Summary: Naive Bayes classifier (Naïve Bayes classifier) is a common but fairly simple and quite effective classification algorithm has very important applications in the field of supervised learning. Naive Bayes is based on "total probability formula" under, known as much by the event A, B obtained P (A | B) to infer the unknown P (B | A) , is the a little metaphysical meaning, knock blackboard! ! !
advantage:
- TF-IDF model training using the training data do word frequency and probability and statistics;
- Classification using Naive Bayesian probabilities for all categories of computing;
- Short text classification applies to electricity providers, adding some manual intervention, top3 accuracy rate can reach 95%;
- Class prediction completely interpretable, black box neural network does not exist, but more dependent on segmentation results;
- Training data category under the basic data is not balanced will not affect the accuracy of the model.
Disadvantages:
- More dependent on segmentation effect;
- Large-scale classification task model file is large (compared with neural networks).
Keywords (Aoutomatic Keyphrase extraction) tf-idf is often used to extract the article, completely without any manual intervention, we can achieve good results, and it does not require advanced mathematics to simple, ordinary people just 10 minutes I can understand, that we first introduce the next TF-IDF algorithm.
TF-IDF
For example, assume that there are a relatively long article "an open letter children around the world," we are ready to extract its keywords by the computer. A simple idea is to find the highest number of words appear. If the word is very important, it should appear many times in this article . So, we "word frequency" (Term Frequency, abbreviated as TF) statistics , but you might guess, the most frequent word --- "and", "Yes", "In the" ---- this category the most commonly used words. They are called " stop words " (STOP words) on the extraction results indicate no help, it is necessary to filter out words, this is you may ask, from the "article" to "word" is how you convert, if you know Chinese word , they should not ask this question, there are many Chinese word pattern, usually by HMM (hidden Markov model), a good word system is very complex, you want to manage access can click on the HMM to understand, but now there are many systems use deep learning of NER (lstm + crf) do object word recognition, not presented here; ok, said before returning, we may find that "child", "power", " mental health "," Privacy "," migration "," conflict "," poor "," disease "," food "," drinking water "," United Nations "that the words as much as the number of occurrences. Does this mean, as a keyword, their importance is the same?
Clearly not the case. Because the "United Nations" is a very common word, relatively speaking, "mental health", "Migration", "conflict" is not so common. If the number of these four words appear as much reason to believe that "mental health", "migration" important "conflict" is greater than the degree of "United Nations", "mental health" and "population movement in the sorting keyword "" conflict "should be at the" front of the United Nations ".
So, we need an important adjustment factor, a measure of a word is not very common. If the word is rare, but it appears more than once in this article, it is likely to reflect the characteristics of this article, is the keyword we need. The adjustment factor is based on the word frequency statistics to assign a "importance" weight for each word. This weight is called "inverse document frequency" (Inverse Document Frequency, abbreviated as "IDF"), its size and the extent of a common word is inversely proportional.
Know the "word frequency" (TF) and "inverse document frequency" (IDF) later, these two values are multiplied, you get a TF-IDF value of a word. The higher the importance of the article a word, it's TF-IDF values greater. So, at the top of a few words, this article is the key word; if applied to text classification, to a high class all the tf-idf value of words and tf-idf value to be extracted and this such is the feature model.
in conclusion:
TF = (某个词在文档中出现的次数) / (文档中的总词数)IDF = log(语料中文档总数 / 包含该词的文档数+1) 分母加1 避免分母为0TF-IDF = TF*IDF
Naive Bayesian inference
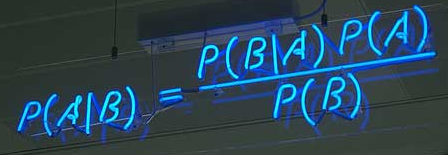
Naive Bayes theory looks on very large, but in fact did not use very deep mathematical knowledge , even without learning too high number also can understand, I feel that is simple but some around , then I will run out under naive Bayes theory may explain the straightforward words.
Bayesian inference is a statistical method used to estimate some of the nature of statistics with other statistical inference different, it is based on subjective judgments on, that is, you can do without objective evidence, first estimate a value, then constantly revised based on actual results.
Here someone may ask, tf-idf can be used for classification, why Naive Bayes? Yes, good question, tf-idf can indeed be classified, but naive Bayes will effectively enhance the accuracy weaken error rate (if you previously had to understand the depth of learning, naive Bayes effect of play a bit like softmax), naive Bayes is based on "total probability formula" under, known as much by the event a, B obtained P (a | B) to infer the unknown P (B | a), is the a little metaphysical meaning, knock blackboard! ! ! It also determines the essential difference between it and the tf-idf probability of such statistics.
Bayes 'theorem : Bayesian inference to be understood, we must first know Bayes' theorem. The latter is actually calculated "conditional probability" formula.
The so-called "conditional probability" (Conditional probability), refers to the case of an event B occurs, the probability of event A with P (A | B) is represented, ah, on which formula is right map. School teacher that would have to memorize this formula, or mathematics second short answer can only write a solution, but today we look at the reasoning of the formula: