Hello everyone, I am Payson sauce!
I've been under a lot of work pressure recently, and I'm going to sleep after I come back every night after washing up. But I always feel that the day passes like this, which is a bit regrettable, so I lie on the bed every day before going to bed and watch the vibrato, and look at the beautiful lady, and I will feel much more comfortable!
Some girls’ videos are really endless, so I want to save them on my phone, and when I need comfort (empty, lonely and cold), take them out and enjoy them, to cheer myself up!
So I picked up their videos and enjoyed them slowly! The following is a brief introduction to the pulling process.
This article introduces 3 aspects
How to download the high-definition video wallpaper of a certain sound in the windows version (review the old text + video introduction)
Download a single video of a certain audio (video introduction)
Download a certain audio user video collection (detailed introduction)
Using mitmproxy, you can download videos, live wallpapers, and comments no matter if it is a certain sound in the web version or a certain sound in the windows version.
The proxy configuration and certificate installation of mitmproxy
python技术have been introduced in the official account to capture a short audio and video data
I am writing this article because I want to download 105 videos of this collection

What is the use of downloading these?
One of the benefits is to get a wealth of material, which will dazzle you. I downloaded more than 400 high-definition video wallpapers of a certain sound in the Windows version at one go
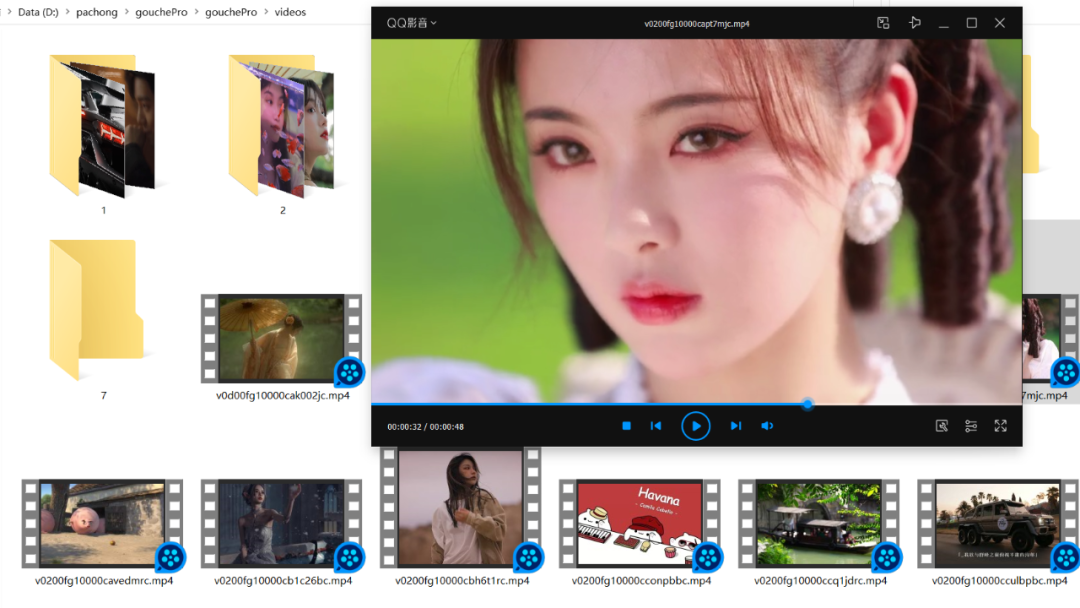
They are all high-definition horizontal desktop dynamic video wallpapers, which are simply not too fragrant.
Previously, I used the method of "bypassing cookies" to download the videos collected on Dianchedi. In comparison, the method we introduced today is simpler, and there is no need to run python to simulate requests. See how mitmweb can help you with exact matching:
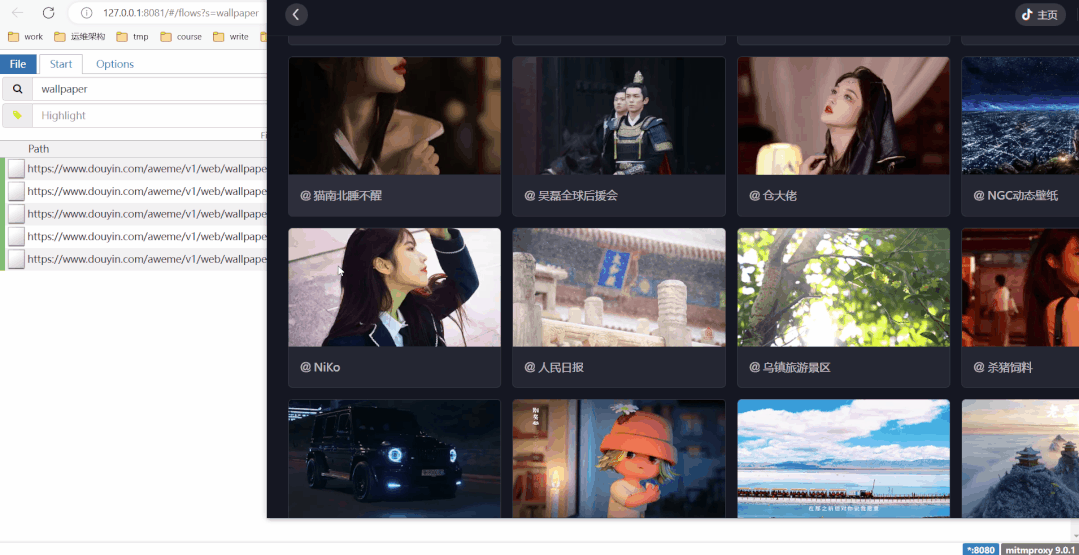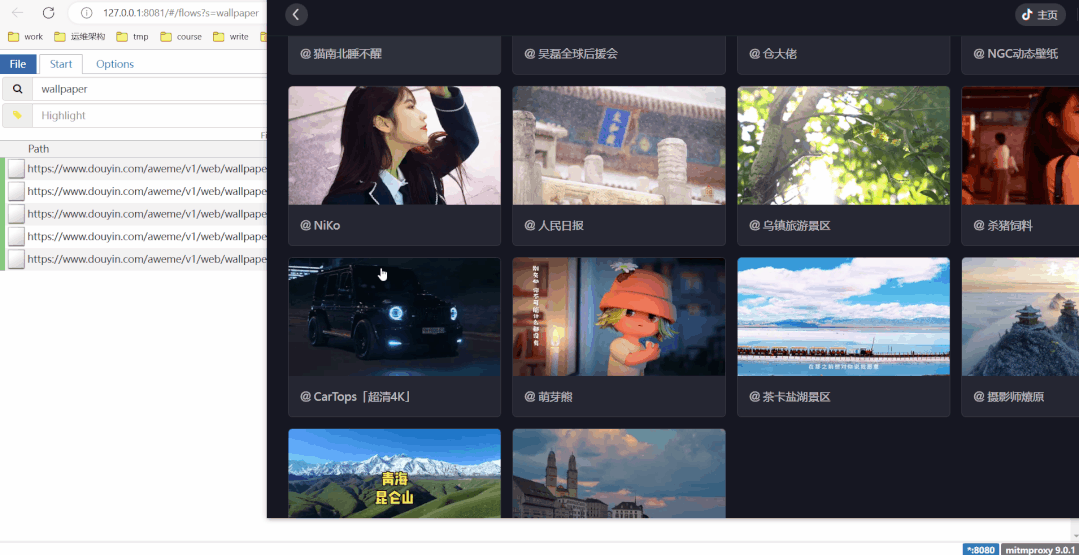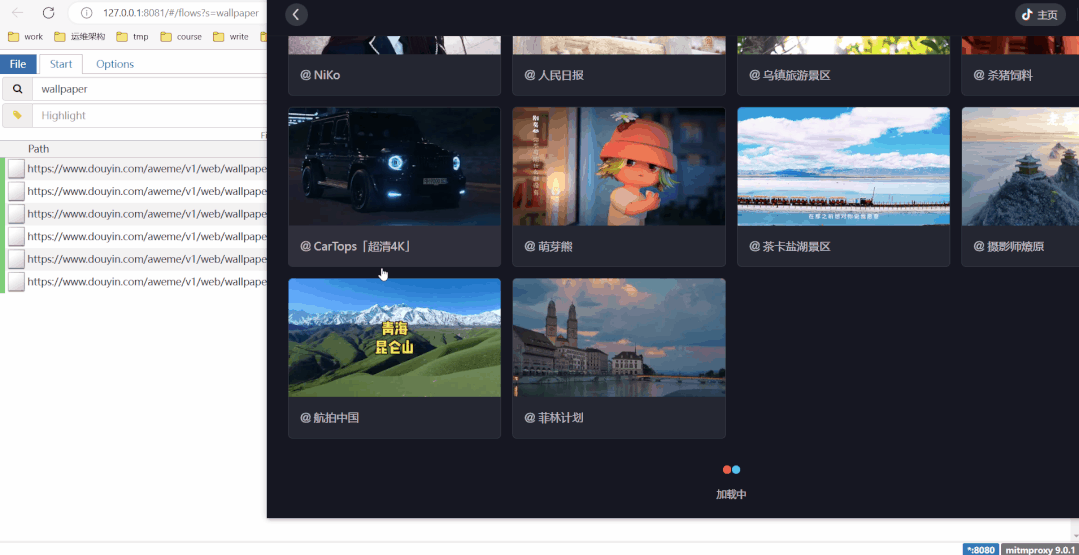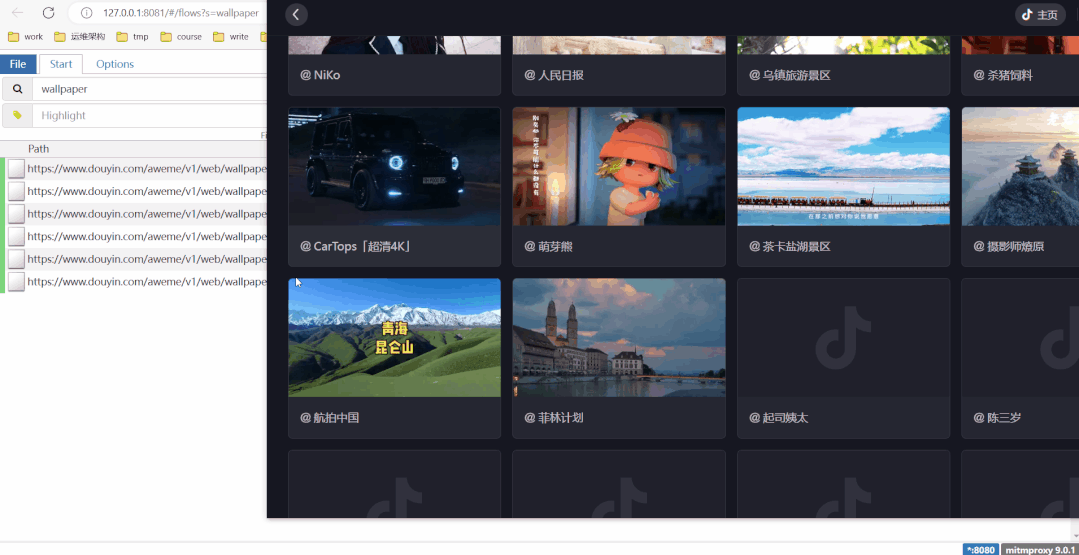
Define the search condition "wallpaper", refresh the live wallpaper of a certain sound, and new links will appear on the left, and the video MP4 addresses are all in these links!
For details, please refer to the article Use Python to crawl a certain sound dynamic wallpaper, and the desktop will be more fragrant
For the sake of clarity, I tried to make a video version for the first time to explain:
Use video clips
I made this "three-screen title effect" with Clipping:
3 dance videos are needed, all of which are linked from a sound live wallpaper through mitmproxy, and then downloaded in batches by python.
