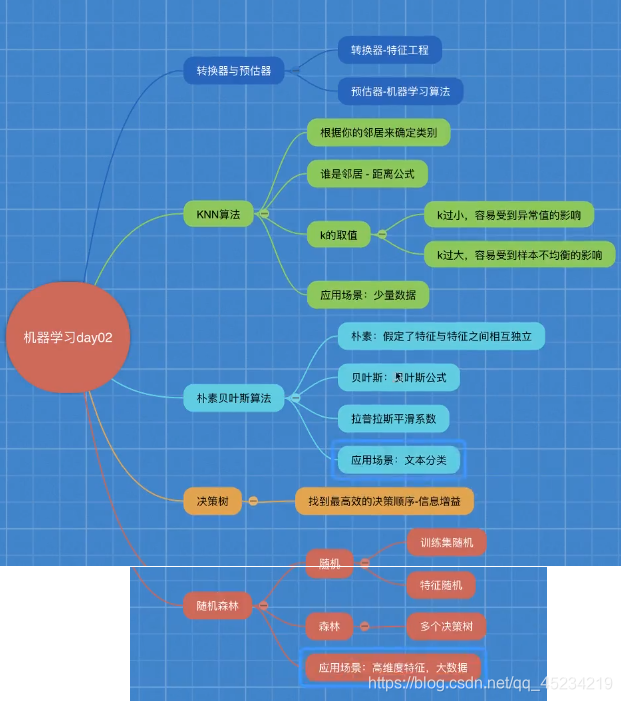
Learning Directory:

Four. Naive Bayes Algorithm



Example: 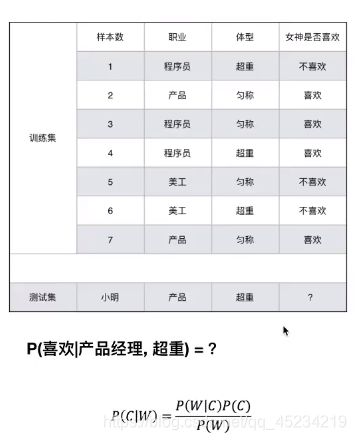

Application of Naive Bayes (including Laplacian smoothing coefficient): Text classification case
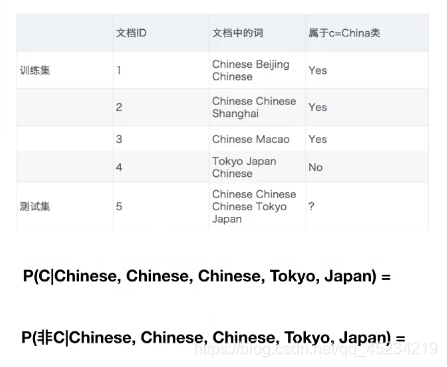


Case: 20 types of news text classification
**Process:** Obtain data (no need to do data processing, English sklearn data is processed)
Divide the data set
feature engineering (because it is an article, so do text feature extraction)
Naive Bayesian predictor process
model evaluation
from sklearn.datasets import fetch_20newsgroups
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.naive_bayes import MultinomialNB
from sklearn.naive_bayes import MultinomialNB
def nb_news():
#获取数据集
news = fetch_20newsgroups(subset='all')
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(news.data, news.target)
#特征工程
transfer = TfidfVectorizer()
x_train=transfer.fit_transform(x_train)
x_test=transfer.transform(x_test)#不使用fit(),因为对验证集进行标准化要按照训练集的标准化标准进行
#朴素贝叶斯算法预估流程
estimator=MultinomialNB()#调用贝叶斯算法
estimator.fit(x_train,y_train)
#模型评估
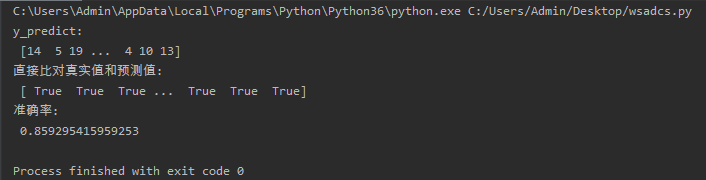
#方法一:直接比对真实值和预测值
y_predict=estimator.predict(x_test)
print('y_predict:\n',y_predict)
print('直接比对真实值和预测值:\n', y_test=y_predict)
# 方法二:计算准确率
score = estimator.score(x_test,y_test)
print('准确率:\n', score)
if __name__=='__main__':
nb_news()
Summary: Naive Bayes
Advantages: less sensitive to missing data, simpler algorithms, higher accuracy of common language text classification, and fast speed
Disadvantages: due to the use of the assumption that the sample attributes are mutually independent, if there is a correlation between features and features, The effect will be worse
Summary of classification algorithms: