system cannot predict the access sequence of pages in advance. Therefore, an optimal permutation algorithm cannot be implemented. -
The first-in-first-out replacement algorithm (FIFO)
algorithm idea: the page that is selected and eliminated each time is the first page that enters the memory.
When the number of physical blocks allocated for a process increases, the abnormal phenomenon that the number of page faults does not decrease but increases is called Belay anomaly.
Only FIFO algorithms generate Belay exceptions. In addition, although the FIFO algorithm is simple to implement, the algorithm does not adapt to the rules of the actual running of the process. Because the pages that enter first are also likely to be visited most often. Therefore, the algorithm performance is poor. -
The least recently used replacement algorithm (LRU, Least Recently Used)
algorithm idea: the page eliminated each time is the page that has not been used for the longest time recently.
Implementation method: in the page table entry corresponding to each page, use the access field to record the time t that has elapsed since the page was last accessed. When a page needs to be eliminated, select the page with the largest t among the existing pages, that is, the page that has not been used the most recently. -
Clock replacement algorithm
Simple CLOCK algorithm algorithm idea: set an access bit for each page, and then link the pages in the memory into a circular queue through the link pointer. When a page is accessed, its access position is 1. When a page needs to be eliminated, only the access bit of the page needs to be checked. If it is 0, select the page to be swapped out; if it is 1, do not swap out for now, change the access bit to 0, and continue to check the next page, if all pages in the first round of scanning are 1, then these pages After the access bit is set to 0 once, the second round of scanning is performed (in the second round of scanning, there must be a page with an access bit of 0, so the simple CLOCK algorithm selects an eliminated page and will go through at most two rounds of scanning).** Simple clock replacement algorithms only take into account whether a page has been accessed recently. In fact, if the retired page has not been modified, there is no need to perform I/O operations to write back to external storage. Only when the obsolete page is modified, it needs to be written back to the external storage**
Therefore, in addition to considering whether a page has been accessed recently, the operating system also needs to consider whether the page has been modified.
The algorithm idea of the improved clock replacement algorithm : when other conditions are the same, pages that have not been modified should be eliminated first, so as to avoid I/O operations.

5. The concept of deadlock and the necessary conditions for deadlock, deadlock prevention, deadlock avoidance
Deadlock refers to the phenomenon that two or more processes wait for each other due to competition for resources during execution. Without external force, they cannot advance.
Four necessary conditions for deadlock:
1. Mutual exclusion conditions
A resource can only be used by one process at a time, that is, a resource can only be used by one process within a period of time. At this time, if other processes request the resource, the requesting process can only wait.
2. Request and holding conditions
At least one resource has been held in the process, but a new resource request is made, and the resource is already occupied by other processes. At this time, the requesting process is blocked, but it does not let go of the resources it has obtained.
3. Non-alienable conditions
Unused resources of a process cannot be forcibly taken away by other processes before they are used up, that is, they can only be released by the process that obtained the resource.
4. Circular waiting conditions
A number of processes form a relationship of end-to-end cyclic waiting for resources. When a deadlock occurs, there must be a process waiting queue {P1, P2, ..., Pn}, where P1 waits for the resources occupied by P2, P2 waits for the resources occupied by P3, ..., Pn waits for the resources occupied by P1, forming a process waiting loop In the loop, the resources occupied by each process in the loop are simultaneously requested by the other.
Note : These four conditions are the necessary conditions for deadlock, as long as the system has a deadlock, these conditions must be true. As long as one of the above conditions is not satisfied, deadlock will not occur.
Deadlock avoidance
Basic idea: The system dynamically checks each resource request issued by the process that the system can satisfy, and decides whether to allocate resources according to the check results. If the system may deadlock after allocation, it will not be allocated, otherwise it will be allocated. This is a dynamic strategy. A typical deadlock avoidance algorithm is the banker's algorithm.
6. Functions of the operating system
The basic functions of the operating system are: 1. Process management. 2. Storage management, which can be divided into storage allocation, storage sharing, storage protection, and storage expansion. 3. Equipment management, which can be divided into equipment allocation, equipment transmission control, and equipment independence. 4. File management. 5. Job management, responsible for processing any requests submitted by users.
7. The four characteristics of the operating system, the most basic characteristics of the operating system
Concurrent, shared, virtual, asynchronous.


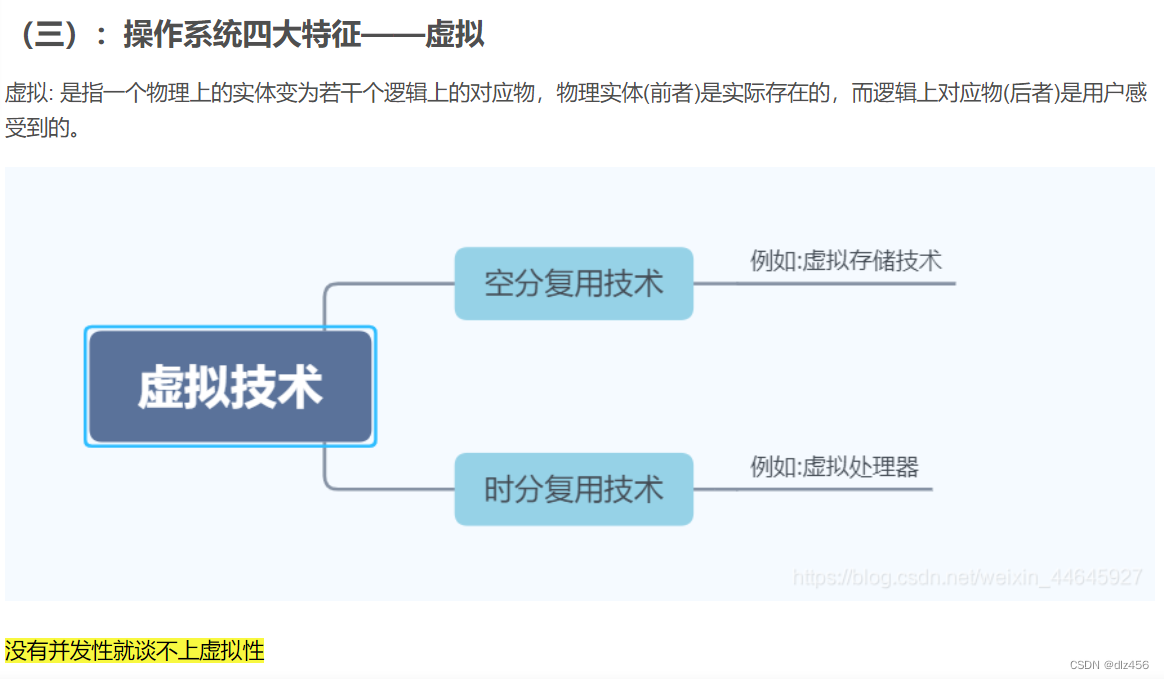

The most basic features are concurrency and sharing.
8. Interrupts and system calls
Interrupts, also called hard interrupts, refer to events other than instructions executed by the CPU. A system call is a type of soft interrupt. System calls refer to a set of special interfaces provided by the operating system to user programs, and user programs can obtain services from the operating system kernel based on this set of interfaces.
9. The difference between hard interrupts and soft interrupts
Hard interrupts: Hard interrupts are generated by hardware, such as disks, network cards, etc. A soft interrupt is a software interrupt that a process generates.
The occurrence time of the soft interrupt is controlled by the program, and the occurrence time of the hard interrupt is random. Soft interrupts are caused by program calls, and hard interrupts occur at random times. Hard interrupts can be masked, but soft interrupts cannot. The interrupt signal of the hard interrupt is controlled by the interrupt controller, and the interrupt signal of the soft interrupt is directly pointed out by the instruction.
10. Process thread difference
Process:
It is the basic unit for allocating and managing resources during the execution of concurrently executed programs. It is a dynamic concept and the basic unit for competing for computer system resources.
Thread:
is an execution unit of a process. A basic unit of independent operation that is smaller than a process. Threads are also known as lightweight processes.
The difference between processes and threads
Address space:
Threads share the address space of the process, while processes have independent address spaces.
Resources:
Threads share the resources of the process, such as memory, I/O, cpu, etc., which is not conducive to the management and protection of resources, but the resources between processes are independent, which can be well managed and protected.
Robustness:
Multi-process is stronger than multi-thread. After a process crashes, it will not affect other processes in protected mode, but if a thread crashes, the whole process will die.
Execution process:
Each independent process has a program running entry, sequential execution sequence and program entry, and the execution overhead is high.
However, threads cannot be executed independently, and must depend on the application program. The application program provides multiple thread execution control, and the execution overhead is small.
Concurrency:
Both can be executed concurrently.
When switching:
When the process is switched, it consumes a lot of resources and has high efficiency. So when it comes to frequent switching, it is better to use threads than processes. Similarly, if concurrent operations that are required to be performed at the same time and share certain variables, only threads cannot be used.
Others:
Thread is the basic unit of processor scheduling, but process is not.
11. Which resources are shared by threads and which resources are not shared
The shared resources are:
heap. Since the heap is opened up in the process space, it is naturally shared; therefore, all new ones are shared (the 16-bit platform is divided into global heap and local heap, and the local heap is exclusive)
global variables. It is not related to a specific function, so it has nothing to do with a specific thread; therefore it is also shared
static variable. Although for a local variable, it is "placed" in a certain function in the code, but its storage location is the same as that of a global variable. The .bss and .data segments opened up in the heap are shared.
Public resources such as files. This is shared, and threads using these common resources must be synchronized. Win32 provides several ways to synchronize resources, including signals, critical sections, events, and mutexes.
Exclusive resources include:
stack. The stack is an exclusive
register. This may be misunderstood, because the registers of the computer are physical, isn't it different for each thread to get the value? In fact, what is stored in the thread is a copy, including the program counter PC
12. How to prevent deadlock?
Prevention of deadlock
We can prevent deadlock by destroying the four necessary conditions for deadlock, because mutual exclusion of resources is an inherent characteristic that cannot be changed.
1. Destroy the "request and hold" condition
Method 1: Static allocation, each process applies for all the resources it needs when it starts executing.
Method 2: Dynamic allocation, each process does not occupy system resources when applying for the required resources.
2. Breaking the "non-alienable" condition.
A process cannot obtain all the resources it needs and is in a waiting state. During the waiting period, the resources it occupies will be implicitly released and re-added to the system's resource list, which can be used by other processes. The waiting process can only be restarted and executed if it regains its original resources and newly applied resources.
3. Destroy the "circular waiting" condition
and adopt the basic idea of orderly allocation of resources. Number the resources in the system sequentially
13. Brief description of banker's algorithm
The banker's algorithm is one of the most representative algorithms for avoiding deadlocks. In the deadlock avoidance method, the process is allowed to dynamically apply for resources, but before the system allocates resources, it should first calculate the security of the allocated resources. If the allocation will not cause the system to enter an unsafe state, then allocate, otherwise wait.
14. Introduce several common process scheduling algorithms
First come first served (FCFS, first come first served)
Among all scheduling algorithms, the simplest is the non-preemptive FCFS algorithm.
Algorithm principle: Processes use the CPU in the order in which they request the CPU. Just like you buy things and queue up, whoever is first in the queue will be executed first. During its execution, it will not be interrupted. When other people also want to enter the memory to be executed, they have to wait in line. If something happens during the execution, he doesn't want to queue up now, and the next one in line will fill it up. At this time, if he wanted to line up again, he could only stand at the end of the line.
Advantages of the algorithm: easy to understand and simple to implement, only one queue (FIFO) is required, and quite fair
Algorithm disadvantages: it is more conducive to long processes, not conducive to short processes, conducive to processes with busy CPU, not conducive to those with busy I/O process
Shortest Job First (SJF, Shortest Job First)
Shortest Job First (SJF, Shortest Job First) is also known as "short process priority" SPN (Shortest Process Next); this is an improvement to the FCFS algorithm, and its goal is to reduce the average turnaround time .
Algorithm principle: Prioritize the allocation of processors to processes with short expected execution times. Usually later short processes do not preempt the executing process.
Algorithm advantages: Compared with the FCFS algorithm, this algorithm can improve the average turnaround time and average weighted turnaround time, shorten the waiting time of the process, and improve the throughput of the system.
Disadvantages of the algorithm: It is very unfavorable to long processes, which may not be executed for a long time, and the priority of execution cannot be divided according to the urgency of the process, and it is difficult to accurately estimate the execution time of the process, thus affecting the scheduling performance.
The highest response ratio priority method (HRRN, Highest Response Ratio Next)
The highest response ratio priority method (HRRN, Highest Response Ratio Next) is a comprehensive balance of the FCFS method and the SJF method. The FCFS method only considers the waiting time of each job without considering the length of the execution time, while the SJF method only considers the execution time without considering the length of the waiting time. Therefore, these two scheduling algorithms will bring some inconvenience in some extreme cases. The HRN scheduling strategy considers the waiting time of each job and the estimated execution time of each job, and selects the job with the highest response ratio for execution. In this way, even if it is a long job, as its waiting time increases, the W/T will also increase, and it will have a chance to be scheduled for execution. This algorithm is a compromise between FCFS and SJF.
Algorithm principle: The response ratio R is defined as follows: R = (W+T)/T = 1+W/T
where T is the estimated execution time of the job, and W is the waiting time of the job in the standby queue. Whenever job scheduling is to be performed, the system calculates the response ratio of each job, and selects the one with the largest R and puts it into execution.
Advantages of the algorithm: Since long jobs also have the opportunity to be put into operation, the number of jobs processed at the same time is obviously less than that of the SJF method, so the throughput of the HRRN method will be smaller than that of the SJF method.
Disadvantages of the algorithm: Since the response ratio needs to be calculated before each scheduling, the system overhead will also increase accordingly.
Time slice round-robin algorithm (RR, Round-Robin)
This algorithm adopts deprivation strategy. Time slice round-robin scheduling is the oldest, simplest, fairest and most widely used algorithm, also known as RR scheduling. Each process is assigned a period of time, called its time slice, which is the amount of time the process is allowed to run.
Algorithm principle: Let the ready process use the CPU scheduling method in turn according to the time slice in the FCFS mode, that is, all the ready processes in the system are arranged in a queue according to the FCFS principle, and the CPU is assigned to the queue head process each time when scheduling, so that it Execute a time slice, and the length of the time slice ranges from a few ms to hundreds of ms. At the end of a time slice, a clock interrupt occurs, and the scheduler suspends the execution of the current process accordingly, sends it to the end of the ready queue, and executes the current head process through context switching. The process can not use up a time slice. Just sell the CPU (such as blocking).
Algorithm advantages: The time slice round-robin scheduling algorithm is characterized by simplicity and short average response time.
Disadvantages of the algorithm: it is not conducive to processing urgent jobs. In the time slice rotation algorithm, the size of the time slice has a great impact on the system performance, so the size of the time slice should be selected appropriately. How to
determine the size of the time slice:
Determination of time slice size
1. System requirements for response time
2. Number of processes in the ready queue
3. System processing capacity
Multilevel feedback queue (Multilevel Feedback Queue)
multilevel feedback queue scheduling algorithm is a CPU processor scheduling algorithm, which is adopted by the UNIX operating system.
Multi-level feedback queue scheduling algorithm description:
1. When a process enters the queue to be scheduled and waits, it first enters the Q1 with the highest priority to wait.
2. The processes in the queue with high priority are scheduled first. If there is no scheduled process in the high-priority queue, the process in the sub-priority queue is scheduled. For example: Q1, Q2, and Q3 are three queues. Q2 is only scheduled when there is no process waiting in Q1. Similarly, Q3 is only scheduled when Q1 and Q2 are empty.
3. For each process in the same queue, it is scheduled according to the time slice rotation method. For example, if the time slice of the Q1 queue is N, then if the job in Q1 has not been completed after N time slices, it will enter the Q2 queue and wait. If the job cannot be completed after the Q2 time slice is used up, it will continue to the next level queue until complete.
4. When the process in the low-priority queue is running, there is a newly arrived job, then after running this time slice, the CPU is immediately allocated to the newly arrived job (preemptive).
In the multi-level feedback queue scheduling algorithm, if the time slice of the first queue is slightly larger than the processing time required by most human-computer interactions, it can better meet the needs of various types of users.
15. The role and benefits of paging, and what is the difference between segmentation
Segmentation and paging are actually a way of dividing or mapping addresses. The difference between the two mainly has the following points:
1) A page is a physical unit of information, and paging is to achieve discrete allocation, to reduce the external fraction of memory and improve memory utilization; in other words, paging is only due to the needs of system management, not the needs of users (also for user transparent) . A segment is a logical unit of information, which contains a set of relatively complete information (such as data segments, code segments, and stack segments, etc.). The purpose of segmentation is to better meet the needs of users (users can also use it) .
2) The size of the page is fixed and determined by the system. The logical address is divided into two parts, the page number and the address in the page, which is realized by the machine hardware, so a system can only have pages of one size. The length of the segment is not fixed, it depends on the program written by the user, and is usually divided by the editor program according to the nature of the information when editing the source program.
3) The paging operation address space is one-dimensional , that is, a single linear space, and the programmer only needs to use a mnemonic (hexadecimal representation of a linear address) to represent an address. The segmented operating address space is two-dimensional . When marking an address, the programmer needs to give the segment name (such as data segment, code segment, and stack segment, etc.) and the address within the segment.
16. Classification of threads
Kernel-level threads, user-level threads
17. Interrupts and exceptions

18. Interrupt processing flow
Interrupt request, interrupt arbitration, interrupt response, interrupt service, interrupt return.
Interrupt request: Internal interrupt does not require an interrupt request, and an external interrupt request is made by the interrupt source.
Interrupt arbitration: Both hardware and software can be implemented.
Interrupt response: The CPU sends an interrupt response signal to the interrupt source, and at the same time protects the hardware site; closes the interrupt; protects the breakpoint; obtains the entry address of the interrupt service program.
Interrupt service: The general structure of the interrupt service program: protect the scene; open interrupt; interrupt service; restore the scene; interrupt return.
Interrupt return: the reverse process of interrupt response.
19. The difference between a process and a program, contact
the difference:
1. The process is dynamic, while the program is static;
2. A process has a certain life span, and a program is a collection of instructions, which itself has no meaning of "movement". A program that does not create a process cannot be recognized by the operating system as an independent unit.
3. A program can correspond to multiple processes, but a process can only correspond to one program.
4. The composition of the process and the program is different. From a static point of view, a process consists of three parts: program, data, and process control block (PCB), and a program is an ordered set of instructions.
connect:
A process is an operation of a program in a computer on a certain data set. It is the basic unit for system resource allocation and scheduling, and the basis of the operating system structure.
20. Processor scheduling levels: high-level scheduling, middle-level scheduling, and low-level scheduling
There are three scheduling levels
Advanced Scheduling = Job Scheduling = Long-range Scheduling
Low-level Scheduling = Process Scheduling = Short-Range Scheduling
Intermediate Scheduling = Mid-Range Scheduling
Job scheduling often occurs when a job finishes running and exits the system, and a (batch) job needs to be reloaded into memory. Therefore, the cycle of job scheduling is longer, about every few minutes, so it is called long-range scheduling. Since it runs less frequently, it allows the job scheduling algorithm to spend more time.
The running frequency of process scheduling is the highest. In a time-sharing system, it usually takes 10 to 100 ms to schedule a process, so it is called short-range scheduling. In order to avoid process scheduling taking up too much CPU time, the process scheduling algorithm should not be too complicated.
The operating frequency of intermediate scheduling is basically between the above two schedulings, so it is called intermediate scheduling.
The main function of advanced scheduling is to transfer those jobs that are in the queue on the external memory into the memory according to a certain algorithm, that is to say, their scheduling objects are jobs. So advanced scheduling is also called job scheduling.
Low-level scheduling is used to decide which process in the ready queue should get the processor, and then the dispatcher performs the specific operation of assigning the processor to the process.
The main purpose of intermediate scheduling is to improve memory utilization and system throughput.
For this reason, those processes that cannot run temporarily should no longer occupy valuable memory resources, but they should be transferred to the external memory to wait, and the process state at this time is called the ready external memory state or the suspended state.
When these processes are ready to run again and the memory is a little free, the intermediate scheduling will decide to transfer those ready processes on the external storage to the memory again, and modify their status to the ready state, and hang them on the ready state. Waiting for process scheduling on the queue.
21. Critical resources, critical sections
Critical resource: A shared resource that only one process is allowed to use at a time.
Critical Section: The section of code that accesses critical resources
22. Synchronization and mutual exclusion
Mutual exclusion: refers to a resource that only allows one visitor to access it at the same time, which is unique and exclusive. But mutual exclusion cannot limit the order in which visitors access resources, that is, access is out of order.
Synchronization: refers to the sequential access of visitors to resources through other mechanisms on the basis of mutual exclusion (in most cases). In most cases, synchronization already implements mutual exclusion, and in particular all writes to resources must be mutually exclusive. In rare cases, multiple visitors can be allowed to access resources at the same time.
23. Signal amount
Semaphores are mostly used for synchronization and mutual exclusion between processes.
It allows multiple threads to access the same resource at the same time, but needs to limit the maximum number of threads that can access this resource at the same time.
The data structure of the semaphore is a value and a pointer, and the pointer points to the next process waiting for the semaphore.
The value S of the semaphore is related to the usage of the corresponding resource. When S is greater than 0, it indicates the number of currently available resources; when S is less than 0, its absolute value indicates the number of processes waiting to use the resource. Note that the value of a semaphore can only be changed by PV operations.
Executing a P operation means requesting to allocate a unit resource, so the value of S is reduced by one; when S<0, it means that there are no available resources, and the requester must wait for other processes to release such resources before it can continue to run.
Executing a V operation means releasing a unit resource, so the value of S is increased by one; if S<=0. Indicates that some processes are waiting for the resource, so a waiting process should be woken up to keep it running.
24. Monitor
A monitor is a software module consisting of a set of data and operations on the set of data defined on the set of data. These operations can initialize and change the data and synchronization processes in the monitor.
Only one process can use the monitor at a time.
25. Execution process of the program
Compile, link, load.
Compile: Compile the user's source code into several target modules by the compiler.
Linking: A set of target modules formed after compilation and required library functions are linked together by the linker to form a complete loading module.
Loading: The loader loads the load module into the memory and runs it
26. How to link the program
static linking, load-time dynamic linking, runtime dynamic linking
27. How to load the program
Absolute loading, relocatable loading, dynamic running loading
Absolute loading: the physical address where the program will reside in the memory is known at compile time, and the compiled program generates
28. Dynamic Partition Allocation Algorithm
The dynamic partition allocation algorithm is also called variable partition allocation. It is a kind of continuous allocation of memory. (Memory allocation is divided into memory continuous allocation and discontinuous allocation. Memory continuous allocation is divided into single continuous allocation, fixed partition allocation, and dynamic partition allocation.)
Including four algorithms:
First Adaptation Algorithm
Algorithm idea:
search from the low address every time, and find the first free partition that can meet the size.
How to achieve:
The free partitions are arranged in the order of increasing address.
Every time memory is allocated, the free partition chain (free partition table) is searched from the low address order
to find the first free partition whose size can meet the requirements.
After each allocation is completed, the size of the free partition is modified.
When no free partition that meets the requirements can be found, memory allocation fails.
Advantages:
Prioritize the use of low-address parts in the memory, and reserve large free areas in high-address parts, creating conditions for large memory allocations for large jobs that arrive later. Disadvantages
:
The low address part will generate a lot of fragmentation that is difficult to exploit.
Loop first-fit algorithm
is different from the first-fit algorithm:
when searching for memory space for a process, it no longer starts to search from the head of the chain every time, but starts to search from the next free partition of the free partition found last time.
