Introduction to MaxCompute
Big Data Computing Service (MaxCompute, formerly ODPS) is a fast, fully managed TB/PB level data warehouse solution. MaxCompute provides users with a complete data import solution and a variety of classic distributed computing models, which can solve users' massive data computing problems more quickly, effectively reduce enterprise costs, and ensure data security. MaxCompute mainly serves the storage and calculation of batch structured data, and can provide solutions for massive data warehouses and analysis and modeling services for big data. With the continuous enrichment and improvement of social data collection methods, more and more industry data is accumulated. The scale of data has grown to the level of massive data (hundreds of GB, TB, and even PB) that the traditional software industry cannot carry. In the case of analyzing massive data, data analysts usually use distributed computing mode due to the limitation of the processing capacity of a single server. However, the distributed computing model puts forward higher requirements for data analysts and is not easy to maintain. With a distributed model, data analysts not only need to understand business requirements, but also need to be familiar with the underlying computing model. The purpose of MaxCompute is to provide users with a convenient means of analyzing and processing massive data. Users do not need to care about the details of distributed computing, so as to achieve the purpose of analyzing big data. MaxCompute has been applied on a large scale within Alibaba Group, such as: data warehouse and BI analysis of large Internet companies, log analysis of websites, transaction analysis of e-commerce websites, user characteristics and interest mining, etc.
Free big data service activation: tutorial on using the big data computing service MaxCompute
Development History of MaxCompute
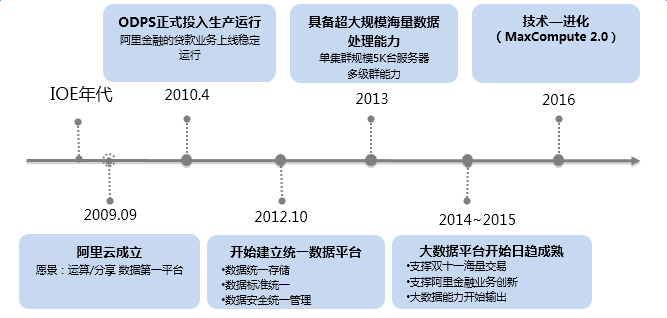
Since the establishment of Alibaba Cloud in September 2009, the vision is to be the first platform for computing/sharing data; in April 2010, with the launch of Alibaba Finance's loan business, ODPS was officially put into production and operation. In 2012, a unified data platform was established. Large-scale and massive data processing capabilities, the big data platform began to mature from 2014 to 2015, and the birth of MaxCompute 2.0 in 2016, the vision at the beginning of its establishment has been gradually realized through step-by-step efforts.
key milestones
2010.04 ODPS was officially put into production and operation. Alibaba Finance's loan business was launched and operated stably.
2013.05 ODPS public beta.
2013.07 ODPS officially provides commercial services, with a multi-level cluster capability of 5K servers in a single cluster.
2016.09 ODPS officially changed its name to MaxCompute, and launched 2.0 to achieve high performance, new functions, and rich ecology.
Introduction to MaxCompute Components
- Data channel:
- TUNNEL : Provides highly concurrent offline data upload and download services. Users can use the Tunnel service to upload or download data to MaxCompute in batches. MaxCompute Tunnel only provides Java programming interfaces for users to use.
- Computational and analytical tasks:
- SQL : MaxCompute can only store data in the form of tables, and provides external SQL query functions. Users can operate MaxCompute as a traditional database software, but it can process massive amounts of data at the TB and PB levels. It should be noted that MaxCompute SQL does not support operations such as transactions, indexes, Update/Delete, and the SQL syntax of MaxCompute is different from Oracle and MySQL. Users cannot seamlessly migrate SQL statements from other databases to MaxCompute. In addition, in terms of usage, MaxCompute SQL can complete queries in minutes or even seconds at the fastest, but cannot return user results in milliseconds. The advantage of MaxCompute SQL is that the learning cost for users is low, and users do not need to understand complex distributed computing concepts. Users with database operation experience can quickly become familiar with the use of MaxCompute SQL.
- MapReduce : MapReduce was first proposed by Google as a distributed data processing model, and subsequently received extensive attention in the industry and was widely used in various business scenarios. In this document, we will briefly introduce the MapReduce model, so that users can quickly get familiar with and understand the model. Users who use MaxCompute MapReduce need to have a basic understanding of distributed computing concepts and corresponding programming experience. MaxCompute MapReduce provides users with a Java programming interface.
- Graph : The Graph function provided by MaxCompute is an iterative graph computing and processing framework. Graph computing jobs are modeled using graphs, which consist of vertices (Vertex) and edges (Edge), which contain weights (Value). Iteratively edits and evolves the graph, and finally solves the result. Typical applications: PageRank , single-source shortest distance algorithm , K-means clustering algorithm , etc.
- SDK: The toolkit provided to developers. For the related introduction of SDK, please refer to SDK introduction .
- Security: MaxCompute provides powerful security services to protect users' data security. For details, please refer to the Security Reference Manual .
More excellent courses:
ApsaraDB for Redis Edition Tutorial
Getting Started with Cloud Storage Object Storage OSS
Load Balancing Getting Started and Product Usage Guide
Alibaba Cloud University Official Website (Alibaba Cloud University - Official Website, Innovative Talent Workshop under the Cloud Ecosystem )