There are many classification algorithms for machine learning, and today we will learn one of them - Naive Bayes.
Naive Bayes is part of Bayesian decision theory, and the core idea of Bayesian decision theory is to choose the decision with the highest probability.
For example, if there are two thieves A and B in a village, p1 indicates the probability that the theft in the village is caused by A, and p2 indicates the probability that the theft in the village is caused by B. Now if the village is stolen, guess who did it.
If p1>p2, it is considered that A did it, otherwise p1<p2, it is considered that B did it. This is the core idea of Bayesian decision theory.
Let's experience Naive Bayes with a practical example of a binary classification problem.
Most of the comments on the website have an approval process to determine whether a comment is abusive, and if so, it will not be displayed on the website. This is a typical two-category practical problem. Messages are classified into two categories: insulting and non-insulting.
In order to realize the classification procedure of the message, there are roughly the following two difficulties that must be solved:
1. How is the message stored in the memory and how is it expressed?
2. How to calculate the probability that a message belongs to a certain category?
Let us discuss these two issues one by one. For a specific message, except for punctuation, it is nothing more than a collection of words. And some words appear in one message, but not necessarily in others. We can combine all the words that appear in the message into a vocabulary. For a specific message, there is an array of flags, and the corresponding index value indicates whether the words in the vocabulary appear in the message.
For example, message 1 is "I Love You", and message 2 is "I Hate You". At this time, the vocabulary composed of message 1 and message 2 is "I Love Hate You", and the flag array corresponding to message 1 is [1,1 ,0,1], the flag array corresponding to message 2 is [1,0,1,1].
Alright, let's implement this functionality with code.
#Load message collection and message tags
def loadDataSet():
messageList1=[['my', 'dog', 'has', 'flea', 'problems', 'help', 'please'],
['maybe', 'not', 'take', 'him', 'to', 'dog', 'park', 'stupid'],
['my', 'dalmation', 'is', 'so', 'cute', 'I', 'love', 'him'],
['stop', 'posting', 'stupid', 'worthless', 'garbage'],
['mr', 'licks', 'ate', 'my', 'steak', 'how', 'to', 'stop', 'him'],
['quit', 'buying', 'worthless', 'dog', 'food', 'stupid']]
messageClass1 = [0,1,0,1,0,1] #message label 1=insulting 0=non-insulting
return messageList1,messageClass1
'''
Create a glossary
The parameter is the message collection
'''
def createVocaList(messageList1):
vocaList1 = set() #Use sets to remove duplicate words
for message in messageList1:
for word in message:
vocaList1.add(word)
vocaList1 = list(vocaList1)
vocaList1 = sorted(vocaList1) #word sorting
return vocaList1
'''
Find the flag array corresponding to the message
The parameters are vocabulary and a message
'''
def messageToFlag(vocaList1,message):
flag = [0]*len(vocaList1)
for word in message:
if word in vocaList1:
flag[vocaList1.index(word)] = 1
else:
print(word+'not in this vocabulary')
return flag
The loadDataSet() function above creates some experimental samples and returns 6 message sets and corresponding categories. The createVocaList() function is used to create a vocabulary, the input parameter is the message collection, and it returns a vocabulary without repeated words and sorted alphabetically. The messageToFlag() function is used to find the flag array corresponding to a specific message. The parameters are the vocabulary and a specific message.
As a test, output the vocabulary and an array of flags corresponding to the first message.
#test messageList , messageClss = loadDataSet() vocaList = createVocaList(messageList) print(vocaList) print(messageToFlag(vocaList,messageList[0]))
The output is as follows.
['I', 'ate', 'buying', 'cute', 'dalmation', 'dog', 'flea', 'food', 'garbage', 'has', 'help', 'him', 'how', 'is', 'licks', 'love', 'maybe', 'mr', 'my', 'not', 'park', 'please', 'posting', 'problems', 'quit', 'so', 'steak', 'stop', 'stupid', 'take', 'to', 'worthless'] [0, 0, 0, 0, 0, 1, 1, 0, 0, 1, 1, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0]
So far, we have solved the first difficulty. It is to use all the messages to generate a vocabulary, and then generate a flag array for each message just like looking up a dictionary, which solves the problem of message storage and representation.