If the last free partition cannot meet the requirements, it should return to the first free partition.
Implementation:
connect the free area list end to end to form a ring, and each search starts from the last stop position.
Pros:
more even distribution of free partitions in memory
Disadvantages:
Fragmentation is still not resolved
Large free areas are allocated, lack of large free partitions
Best Adaptive Algorithm
Algorithm idea:
use the smallest continuous free area first when allocating.
Realization:
Free partitions are linked in order of increasing capacity.
Each time a free partition is allocated, the free partition chain (free partition table) is searched in order
to find the first free partition that meets the size requirements.
After the free partition is allocated, the free partition link (free partition table) must be updated ), keeping the capacity increasing.
Disadvantages:
The smallest free partition is selected each time for allocation, so many, small, and difficult-to-use memory blocks will be left.
Worst Adaptation Algorithm
Algorithm idea:
use the largest continuous free area first in each allocation.
Realization:
The free partitions are linked in the order of decreasing capacity.
Each time memory is allocated, the free partitions are sequentially searched (free partition table)
to find the first free partition with a sufficient size.
After the free partition is allocated, the free partition link (free partition table) must be updated to keep the capacity decreasing.
Disadvantages:
Large continuous free partitions are used up, and there will be no partitions for future large jobs.
Advantages:
High query efficiency
29. Library functions
A way to put functions in a library for others to use.
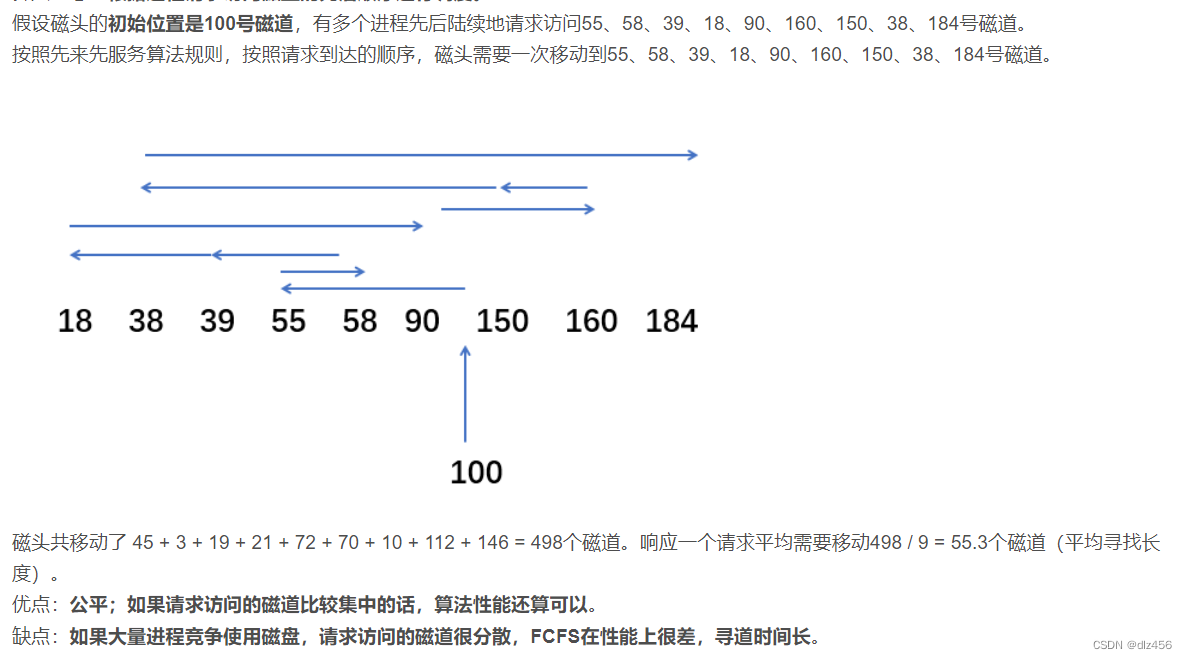
30. Disk scheduling algorithm
First-come-first-served (FCFS)
algorithm idea: Scheduling is performed according to the order in which processes request access to disks.
SSTF scheduling (shortest seek time first)
algorithm idea: the track that is processed first is the track closest to the current head. The shortest seek time can be guaranteed each time, but the shortest total seek time cannot be guaranteed. (In fact, it is the idea of a greedy algorithm, just choose the best in front of you, but the overall may not be the best).
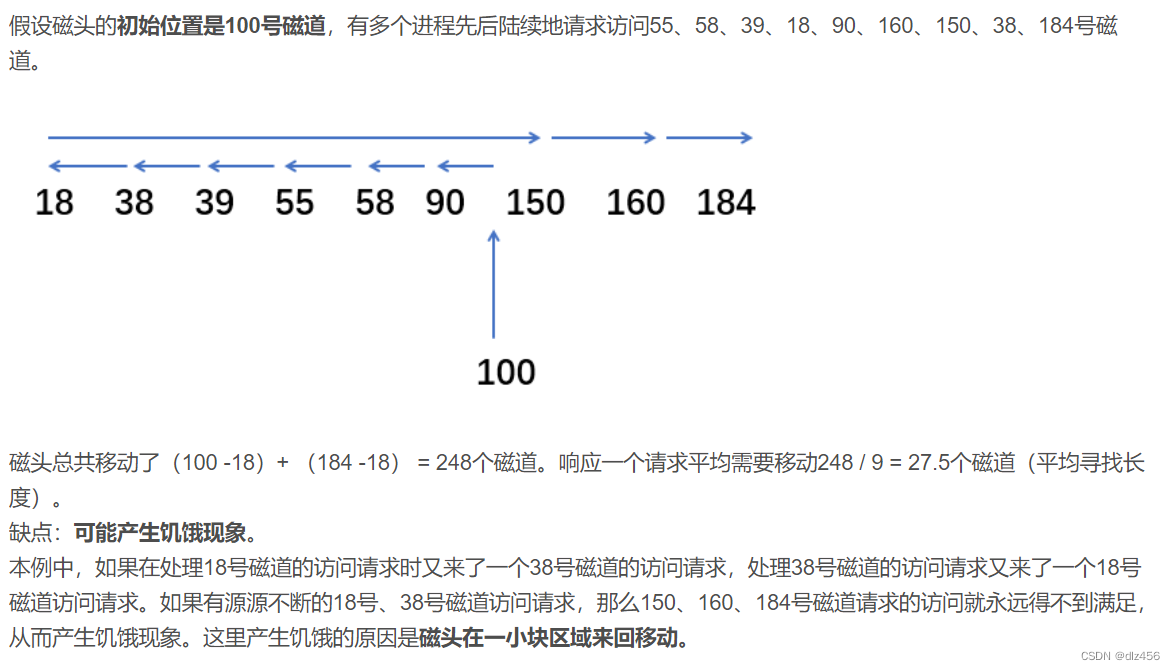
The scanning algorithm (SCAN)
sweeps to the end, and then sweeps back in turn.
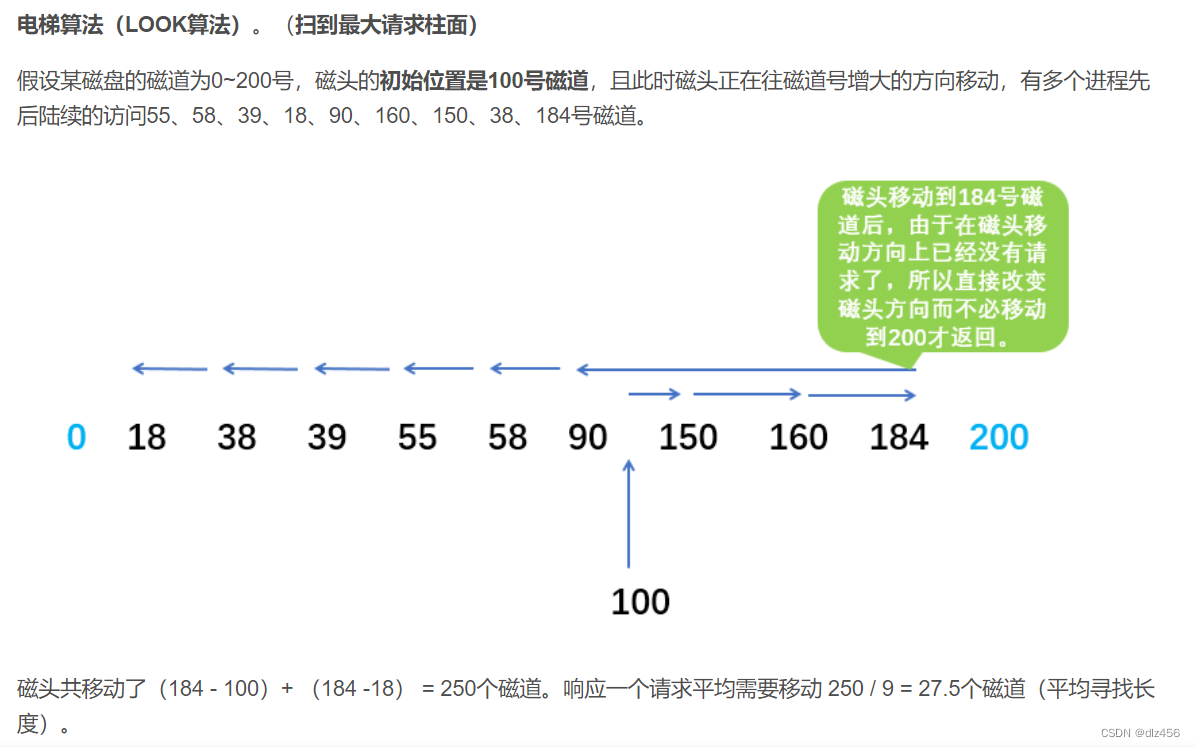
Cyclic scanning algorithm
Cyclic scanning (C-SCAN) scheduling is a variant of SCAN to provide a more uniform waiting time. Like SCAN, C-SCAN moves the head from one end of the disk to the other and handles requests along the way. However, when the head reaches the other end, it immediately returns to the beginning of the disk without processing any requests on the way back. (Sweep to the end, then quickly return to the first cylinder, and then sweep back in turn)
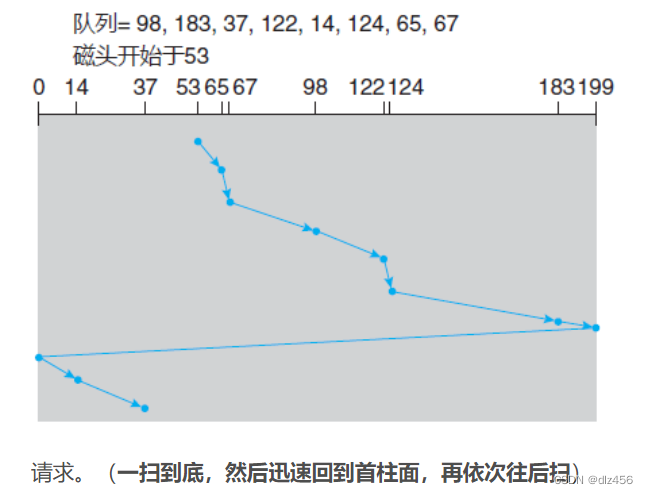
Sweep to the end, then quickly return to the first cylinder, and then sweep back in turn
31. SPOOLing technology
Multiprogramming technology virtualizes one physical CPU into multiple logical CPUs, allowing multiple users to share one host. Through SPOOLing technology, a physical IO device can be virtualized as a polymorphic logical IO device, which also allows multiple users to share a physical IO device.
SPOOLing technology is to use one of the multi-programs to simulate the function of the peripheral control machine during offline input, and transfer the data on the low-speed IO device to the high-speed disk; use another program to simulate the function of the peripheral control machine during offline output Transfer data from a disk to a low-speed output device. In this way, offline input and output functions are realized under the direct control of the host. At this time, the peripheral operation is performed simultaneously with the data processing by the CPU. This kind of simultaneous peripheral operation is called SPOOLing in the case of online.
