
Reprinted from: Python technology
Spring is here, the spring is bright, the birds are singing and the flowers are fragrant, and everything is getting warmer! The flowers in the park are all blooming, and I am not in the mood to work these days. I am planning to go out on weekends to play in the mountains and water, and go out for a walk! First, use Python to crawl a wave of girls' pictures and feel the fish.
import module
First, paste the modules you are using.
import requests
from bs4 import BeautifulSoup
import time
import randomgrab
The crawling process of Jiandan.com: start crawling from page 101, extract the url of the women's clothing picture on the page, save the picture after requesting the url, click the next page, repeat the cycle... .
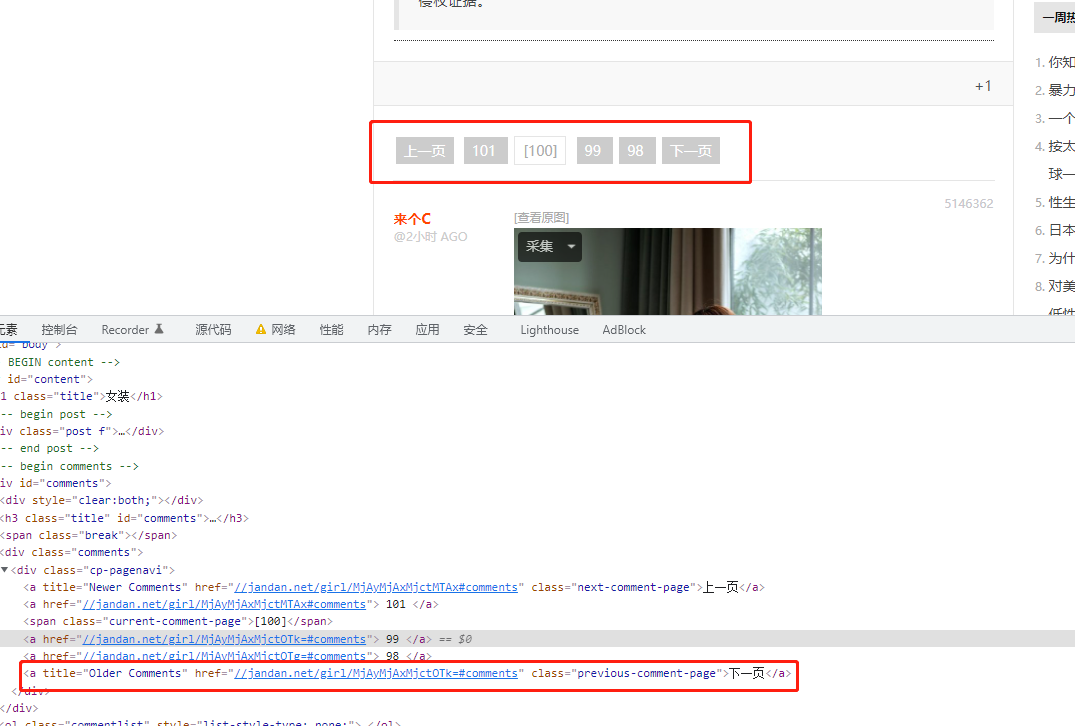
http://jandan.net/girl It is the last page displayed when visiting the page of the omelette.com . Get the url of the next page through the paging control above.
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/97.0.4692.99 Safari/537.36'
}
def get_html(url):
resp = requests.get(url = url, headers = headers)
soup = BeautifulSoup(resp.text)
return soup
def get_next_page(soup):
next_page = soup.find(class_='previous-comment-page')
next_page_href = next_page.get('href')
return f'http:{next_page_href}'[查看原图] You can see the hyperlinks on each image , extracting this href is to download the image.