Now let's look at the second question, how to calculate the probability of which category the message belongs to. Through the above analysis, we know that the message corresponds to a flag array w, and to find the probability of which category the message belongs to is to find the value of P(ci |w) . From the calculation formula of conditional probability, we have the following method to calculate P( ci |w) .
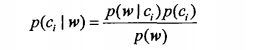
where P(ci) can be obtained by dividing the number of comments in category i (insulting or non-insulting) by the total number of comments. We assume that words appear independently, and P(w|ci) can be written as P(w1,w2,...,wn|ci), where n is the number of words in the vocabulary. Since w1, w2, ..., wn are independent, P(w1, w2...wn|ci) is P(w1|ci), P(w2|ci), ..., P The product of (wn|ci). P(wi|ci) can be calculated by dividing the number of occurrences of the wi-th word of the corresponding vocabulary in category i by the total number of words in category i.
The following code is to find the above probability.
'''
Find P(c1): the probability that the message is insulting
Find P(wi|ci): the probability of the occurrence of the wi-th word in the corresponding vocabulary in category i
The parameters are the set of flag arrays corresponding to the message and the classification label of the message
'''
def calcuProbability(messageFlag1,messageClass1):
messageNum = len(messageClass1) #Total number of messages
class1Probability = sum(messageClass1) / float(messageNum) #P(c1)
WordNum = len(messageFlag1[0]) #vocabulary length
pw0 = np.zeros(WordNum) #The number of occurrences of each word in the vocabulary in non-insulting
pw1 = np.zeros(WordNum) #The number of occurrences of each word in the vocabulary in insulting
p0Num = 0 #Number of non-insulting words
p1Num = 0 #Number of insulting words
for i in range(messageNum):
if messageClass1[i] == 1: #insulting message
p1Num += sum(messageFlag1[i])
pw1 += messageFlag1[i]
else: #non-insulting message
p0Num += sum(messageFlag1[i])
pw0 += messageFlag1[i]
pw0 = pw0 / float(p0Num)
pw1 = pw1 / float(p1Num)
return pw0, pw1, class1Probability
have a test.
#test
messageList , messageClss = loadDataSet()
vocaList = createVocaList(messageList)
messageFlag = []
for message in messageList:
messageFlag.append(messageToFlag(vocaList,message))
p0, p1, c1 = calcuProbability(messageFlag,messageClss)
print(vocaList)
print(p0)
print(p1)
print(c1)
The results are as follows.
['I', 'ate', 'buying', 'cute', 'dalmation', 'dog', 'flea', 'food', 'garbage', 'has', 'help', 'him', 'how', 'is', 'licks', 'love', 'maybe', 'mr', 'my', 'not', 'park', 'please', 'posting', 'problems', 'quit', 'so', 'steak', 'stop', 'stupid', 'take', 'to', 'worthless'] [0.041666666666666664, 0.041666666666666664, 0.0, 0.041666666666666664, 0.041666666666666664, 0.041666666666666664, 0.041666666666666664, 0.0, 0.0, 0.041666666666666664, 0.041666666666666664, 0.083333333333333329, 0.041666666666666664, 0.041666666666666664, 0.041666666666666664, 0.041666666666666664, 0.0, 0.041666666666666664, 0.125, 0.0, 0.0, 0.041666666666666664, 0.0, 0.041666666666666664, 0.0, 0.041666666666666664, 0.041666666666666664, 0.041666666666666664, 0.0, 0.0, 0.041666666666666664, 0.0] [0.0, 0.0, 0.052631578947368418, 0.0, 0.0, 0.10526315789473684, 0.0, 0.052631578947368418, 0.052631578947368418, 0.0, 0.0, 0.052631578947368418, 0.0, 0.0, 0.0, 0.0, 0.052631578947368418, 0.0, 0.0, 0.052631578947368418, 0.052631578947368418, 0.0, 0.052631578947368418, 0.0, 0.052631578947368418, 0.0, 0.0, 0.052631578947368418, 0.15789473684210525, 0.052631578947368418, 0.052631578947368418, 0.10526315789473684] 0.5
Among them, the word 'buying' appears 0 times in the non-insulting message and 1 time in the insulting message, so the probabilities are 0 and 0.052631578947368418 respectively, and the calculation is correct. The probability of an insulting message being 0.5 is also calculated correctly.