32. IO control mode
- The program directly controls
the CPU to read the IO status repeatedly until the IO is ready. - Program interruption mode
Reduce the waiting time of the CPU under the program direct control mode and improve the parallelism of the system.
After the CPU issues a read and write command, it will block the process waiting for IO and switch to other processes for execution. When the IO is completed, the controller will send an interrupt signal to the IO. After the CPU detects the interrupt, it saves the running environment information of the current process and transfers to process the interrupt, so that the CPU and the IO device can work in parallel. - DMA mode
Direct memory access control mode
The external device sends a DMA request, and the CPU agrees to give up the control of the bus. After the DMA controller takes over the control of the bus, it starts direct data exchange between the external device and the memory. The CPU no longer acts as the center. It is suitable for Transfer of large amounts of data.
DMA request—>DMA response—>data transfer—>DMA ends. - Channel control mode
A channel is a processor that is independent of the CPU and specifically controls the input and output. It controls the memory and the device to exchange data directly.
data structure
1. The concept of red-black tree
Is a special binary search tree whose maximum depth is less than twice the minimum depth.
Jingle: The root node must be black, and the new addition is red. It can only be black and black, not red and red. When the father and uncle are red, the color will change, and the father and uncle will rotate when the red and uncle are black. Whichever side is black, turn to the other side.
Red-black trees must be stored in memory, so large files like databases cannot be used.
As for why the red-black tree is proposed?
Because the binary search tree may degenerate into a linked list, and the cost of maintaining balance in a balanced binary tree is too high.
2. KMP algorithm
Calculate the next array according to the characteristics of the pattern string to prevent backtracking of the main string pointer and improve efficiency.
Algorithm flow
Assume that the text string S is matched to position i, and the pattern string P is matched to position j.
If the current character is successfully matched (that is, S[i] == P[j]), make i++, j++, and continue to match the next character;
If the current character fails to match (that is, S[i] != P[j]), keep i unchanged, and j = next[j]. This means that when there is a mismatch, the pattern string P is moved to the right by j - next [j] bits relative to the text string S. In other words, when the match fails, the number of bits to move to the right of the pattern string is: the position of the mismatch character - the next value corresponding to the mismatch character, that is, the actual number of bits to move is: j - next[j], and this value is greater than is equal to 1.
The next array of KMP is equivalent to telling us: when a character in the pattern string does not match a character in the text string, which position the pattern string should jump to next. If the character at j in the pattern string does not match the character at i in the text string, the character at next [j] will continue to match the character at i in the text string in the next step, which is equivalent to moving the pattern string to the right by j - next[j] bit.
3. Topological sort
A linear sequence of all vertices of a DAG.
4. Huffman tree and Huffman coding
Huffman tree: A binary tree with a minimum weighted path length.
5. Determine whether the linked list has a ring
speed pointer
6. Binary Sorting Tree
Left child < root node < right child
Elements with the same value are not allowed.
Build, insert are all based on search.
There are three situations for deleting a node: 1) Deleting a leaf node, directly deleting. 2) The deleted node only has left/right subtree, so move his left/right subtree directly. 3) The deleted node has both the left subtree and the right subtree, and is replaced by the rightmost node of the left subtree and the leftmost node of the right subtree.
7. Balanced Binary Tree
In a special binary sorting tree, the absolute value of the height difference between the left and right subtrees of any node is not greater than 1.
Insertion and deletion of nodes must be judged and adjusted.
8. Conflict resolution for hash tables
Open addressing method : When we encounter a hash collision, we look for a new free hash address.
1) Linear detection method
When the position we need to store the value is occupied, we will add 1 to the back and take the modulus of m until there is a free address for us to store the value. The modulus is to ensure that the found position is in In the effective space of 0~m-1.
2) Square detection method (secondary detection)
When the position we need to store the value is occupied, it will search forward and backward instead of searching in a single direction.
Chain address method : link all records with the same hash address in the same linked list.
9. B tree (B-tree)
B-tree is a balanced multi-way search tree. There are not only left and right search paths for a node, but multiple ones.
So why use B-trees (or why do you have B-trees)? To explain this clearly, we assume that our data volume has reached the level of 100 million, which cannot be stored in the main memory at all. We can only read data from the disk in the form of blocks. Compared with the access time of the main memory, the I/O of the disk is O operation is quite time-consuming, and the main purpose of proposing B-tree is to reduce disk I/O operations. Most operations on a balanced tree (find, insert, delete, max, min, etc.) require O(n) disk access operations, where h is the height of the tree. But for the B-tree, the height of the tree will no longer be logn (where n is the number of nodes in the tree), but a height that we can control, so compared with AVL tree and red-black tree, B - The disk access time of the tree will be greatly reduced.
10. B+ tree
Nodes are divided into index nodes and leaf nodes. The node data of the B tree will not be repeated, the node data of the B+ tree will be repeated, and all data will appear again in the leaf nodes

11. B-tree and B+ tree comparison
The search for elements near the root node of the B tree will be faster. B+ tree facilitates range lookup
12. The connection and difference between divide and conquer and dynamic programming
Divide and conquer and dynamic programming
have something in common: both require the original problem to have optimal substructure properties, and both divide and conquer the original problem and decompose it into several smaller-scale (small enough to be easily solved program) sub-problems. Then The solutions to the subproblems are combined to form a solution to the original problem.
The difference:
the divide and conquer method regards the decomposed sub-problems as independent of each other, and does it by using recursion.
Dynamic programming understands the decomposed sub-problems as being related to each other, there are overlapping parts, and memory is required, which is usually done by iteration.
13. Insertion sort
Insertion sort includes direct insertion, binary insertion, and Hill sort.
Insertion sorting can be understood as the process of coded poker cards, which is easy to understand and remember. Take one card in the unordered queue and put it in the corresponding position in the already ordered queue.
Hill sorting: group the sequence according to a certain increment of the subscript, and use direct insertion sort for each group, and the increment gradually decreases until it is divided into a group.
Time complex: average O(nlogn), worst O(n2). Empty complex O(1). unstable.
Comparison of these three insertion sorts: direct insertion is stable, Hill sort is unstable. Direct insert fits the original record in basic order. Hill sort has fewer comparisons and fewer moves. Direct insertion sort is suitable for linked storage, Hill is not applicable.
14. Swap Sort
Bubbling and fast sorting.
Bubble sort average time complex: O(n2), worst: O(n2), best: O(n). Empty complex: O(1).
The bubbling is stable, but the quick discharge is unstable.
15. Selection Sort
Simple selection sort, heap sort.
16. Radix sort
Stablize
17. Merge Sort
Typical applications of divide and conquer
are O(nlogn) stable
18. Adjacency list and adjacency matrix
Adjacency list: For each vertex, create a table linking all its outgoing edges.
Adjacency matrix: It is a two-dimensional array with a size of dis[n][n], where dis[i][j] represents the distance from vertex i to vertex j.
19. Dijkstra
Used to find the single-source minimum path
20. Floyd
Can be used for edges with negative weights, but loops with negative weights are not allowed.
Dynamic programming is adopted.
In the network layer protocol, the routing protocol within the autonomous system: the Open Shortest Path Limited Protocol OSPF uses this.
21. Algorithm for minimum spanning tree
Given an undirected graph, if any two vertices in its subgraph are connected to each other and form a tree structure, then this tree is called a spanning tree. When the graph connecting vertices has weights, the tree structure with the smallest sum of weights is the minimum spanning tree!
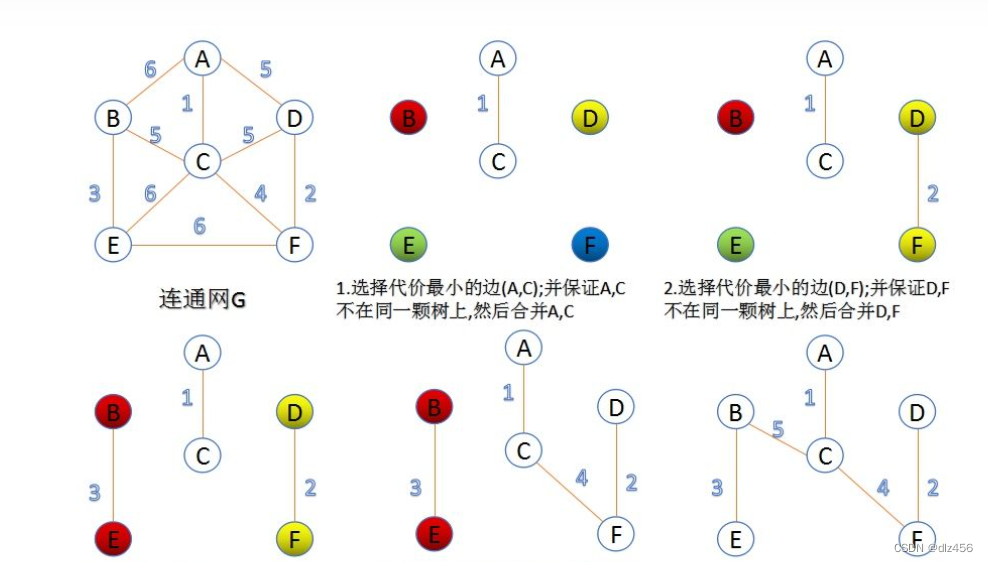
Kruskal algorithm (Kruskal algorithm)
Kruskal algorithm is a greedy algorithm. We sort each edge in the graph according to the weight, and take out the edge with the smallest weight and two vertices that are not in the same set from the edge set each time. Join the spanning tree! Note: If these two vertices are in the same set, they are already connected by other edges, so if this edge is added to the spanning tree, then a cycle will be formed! Do this repeatedly until all nodes are successfully connected!
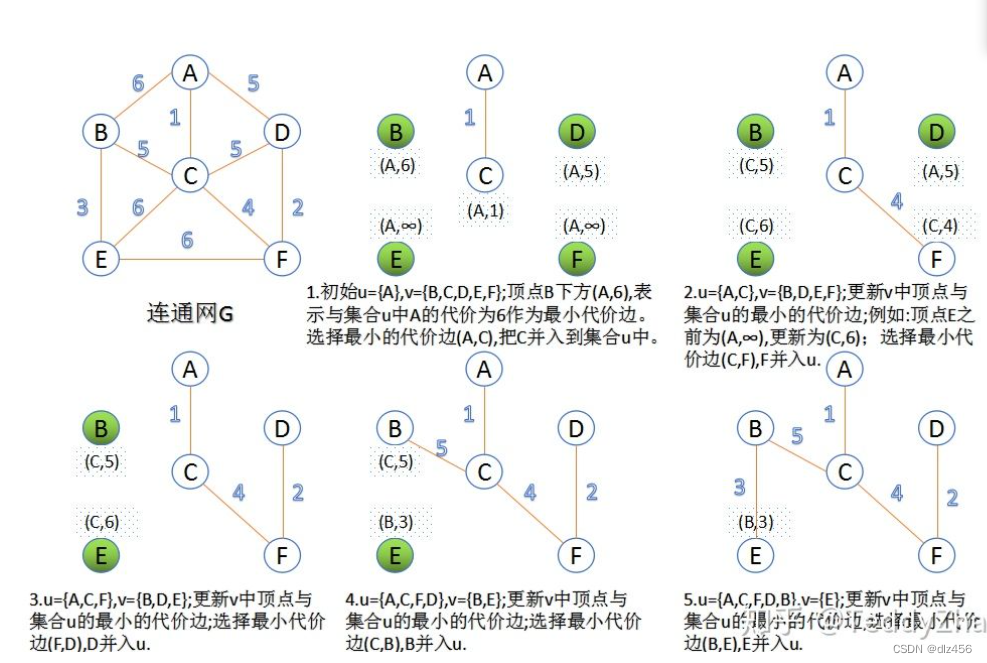
Prim algorithm (Prim algorithm)
Prim algorithm is another greedy algorithm, which is different from the greedy strategy of Kuskral algorithm. Kuskral algorithm mainly operates on edges, while Prim algorithm operates on nodes, adding a point for each traversal. At this time, we don't need to use and check. The specific steps are:
22. What does the big O of O(n) mean?
The big O of O(n) represents the time complexity in the worst case.