There are a lot of youthful and energetic dances, it is not very suitable to download and use
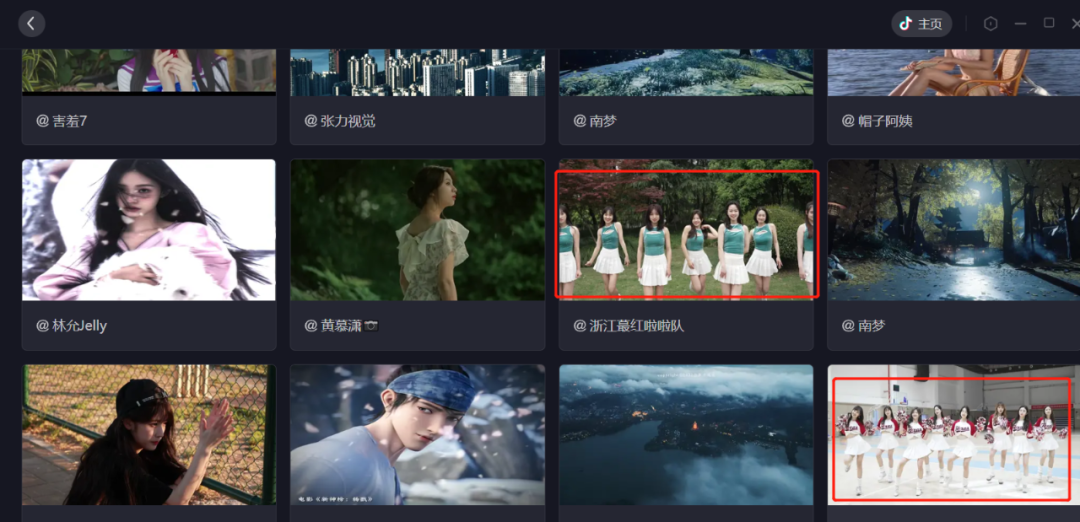
download single video
The way to download a single video mitmdump -q -s 脚本名, the script is very simple, just write it like this
def response(flow):
if 'web.douyinvod.com' in flow.request.url:
print('nice111',flow.request.url)A certain audio and video you swiped matches web.douyinvod.com,
Wechat video account, comments under a certain audio and video can also be obtained or downloaded in this way, because the link is characteristic:
An audio and video link generally matches
web.douyinvod.comWeChat video number matching
video.qq.comComments under an audio and video match
v1/web/comment/list
Check out my video introduction:
This method can download the beautiful video you are watching in real time
Download an audio user video collection
Having said so much, let's enter today's topic and download the video collection

Pay attention, this collection is updated to 105 episodes.
Remember this number, we're going to download it all. In case the author deletes the work, he will not be able to see it.
First set the proxy and start mitmweb,
Then click on the collection on the webpage to enter the playback page
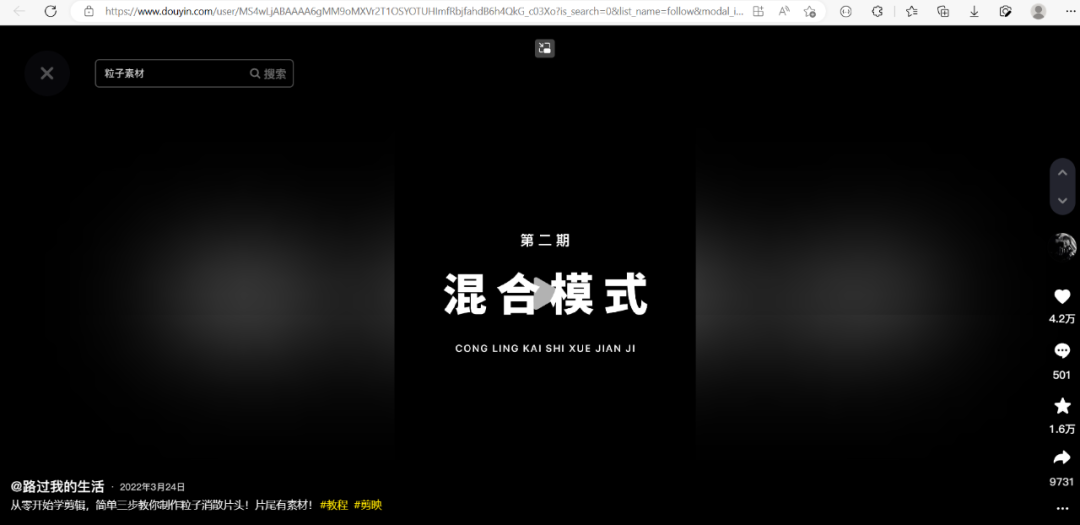
Rolling the mouse wheel will play the videos of this collection in turn. Let's be patient and scroll to the last work (No. 105).
Just scroll quickly, the purpose is to let mitmweb record these video data. Although it is a little cumbersome, but more than 100 videos are scrolled in more than ten seconds, and then it is easy to handle.