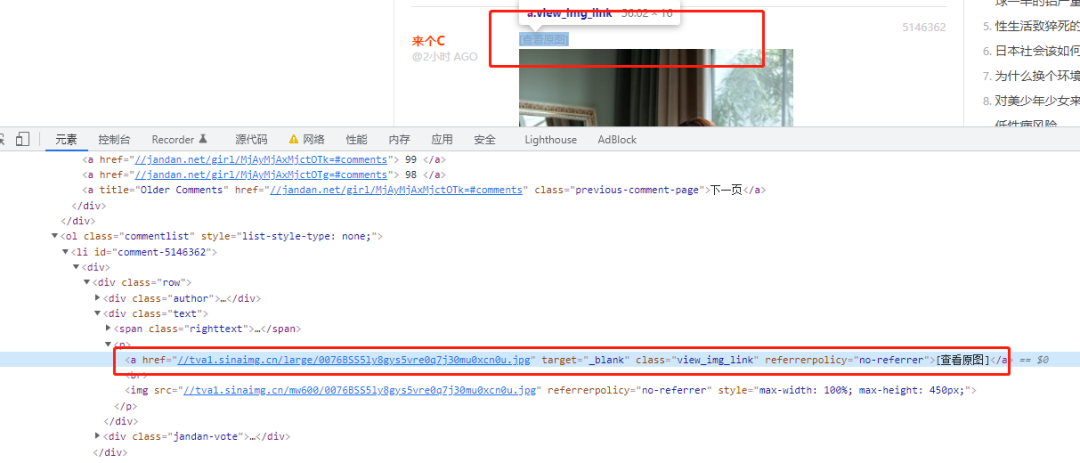
def get_img_url(soup):
a_list = soup.find_all(class_ = 'view_img_link')
urls = []
for a in a_list:
href = 'http:' + a.get('href')
urls.append(href)
return urlsIt is easier to save the image, and write it directly to the file after the request.
def save_image(urls):
for item in urls:
name = item.split('/')[-1]
resp = requests.get(url=item, headers = headers)
with open('D:/xxoo/' + name, 'wb') as f:
f.write(resp.content)
time.sleep(random.randint(2,5))Finally, let's take a look at the fetch results.

Summarize
This request crawler is suitable for small partners who are new to python and have not learned the soup module. Interested friends, you can start typing the code. Read a hundred times, read a thousand sides, it is better to knock on one side. Learning Python must be hands-on and practical.
Interested students can quickly join our planet
3 weeks zero basic introduction provides 10 lessons
12 interesting practical projects throughout the year including source code,
Reward outstanding Top3 students every month to send books
Professional Q&A group, nanny-style teaching by Dachang teachers
If you are not satisfied, feel free to refund within three days! 88 a year, now 16 yuan off

Scan the code to join, get started with zero basics in 3 weeks
推荐阅读:
入门: 最全的零基础学Python的问题 | 零基础学了8个月的Python | 实战项目 |学Python就是这条捷径
干货:爬取豆瓣短评,电影《后来的我们》 | 38年NBA最佳球员分析 | 从万众期待到口碑扑街!唐探3令人失望 | 笑看新倚天屠龙记 | 灯谜答题王 |用Python做个海量小姐姐素描图 |碟中谍这么火,我用机器学习做个迷你推荐系统电影
趣味:弹球游戏 | 九宫格 | 漂亮的花 | 两百行Python《天天酷跑》游戏!
AI: 会做诗的机器人 | 给图片上色 | 预测收入 | 碟中谍这么火,我用机器学习做个迷你推荐系统电影
小工具: Pdf转Word,轻松搞定表格和水印! | 一键把html网页保存为pdf!| 再见PDF提取收费! | 用90行代码打造最强PDF转换器,word、PPT、excel、markdown、html一键转换 | 制作一款钉钉低价机票提示器! |60行代码做了一个语音壁纸切换器天天看小姐姐!|The year's hottest copy
5). 20 python codes you must master, short and powerful, infinitely useful
7). The 80 pages I summarized in the "Rookie Learning Python Selected Dry Goods.pdf" are all dry goods
8). Goodbye Python! I'm going to learn Go! 2500 words in-depth analysis !
Click to read the original text to see 200 Python cases!