23. Comparison between linear storage structure and chained storage structure
24. The difference between head pointer and head node
25. Difference between stack and queue and memory structure
The stack only allows insertion and deletion at the top of the stack, not at the bottom of the stack.
The memory structure of the sequential stack: array, pointer to the top of the stack, and the maximum number of elements that can be accommodated.
The memory structure of the linked stack, the top pointer of the stack
Queue: Delete at the head of the queue and insert at the end of the queue.
Sequential storage structure: array, head pointer, tail pointer.
Chained queue: queue head pointer, queue tail pointer.
26. There is a circular queue Q, which is numbered from 0 to n-1, head pointer f, tail pointer p, find the number of elements in Q.
(p-f+n)%n
Note: The tail pointer is not pointing to the tail element, but the next position of the tail element
27. Distinguish whether the circular queue is empty or full
Two methods: one is to add an additional element to record the number of existing elements in the queue. The second is to give up the storage space at the end of the team.
28. Implementation and application of heap, big top heap and small top heap
for heap sort
29. The concept of the hash table, the construction method, and the solution to the drama conflict
The hash table is suitable for storing some data that has a certain functional relationship between keywords and storage addresses.
The construction method of the hash function: direct addressing method, the remainder method after division.
Hash conflict resolution: open addressing method, zipper method
30. How to construct a binary tree from the traversal sequence?
Inorder plus preorder can be constructed, inorder plus postorder can be constructed, inorder plus hierarchical traversal can also be
31. Introduce how depth-first and breadth-first are implemented?
Depth first: go to the end, choose a branch, and continue to go deeper.
Breadth first: Exploring layer by layer
32. Why do we need stable sorting?
Causes the result sorted on the first key to serve those elements that are equal when sorted on the second key.
33. Why do B-trees, B+ trees, and red-black trees appear in balanced binary trees?
Because the requirements of a balanced binary tree are too strict, every insertion and deletion may involve tree rotation.
34. Threaded Binary Tree
Traversing the binary tree is actually arranging the nodes in the binary tree into a linear sequence according to certain rules, and obtaining the pre-order sequence, in-order sequence or post-order sequence of the nodes in the binary tree. Each element in these linear sequences has one and only one predecessor node and successor node.
But when we want to get the predecessor or successor node of a certain node in the binary tree, the ordinary binary tree cannot be obtained directly, and can only be obtained by traversing the binary tree once . Whenever it comes to solving the predecessor or successor, the binary tree needs to be traversed once, which is very inconvenient.
Binary tree structure
Observing the structure of the binary tree, we found that the pointer field is not fully utilized , there are many "NULL", that is, there are many null pointers.
For a binary linked list with n nodes, each node has two pointer fields pointing to left and right children, a total of 2n pointer fields. And the binary tree with n nodes has n-1 branch lines (except the head node, each branch points to a node), that is, there are 2n-(n-1)=n+1 null pointer fields . These pointer fields are just wasted space. Therefore, an empty chain field can be used to store the predecessor and successor of a node . The thread binary tree uses n+1 empty chain domains to store the information of the predecessor and successor nodes of the node .
If only empty nodes are used on the basis of the original binary tree, then there is such a problem: how do we know whether the lchild of a certain node points to its left child or to the predecessor node ? Does rchild point to the right child or the successor node? Obviously we need to add signs to his pointing to distinguish.
35. Euler circuit
A cycle containing all edges on the graph.
computer network
1. Functions between the various layers of the OSI and TCP/IP models
OSI: physical layer, data link layer, network layer, transport layer, session layer, presentation layer, application layer.
TCP/IP: Network Interface Layer, Internet Layer, Transport Layer, Application Layer.
Physical layer: Consider how to transmit the bit stream on the transmission medium, and shield the differences between the transmission medium and communication means as much as possible, so that the data link layer does not feel the difference.
Data link layer: It is possible to perform error detection, but not error correction, to transmit data packets and frames that can be transmitted on different networks. Increase the ability of the physical layer to transmit raw bit streams.
Network layer: for routing and packet forwarding.
Transport layer: Provides reliable and unreliable data transmission services between application processes, and is responsible for the communication between processes between different hosts.
Session layer: establish and manage sessions.
Presentation layer: perform data compression, data encryption, and format conversion.
Application layer: Provide an interface for users to complete specific network applications through interaction between processes.
2. Why is the computer network layered? advantage
1) Each layer is independent of each other: the upper layer does not need to know that the functions of the lower layer are realized by hardware technology, it only needs to know that the required services can be obtained through the interface with the lower layer; 2) Good flexibility: each
layer All can be implemented with the most appropriate technology. For example, the implementation technology of a certain layer has changed, and the software is replaced by hardware. As long as the functions and interfaces of this layer remain unchanged, the change of the implementation technology will not affect other layers. 3) Ease of implementation
and standardization: Due to the adoption of a standardized hierarchical structure to organize network functions and protocols, the complex communication process of a computer network can be divided into orderly continuous actions and orderly The interaction process helps to resolve the complex communication process of the network into a series of functional modules that can be controlled and realized, making the complex computer network system easy to design, implement and standardize
3. Briefly describe the principle of hierarchical routing
The Internet is divided into multiple autonomous systems or multiple domains. A domain is a collection of hosts and routers that use the same routing protocol.
Interior Gateway Protocol IGP: Distance Vector Routing Protocol, Link State Routing Protocol
Exterior Gateway Protocol EGP
4. Three elements of network protocol
Syntax, Semantics, Timing.
Syntax: Used to specify the format of the message.
Semantics: used to explain what the two parties should do
Timing: detail the sequence of events
5. Shannon formula
In a channel with limited bandwidth and noise, in order not to generate errors, the data transmission rate of information has an upper limit.
C=B*log(1+S/N)
C is channel capacity, unit bit per second, B is channel bandwidth, unit Hz.
Note: The unit of channel bandwidth is Hz, and the unit of network bandwidth we usually refer to is bit/s, which is the concept of rate. It is easy to understand that the channel bandwidth is related to our filter. The filter can be divided into "high pass", "low pass" and "band pass". The concept of passband here is the frequency range that can pass. Once the hardware or communication system is designed, the maximum channel bandwidth that the hardware or communication system can pass is determined.
The unit of channel capacity is bit/s, which is the same as the network bandwidth unit we mentioned above, and it is also a concept of transmission rate. Well, at this time we know that the network bandwidth we usually talk about originally refers to the transmission rate of the channel! The channel capacity is also the channel transmission rate! !
What is the difference between network bandwidth and channel capacity? In fact, the channel capacity refers to the maximum data transmission rate of the channel, and the network bandwidth refers to the actual data transmission rate of the channel.
6. Briefly describe the CSMA/CD agreement
Carrier sense, multipoint access, collision detection.
Listen first and then send, listen while sending, conflict stop sending, random resend
MA: Multiple stations are connected to a bus and compete to use the bus


7. Similarities and differences between TCP and UDP
Same point
Both TCP and UDP are at the network layer, both are transport layer protocols, both can protect the transmission of the network layer, and both parties need to open ports for communication.
difference

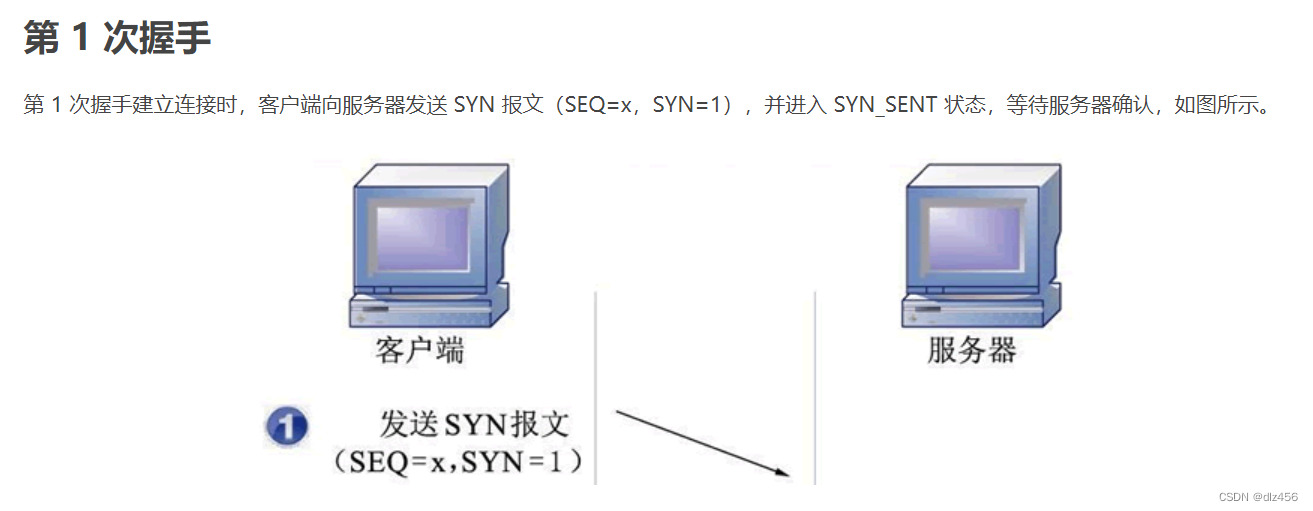
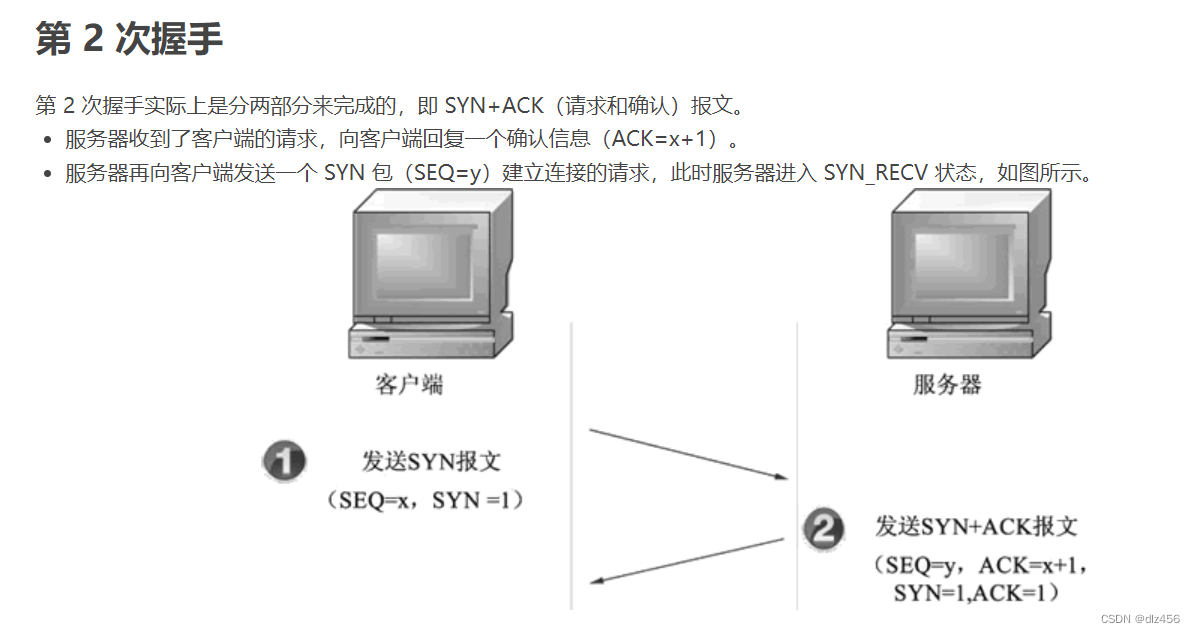
8. TCP three-way handshake to establish a connection

9. Why does TCP not use two handshakes to establish a connection, four times?
10 TCP waved four times to release the connection
11. UDP header, TCP header
UDP: source port number, destination port number, length, checksum
TCP: source port number, destination port number, serial number, confirmation number, ACK, FIN, SYN, window size...