Next we enter the most exciting part - predicting the classification of a message. We still have two small problems to solve before making predictions. Have you found that many of the values of P(wi|ci) are 0. When multiple P(wi|ci) are multiplied, as long as one of them is 0, the result is 0. To reduce this effect, we can initialize the number of occurrences of all words to 1 and the denominator to 2.
pw0 = np.ones(WordNum) #The number of occurrences of each word in the vocabulary in non-insulting pw1 = np.ones(WordNum) #The number of occurrences of each word in the vocabulary in insulting p0Num = 2 #Number of non-insulting words p1Num = 2 #Number of insulting words
Another small problem is that the value of P(wi|ci) is generally relatively small, and underflow may occur when multiple smaller numbers are multiplied. To solve this problem, the logarithm method can be used. log( P(w1|ci)*P(w2|ci), ..., *P(wn|ci) ) = log( P(w1|ci) ) + log( P(w2|ci)) + . ..+log( P(wn|ci) ). Taking the logarithm method can not only avoid the underflow problem, but also has no effect on the predicted result, because the value after taking the logarithm changes the same as the original value. For details, please refer to the figure below.
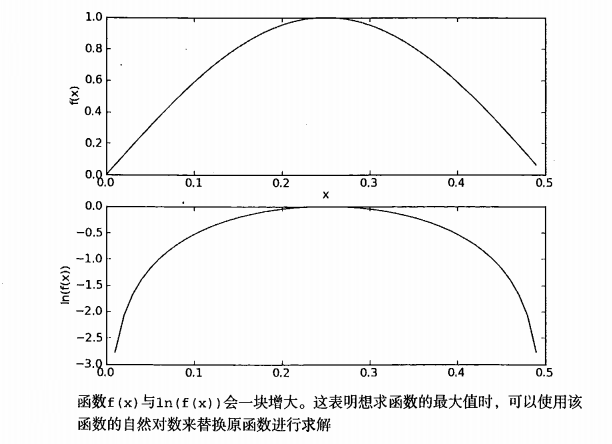
The Python code for taking the logarithm method is as follows.
pw0 = np.log(pw0 / float(p0Num)) pw1 = np.log(pw1 / float(p1Num))
Well, two small problems have been solved, let's predict the classification of a message. Since there are only two types of message categories, and the value of P(w) is the same, we only need to compare the sizes of P(w|c0)*P(c0) and P(w|c1)*P(c1). According to the logarithm method, just compare the size of log( P(w|c0)*P(c0) ) and log( P(w|c1)*P(c1) ). log( P(w|c0)*P(c0) ) = log( P(w1|c0) ) + log( P(w2|c0)) + ...+log(P(wn|c0)) +log (P(c0)), log( P(w|c1)*P(c1) ) = log(P(w1|c1)) + log(P(w2|c1)) + ...+log(P( wn|c1)) + log(P(c1)).
The Python code for the classifier is as follows.
'''
Category of asking for a message
Parameters: inputVec message flag array
'''
def bayesClass(inputVec, pw0,pw1,class1Probability):
pr1 = sum(inputVec * pw1) + np.log(class1Probability)
pr0 = sum(inputVec * pw0) + np.log(1 - class1Probability)
if pr1>pr0:
return 1
else:
return 0
Finally, let's test it with two messages. The words of these two messages are 'love', 'my', 'dalmation' and 'stupid', 'garbage'.
#test
messageList , messageClss = loadDataSet()
vocaList = createVocaList(messageList)
messageFlag = []
for message in messageList:
messageFlag.append(messageToFlag(vocaList,message))
p0, p1, c1 = calcuProbability(messageFlag,messageClss)
testMessage1 = ['love', 'my', 'dalmation']
message1Flag = messageToFlag(vocaList,testMessage1)
print(testMessage1 , ' is classified as' , bayesClass(message1Flag,p0,p1,c1))
testMessage2 = ['stupid', 'garbage']
message2Flag = messageToFlag(vocaList,testMessage2)
print(testMessage2 , ' is classified as' , bayesClass(message2Flag,p0,p1,c1))
The results are as follows.
['love', 'my', 'dalmation'] has a classification of 0 ['stupid', 'garbage'] has a classification of 1
Well, at this point, a simple naive Bayes classifier is completed. If you have any doubts or advice, please contact the editor in the background.
For more dry goods, please pay attention to the WeChat public account: Dream Chasing Programmer.