The next step is to use Python to crawl the dynamic wallpaper of a certain sound, and the desktop will be even more fragrant! Almost the same, just change the search criteria.
mix means "collection", we search for "mix/" and see 7 urls
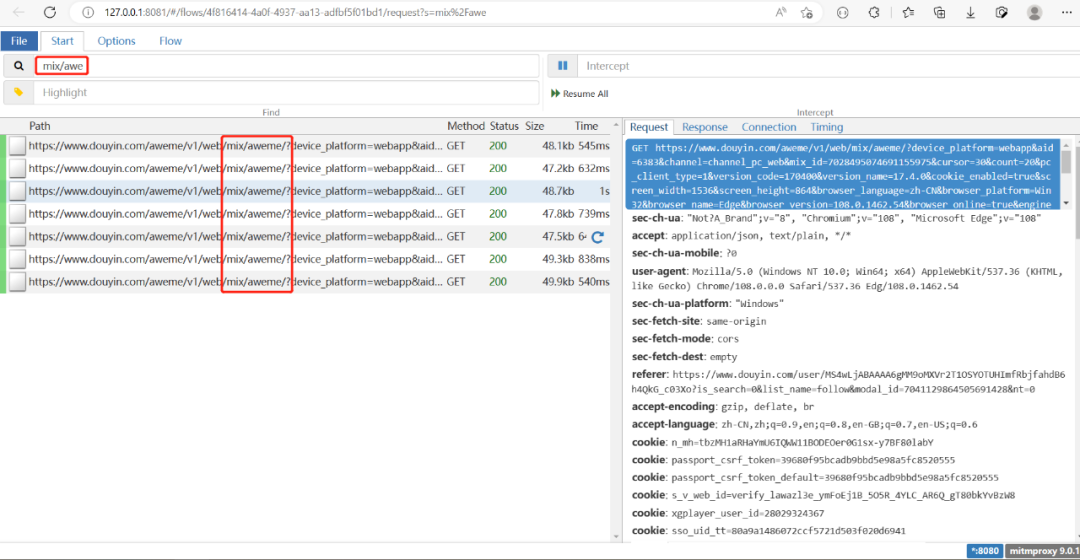
If you select one and click the "Download" button, a "content.data" file will be downloaded
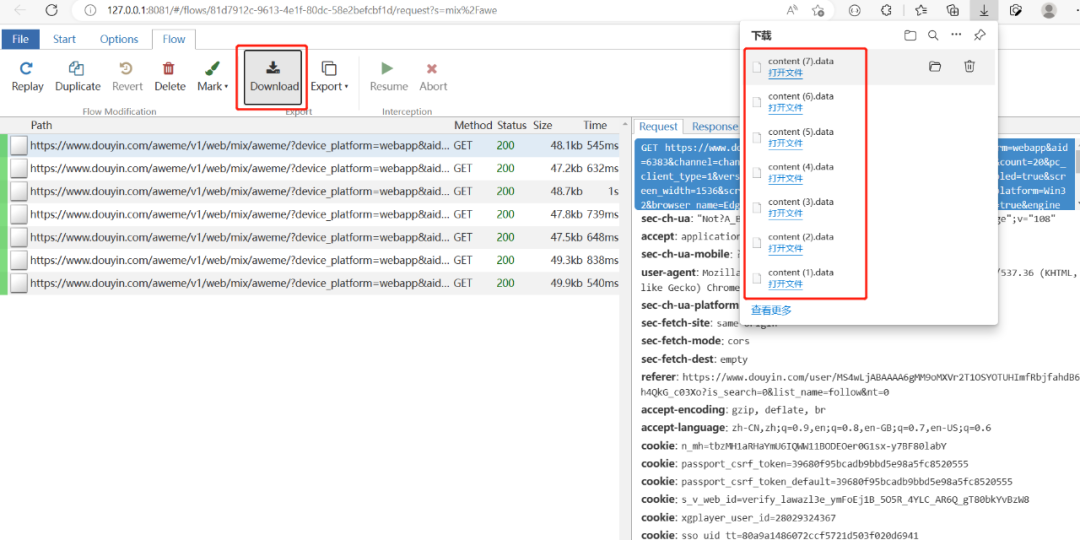
7 urls are 7 content.data files, use scripts to do deduplication processing
import json
url_list = []
url_dict = {}
with open('content.data', 'r',encoding='utf-8') as f:
x = json.load(f)
for i in x['aweme_list']:
#去掉特殊的
if 'anchor_info' in i:
continue
else:
for i in i['video']['bit_rate']:
#url_list有3个url,但视频内容相同,取最后一个
url = i['play_addr']['url_list'][2]
#video_id相同的是同一个视频,取出video_id,用字典去重
a = url.split('video_id=')[1].split('&line=')[0]
print(a)
url_dict[a] = url
#去重后的视频添加到列表中
for k,v in url_dict.items():
url_list.append(v)
print(len(url_list))
print(url_list)Print the output, each content.data has 15 video addresses
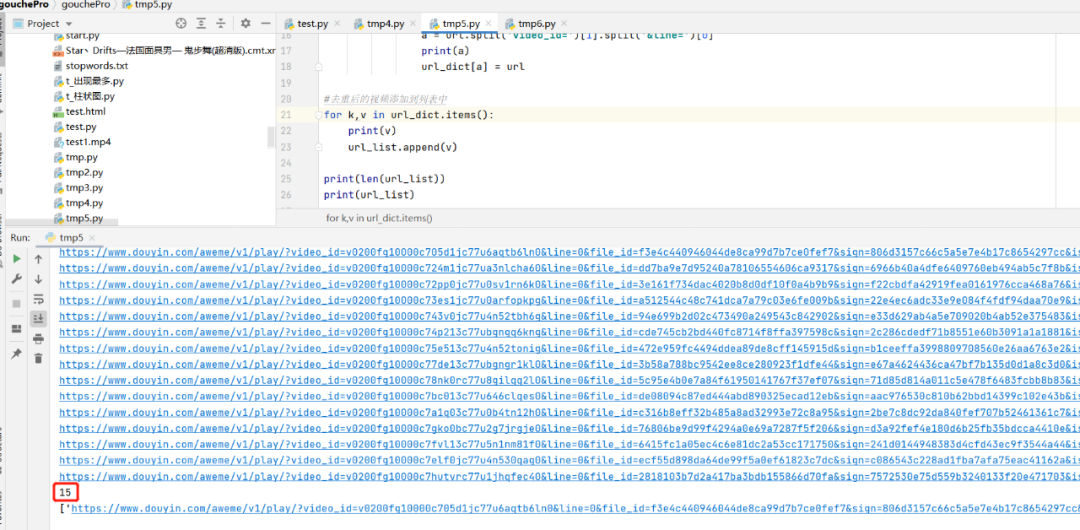
7 content.data, 7 multiplied by 15 is 105 videos, the video download address of the entire collection is here!