12. How does TCP ensure reliable transmission?
13. TCP's fast retransmission mechanism.
14. What is the relationship between flow control and congestion?
1. Congestion control has a premise that the network can bear the existing network load.
2. Congestion control is a global process involving all hosts, all routers, and all factors related to reducing network transmission performance.
3. Flow control often refers to the control of point-to-point channel traffic between a given sender and receiver.
4. What flow control needs to do is to suppress the rate at which the sender sends data so that the receiver can receive it in time.
15. ARP address resolution protocol
16. What is a network card? Function
A network card is a network component that works at the link layer, and is an interface that connects computers and transmission media in a local area network.
Function: Realize the physical connection and electrical signal matching between LAN transmission media, and also involve the sending and receiving of frames, encapsulation and unpacking of frames, etc.
17. Host communication process in the network.
18. Briefly describe the process of DNS domain name resolution
19. Enter a URL in the browser, what will happen?
20. What is the difference between an IP address and a MAC address, and what are their uses?
21. The role of DHCP
Manage and assign IP addresses
Work in LAN, use UDP
22. Can the data be handed over to the network layer directly at the application layer
23. What is socket
24. Connection and difference between agreement and service
25. Common working modes of computer networks (communication methods between end systems)
C/S, P2P
26. The main equipment of the physical layer
repeater, hub
27. The way of physical layer data exchange
28. Why flow control?
29. Framing
Framing includes: frame delimitation, frame synchronization, transparent transmission
30. The way of framing
31. Error control at the data link layer
Error detection, error
correction Error detection: parity check, CRC
Error correction: Hamming code
32. Fundamentals of sliding window flow control
33. Three automatic retransmission request methods
34. Random Access Media Control Protocol
ALOHA protocol
CSMA protocol
CSMA/CD protocol
CSMA/CA protocol
35. The protocol of the data link layer in the wide area network
PPP, Advanced Data Link Control Protocol HDLC
36. Link Layer Devices
bridge, switch
37.
database
1. Affairs
Transaction is the basic unit of concurrency control. It is a sequence of operations. These operations are either executed or not executed. It is an indivisible unit of work. A transaction is a unit for maintaining consistency in a database, and data consistency can be maintained at the end of each transaction.
2. ACID (the four basic elements for the correct execution of database transactions)
Atomicity, consistency, isolation, and durability.
A, atomicity: Atomicity A
transaction must be an atomic unit of work, and the execution of the data must either be executed in full or not at all. If only a subset is executed, it may defeat the overall purpose of the transaction.
C, consistency: Consistency
** transactions change the database from one consistent state to the next. **If account A transfers money to account B, the deduction from account A and the addition of money from account B must be all or nothing, that is, the database must be in a consistent state.
I, isolation: isolation
The execution of a transaction cannot be interfered by other things. That is, the internal operation and data used by a thing are isolated from other concurrent transactions , and the concurrently executed things cannot interfere with each other.
D, durability: After the persistence
** transaction is completed, its impact on the system is permanent. **This modification will persist even in the event of a fatal system failure.
3. Index
(When the amount of data in the table is relatively large, the query operation will be very time-consuming, and indexing is an effective means to speed up the query)
An index is a structure that sorts the values of one or more columns in a database table, which helps to query quickly.
4. The benefits of database indexing
- By creating a unique index, the uniqueness of each row of data in the database table can be guaranteed.
- It can greatly speed up the retrieval of data, which is the main reason for creating indexes.
- Tables and joins between tables can be accelerated, especially in terms of achieving referential integrity of data.
- When using grouping and sorting clauses for data retrieval, it can also significantly reduce the time for grouping and sorting in queries.
- By using the index, you can use the optimization hider during the query process to improve the performance of the system.
5. The disadvantages of adding indexes
- Creating and maintaining indexes takes time
- Indexes require physical space
- When adding, deleting and modifying the data in the table, the index should also be dynamically maintained.
6. Which columns should be indexed
- On the column used as the primary key, the uniqueness of the column and the arrangement structure of the data in the organization table are enforced.
- On the columns that are often used in connections, these columns are mainly some foreign keys, which can speed up the connection.
- Create indexes on columns that often need to be searched by range, because the index is sorted and its specified range is contiguous.
- Create an index on a column that often needs to be sorted, because the index is already sorted, so that the query can use the sorting of the index to speed up the sorting query time.
- Create indexes on the columns that are often used in the where clause to speed up the judgment of conditions.
7. Which columns should not be indexed
- Columns that are rarely used or referenced in queries
- Columns with few data values, such as gender
- Columns defined as text, image, bit data types
- When the modification performance is much greater than the retrieval performance, an index should not be created, because the modification performance and retrieval performance are contradictory.
8. How to create an index
Direct creation and indirect creation (when defining a primary key constraint or a unique constraint in a table, an index is also created)
9. Basic index types
Unique and Composite Indexes
A unique index ensures that all data in the index column is unique and does not contain redundant data.
A composite index is an index created on two or more columns, which can reduce the number of indexes created in a table.
10. Abnormal situations
Lost data, read dirty data, non-repeatable read, phantom read.
Lost data: Both transactions modify a data, one modifies first and the other modifies later
high number
1. Continuous, differentiable, differentiable, and integrable relationships
One-variable function: differentiable can be derived, and differentiable can also be derived. Both are able to launch a continuation. Continuous can lead to integrable.
Multivariate functions: continuous partial derivatives can be introduced to be differentiable. Differentiable can introduce partial derivative, and can also introduce continuous. But continuous and deflectable cannot be derived from each other.
2. The difference between the three mean value theorems
Rolle's mean value theorem, Lagrange's mean value theorem, Cauchy's mean value theorem
3. Partial derivatives, directional derivatives, gradients, gradient descent
Partial derivative: For a multivariate function, one independent variable is selected to keep the other independent variables unchanged, and only the relationship between the dependent variable and the selected independent variable is examined.
Directional derivative: Multivariate functions can also find derivatives in the direction of non-coordinate axes.
Gradient: A vector composed of all partial derivatives of the function. The direction of the gradient is the direction in which the value of the function grows fastest.
Gradient descent: reduce the function value along the negative gradient direction
4. Taylor formula
A formula that uses information about a function to describe its nearby values. Use a polynomial to approximate a function.
McLaughlin's formula is a special case of Taylor's formula, that is, Taylor's formula with x0=0.
line generation
1. Vector spaces
2. The rank of the matrix
3. Eigenvalues and eigenvectors
4. Similarity Matrix
5. Positive definite matrix
Suppose A is a square matrix of order n, for any non-zero vector x, xTAx>0, then A is said to be a positive definite matrix.
6. Linear correlation and linear independence
7. Orthogonal Matrix
A matrix whose transpose is equal to its inverse.
Positive vector: If the inner product of two vectors is 0, then the two vectors are said to be orthogonal. Two vectors are orthogonal meaning they are perpendicular to each other.
probability theory
1. Classical outlines, geometric outlines
Classical concept: finite possibilities. There are a finite number of possible events, and each event is equally likely to occur.
Geometry: Infinite Possibilities
2. Conditional probability
If P(B)>0, it is said that under the condition of B happening, the probability of A happening is conditional probability, and P(A|B)=P(AB)/P(B).
3. Total probability formula
If B1, B2, Bn is a complete event group, then for any event A, there is P(A)=P(A|B1)+P(A|B2)+…+P(A|Bn)
4. Bayesian formula
Given the occurrence of event A, the probability of event Bi occurring.
P(Bi/A)=P(A|Bi)P(Bi) / P(A|B1)+P(A|B2)+...+P(A|Bn) Give an example to facilitate the memory of full probability and
Bayeux s.
For example, if I go to class today, the probability of taking the first path is a, the probability of taking the second path is b, the probability of being late by taking the first path is c, and the probability of being late by taking the second path is d. Then the total probability formula is used to find the probability that I will be late today, that is, ac+bd. The Bayesian formula is used to find, I am already late, so what is the probability that I will go the first way? That is ac/(ac+bd).
5. What is the prior probability?
Things did not happen, only based on past data statistics to analyze the possibility of things happening, that is, the prior probability.
Prior probability refers to the probability obtained based on past experience and analysis, such as the total probability formula, which often appears as the cause in the problem of "seeking effect from cause".
6. What is the posterior probability?
The event has happened and the outcome is known. Find the possibility of the factors that caused this to happen, and seek the cause from the effect, that is, the posterior probability.
The posterior probability refers to the most likely kind of event calculated based on the obtained "result" information, such as in the Bayesian formula, which is the cause in the problem of "seeking the cause of the result".
The calculation of the posterior probability is based on the prerequisite of the prior probability. If you only know the result of the event, but do not have previous statistics and prior probability, there is no way to calculate the posterior probability.
7. Common distributions of discrete random variables.
8. Distribution of Continuous Random Variables
9. Add several normal distributions, what is the distribution obtained after multiplication
Under the premise of independence, they all obey the normal distribution.
10. Mathematical expectations
The mean of a random variable (different from the sample mean), the law of large numbers states that if there are enough samples, the sample mean will be infinitely close to the mathematical expectation.
Mathematical expectation (mean) is the sum of the probability of each possible result multiplied by its result in an experiment, and it is one of the most basic mathematical characteristics.
11. Variance
Variance is a measure of the difference between the data and the expected value.
D(X) = E(X2) - E2(X)
Squared Expectation minus Expected Squared.
12. Covariance
The covariance of X, Y is equal to the average of the sum of the products of each X minus the X mean times each Y minus the Y mean. From a numerical point of view, the larger the value of the covariance, the greater the degree of the same direction of the two variables. Intuitively, covariance expresses the expectation of the overall error of two variables.
If two variables follow the same trend, that is, if one of them is greater than its expected value while the other is less than its own expected value, then the covariance between the two variables is negative.
13. Correlation coefficient
The correlation coefficient of X and Y is simply the covariance of X and Y divided by the standard deviation of X and the standard deviation of Y.
The correlation coefficient can also be regarded as a covariance: a special variance after the standardization that removes the influence of two variables. He eliminated the effect of the magnitude of change in the two variables. Rather, it simply reflects the degree of similarity between two variables per unit change.
14. When the correlation coefficient or covariance is 0, can it mean that the two distributions are irrelevant? Why?
It can only show that it is not linearly related, but not irrelevant. Because in the case of mathematical expectations, independence must not be correlated, and uncorrelated may not be independent.
15. What is the relationship between independence and mutual exclusion?
Mutually exclusive not independent Independent not mutually exclusive
16. The difference between independent and unrelated
Correlation describes whether there is a linear relationship between two variables, and independence describes whether there is a relationship between two variables . Uncorrelated means that there is no linear relationship between the two variables, but there can be other relationships, that is, they are not necessarily independent of each other. Independence means being independent from each other.
17. The law of large numbers
Answer 1:
The law of large numbers is divided into Chebyshev's law of large numbers, Schinchin's law of large numbers, and Bernoulli's law of large numbers.
The first two: When the number of trials is large enough, the sample mean approaches the mathematical expectation of a random variable.
Bernoulli's Theorem of Large Numbers: When the number of trials is large enough, the frequency approaches the probability.
Answer 2:
The mean of the random variable converges to its own expectation according to the probability.
In other words, under the condition that the experiment remains unchanged, the experiment is repeated many times, and the frequency of random events approximates its probability.
18. Central limit theorem
Given a population with an arbitrary distribution, n samples are randomly drawn from these populations each time, and a total of m times are drawn. Then take the m groups of samples and calculate the average value respectively. The distribution of these means is close to a normal distribution.
19. The difference between the theorem of large numbers and the central limit theorem
The former pays more attention to the sample mean, and the latter pays more attention to the distribution of the sample mean.
20. What is Maximum Likelihood Estimation
is a parameter estimation method.
The purpose of maximum likelihood estimation is to use the known sample results to deduce the parameter values that are most likely (maximum probability) to lead to such results.
Understand several artificial intelligence related algorithms
1. Linear regression
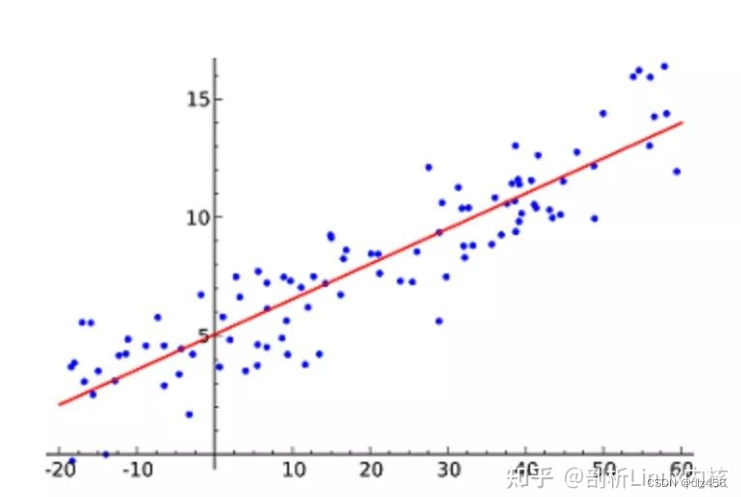
Linear Regression is probably the most popular machine learning algorithm. Linear regression is to find a straight line and make it fit the data points in the scatter plot as closely as possible. This line can then be used to predict future values! The most commonly used technique for this algorithm is Least of squares. This method calculates the line of best fit such that the vertical distance to each data point on the line is minimized. The total distance is the sum of the squares of the vertical distances (green line) of all data points. The idea is to fit the model by minimizing this squared error or distance.
2. Logistic regression
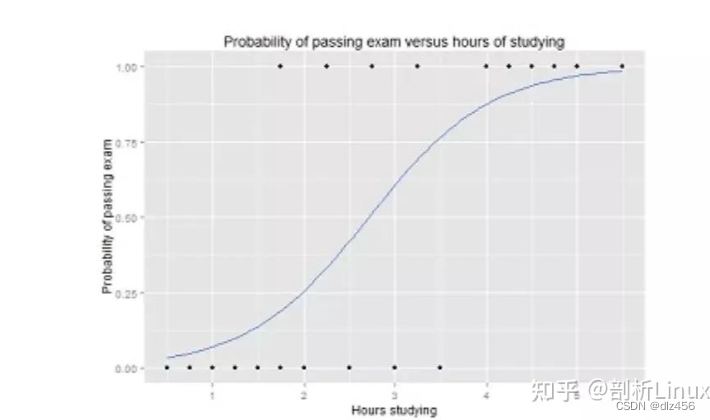
Logistic regression is similar to linear regression, but the result of logistic regression can only have two values. If linear regression is predicting an open value, then logistic regression is more like a yes or no judgment question.
The Y value in the logistic function ranges from 0 to 1 and is a probability value. Logistic functions usually have an S-shaped curve that divides the graph into two regions, making them suitable for classification tasks.
3. Decision tree
If both linear and logistic regression end the task within one round, then Decision Trees is a multi-step action, which is also used in regression and classification tasks, but the scenarios are usually more complex and specific.
To give a simple example, when a teacher faces a class of students, who are the good students? If it is simply judged that a score of 90 in the test is good, the students seem to be too rude, and they cannot rely solely on score theory. For students whose grades are less than 90, we can discuss them separately from homework, attendance, and questions.
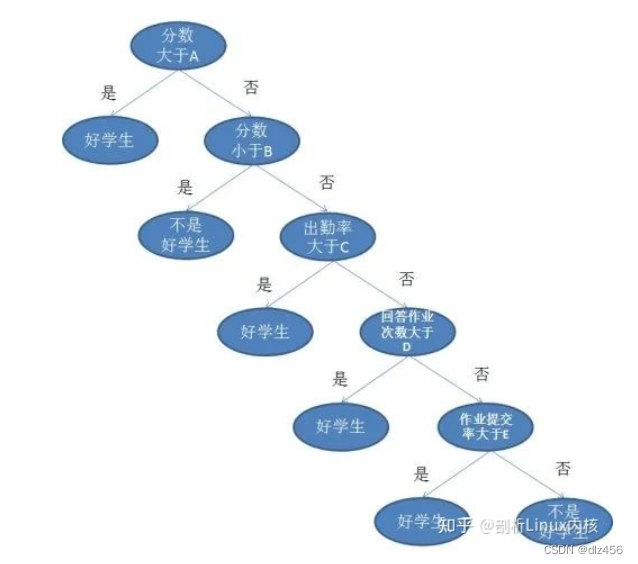
The above is a legend of a decision tree, where each bifurcated circle is called a node. At each node, we ask questions about the data based on the available features. The left and right branches represent possible answers. The final nodes (i.e. leaf nodes) correspond to a predicted value.
The importance of each feature is determined by a top-down approach. The taller a node is, the more important its attributes are. For example, the teacher in the above example thinks that the attendance rate is more important than homework, so the node of the attendance rate is higher, and of course the node of the score is higher.
4. Support Vector Machine SVM
Support Vector Machine (SVM) is a supervised algorithm for classification problems. The SVM tries to draw two lines between the data points with the largest margin between them. To do this, we plot data items as points in n-dimensional space, where n is the number of input features. On this basis, the support vector machine finds an optimal boundary, called the hyperplane, which best separates the possible outputs by class labels.
The distance between the hyperplane and the nearest class point is called the margin. The optimal hyperplane has the largest bound to classify points such that the distance between the nearest data point and the two classes is maximized.
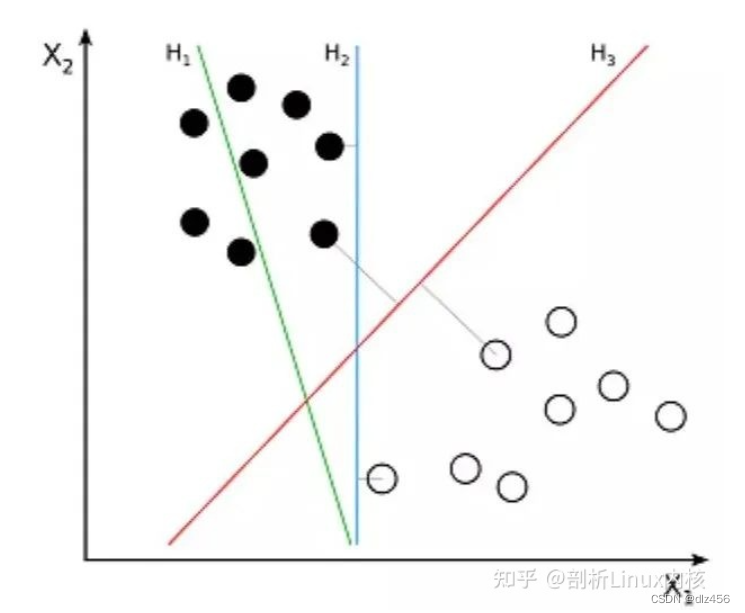
So the problem that the support vector machine wants to solve is how to separate a bunch of data. Its main application scenarios include character recognition, facial recognition, text classification and other recognition.
5. K-nearest neighbor algorithm KNN
It is one of the simplest methods in data mining classification techniques. The core idea of the KNN algorithm is that if most of the k nearest neighbor samples of a sample in the feature space belong to a certain category, the sample also belongs to this category and has the characteristics of samples in this category. In determining the classification decision, this method only determines the category of the sample to be divided according to the category of the nearest one or several samples. The KNN method is only related to a very small number of adjacent samples when making category decisions. Since the KNN method mainly relies on the limited surrounding samples rather than the method of discriminating the class domain to determine the category to which it belongs, the KNN method is more accurate than other methods for the sample sets to be divided when the class domain crosses or overlaps more. for fit.

KNN classification example
KNN theory is simple, easy to implement, and can be used for text classification, pattern recognition, cluster analysis, etc.
6. Dimensionality reduction
Machine learning problems are compounded by the sheer volume of data we are able to capture today. This means that training is extremely slow, and it is difficult to find a good solution. This problem is often referred to as the "curse of dimensionality".
Dimensionality reduction attempts to solve this problem by combining specific features into higher-level features without losing the most important information. **Principal Component Analysis (PCA)** is the most popular dimensionality reduction technique.
Principal component analysis reduces the dimensionality of datasets by compressing them into low-dimensional lines or hyperplanes/subspaces. This preserves the salient features of the original data as much as possible.
7. Artificial neural network ANN
Artificial Neural Networks (ANN) can handle large and complex machine learning tasks. A neural network is essentially a set of interconnected layers of weighted edges and nodes called neurons. Between the input and output layers, we can insert multiple hidden layers. Artificial neural networks use two hidden layers. Beyond that, deep learning needs to be dealt with.
The working principle of artificial neural network is similar to the structure of the brain. A group of neurons is assigned a random weight that determines how the neurons process input data. The relationship between input and output is learned by training a neural network on input data. During the training phase, the system has access to the correct answers.
If the network cannot accurately identify the input, the system adjusts the weights. When sufficiently trained, it will consistently recognize the correct patterns.
Each circular node represents an artificial neuron, and arrows represent connections from the output of one artificial neuron to the input of another artificial neuron.
Image recognition is a well-known application of neural networks.

8. Naive Bayes classification
It is mainly used to solve classification and regression problems.
Specific applications include:
marking an email as spam or not spam;
classifying news articles as technical, political or sports;
checking whether a piece of text expresses positive sentiment or negative sentiment;
in facial recognition software.
Bayesian classification is a general term for a series of classification algorithms. These algorithms are all based on Bayesian theorem, so they are collectively called Bayesian classification. Naive Bayesian algorithm (Naive Bayesian) is one of the most widely used classification algorithms. Naive Bayesian classifiers are based on a simple assumption that attributes are conditionally independent of each other given target values.
The above artificial intelligence algorithm comes from the link: https://zhuanlan.zhihu.com/p/536818157
machine learning
According to the training method, machine learning can be roughly divided into three categories:
supervised learning,
unsupervised learning,
reinforcement learning
Supervised learning
Supervised learning means that we give the algorithm a data set and give the correct answer. Machines use data to learn how to calculate the correct answer.
This way of helping machine learning by manually labeling is called supervised learning. This way of learning works very well, but the cost is also very high.
Unsupervised learning
In unsupervised learning, there is no "right answer" for a given data set, all data are the same. The task of unsupervised learning is to mine the underlying structure from a given data set.
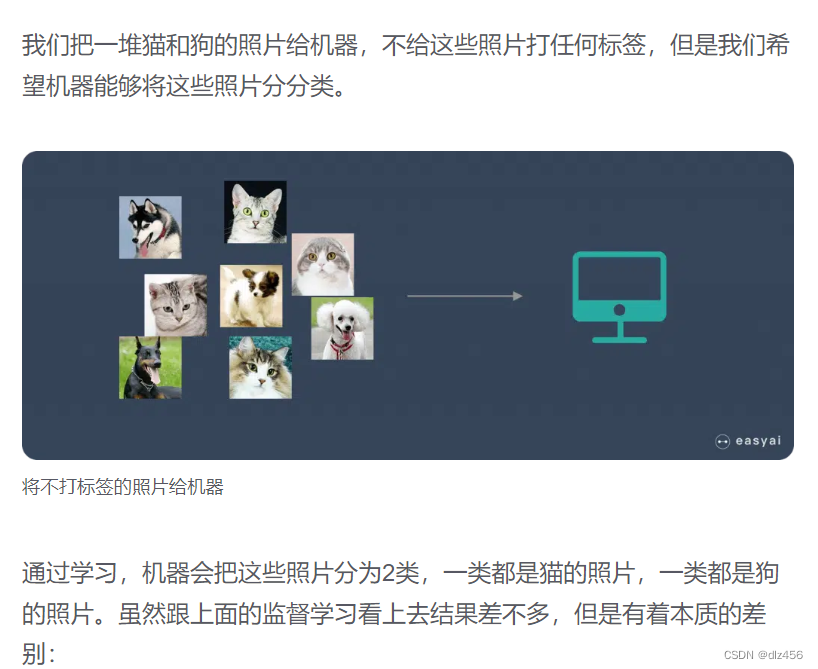
In unsupervised learning, although the photos are divided into cats and dogs, the machine does not know which is a cat and which is a dog. For machines, it is equivalent to being divided into two categories, A and B.