Then download with script
import os
import requests
from tqdm import tqdm
VIDEO_PATH = r'videos'
def download(url,fname):
# 用流stream的方式获取url的数据
resp = requests.get(url, stream=True,verify=False)
total = int(resp.headers.get('content-length', 0))
with open(fname, 'wb') as file, tqdm(
desc=fname,
total=total,
unit='iB',
unit_scale=True,
unit_divisor=1024,
) as bar:
for data in resp.iter_content(chunk_size=1024):
size = file.write(data)
bar.update(size)
if __name__ == "__main__":
url_list = ['https://www.douyin.com/aweme/v1/play/?video_id=v0d00fg10000cagm35rc77u3k4nb0430&line=0&file_id=fec3f8eeb45e48a18f30dfd96922f659&sign=4450c5609c69d0a5c1100e6801cf25dd&is_play_url=1&source=PackSourceEnum_AWEME_DETAIL', 'https://www.douyin.com/aweme/v1/play/?video_id=v0200fg10000c9glhfrc77u0fbj4iqs0&line=0&file_id=e330ce20f5f245e9b1923f8cd26b6ef9&sign=0ee1a91a52645237a4d1382c22a0b540&is_play_url=1&source=PackSourceEnum_AWEME_DETAIL', ...]
for url in url_list:
video_name = url[47:67]
video_full_path = os.path.join(VIDEO_PATH,"%s.mp4" % video_name)
download(url, video_full_path)The downloaded video, as shown below

Well, that's all for today's introduction, see you next time!