**Reinforcement Learning**
Reinforcement learning is closer to the essence of biological learning, so it is expected to obtain higher intelligence. It focuses on how the agent can take a series of actions in the environment so as to obtain the maximum cumulative reward. With reinforcement learning, an agent should know what action to take in what state.
The most typical scenario is playing games.
On January 25, 2019, AlphaStar (an artificial intelligence program developed by Google, which adopts the training method of reinforcement learning) completely abused the professional players "TLO" and "MANA" of StarCraft.
7 Steps to Hands-On Machine Learning
- Data collection
- data preparation
- choose a model
- train
- Evaluate
- Parameter adjustment
- forecast (get started)

15 classic machine learning algorithms
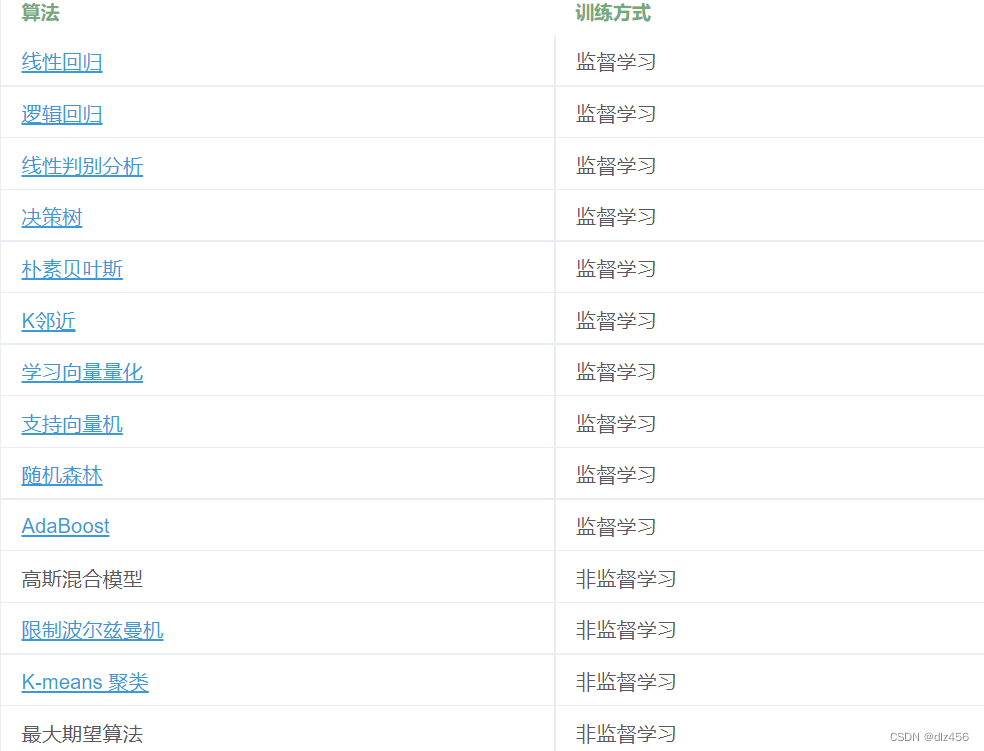
Machine learning-related content transferred from: https://easyai.tech/ai-definition/machine-learning/
deep learning
Deep learning is a branch (the most important branch) of machine learning. Some of the best-performing applications today are mostly deep learning.
The concept of deep learning originated from the research of artificial neural networks, but it is not completely equal to traditional neural networks. However, in terms of name, many deep learning algorithms will contain the word "neural network", such as: convolutional neural network, recurrent neural network. Therefore, deep learning can be said to be an upgrade based on traditional neural networks, which is approximately equal to neural networks.
The following example really explains it very well! ! learned! :
Assume that the information to be processed by deep learning is "water flow", and the deep learning network that processes data is a huge water pipe network composed of pipes and valves. The inlets of the network are pipe openings and the outlets of the network are also pipe openings. This network of water pipes has many layers, and each layer has many regulating valves that can control the direction and flow of water flow. According to the needs of different tasks, the number of layers of the water pipe network and the number of regulating valves in each layer can have different combinations. For complex tasks, the total number of regulating valves can be in the thousands or even more. In the water pipe network, each regulating valve on each floor is connected to all regulating valves on the next floor through water pipes to form a fully connected water flow system from front to back layer by layer.
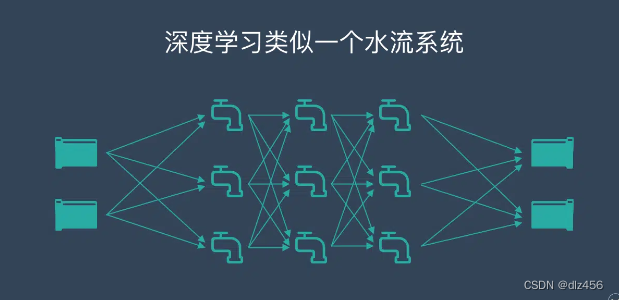
So how can a computer use this vast network of water pipes to learn to read?
For example, when the computer sees a picture with the word "Tian", it simply puts all the numbers that make up the picture (in the computer, each color point of the picture is composed of "0" and "1") represented by numbers) all become streams of information, which are poured into the water pipe network from the inlet.
We pre-inserted a signboard at each outlet of the water pipe network, corresponding to each Chinese character we want the computer to recognize. At this time, because the input is the Chinese character "Tian", when the water flows through the entire water pipe network, the computer will run to the outlet of the pipe to see if the water flowing out of the pipe outlet marked with the word "Tian" is the most . If so, the pipe network meets the requirements. If this is not the case, just adjust each flow control valve in the water pipe network, so that the water that "flows out" from the "Tian" character outlet is at most.
Now, the computer has to be busy for a while, and there are so many valves to adjust! Fortunately, the speed of the computer is fast, and the violent calculation and the optimization of the algorithm can always give a solution quickly and adjust all the valves so that the flow at the outlet meets the requirements.

In the next step, when learning the word "Shen", we will use a similar method to turn each picture with the word "Shen" into a water flow composed of a large number of numbers, pour it into the water pipe network, and see if it is The outlet of the pipe with the word "Shen" is the most flowing. If not, we have to adjust all the valves. This time, we must not only ensure that the "Tian" character we have just learned is not affected, but also ensure that the new "Shen" character can be processed correctly.
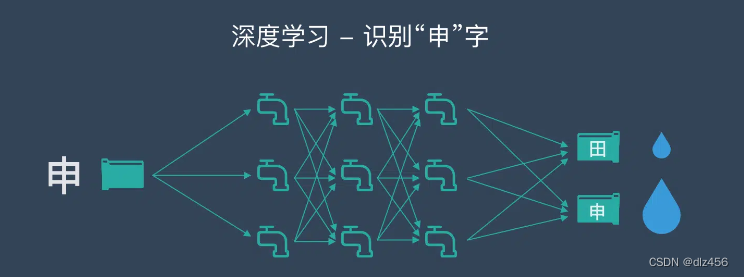
Repeatedly, it is known that the water flow corresponding to all Chinese characters can flow through the entire water pipe network in the desired way. At this time, we say that this water pipe network is a well-trained deep learning model. When a large number of Chinese characters are processed by this pipeline network and all valves are adjusted in place, the entire water pipeline network can be used to recognize Chinese characters. At this time, we can "weld" all the adjusted valves and wait for the arrival of new water flow.
Similar to what is done during training, the unknown pictures will be converted by the computer into a stream of data, which will be poured into the trained water pipe network. At this time, the computer only needs to observe, which water outlet flows out the most, and which word is written in this picture.
Deep learning is roughly such an overall structure built with human mathematical knowledge and computer algorithms, combined with as much training data as possible and the large-scale computing power of computers to adjust internal parameters, so as to approach the problem goal as much as possible. The way experience is modeled.


Convolutional Neural Networks – CNN
Value of CNN:
It can effectively reduce the dimensionality of a large amount of data into a small amount of data (without affecting the result)
and can retain the characteristics of the image, similar to the human visual principle
The basic principle of CNN:
Convolutional layer – the main function is to preserve the characteristics of the picture
Pooling layer – the main function is to reduce the data dimension, which can effectively avoid overfitting
Fully connected layer – output the results we want according to different tasks
Practical applications of CNN:
image classification, retrieval,
target location detection,
target segmentation,
face recognition
, bone recognition
Recurrent Neural Network – RNN
RNN is an algorithm that can efficiently process sequence data. For example: article content, voice audio, stock price trend...
The reason why he can process sequence data is that the previous input in the sequence will also affect the subsequent output, which is equivalent to having a "memory function". But RNN has serious short-term memory problems, and long-term data has little effect (even if it is important information).
So variant algorithms such as LSTM and GRU appeared based on RNN. These variant algorithms mainly have several characteristics:
long-term information can be effectively retained;
important information is selected to be retained, and unimportant information will be "forgotten"
Several typical applications of RNN are as follows:
text generation
, speech recognition
, machine translation,
image description generation,
video tagging
Generative Adversarial Networks – GANs
assume that a city is in chaos, and soon there will be countless thieves in the city. Among these thieves, some may be master theft, and some may have no skills at all. If the city starts to improve its law and order, a "campaign" against crime is suddenly launched, and the police begin to resume patrolling in the city. Soon, a group of "not skilled" thieves will be caught. The reason why the unskilled thieves were caught was because the police were not skilled enough. After catching a group of low-end thieves, it is hard to say how the city's security level will become, but it is obvious that the city The average level of thieves here has been greatly improved.
The police began to continue training their crime-solving skills and began to catch the more and more cunning thieves. With the arrest of these professional habitual offenders, the police have also developed special skills. They can quickly spot suspicious persons from a group of people, so they go forward to interrogate and finally arrest the suspects; the life of thieves is also difficult. , because the level of the police has been greatly improved, if you still want to behave sneakily like before, you will be caught by the police soon. In order to avoid being arrested, the thieves try their best to appear less "suspicious", while the devil is one foot tall and the road is one foot high. The police are also constantly improving their own level, striving to distinguish thieves from innocent ordinary people. With this kind of "communication" and "communication" between the police and the thief, the thieves have become very cautious. They have extremely high stealing skills and behave exactly like ordinary people, while the police have all practiced "sighting eyes". ", once a suspicious person is found, it can be found immediately and controlled in time-in the end, we got the strongest thief and the strongest police at the same time.

Deep Reinforcement Learning –
The idea of the RL reinforcement learning algorithm is very simple. Taking games as an example, if a certain strategy can be adopted in the game to achieve higher scores, then further "strengthen" this strategy in order to continue to achieve better results . This strategy is very similar to various "performance rewards" in daily life. We often use this strategy to improve our game level.
In the Flappy bird game, we need simple click operations to control the bird, avoid various water pipes, and fly as far as possible, because the farther you fly, the higher the reward points.
This is a typical reinforcement learning scenario:
the machine has a clear role of a bird—the agent
needs to control the bird to fly farther—the goal
needs to avoid various water pipes throughout the game—
the way the environment avoids water pipes is to make the bird The bird flies hard—the action,
the farther it flies, the more points it will get—reward
You will find that the biggest difference between reinforcement learning, supervised learning, and unsupervised learning is that it does not require a lot of "data feeding". Instead, you learn certain skills through your own constant attempts.
Deep learning related content comes from: https://easyai.tech/ai-definition/deep-learning/